【2025年10月】最先端の半導体の概要と論点-GPUとデータセンターとものづくり
1. はじめに
「半導体業界」というテーマで情報をまとめました。
背景を少し説明する。幸運にも縁があって、東大松尾研主催の「AIと半導体講座 2025|Summer」を受講することができた。

そのなかで特に、東京大学(現在スタンフォードで共同研究中)の小菅先生の「半導体のエコシステム」という講座が面白いと感じた。本当に楽しそうに、ワクワクされながら最新の技術を解説していて、「良いなあ、面白そうだなあ」と思える素晴らしい講座だった。
講座を聞いて思ったのは、とてつもない大企業が手を取り合ったり、殴り合ったりしている。悲喜こもごもあると思うが、端から見ている分にはエンタメでしかない。
- 半導体設計ではNvidia一強。シェアを奪いたいAMD。Nvidia依存度を下げたいGAFAM。
- ウエハ工程では王者TSMCとSamsungとIntel。そこに新たにラピダスも挑む。
巨大企業がシェア・利益を争ったリーグ戦をしている。もっと詳しくなれば、もっと楽しめるはず。
今業界で勝っている企業の強みはなんなのか、今後の技術の争点はどこにあるのか、がもっと知りたい。その手前の、業界全体の概要的な部分を知らないことも多い。合わせて調べてまとめていきたい。
1.1 やりたいこと
理解するということは分解することなので、分解したい。
ざっくりした切り分け方として以下の4つを考えてみた。他にも分け方はあると思う。
- 作る側(設計→前工程→後工程) or 使う(GPU計算、データセンター)で分ける(※1)
- 作る側のプロセスでわける:設計 or 前工程 or 後工程 or ...,
- 作る部品でわける:GPU or CPU or メモリ or SSD or 通信機器 or ...,
- アプリケーションでわける:サーバ(PC) or スマホ or 車載 or ...,(※2)
※1:今回「作る」側を中心に調べた。
※2:「アプリケーションでわける」は、いいわけ方だと思うので書いてみたのだけれど、直近はLLMの学習や推論等で、AIデータセンターが話題沸騰中なので、スマホや車載は一旦離れて、サーバ(PC)に話を絞ることにする。
部品もGPUがホットなのでGPUに絞ってもいい。ただCPUやメモリも面白いので調べたことは適宜触れていきたい。
なので要するに、
データセンター向けのGPU(やメモリ)の、設計〜前工程〜後工程をざっくり調べる。
書く内容はどのような論点が現在のホットトピックなのかを中心に調べていく。したがって、「トランジスタの動作原理は?CPUってどういう命令ができるの?」という具体的な技術各論は置いておく。え、置いておく?いや「置いておく」というのはかっこつけた言い方で、ほんとは全く詳しくないので書けません。すいません。
いきなり個別の話をしても混乱してくるので、まずは全体像をまとめてみます。
2. 半導体概要と業界
2.1 半導体のプロセス概要
まずは業界の前に一通り半導体を作るまでの流れを記載する。簡単に、以下3つの工程にわけた。

| 工程 | 概要 | 特徴 |
|---|---|---|
| 設計 | 半導体チップの回路設計とフォトマスク製造を行う工程 | - ファブレス(製造設備を持たない)企業が担当 - 実際の製造は行わない - CAD/EDAを使用した設計作業が中心 |
| 前工程 | シリコンウェハー上に微細な回路を形成する工程 | - サイクル型の製造フロー(同じ作業を層数分繰り返し) - ナノメートル単位の極精密加工 - 超清浄なファブ(fab)で実施 - 数十億ドルの設備投資が必要 |
| 後工程 | 完成したウェハーを個々のチップに切り分け、製品として組み立てる工程 | - 直線型の製造フロー(一方向の工程) - OSAT企業が専門的に担当 - 2.5D/3D実装やパッケージング |
2.2 半導体設計
設計の目標は仕様を回路図に落とし込むことである。
最近のGPUでは800mm^2のチップサイズに100億個以上のトランジスタが搭載されている。こんなトランジスタの塊を設計できるのか不思議。
流れとしては以下。

このように、半導体設計は要件を固めて設計を進めるウォーターフォールである。
また、EDAツール(Electronic Design Automation)を活用しておりかなりの部分が効率的に設計できるようになっている。が、回路設計~設計検証においては人手でやらないと行けない部分が多い。設計全体で1~2年くらいかかる。
ソフトウェア開発ではウォーターフォールからアジャイルへと変遷しているが、半導体設計では各工程で求められる知識ドメインが大きく異なるため、手戻り発生時のロスが大きいので頻繁に仕様が変更できないのでウォーターフォールが採用される。一方、上流段階でFPGA試作やシャトル試作などで早期検証しサイクルを回すなど、アジャイル的な要素も取り入れられている。
シャトル試作;複数の設計を1枚のウェハに“相乗り”させた試作チップ
Appleは毎年のように新しいiPhoneのチップを出せているのは、既存IPと設計プラットフォームをうまく再利用できているからだと思う。
1. 要件定義・機能設計
欲しいものを決める最初の工程。
例えば、「LLMの学習や推論を効率化するプロセッサを作ってほしい!」という需要がある。
そういった需要を掘り下げながら、今の設計製造技術から実現できそうなレベルのチップ仕様を固めていく。
2. アーキテクチャ設計
要件定義で決まった仕様を具現化する設計段階。
半導体チップ全体の機能ブロック構成や、それらの接続方法を決定する。例えば、「LLM推論用プロセッサ」であれば、演算処理ユニット、メモリインターフェース、入出力インターフェース、制御ユニットなどの主要ブロックと、それらを結ぶデータバスの構成を設計する。
この段階では、性能目標(処理速度、消費電力、チップサイズなど)と製造コストのバランスを取りながら、各機能ブロックの役割分担や相互接続方式を詳細に決めていく。また、メモリアーキテクチャやデータフローの最適化、並列処理構造なども検討し、システム全体として効率的に動作するよう設計を行う。
3. 回路設計

https://www.technologyreview.com/2022/08/18/1058116/eda-software-us-china-chip-war/
アーキテクチャ設計で決めた機能ブロックを、実際のデジタル回路として設計する工程。
この段階では主にRTL(Register Transfer Level:レジスタ転送レベル)設計と呼ばれる手法を用います。設計者はVHDLやVerilogなどのハードウェア記述言語(HDL)を使って、各機能ブロックの動作を記述する。
RTL設計では、データがレジスタ間でどのように転送され、どのような論理演算や算術演算が行われるかを定義する。この抽象的な記述により、物理的なコンポーネントの詳細を考える前に、回路の機能を定義・最適化できるため、効率的な設計が可能になる。
設計された回路は、その後の論理合成工程でゲートレベルのネットリスト(実際の論理ゲートの接続リスト)に自動変換される。
4. 設計検証
設計した回路が仕様通りに動作するかを確認する重要な工程。
検証には主にシミュレーション検証とフォーマル検証の2つのアプローチがある。
シミュレーション検証では、設計した回路にテストパターンを入力し、期待する出力が得られるかを論理シミュレーションで確認する。
フォーマル検証は、テストパターンを用意することなく、回路の論理構造を数学的に解析して動作の正当性を証明する手法。アサーション(動作条件)を定義し、その条件が満たされるか、あるいは違反するかを自動的に検証できる。
また、設計品質を客観的に評価するため、HDL記述のカバレッジ測定も実施されて、テストが十分に行われていない部分を特定し、設計不具合の削減をする。
現在は高位合成と呼ばれるツールがあり、仕様書とプログラム仕様(C言語)をインプットすると、RTLが自動生成可能になる。また、設計検証結果まで自動化されており、検証を満たすように回路が繰り返し最適化される。現状は高位合成ツールが理解できるようなプログラム仕様の記述をしないといけないし、このいいRTL記述ができるようにツール自体の改良が求められている。こちらも今ホットなトピック。
5. 半導体図面合成
設計最終段階では最適化と最後の検証、及びほんまに作れるのかの確認をする。主に、以下の4つのことをする。
-
回路レベルの最適化
まず、抽象的な回路記述(RTL)を使って自動的にゲートやフリップフロップのつながりを作る。このとき、動作速度・チップサイズ・消費電力を考慮しながら、冗長な部分を削ったり、信号が速く届くように部品を入れ替えたりする。 -
物理レベルの最適化(配置配線)
次に、チップ上にゲートや大きなブロック(メモリなど)を並べる(配置)。その後、各部品を金属線で結ぶ(配線)ことで信号の通り道を作る。まず大まかな線を引き、その後最適化する。
CPUやGPUといってもただの電子回路。配線長が長ければ、抵抗と容量が大きくなる。となると、消費電力と発熱が増加する。それは困る。とにかく配線長を短くするようにセルの配置を最適化しないと行けないが、素子数が多すぎて大変。ツールがある程度エイヤで置いて、そこから最適化する手法を取っている。
Googleが強化学習で最適化する手法をNatureで提案しました。
https://www.nature.com/articles/s41586-021-03544-w
オープンソースでGithubで公開されています。
https://github.com/google-research/circuit_training
ただ、この論文や実装に対して批判的な見方もされています。
https://cacm.acm.org/research/reevaluating-googles-reinforcement-learning-for-ic-macro-placement/
-
設計との整合性を確認。LVS(Layout Versus Schematic)
回路図とRTLや回路図とプログラム仕様を比べる。ずれがあると、どこが違うかを見つけて直す。→回路図面の完成 -
製造ルールを確認。DRC(Design Rule Check)
ファウンドリ設計ルールに基づき、最小線幅・間隔、ビア寸法、重なり制約など幾何学的ルール遵守を確認する。違反箇所はマスクデータ修正により再検証を行い、製造可能性を保証する。
これでチップ製造用のマスクデータが完成する。→製造図面の完成
この最後のタイミングで「デザインルールに違反してますので、その設計は作れません」ってなっても、「えぇ〜こんなにがんばって設計したのにぃ〜!?!?」となり困り果て枯れ朽ち死にます。
実際は設計初期からDFM(Design for Manufacturability)の考えが組み込まれており、設計途中でも部分的にDRCを検証することで手戻りを防止している。
補足
もう少し詳しいフローも置いておきます。

https://aws.amazon.com/jp/blogs/industries/generative-ai-for-semiconductor-design/
半導体工程全体像

https://www.rapidus.inc/tech/te0001/
工程の概要は以下もイラストで説明されていて、ざっくりイメージしやすい。
2.3 前工程
前工程の目標はシリコンウエハに多数のCPUやGPUを作ることである。

ウエハにナノオーダーのCPUやGPUのトランジスタを大量に作るんだけど、トランジスタのサイズがキーポイントになってくる。16nmとか3nmとか聞いたことがあると思う。これをプロセスルールといいます。が、今やもうどこかの長さを表しているわけではなく、微細化の世代の名前くらいに捉えておいてよい。
なので半導体企業はもうnm表記をやめて、16Nとか3Nという表記を使っている。世代が進むごとに0.7倍していくだけのただの数字。「微細化進んでますよ!」と、アピールしたいところでもあるので、nmを想起させるNを使っている。ちょっとせこいなと思ってしまった。
ちなみに2Nの次は14Aです。1.4nm=14Åだからですね。いつまでこれやるんだ。

https://www.tel.co.jp/museum/magazine/report/202407_02/?section=last
トランジスタの構造は微細化が進むにつれ、FinFET→GAA→CFETへと変遷していくロードマップが描かれている。今は2NのGAAが量産されている時代。構造が小さいほどチップを詰め込めるし、消費電力も小さくなるメリットがあるので今後も微細化は進む。ただ製造コストもかかるので一長一短。一気に置き換わるわけではないし、古い世代の需要もある。
実際、TSMCの熊本第一工場は12~24nm世代の半導体が作られている。
さて、この小さいトランジスタたちをどうやって作るかというと、主に成膜・エッチング・洗浄・露光の4つの工程を繰り返して複雑な構造を作っている。細かい工程含めると何百工程とかになるはず。
同じ装置を使い回すので、自動車の生産ラインのような流れ作業のラインは作れない。同じ装置に行ったり来たりするのでややこしい。「このウエハどこまでやったんだっけ」ってなりそう。実際はそんなことならない。システムで管理されているし、ウエハ搬送ロボットが自動で装置に投入して回収するので、半導体工場のクリーンルームには全然人がおらず、高度に自動化されている。
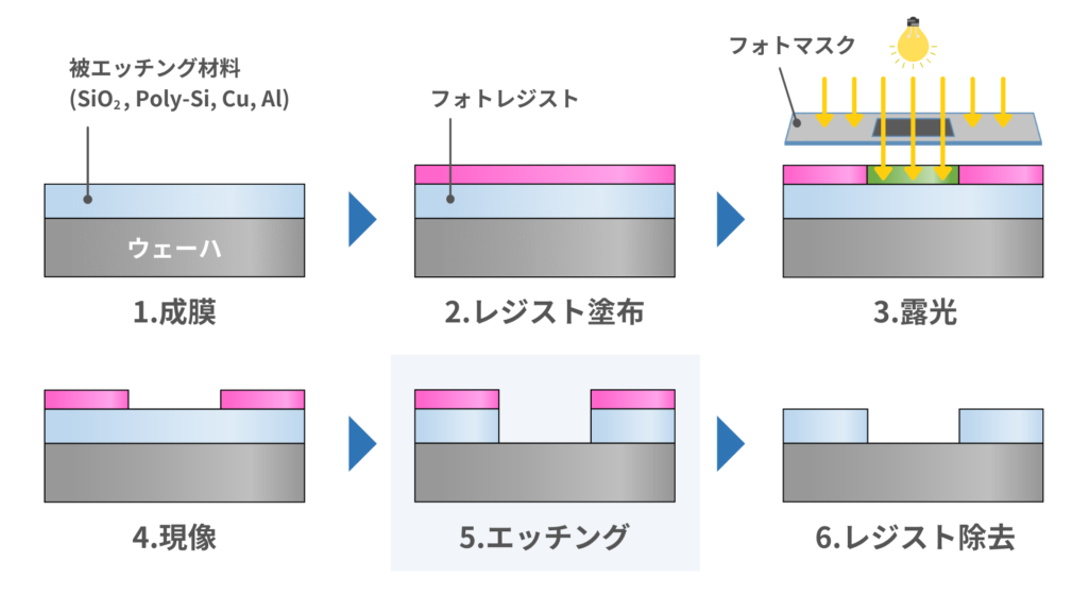
https://semi-journal.jp/basics/process/etching.html
イメージを掴むには動画のほうが手っ取り早いかも。
成膜やエッチングというのは、ウエハ全体に薄膜を積んだり、全体を掘っているイメージで、これだけでは多層膜的なものしか作れない。ウエハがデバイスになれるのは、露光(リソグラフィ)でパターニングしているからこそだと思う。そして露光が最も難しい。装置作る側も装置使う側にとっても。
露光装置の概要

https://www.tel.co.jp/museum/magazine/report/202310_01/?section=3
2Nのデバイスでは最も解像度の高いEUVが求められる。世界でオランダのASML1社のみがEUVを製造できる。1台300億円とかする。高い。年間100台くらいしか作れない。
解像度は光源波長と開口数とプロセス依存係数で決まる。波長が短いほど解像度が高い。
1世代前の液浸ArFでは光源波長193nmで、純水(屈折率1.44@193nm)に浸けても実質波長134nm程度。
一方でEUVはドライ(真空)なので屈折率は1なのだが、EUVの波長は13.5nm。え?いきなり一桁解像度上がってる!
EUVってExtreme Ultraviolet(極端紫外線)なんですけど、13.5nmって紫外線っていうかもうこれほぼX線じゃない?X線で露光してるん?そら解像度高いわ。
EUVで難しいのは、短波長だと光源がミラーやレンズに吸収されてしまう。レジストに行くのは出力の1%程度。なのでめちゃめちゃ高出力の光源が必要。高出力にすると汚染しやすいし困る。あと運用側としてもEUVは部品寿命が短かったりするらしく、ダウンタイムを小さくしながら定期的にメンテしなければならない。加えてEUV用マスクは一般的な透過型ではなく反射型なので、マスク洗浄、マスク検査の頻度も多い。
それでも実質的な解像度は8nm、GAAを作るにはまだ足りず、EUVを複数回露光して1つのパターンを作るマルチパターニングが採用される。
マルチパターニング技術の中で4回露光するSAQP(Self-Aligned Quadruple Patterning)のイメージ


https://www.globalsino.com/ICsAndMaterials/page2352.html
↑
これで解像度の限界のさらに1/4のパターンができている。ただ、これを採用すると、露光回数が増えるので工程の長期化や、歩留まりが低下するリスクがある。
単純に作れればそれでいいのではなく、歩留まり(良品率)が重要な指標になる。
12インチシリコンウエハ(70,686mm2)からダイサイズ800mm2のGPUチップが80個近く取れるはずだが、歩留まりが40%であれば、1枚のウエハから32個しか取れず、残りはゴミとなってしまう。これでは儲からない。歩留まりが想定より低ければ生産未達で納期遅れが生じてしまい、クレームや信用問題に発展する。最先端の技術難易度が高いものでも、歩留まり70%は欲しい。
サムスンはQualcommのCPUの試作歩留まりが低く、取引を失注した。
前工程は、一見すると大量の装置を買えばどうにか作れる装置産業に見える。なんだけど、ほんとのところは装置よりも、高い歩留まりを維持する量産技術のほうがめちゃめちゃ重要。技術とノウハウの塊魂。
2.4 後工程

https://corp.i-pex.com/en/product/semiconductor/semiconductor
サムスンの動画わかりやすくていいです
以前は後工程が半導体工程の花形であったらしい。現在はチップレット実装等で再び脚光を浴びている。チップレット実装は後述する。
やっていることとしては、
- ウエハ切り出してチップにする
- チップ乗っける
- ワイヤ打つ
- パッケージする
- テストする
- 出荷
技術的難易度が非常に高い工程があるわけでもないように思えるが、それは前工程のように微細化や性能向上が強く求められるわけでもなく、習熟した技術の採用を維持できているから。
後工程は日本の装置メーカや材料メーカがかなり強い。前工程も強い。
後工程ではロボットが自動でワイヤをパンパン打ってる感じ。他の工程もロボットが自動で色々頑張っている。
ワイヤボンダ、めっちゃ動作速ない?
TSMCが営業利益率50%ほどあるのに対して、後工程のトップシェアのASEは7%ほど。それだけ「付加価値が低い」ように思われています。あと、単純に話題性がそれほどないです。。
TSMCの利益率が高いのは古いラインも生産継続できているから。半導体設備の償却年数が5年なので償却済みのラインは費用計上が少なく利益率が上がるらしい。
チップレット実装を後工程に入れてよいかは諸説ある。チップに切り出してから実装するまで前工程という捉え方もある(チップレット実装ラインのクリーン度は前工程と同等を求められるし)。後は新たな中工程だという人もいる。ややこしいので早く結論出てほしい。
2.5 半導体業界概要
以上を踏まえて、現在の企業を説明します。
| 用語 | 定義 | 備考 |
|---|---|---|
| ファブレス | 自社に製造設備を持たず、半導体の企画・設計・販売に特化する事業モデル | |
| ファウンドリ | 他社設計のICを受託製造する半導体工場/ビジネスモデル | ファブレスから設計データを受け取り、完成ウェハをOSATへ出荷 |
| OSAT | Outsourced Semiconductor Assembly and Testの略。パッケージ組立と電気的試験を外注で担う企業・工程 | ファウンドリからウェハを受領し、実装可能な完成パッケージにして出荷 |
| IDM(垂直統合型) | 設計・製造・組立試験・販売までを自社一貫で行う企業形態 | 基本は内製だが、必要に応じて一部を外部委託する場合もある。また外部から受注して生産のみすることもある。 |
このようになっていて、企業群をまとめるとこんな感じ。

サプライチェーン的な関連企業群を加えるとこんな感じ。

ほんとはもっとたくさん書きたい企業がありますが、書ききれない
3. 論点
論点1. IntelとSamsungの衰退
まずは客観的な一つの指標である株価を見てみます。

Intelは下落しています。Samsungは+43%ですが、S&Pに比べて劣後しています。この5年って半導体(生成AI,GPU,データセンター)に注目が集まった5年かなと、なので他のファブレス企業やウエハファブの株価は大きく上昇しています。そこも踏まえてみると、なかなか厳しい結果なのでは。
それぞれ個別具体要因があるが、共通して言えるのは先端ノードの歩留まりが低い。これに尽きると思う。
Intel
CPUシェアはAMDが猛追。
- サーバではAMDがほぼ50%
- PCではAMDが30~40%
かつてはCPUといえばIntelだったが、一気にAMDにシェアを奪われた。
13世代14世代CPUの設計問題もあった。あとデスクトップ向けではマザボ仕様が頻繁に変わるしマザボ高いらしい。今はコスパ求めるならAMDという印象。
しかしIntelは起死回生を図る最先端の18A世代GAAの量産を進めている。Panther Lake。この歩留まりが55%程度まで改善しており、さらに改善できれば復活するかもしれない。
Samsung
早くから3N世代の量産に着手していたが、歩留まりがなかなか安定せず。
QualcommのSnapdragon、NvidiaのRTX30系を受注していたSamsungであったが、TSMCの歩留まり90%に見劣りし、顧客が流出してしまった模様。メモリの方でも歩留まりと消費電力の問題でNvidiaの受け入れテストに落ちてSK hynixに大きく引き離されてしまった(現在は再設計して合格した)。
結果として、ここ数年のSamsungの半導体事業部門は利益トントン。
成熟ノードでは歩留まりは悪くない。最近テスラから大型受注した。
Samsungは超コングロマリットであるし、Intelは垂直統合型なので、リソースをウエハファブに振り切れなかった?ということではなく、それ以上にTSMCが全振りしている。
TSMCの設備投資額はIntelやSamsungがウエハファブに向ける金額の倍以上ある。TSMCの市場シェアは70%。
Intelについては先端ノードの量産が始まっているし、調子が悪くてもCPUの設計改善とかでごまかせる面があり体力がある。一方、受注生産するSamsungは受注しなければ売上が立たないし、歩留まりが悪ければ利益も出ない。ファウンドリが1社に集中するのも市場原理な気がしている。が、発注側として複数社購買をして供給リスクの低減や価格競争をさせたいはずで、ファブレス側はSamsungの歩留まり向上を期待している。
結論:TSMCが強すぎるだけなのでは?という気がしてきた。
論点2. TSMC強すぎる問題
| 観点 | 具体的な強み | 数値・事実 |
|---|---|---|
| 高い歩留まり | 先端ノードの早期量産安定化と高い歩留まり実現 | 3nm N3Pで85-90%の歩留まり、2nm N2で試作段階60-70%(量産時は80%超を目標) |
| 圧倒的な規模 | 世界最大規模のファブ運営と急拡大 | ウエハファブ:18拠点、建設中24拠点 後工程ファブ:6拠点、建設中4拠点 |
| 設計支援 | ファブレスとの協調による上流設計段階からの統合支援 | VCAプログラムでGUC等と連携し、ファブレス顧客のコンセプト段階から量産まで一貫支援、MPW・IP統合・DFM最適化を提供 |
| 先端パッケージ強化 | CoWoS等の急拡大と新技術導入 | 2025年末70-80千枚/月→2026年末100千枚超、CoWoS-L(2026年)・SoW-X(2027年)投入計画 |
- 先端ノードは作れるのがTSMC1社だから価格決定権を持ってる
- 設計支援子会社を通じてファブレスの設計から入ってる
- ウエハだけかと思いきやチップレット関係の中工程までやってる
- 設備投資や人材投資含めた全ての規模が別次元
- これ誰が勝てるのかわからない
論点3. Nvidia強すぎる問題
Nvidiaの強みはGPUの設計もそうだが、GPUを使いこなすためのCUDAエコシステム。
GPUプログラミングは本来めちゃめちゃ面倒な制御が求められる。なはずだが、機械学習エンジニアはハードウェアをそれほど意識することなくAI開発ができる。なぜならCUDAプラットフォームの上でpytorchなどのライブラリが動くから。

https://documentation.sigma2.no/code_development/guides/pytorch_profiler.html
- AIデータセンター向けGPUで90%以上のシェア
- もともとGPUはPCゲーム用途が多かったが、最近はAIに注力していてゲーマーが嘆いている。
- GPU最近えらい高くない?
- データセンター向けだと、モデルが巨大になってきて、分散学習が必須になっているのでGPU間の通信帯域が求められる。ここもNVLinkで抑えている。これが結構いいらしい。
CUDAはGPUを「なんでもできるハードにする」ためのプラットフォームというイメージ。近年急速にAI関係の需要が伸びたが、最適化されたハードウェアやライブラリがないので、Nvidiaを使うしかなかった。この需要をNvidiaが全部巻き取ったから世界を取った。
ただ一方で、「この計算をめちゃめちゃしたいです」という専門的なハードウェアが求められるのであれば、ASICを独自で開発して、ハードウェアからソフトウェアまで最適化したほうが効率がいい。これをやったのがGoogleのTPU。GAFAMくらいの規模だとこういう動きがあるが、大半の企業にとってはNvidiaのプラットフォームに囲い込まれたほうが楽だと思う。
この絶対的なポジションを取ったCUDAですが、その牙城を崩そうとする動きがいくつかある。最近注目を集めているのはTriton。これはオープンソースのコンパイラで、Nvidia/AMDなどハードウェアに依存することなく高速なGPUプラグラミングコードに変換できる。これにより最近はAMDのGPUでも機械学習しやすい環境が整いつつある。AMDのプラットフォーム「ROCm」の評判はよくなかったようだが、Triton対応を強化することで追いつこうとしている。でも特段理由なければNvidia使うよね。
論点4. メモリ、縦に積まれる(HBM)。HBM4が量産へ。
DRAMの話をします。
これ最近の論点でもなんでもないのですが、メモリって昔ながらの付け外しできる基板実装タイプのイメージ持ってた。。DDR4とかDDR5とか進化してるな〜くらいにしか思ってなかった。GPUもオンボードメモリなんだな〜的な。調べてみると面白い。
HPC向けのGPUではGPUチップのすぐそばにメモリがある。これがいわゆる2.5D実装。
ちなみにTSMCはインターポーザ上に2.5Dにパッケージングする技術をCoWoS(Chip on Wafer on Substrate)と呼んでいます。
DRAMダイが積み重なっています。これをHBM(High Bandwidth Memory)といいます。

https://pc.watch.impress.co.jp/docs/news/1159414.html#01_l.png
HBMの世代は「1 → 2 → 2e → 3 → 3e → 4」と進んでおり、現在3,3eが広く用いられている。1TB/sまで来てる。
Nvidia H100(2022年)はHBM3で、Nvidia H200(2024年)はHBM3e。
| 世代 | 積層ダイ数 | ピン速度 (Gb/s) | スタック帯域 (GB/s) | スタック容量 (GB) | 実用化時期 |
|---|---|---|---|---|---|
| HBM | 4(4–8) | 1.0 | 128 | 4 | 2015 |
| HBM2 | 8(4–8) | 2.4 | 307 | 8 | 2016 |
| HBM2E | 8(8–12) | 3.6 | 461 | 24 | 2019 |
| HBM3 | 8(8–16) | 6.4 | 819 | 24 | 2022 |
| HBM3E | 12(8–16) | 9.8 | 1,280 | 48 | 2024 |
| HBM4 | 12(4–16) | 10+ | 2,560 | 64 | 2026 |
積層数が増えるほど、発熱の問題がある。メモリは熱に弱い。メモリが重ねっていると放熱性が悪くなる。爆熱になるGPUのそばにあるし。もちろん積層するほど信頼性も大事。
直近のHBMシェアは
- SK hynix62%
- Micron 21%
- Samsung 17%
と、SK hynixが圧倒的な首位を取ってる。
今後はHBM4の量産が始まる。ここでもSK hynixは準備着々。
韓国のSK hynix、HBM4の量産準備が整う。
米Micron、HBM4は2026年量産開始予定
LLMでは、学習段階でもメモリ帯域やメモリ容量が重要ではあると思いますが、特に推論段階でメモリが効いてくると言われています。HBM4などのメモリ積みまくって帯域も早いものが出ると、ChatGPTとかGeminiとかの値段が安くなったりするかも..?
論点5. 通信技術-プラガブルとCPO
GPUの性能向上、クラスタの大規模化によってLLMの学習などの超ハードなタスクでも実現できるようになってきました。しかし、新たなボトルネックが生じました。それはGPU間通信です。
Metaの論文では、GPT-3などの学習において、通信時間が全体の最大60%を占めることが示されました。現在ではさらにクラスタの大規模化やパラメータ数の増加等で、さらに通信の比率が増加しているかもです。が、Nvidiaはちゃんと手を打っています。
データセンターの構成概要
データセンター内の構成には正直詳しくないのですが、ざっくりのイメージで書くと。
普通のデータセンターの場合
・1つのラックにサーバが数十個ある。
・ラックの上(ToR:トップオブラック)にスイッチがあって、
・ToRからさらに上位のスイッチにつながって、、、
という構成のはず。
AIデータセンターの場合
・1つのラックにサーバがたくさん並んでいる。
・サーバからもおそらくToRにつながっているだろう
・各GPUからもNVSwitchにつながっている
・↑これがすごい

https://www.fibermall.com/ja/blog/nvidia-nvlink-and-nvswitch-evolution.htm
NVSwitchっていうのはGPU同士をつなぐための中継スイッチのようなもの。
NVLinkはCPUやメモリを経由せずに爆速でGPU同士を通信可能にする技術。
第4世代のNVLinkでは、各GPU間が900Gbpsの双方向通信ができる。
この技術によって、分散学習では頻発するであろう「あるGPUが別のGPUのメモリの情報が必要になる」状況において、速やかにデータをもらえて通信待ち時間が減る。
プラガブルとCPO(Co-Packaged Optics)
ここでの通信には光通信が主に使われる。家にあるLANケーブルのような銅線ケーブルでは帯域が足りない。帯域を無理やり上げてもノイズで劣化するのでビット誤り率が上がるので困る。光は電磁干渉(EMI)や無線周波数干渉(RFI)の影響を受けないし、高速通信できるので便利。光通信では800Gbpsとか行ける。というかWDM(波長分割多重)を使っているので、波長細かく区切ればなんぼでもいけそう。
プラガブルモジュール
この光通信はプラガブル(LANケーブルみたいにプラグで抜き差しできる)モジュールが用いられる。

https://www.fibermall.com/ja/blog/dac-aoc.htm?srsltid=AfmBOootC_jibaau7L6-0KDQK5EHjUnSZKk--4BTYqTLSCKgIrSae--W
こういうやつで見た感じLANケーブルと大差ない。が、この線の中には光ファイバーがあって、端子には半導体レーザと受光素子が組み込まれている。PC内では当然電気信号でやり取りするので、専用のDSP(Digital Signal Processor)で光信号を電気信号に変換もしている。
上述したように、帯域がどんどん求められるようになってきたが、ケーブルの先から数センチは銅線でつながっているので、そこでロスが生じてしまう。
となると、先程のメモリと流れは同じ。この光ケーブルがGPUに近づいてくるようになる。
基板にトッピング全部乗せみたいになってますね。
CPOとは

https://businessnetwork.jp/article/28042/
図のようにチップのすぐそばで光信号→電気信号変換をしているのがCPO。これで遅延が低減する。
CPOそんな広まらないかも
CPOの何が困るって言うと、光通信モジュールが壊れた場合に修理困難で、GPU含めた丸ごと捨てないといけなさそうな点です。あと光ファイバーはずれると出力が低下するので、神経質な位置合わせ精度が求められる。こんながんばった割に光がチップに少し近づくだけですか...?って感じもする。
一方でプラガブルだったら壊れてもケーブル取り替えるだけなので、すぐ復旧できる。
というわけで現在はプラガブルが主流で、今後CPOは伸びるかもしれないが、プラガブルと共存していく程度だろうと予想されている。
というかLPO(Linear-drive Pluggable Optics)のように、抜き差しのケーブルは残したまま、チップの隣まで光を持っていく技術のほうが良くない?と素直に思う。
実際、市場サイズも市場の伸び率もLPOのほうが大きいと予想されている。
論点6. データセンター、ARMベースのCPUが広がる
ARMっていうとスマホのイメージで、パソコンはx86かなと思ったけど、スマホで培った技術もあってか電力効率が良いらしい。AppleのMacもARMベースのCPUになったし(Apple Silicon)。データセンターにもARMのCPUが広まってる。
AWSのAmazon、AzureのMicrosoft、GCPのGoogle、クラウド御三家がARMのCPUを設計している。NvidiaもARMベースのCPUに自社設計のGPUで統合しています。
富士通も参入。2N世代。
データセンター向けの出荷ベースでARMの比率は20%程度です。
電力問題の圧(データセンターがやり玉に上げられがち)があるので、どんどん広がっていきそう。
2016年:ソフトバンクがARMを買収した。
2020年:ARMをNvidiaに売ろうとしたけど、独禁法に引っかかっておじゃんに。
2023年:ARM再上場。ただ株式はほとんどソフトバンクが持ってる。
いま:上場してから株価3倍くらいになってる。孫さんNvidiaに売れなくてラッキーしたかも。
論点7. SoW(System on Wafer)、あるかも
AMDなど、ダイを小分けにして歩留まり向上とかを狙っている一方で、真逆の動きがちょこちょこあります。
ウエハ丸ごと1チップに持っていくSoWがあります。有名どころのベンチャーで言うとcerebras社。

これ一箇所でも欠陥があると使えないのかと思ったけど、部分的に動かない回路があっても正常に動作はするようなロバスト設計がなされているようです。
本命はTSMCのような気がしていて、2027年に量産を目指すようです。

1つのチップの演算能力が大きいほど、効率面でメリットがある。通信、スペースなど。
規格外のサイズなので、文字通り色々規格から外れて専用設計になり製造コストが高くならないか。
あとピーク時に20kWとかの消費電力のようで、単純に発熱がやばい。電気ポットより電気ポットしてる。サイズがある分、冷やしやすいとは思うけど。液浸にするんだろうか。
論点8. 中国半導体事情について
中国は自国完結した半導体のサプライチェーンを作ろうとしており、国が7兆円のファンドを組成した。
この追い風もあるし貿易戦争で買えないから作るしかないというモチベがあるわけで、急速に進歩している。
| 分類 | 企業名 | 概要 |
|---|---|---|
| ファブレス | HiSilicon(海思半导体) | Huawei傘下のチップ設計企業。スマートフォン向けKirinシリーズなどを開発 |
| ファブレス | UNISOC(紫光展锐) | スマートフォンやIoT向けSoCを手がける上海拠点の設計企業。世界で4番目のモバイルプロセッサメーカー |
| ファブレス | Loongson Technology(龙芯中科) | MIPS互換マイクロプロセッサを開発。政府主導の「中国製造2025」に貢献 |
| ファブレス | Zhaoxin(兆芯) | VIA TechnologiesとのJVでx86互換CPUを設計。国内市場向けデスクトップ/ノートPC用 |
| ファブレス | Cambricon Technologies(寒武纪) | AI向けアクセラレータチップを設計。ディープラーニング用途に特化 |
| ファウンドリ | SMIC(中芯国际) | 中国最大の純プレイファウンドリ。350nm~14nmプロセス対応、世界5位のシェア |
| ファウンドリ | Hua Hong Semiconductor(华虹半导体) | 上海拠点の純プレイファウンドリ。28/22nm量産、14nm開発中 |
| ファウンドリ | Wingtech(闻泰科技) | 設計から製造まで手がけるIDMながら、純プレイファウンドリとして他社向け製造も提供 |
| ファウンドリ | Nexchip(纳芯微电子) | DRAM/フラッシュメモリプロセスを中心とした純プレイファウンドリ |
| ファウンドリ | United Nova Technology(优锘科技) | 高度パッケージングや微細プロセス製造を手がける純プレイファウンドリ |
| OSAT | JCET(长电科技) | 江陰拠点の国内最大OSAT。グローバルでも3位の規模でパッケージング・テストを提供 |
| OSAT | Huatian Technology(华天科技) | パッケージングとテストサービスを提供するOSAT。JCETに次ぐ国内大手 |
| OSAT | Tongfu Microelectronics(通富微电) | 通信・民生向けなど幅広いパッケージング・検査サービスを提供するOSAT |
製造装置
2024年9月に以下の記事が出た。

https://xtech.nikkei.com/atcl/nxt/column/18/00001/09360/
見出し:「厳しい中国の半導体国産化、製造装置のほとんどが自給率2割以下」
なるほどなるほど。製造装置はまだ安心だな。と、思いきや
1年後の2025年9月に以下の記事が出た。
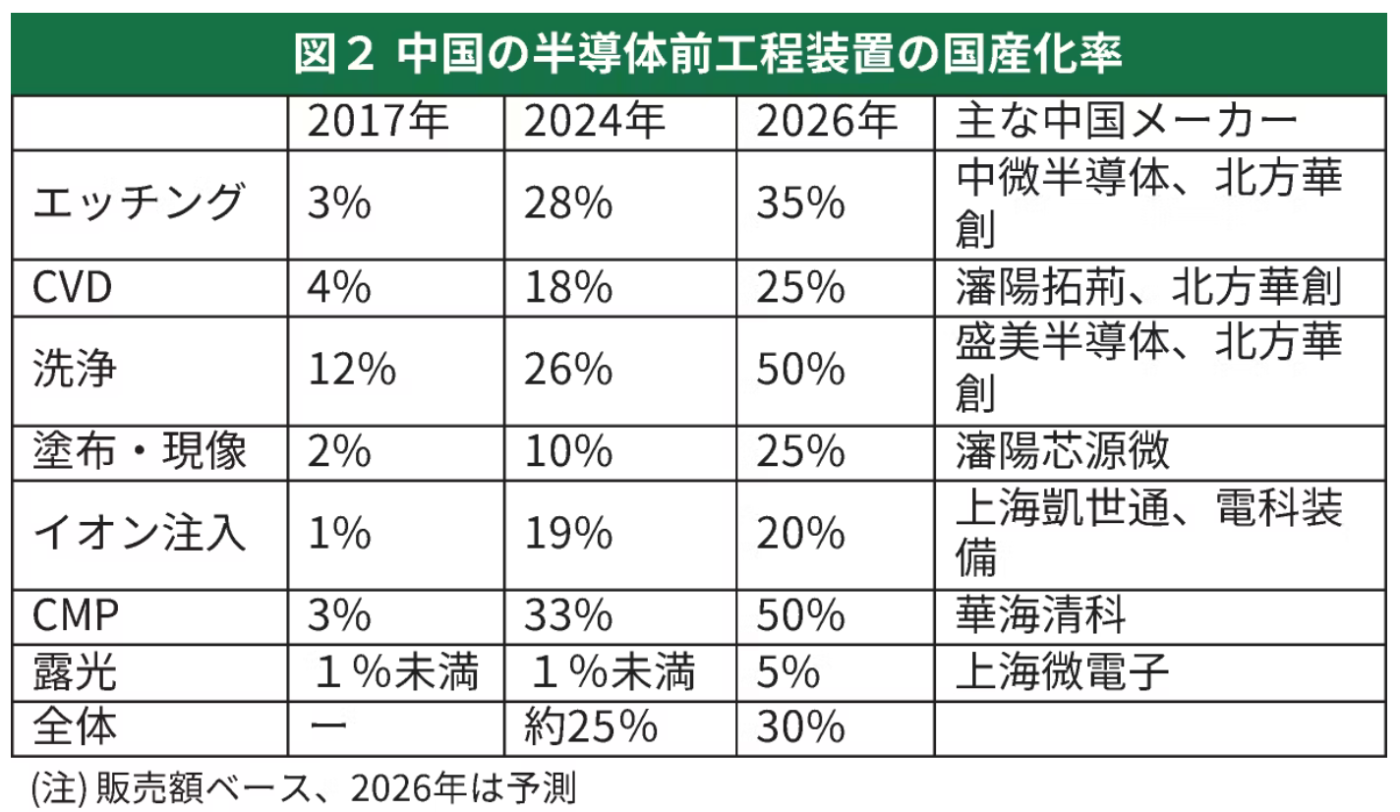
https://bizgate.nikkei.com/article/DGXZQOLM215C7021082025000000
見出し:「急成長する中国の製造装置各社 日米大手のシェア奪う」
おい!!!!!!!!!話が違うやんけ!!!!!!!!!
と、思うのですが、それくらい急成長しています。シンプルにすごいですね。中の人は大変でしょう。
- 中国では米国との貿易戦争の影響でEUVが手に入らない。
- しかし、1世代前のDUVでの気合のマルチパターニングで7nmを量産まで持っていってる。
- 現在6nmとか5nmあたりを目指して開発してる。しかもEUVを中国内で開発しようと取り組む。
- SamsungやIntelの苦労を見てると、EUVを購入できたからといってすぐに量産ができるわけでなく。。2030年前半に追いつけるかどうかって印象を持つ。
これは先端ノードの話で、追いつけていないのは日本も同じ状況。ラピダスはEUVを買えたけど。
中国は最先端を目指す一方で、同時並行で今できることを最大限やっている。
- 成熟ノード
- ロジック半導体
- パワー半導体
- 光電融合系
このあたりのEUVが不要な市場において、シェアを取っていくと思う。
まとめ
貴重な機会をいただけてありがとうございました!
上手にまとめきれなかったです。
改めて見ても「あれやこれやあって面白いなあ」という思いは変わらず。
参考
講座
半導体人材育成とか積極的に推進しているようです。文科省がお金出してるみたい。
サイト
東京エレクトロンと日清紡のサイトがわかりやすいです。
Discussion