BigQuery Studio 試してみた
1. はじめに
CouseraのGoogleデータアナリティクス プロフェッショナル認定講座でBigQueryを触ることになったので、ログを書いていきます。
- 普段はDBやSQLは触らない素人です。
- ログなので、どんな方に読んでほしいかなどは想定していません。
- ただ、学んだことを書いていくだけです。
- 目標はBigQueryの使い方の概要とSQLの超基本の基本の部分がなんとなくわかれば達成としています。
- 画像サイズの変更が面倒だったので、やってません。でかいと思います。
- 寄り道が多いです。
- ちなみに本講座は日本リスキリングコンソーシアムのキャンペーンで無料で受講できました。通常数万円のコースなので助かります。
1.1 用語の理解
(かったるい話が1.3まで続きます。)
BigQueryとはなにか知るには、とりあえずサービスサイトを見るのがいいと思いました。

「データドリブンのイノベーションを推進するクラウドデータウェアハウス」だそうです。なにそれ。
「データドリブンのイノベーションを推進する」かどうかは正直わからないですし、目的はユーザ次第だと思うのでいったん置いておいて、BigQueryはデータウェアハウス(DWH)であることがわかります。
データウェアハウスって直訳すると「データの倉庫」って意味になるので、何かしらのデータが保管されているんだなと思います。データウェアハウスは次のように定義されています。

カタカナ多いですが、要するに過去や現在のデータを保存してレポートを作ったりするようです。整形されていないデータが入っていても、レポートが作れないか、変なレポートができてしまいます。なので、データウェアハウスに保管されるのはリレーショナルデータベースを代表とする構造化データ(フォーマットがガチガチに定まったデータ)が対象になるようです。
半構造化データってXMLやJSONのような形式のようですが、これを時系列で集めてレポートとかできるんですかね?何かしらの変換が必要な気がしますが。まあいいや。
あと、
ビジネスインテリジェンスにおける主要なコンポーネントとなっています。
ビジネスインテリジェンスというワードからは、「データを保管したいんじゃない。データを用いて意思決定がしたいんだ。」という目的志向を感じますね。なのでデータウェアハウスを活用するイメージとしては、
「手元にデータあるし、とりあえずグラフにしてみたら何か出るんじゃない?」という考えよりも、
「組織の意思決定や個人の行動変容を支援するために、こういうKPIを設定したいです。KPIを設定したならKPIを監視するメトリクスが必要です。データウェアハウスのこのテーブルをBIツールで引っ張ってこればメトリクスが作れます。」
という感じで、ビジネスインテリジェンスを主眼においた、データを保管する場所がデータウェアハウスです。と、書いているような気がします。しらんけど。
というわけでビジネスインテリジェンス VS データウェアハウスという対立する関係ではなく、ビジネスインテリジェンスツールの一部にデータウェアハウスがあるという包含関係です。
一方で、データの活用という目的はいったん置いといて、「とりあえずデータ保管しておけば、後から活用するときになんかの役に立つでしょ」という考えもあると思います。これはそのとおりで、とにかくデータを保管する場所をデータレイクといいます。
また、データウェアハウスよりも小規模で特定の部門の構造化データをまとめたものをデータマートといいます。
なのでデータの規模としては、
データレイク > データウェアハウス > データマート
という順番です。これらの比較をChatGPTに書いてもらいました。
| 特徴 | データレイク | データウェアハウス | データマート |
|---|---|---|---|
| 目的 | 大規模な生データの保存と分析 | 分析や意思決定のための整理されたデータの集約 | 特定のビジネス領域や部門向けに集約されたデータの提供 |
| データ形式 | 構造化データ、非構造化データ、半構造化データなど、あらゆる形式のデータ | 構造化データ | 構造化データ |
| スケーラビリティ | 非常に高いスケーラビリティ(大量のデータを保存・処理可能) | 拡張性に限界がある場合が多い | 比較的小規模なデータセットに焦点を当てている |
| 処理方法 | 生データをそのまま保存し、必要に応じて変換や処理を行う | ETL(抽出、変換、ロード)プロセスによるデータの整理と変換 | データウェアハウスから抽出されたデータに基づく |
| 使用例 | IoTデータの分析、機械学習モデルのトレーニング、ログファイルの保存など | 企業全体の売上分析、顧客データの集約など | 販売部門の売上分析、マーケティング部門のキャンペーン分析など |
| 主な利点 | 多様なデータ形式を柔軟に扱える、スケーラビリティが高い | データの品質と一貫性が高い、既存のビジネスインテリジェンスツールとの互換性が高い | 特定のビジネス領域に焦点を当てたデータの提供、クエリのパフォーマンス向上 |
| 主な欠点 | データの管理と品質保証が難しい場合がある、適切なツールやスキルが必要 | スケーラビリティの限界、データの変換に時間がかかる場合がある | データウェアハウスに依存している場合が多い |
BigQueryについて調べたいはずでしたが、長い寄り道でした。ここまで出てきた言葉の中で、よくわからなかったのものがあったので、GPTに用語集を作ってもらいました。
-
アドホック分析:
- 定期的なレポートやダッシュボードではなく、特定のビジネス上の質問に対して即座に行われる分析。
- スピーディーな意思決定を実現するために用いられ、BIツールを使用することで、データの可視化や分析が容易になる。
- 定期・定型レポートと相互補完的な関係にあり、レポートから得られる気づきや疑問をもとに仮説を立てて検証する。
-
半構造化データ:
- 完全には構造化されていないが、ある程度の構造を持つデータ。
- 例えば、XMLやJSONファイルなどが該当し、これらのデータにはタグやキーが存在しているが、固定のスキーマには従っていない。
-
非構造化データ:
- 一定の形式や構造を持たないデータ。
- テキストファイル、画像、動画、音声ファイルなどが該当し、これらのデータから情報を抽出するには、特定の処理や分析技術が必要。
-
ETLプロセス:
- データウェアハウスにデータを統合するためのプロセスで、「Extract(抽出)」「Transform(変換)」「Load(ロード)」の3つの段階からなる。
- データソースからデータを抽出し、必要に応じてデータを変換・クレンジングした後、データウェアハウスにロードする。
-
ビジネスインテリジェンス (BI):
- データを分析してビジネス上の意思決定を支援する技術や手法。
- データの収集、分析、可視化を行い、組織のパフォーマンス向上や戦略策定に役立てる。
- BIツールを使用することで、データドリブンな意思決定が可能になり、ビジネスプロセスの効率化や競争力の強化に貢献する。
アドホックって言葉、昔MHP2Gでお世話になった携帯ゲーム機のPSPで見た記憶があります。当時は全然意味がわからなかったですが、
ad hoc : 特定の目的のための、その場限りの、暫定的な
という意味のラテン語だそうです。in vivoやquasiやvice versaとかのラテン語はかっこいいですが、アドホックはそれほどかっこよくないですね。特にアドホックのホックの部分が抜け感があってかっこよくないと思います。悲しい話だと思いませんか。
というわけで、ここまで簡単にまとめると、
- BigQueryはデータウェアハウスのサービス
- データウェアハウスは様々な構造化データを保管する場所。
異なる概念として、データレイクやデータマートがある。- データウェアハウスはビジネスインテリジェンスの一部
1.2 サービスの比較
データウェアハウスといえば、BigQuery一択という状況ではなく、いくつかの選択肢があるので紹介します。ついでにBIツールもいくつかあるので紹介します。
- データウェアハウスツールの比較
-
Amazon Redshift (Amazon Web Services)
- クラウドベースのデータウェアハウスサービス。
- SQLクエリによる構造化、半構造化、非構造化データの処理が可能。
- ビッグデータ分析や機械学習技術の利用が可能。
-
Google BigQuery (Google Cloud Platform)
- クラウドベースのデータウェアハウスサービス。
- ANSI SQLによるクエリと機械学習機能を内蔵。
- 大規模なデータセットの分析に適しており、コスト効率が高い。
-
Azure Synapse Analytics (Microsoft Azure)
- データ統合、ビッグデータ分析、エンタープライズデータウェアハウスを提供。
- 機械学習技術を用いたアプリケーションの作成が可能。
- 分析ソリューションのエンドツーエンド提供によりプロジェクト開発が加速。
-
Snowflake
- クラウドベースのデータウェアハウスサービス。
- ストレージと計算を分離し、使用した分のみの支払いが可能。
- リアルタイムデータ共有や自動スケーリング、自動停止機能を提供。
-
IBM Db2 Warehouse
- クラウドベースの完全管理型データウェアハウス。
- リアルタイム分析に対応し、大規模なデータ共有と処理が可能。
- オンプレミスのウェアハウスとの互換性があり、エンドツーエンドのセキュリティ機能を提供。
- ビジネスインテリジェンスツールの比較
こちらがBIツールに関する比較です。
-
Power BI:
- 主な特徴: ユーザーがデータを接続し、レポートやダッシュボードを作成できるビジネスインテリジェンスプラットフォーム。無料ライセンスと有料ライセンス(Pro、Premium Per User)があり、機能が異なります。
- 長所: 直感的なインターフェース、豊富なデータ接続オプション、Microsoft製品との統合が容易。
-
Amazon Web Services (AWS) - QuickSight:
- 主な特徴: AWSのクラウドベースのBIサービスで、データの可視化、レポート作成、インサイトの共有が可能。スケーラブルで、Pay-per-Sessionの課金モデルを提供。
- 長所: AWSのエコシステムとの統合、迅速なデプロイメント、コスト効率が高い。
-
Google Cloud - Looker:
- 主な特徴: クラウドベースのビジネスインテリジェンスプラットフォームで、データの探索、分析、可視化が可能。SQLに基づくデータモデリング言語「LookML」を使用。
- 長所: データモデリングが強力、豊富なカスタマイズオプション、Google Cloudプラットフォームとの統合。
-
Tableau:
-
主な特徴: 優れたデータ可視化機能、直感的なインターフェース、豊富なカスタマイズオプション、他のスクリプト言語との統合(PythonやR)。
-
長所: ドラッグアンドドロップ操作が容易、多様なデータ接続オプション、モバイル対応、優れたコラボレーション機能。
-
-
Domo:
-
主な特徴: 多数の事前構築されたクラウドコネクタ、Magic ETL機能、自動的に提案される視覚化、AIエンジン「Mr. Roboto」、Domo Appstore。
-
長所: チームのコラボレーションとデータの信頼性の向上。
-
やはり御三家が強いですね〜。BIではTableauも結構使われているイメージですね。PowerBIはエンジニアではない方でも比較的使いやすいと思います。QuickSightとLookerは使ったことがないのでわかりません。
1.3 BigQueryのプラン
というわけで、ざっくり目的とかなんとなくわかったうえでBigQueryを触っていきます。まずアカウントを作らなければ行けないわけです。BigQueryを無料で使うには大きくわけて、サンドボックスとGoogleCloud無料トライアルの、2種類のアカウントがあります。
雑比較すると以下のようになっています。
| サンドボックス | 無料トライアル | |
|---|---|---|
| 期間 | 無制限 | 90日間 終了後自動的に課金はされないので安心 |
| 付与クレジット | - | 300ドル分 |
| 制限 | 多い | 少ない |
| クレカ登録 | 不要 | 必要 |
Googleはクレカ登録不要で使えるようにしてくれていて、ありがたいです。「3ヶ月無料!」とかのキャンペーンに踊らされて、解約忘れて損した記憶があります。。なので、クレカ登録不要のサンドボック環境を使うようにします。Googleの場合は解約忘れても自動的に課金はされないようなので安心ですが。感覚的に怖いので・・・。
サンドボックス環境の制限は以下のようなものになっています。
- 作れるプロジェクトは12個まで。
- データベースに新しいレコードを挿入したり、値を更新する操作ができない。
- データ操作言語(DML)がサポートされていない。←INSERTやUPDATEやDELETEが使えないらしい。
- デフォルトのテーブルの有効期限が60日
まあ、軽く触るくらいには問題ないでしょう。いざとなったら、サンドボックスから無料トライアルにアップグレードもできますし。
ちなみにDMLというのはSQLのカテゴリです。
SQL (Structured Query Language) は、リレーショナルデータベース管理システム (RDBMS) でデータを操作および管理するための標準的な言語です。SQLは主に次の4つのカテゴリに分類されます。
-
データ定義言語 (Data Define Language)
データベースの構造を定義するために使用されます。例えば、テーブル、インデックス、ビューなどのオブジェクトを作成、変更、削除するために使用されます。主なDDLコマンドにはCREATE、ALTER、DROPなどがあります。 -
データ操作言語 (Data Manipulation Language)
データベース内のデータを操作するために使用されます。DMLの主な操作には以下が含まれます。- SELECT: データベースからデータを取得します。
- INSERT: データベースに新しい行を追加します。
- UPDATE: データベース内の既存のデータを変更します。
- DELETE: データベースからデータを削除します。
-
データ制御言語 (Data Control Language)
データベースのセキュリティやアクセス権限を管理するために使用されます。主なDCLコマンドにはGRANT(権限の付与)とREVOKE(権限の剥奪)があります。 -
トランザクション制御言語 (Transaction Control Language)
データベースのトランザクションを管理するために使用されます。主なTCLコマンドにはCOMMIT(トランザクションの確定)、ROLLBACK(トランザクションの取り消し)、SAVEPOINT(トランザクションの保存点の設定)があります。
DMLはSQLの中でも特にデータの操作に関連する部分であり、データベース内のデータの取得、追加、更新、削除などの操作を行うために使用されます。というわけでデータベースをいじる上で最も使うのがDMLですね。
はい。
BigQueryについてはドキュメントが豊富にあるので、リンクを貼っておきます
以降はBigQueryStudioを主に触っていきます。
2. BigQuery Studioさわってみる
2.1. サンドボックス環境で遊んでみる。
講座ではBigQueryのSQL workspaceで色々作業していたのですが、ページを見るとそのようなサービスはなく困惑しました。
どうやら2023年8月に発表されたBigQuery Studioというサービスに統合されたようです。
これが何ができるかを見てみると
BigQuery Studio には、BigQuery 内のデータの検出、分析、推論に役立つ次の機能があります。
- 堅牢な SQL エディタ。コード補完、クエリ検証、処理されるバイト数の推定値を提供します。
- Colab Enterprise を使用して構築された埋め込み Python ノートブック。Notebooks は、ワンクリックの Python 開発ランタイム、および BigQuery DataFrames の組み込みサポートを提供します。
- Dataform 上に構築された、ノートブックや保存したクエリなどのコードアセットのアセット管理と変更履歴。
- Duet AI 生成 AI 上に構築された、SQL エディタとノートブックでのコード開発支援。
- データ検出、データ プロファイリング スキャン、データ品質スキャンのための Dataplex 機能。
- ユーザー単位またはプロジェクト単位でジョブ履歴を表示する機能。
- Looker や Google スプレッドシートなどの他のツールに接続して保存したクエリ結果を分析し、他のアプリケーションで使用するために保存したクエリ結果をエクスポートする機能。
SQLかけます。
pythonかけます。
BIツールと連携できます。
って感じでめちゃ便利な気がします。
以下リンクから早速サンドボックス環境で遊んでいきましょう。
リンクからBigQueryのサンドボックス環境に入るとこんな感じの画面に入りました。早速「プロジェクトを作成」押してみます。

はい。

適当なプロジェクト名をつけて「作成」を押します。
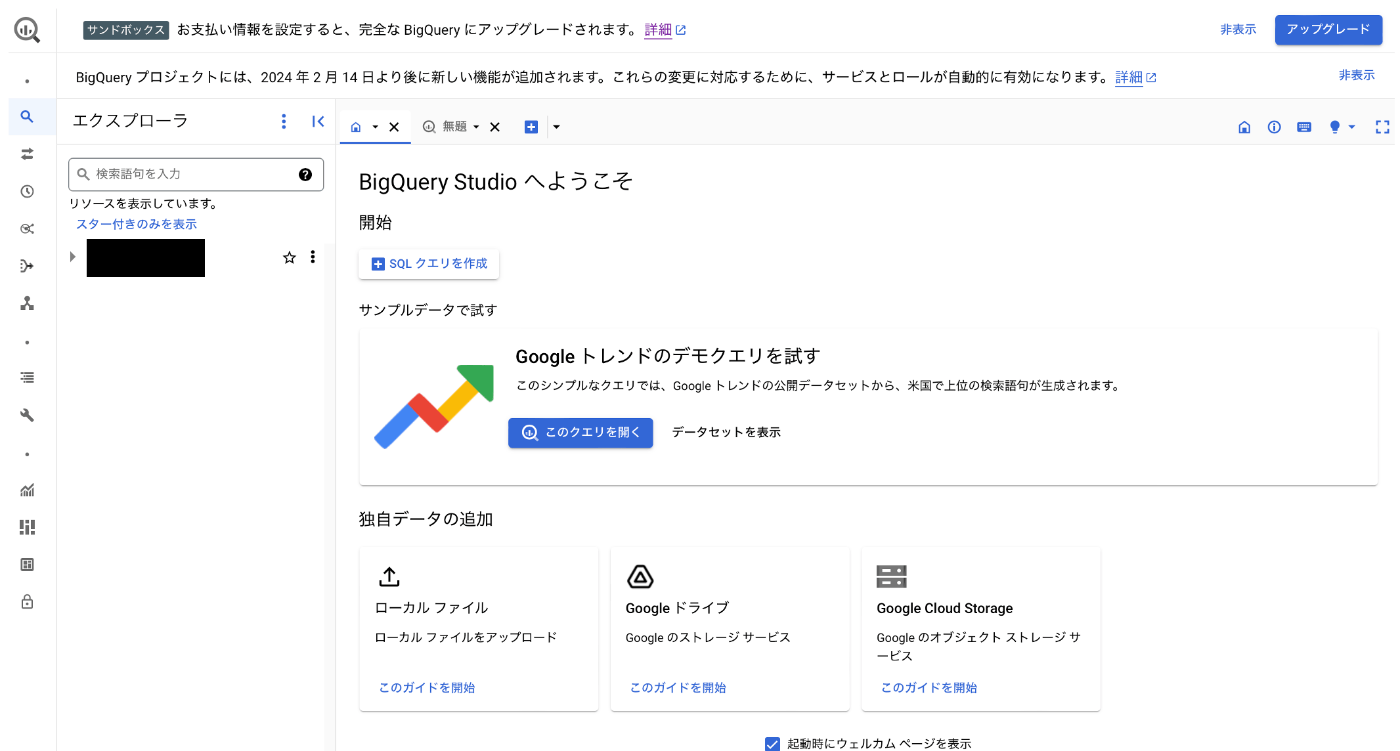
色々ボタンがある画面が出てきました。
とりあえず公開データセットのデモを見てみたいです。なので「このクエリを開く」を押します。

これのことです。

押すとなにやら大量のテーブルが引っ張られてきました。びびります。
そしてエディタ画面にはSQLが書かれています(勝手に開かれました)。
とりあえずここ2週間のトップ検索ワードを表示するっぽいです。実行してみましょう。
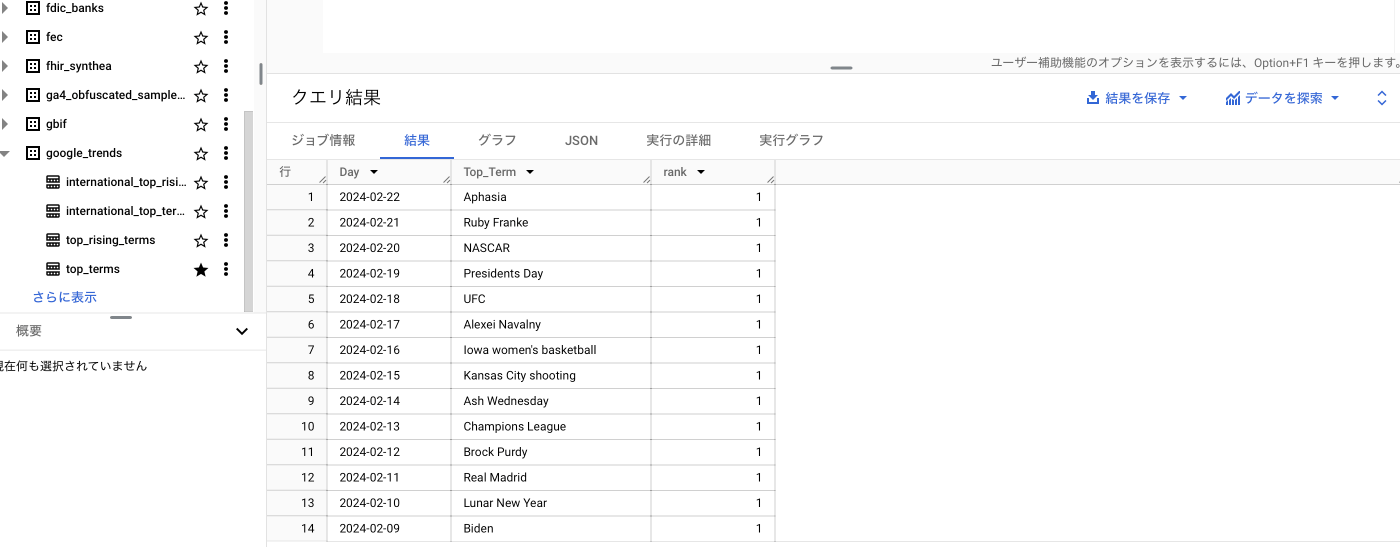
表示されました。全くよくわからんワードが並んでいます。
クエリを適当に名前をつけて保存すると、
プロジェクト名フォルダ > 保存したクエリ
に保存されます。
ちなみに左のエクスプローラから[top terms]をダブルクリックすると色々情報が見れます。
例えば、[スキーマ]タブからはフィールド名のデータのタイプが確認できます。
[詳細]タブからは行数とか容量が見れます。先ほどさらっと実行したクエリでしたが、4300万件以上のレコードから検索しているようです。すごい。
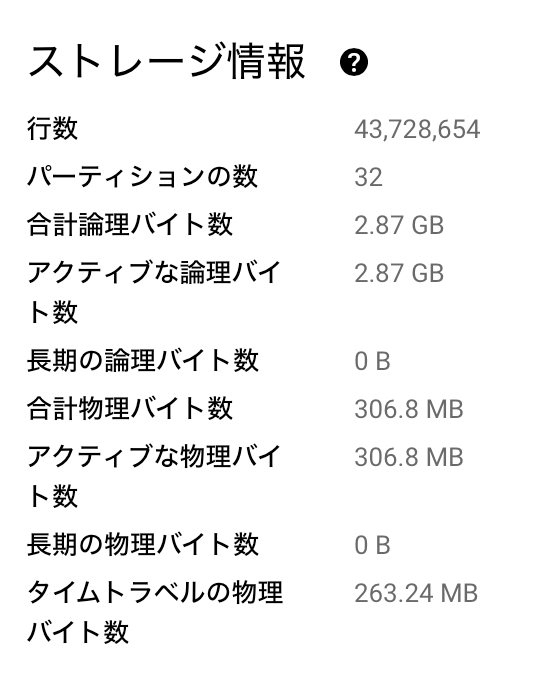
32のパーティションに分割することでパフォーマンスを上げているようです。詳しくはこちら。
とりあえずサンプルデータが用意できてSQL実行方法がわかったので、早速いろいろ触ってイメージを掴みたいです。ぱぱっと試してみるには、スキーマを読んでSQLを書いてみるより、生成AIの力を借りたほうが早いです。Googleには[Duat AI]という生成AIがあって、色々手伝ってくれます。
上のメニューバーのメッセージのアイコンを見てください。
こちらのOpen Duet AIで色々SQLを書いてもらおうと思ったのですが、、、
残念ながら現在は英語限定でした。。
英語で書くと質問には答えてくれますが、英語力がないので、大人しくChatGPTにSQLを書いてもらうようにします。スキーマをスクショ取って貼り付けして、テーブル名を伝えます。あとはやってほしいことを日本語で伝えるだけですね。
オープンデータセットの中に入っているbaseballフォルダのschedulesテーブルでMBAの情報をゲットしてみましょう。
2.2 MBAの情報を引っ張ってみる
例えば、以下の情報を取り出してみます。
- ホームチームがマリーンズの試合
- 取り出すのは「開始日時、観客、デイゲームかナイトゲームか」の3つのフィールド
- 開始日時を昇順(古い順)に並び替える
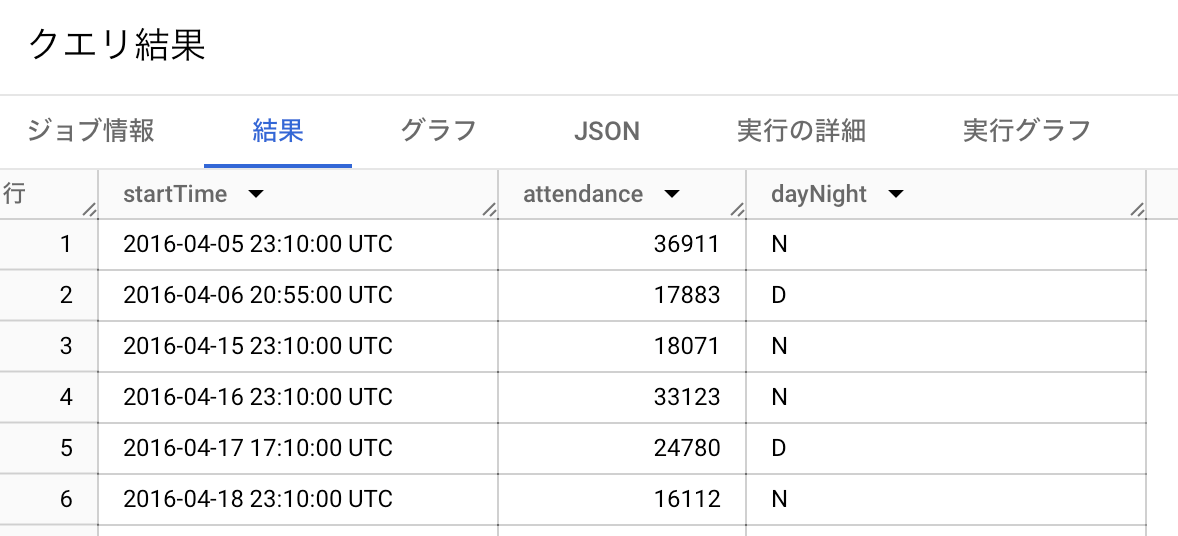
このSQLを書きました(書いてもらいました)。このくらいは自分で書けばよかったすね。
SELECT startTime, attendance, dayNight
FROM `bigquery-public-data.baseball.schedules`
WHERE homeTeamName = 'Marlins'
ORDER BY startTime ASC
実行するとこんな感じです。
[グラフ]というタブがあるので見てみましょう。

こんな感じで何も考えずにグラフが作れてしまいました。
あくまで、こちらは簡易的なグラフ描画であって、そこからさらに分析してみたいです。
そのためには、右上の[データを探索]を押しましょう。

そうすると、スプシでも開けますし、BIツールのLooker Studioも使えますし、Colab上のPythonで解析を進めることもできます。すごい!やりたい放題やん!

ほえ〜すごいっすね。
これほんまにデータウェアハウスなん?
もっとそれ以上の「何でもできる最強データマネジメントツール(もちろんデータウェアハウスもできるよ!)」的なそれっぽいワードで語られるべきのサービスな気がする。知らんけど。
今回はSQLの練習なので、スプシやpythonを使うのは反則としましょうか。試してみたSQLたちを落としていきます。特にマイアミ・マリーンズに強い思い入れはないのですが、マリーンズに関する情報を中心に集めてみました。
- マリーンズのデイゲームとナイトゲームでの平均観客
SELECT dayNight, AVG(attendance) as average_attendance
FROM `bigquery-public-data.baseball.schedules`
WHERE homeTeamName = 'Marlins'
GROUP BY dayNight

デイゲームのほうが多いようです。
- マリーンズの対戦相手による平均観客の変化
SELECT awayTeamName, AVG(attendance) as average_attendance
FROM `bigquery-public-data.baseball.schedules`
WHERE homeTeamName = 'Marlins'
GROUP BY awayTeamName
ORDER BY average_attendance DESC¥

- 各チームのデイゲームとナイトゲームの観客数の年別平均
SELECT
homeTeamName,
dayNight,
EXTRACT(YEAR FROM startTime) AS year,
AVG(attendance) AS average_attendance
FROM
`bigquery-public-data.baseball.schedules`
GROUP BY
homeTeamName,
dayNight,
year
ORDER BY
homeTeamName,
dayNight,
year
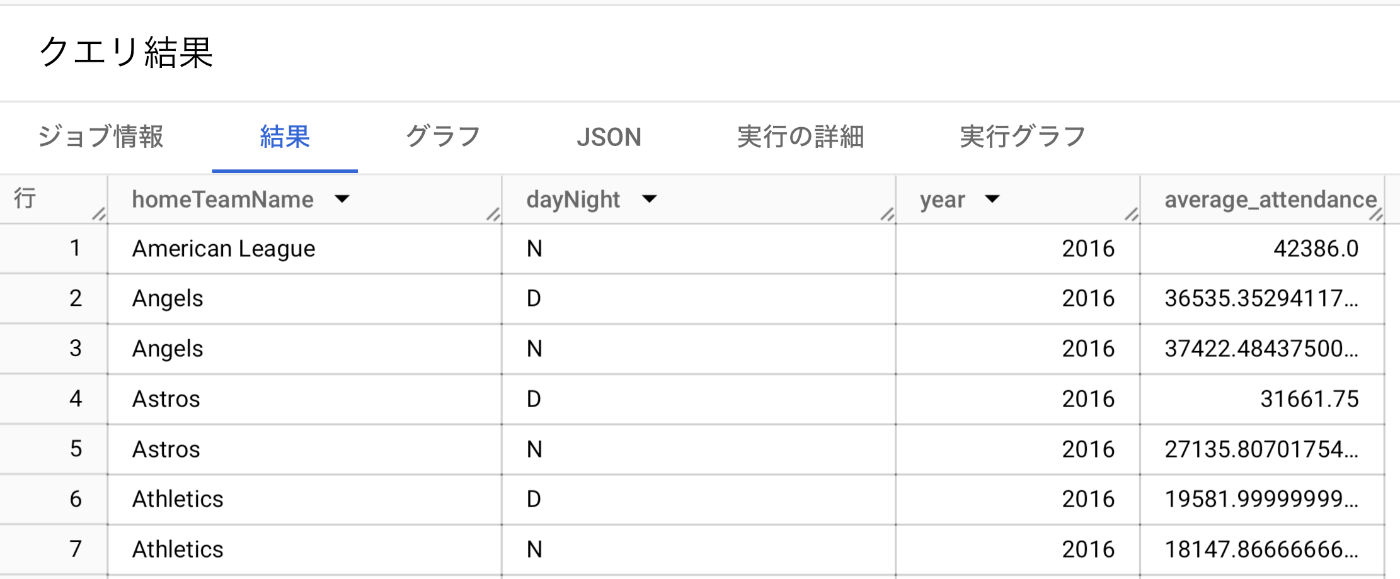
テーブルには2016年の情報しかなかったので、年別平均の意味はなかったです。
あとAmerican Leagueってなに?
あ、どうやらオールスターみたいなやつみたいですね。レコードを見ると、awayTeamNameがNational Leagueで1試合しかなかったので。
ChatGPTにSQLの質問をしまくったあとに、アメリカンリーグについて聞いてみたら、急にBigQuery Studioの話をし始めて怖かったです。アメリカンリーグって曖昧すぎましたね。

怖かったですが、よくよくYoutubeのコメントとかXとか思い返すと、こういう成立していない会話が頻発されているようにも思えます。
- 平均観客数より多いか少ないかを調べる列を追加する。
WITH TeamAverage AS (
SELECT
homeTeamName,
AVG(attendance) AS average_attendance
FROM
`bigquery-public-data.baseball.schedules`
GROUP BY
homeTeamName
)
SELECT
Schedule.homeTeamName,
Schedule.startTime,
Schedule.attendance,
CASE
WHEN Schedule.attendance > TeamAverage.average_attendance THEN 'High Attendance'
ELSE 'Low Attendance'
END as attendance_category
FROM
`bigquery-public-data.baseball.schedules` AS Schedule
JOIN
TeamAverage ON Schedule.homeTeamName = TeamAverage.homeTeamName
ORDER BY
Schedule.startTime
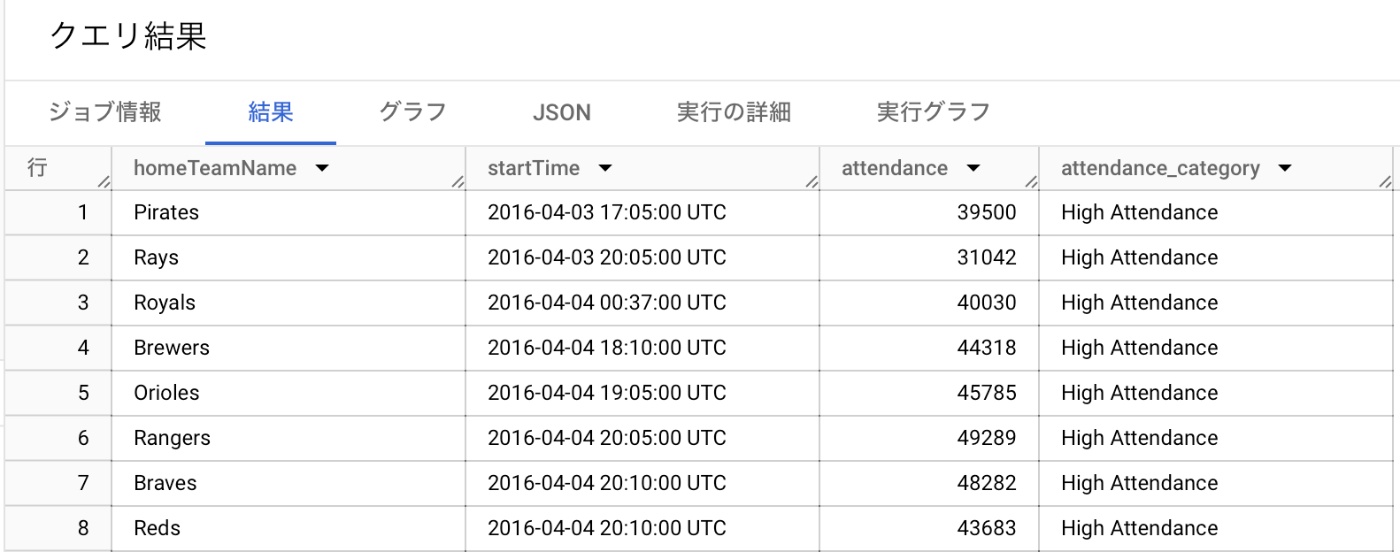
- AwayTeamとして来てくれると、平均観客数が32000人を超えるチーム
SELECT
awayTeamName,
COUNT(*) AS games,
AVG(attendance) AS average_attendance
FROM
`bigquery-public-data.baseball.schedules`
GROUP BY
awayTeamName
HAVING
-- COUNT(*) >= 10 AND -- 試合数が10試合以上にしぼりたいとき(オールスターを除外したいとき)
AVG(attendance) > 32000 -- ここで設定した閾値は適宜変更してください
ORDER BY
average_attendance DESC
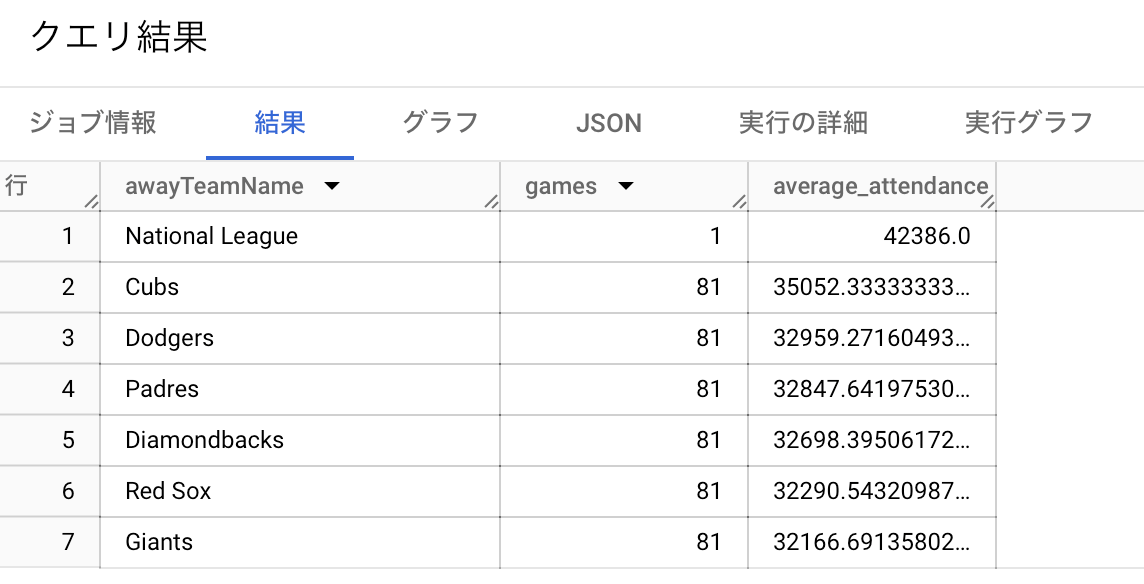
カブスが来てくれると観客数が増えるので嬉しいみたいです。
- HomeTeamの平均観客数
SELECT
homeTeamName,
AVG(attendance) AS average_attendance
FROM
`bigquery-public-data.baseball.schedules`
GROUP BY
homeTeamName
ORDER BY
average_attendance DESC
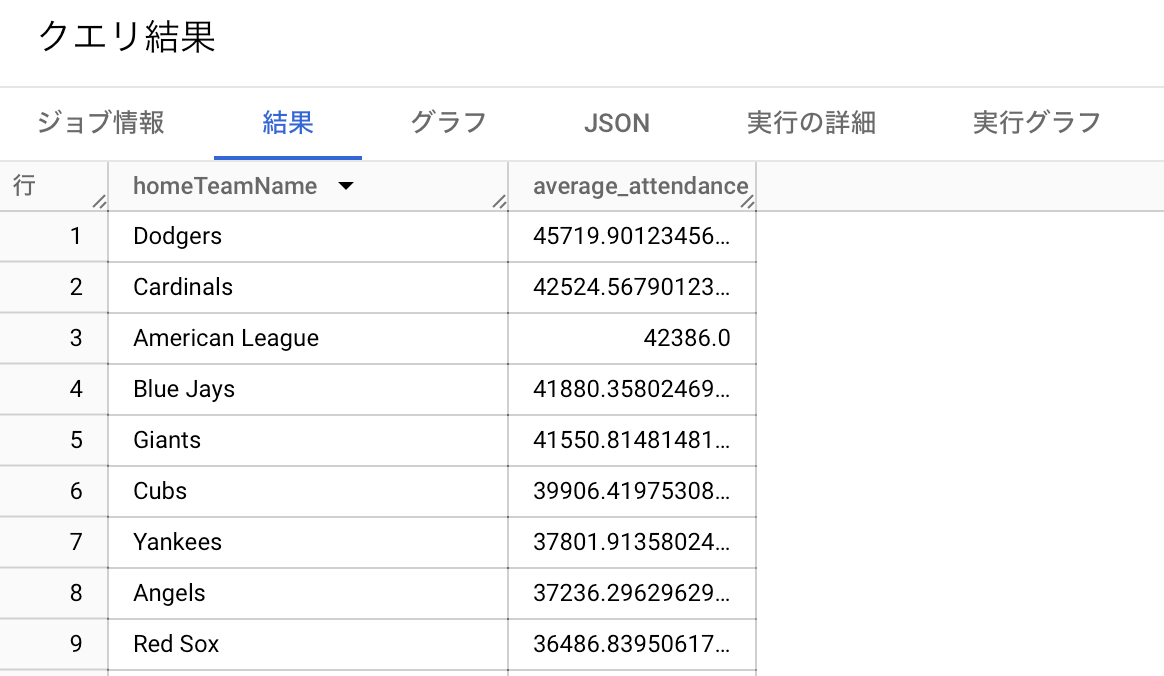
ホームチームとして観客数が多い球団はロサンゼルスのドジャースでした。シカゴのカブスは6位ですね。ロサンゼルスはシカゴよりも都市圏人口が多いです。一方で、都市としてはトップのニューヨークヤンキースが7位に低迷しているので都市の規模だけでは説明できないですね〜。日本でも兵庫県に本拠地があるタイガースが観客動員数トップですし、 地域の野球人気や球団人気ですかね。
2.3. ローカルファイルのアップロード
ここまで、公開データセットでSQLを触ってきましたが、手元のcsvをBigQueryにアップしたいときもあります。
例えば、こんな感じのcsvをアップロードしたいとしましょうか。名前人気ランキングです。名前、性別、カウントの3列です。
| Emma | F | 20941 |
|---|---|---|
| Olivia | F | 19817 |
| Sophia | F | 18628 |
| Isabella | F | 17102 |
| Noah | M | 19316 |
そのときは、
エクスプローラの縦の3点リーダーからデータセットを追加を押します。
右にメニューが表示されるので、ローカルファイルを選択します。
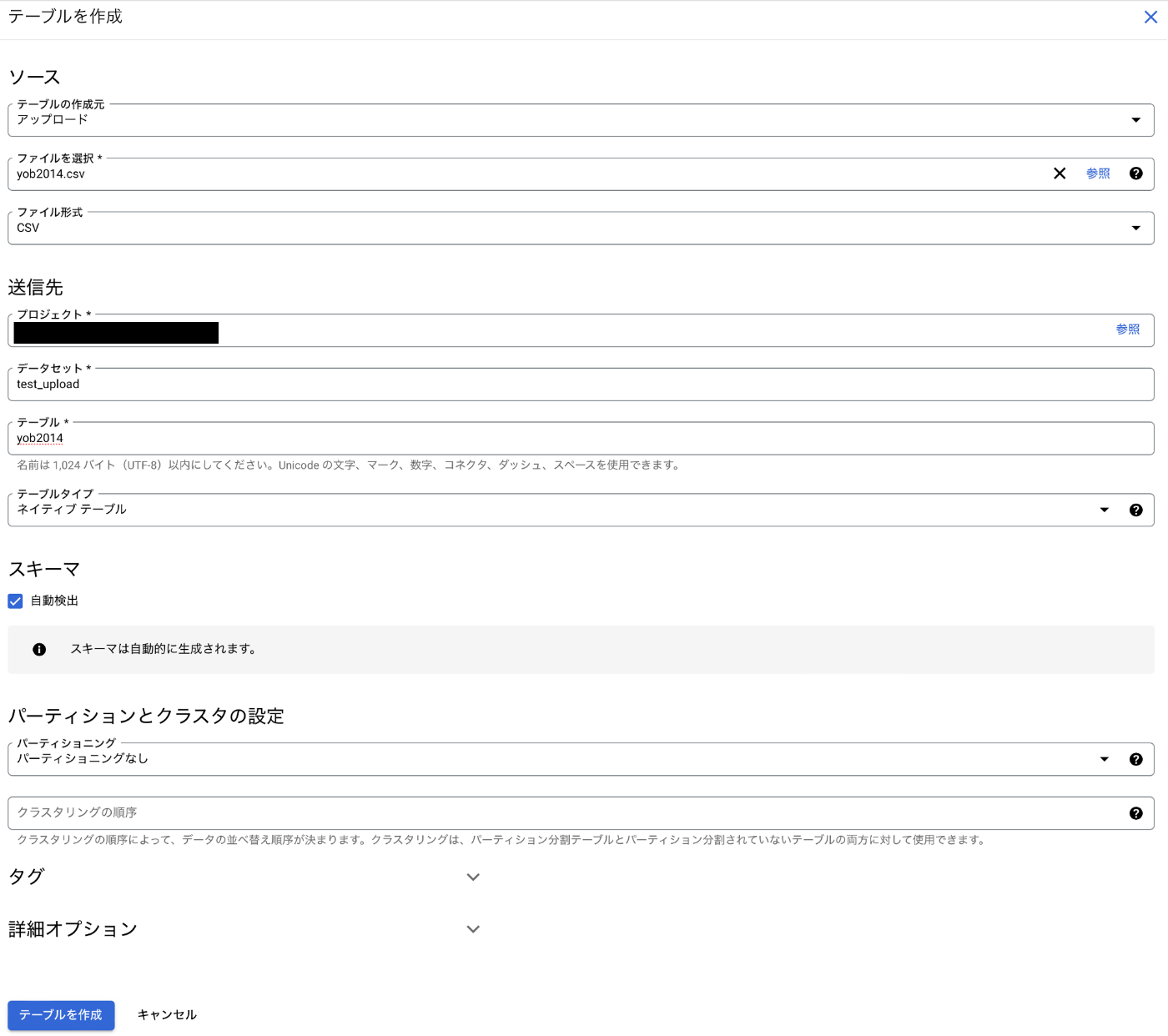
自分は講座でダウンロードしたcsv形式のファイルをアップロードしてみました。
まずデータセットを作らなければ行けないので、データセットの入力欄から「データセットを作成」を選択します。
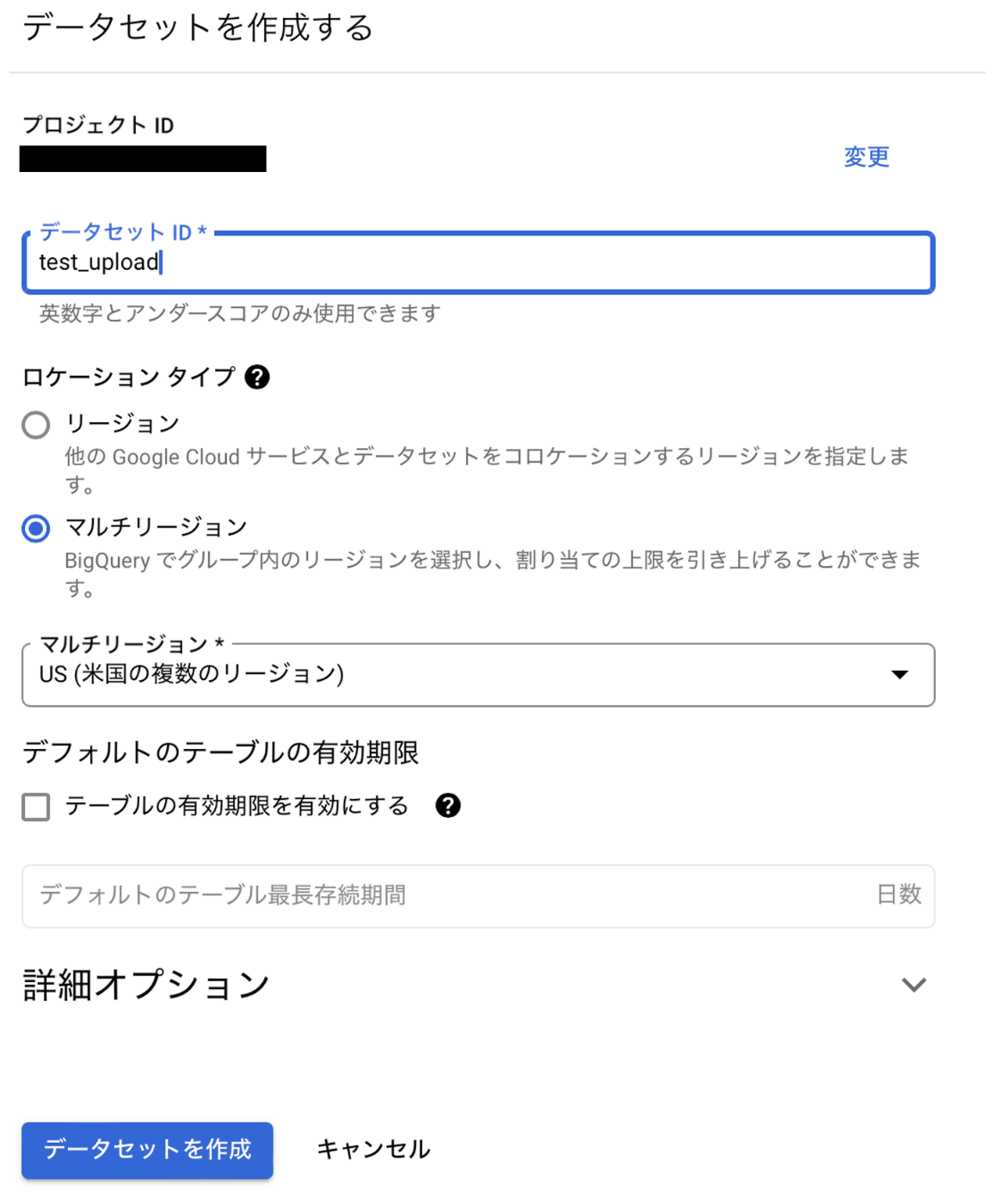
データセットIDを適当につけてあげて、データセットを作成します。
その後、上の画面のテーブル名を適当につけてあげます。
スキーマを定義するのが面倒だなとおもったのですが「自動検出」にチェックをいれるだけでやってくれると信じています。
「テーブルを作成」を選択します。

読み込みで大量のエラーが出てしまいました。スキーマの自動検出のエラーです。gender列には"F","M"いずれかの文字列が入っていて、"F"を見てboolean型と思ったのかなと思います。大人しくスキーマを手書きします。。

こんな感じでスキーマを書きました。
そうすると、無事にデータが読み込まれました!
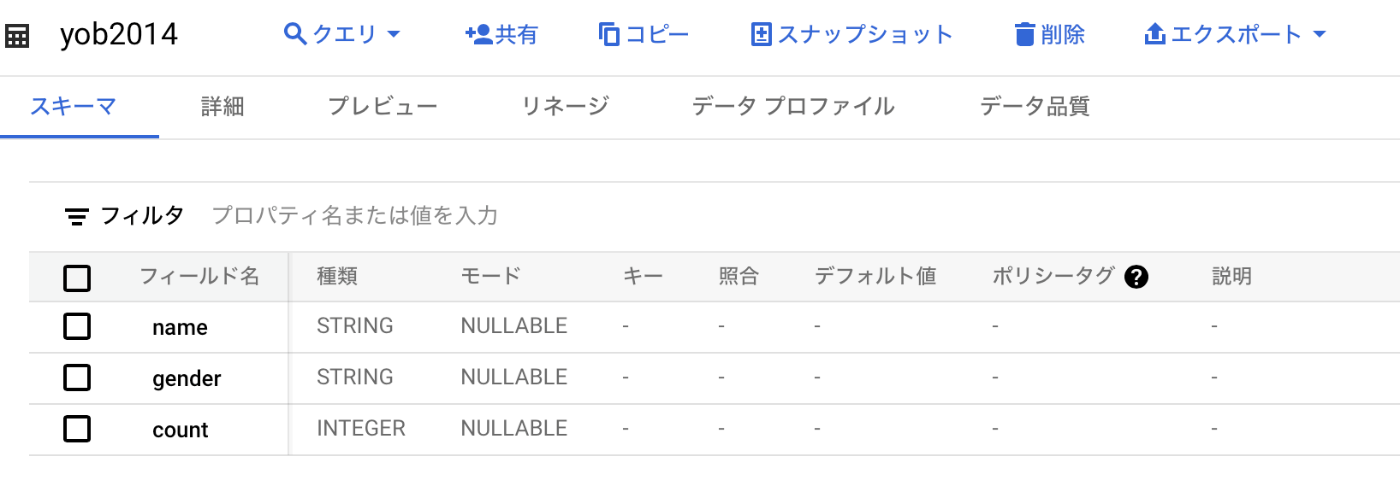
よかったです。
SELECT
name,
count
FROM
`test_upload.yob2014`
WHERE
gender = 'M'
ORDER BY
count DESC
LIMIT
5
クエリを投げると、
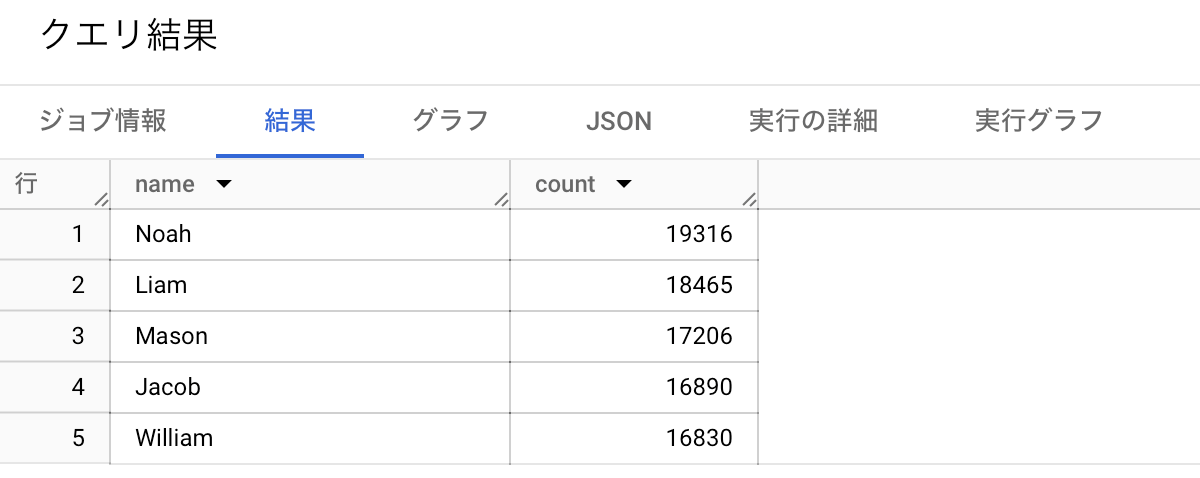
ちゃんと結果が返されます。
3.まとめ
- BigQueryでSQL実行できる。
- ローカルのCSVも取り込める。
- 生成AI(英語のみ)に色々質問できる。
- 簡易的なグラフ描画機能あり。
- スプシ、BIツール、Colabなど、外部連携もしやすい。
- ほんとはもっと機能ある。1割も活用していない気がする。
Discussion