[2024年版] 姿勢推定技術の現在地 簡単まとめ! (2D/3D/骨格推定/骨格検出)
1.はじめに
姿勢推定(Human Pose Estimation, HPE)について、2024年現在でできることを簡単にまとめていきたいなと思っています。このあたりの情報は漁れば出てくるので、詳しい人に有益な情報を提供することができません。すいません。
各手法の原理まで考えるのでなく、概要を一通りさらってみたいというのが本記事の目標です。
(注:韓国のりをつまみにハイボールを飲みながら書いていますので、そのくらいのモチベということご了承ください。)
最初に姿勢推定というのはこんな感じのやつです。

画像から人のキーポイント(関節点や顔のパーツ)を抽出し、得られたキーポイントを繋げることで姿勢を推定します。
データセットのアノテーションによってキーポイントが変わってくるのですが、よく使われるCOCOデータセット(Common Objects in Context)のキーポイントは以下の17個を用いられます。
| キーポイント番号 | キーポイント名 |
|---|---|
| 1 | 鼻 |
| 2 | 左目 |
| 3 | 右目 |
| 4 | 左耳 |
| 5 | 右耳 |
| 6 | 左肩 |
| 7 | 右肩 |
| 8 | 左肘 |
| 9 | 右肘 |
| 10 | 左手首 |
| 11 | 右手首 |
| 12 | 左腰 |
| 13 | 右腰 |
| 14 | 左膝 |
| 15 | 右膝 |
| 16 | 左足首 |
| 17 | 右足首 |
ちなみに腰って書いてますが、正確には脚の付根のちょっと上辺りだと思います。
1.1 姿勢推定の目的
で、画像から人の姿勢を推定できて何が嬉しいの?
って言われると難しいのですが、
直接役に立つわけではなくて、人の状態やその時系列変化を理解する基盤技術として重要なのかと思っています。
ざっくりいうと、以下のような応用例があると思います。
姿勢推定の応用
- スポーツ分析
- ヘルスケア
- Vtuberなど、人と仮想現実をつなぐため
- 映像産業(人の動作をキャプチャして3Dモデルを動かしてみるとか?)
- 監視、セキュリティ(やばそうな行動を検知する、未然に防ぐ)
- 暗黙知の明文化(職人さんの動きを保存する)
- 歩様認証とか?
これらは姿勢推定だけで実現できるわけではなくて、姿勢推定技術を使って実現するようなイメージです。
1.2 参考-関連技術
関連する技術として、指の検出や人の顔の検出や動物の姿勢推定などがあります。

ここでは"人の姿勢"に絞った話なので割愛します。
2.姿勢推定の分類
姿勢推定の流れとしては、超シンプルに以下の流れです。
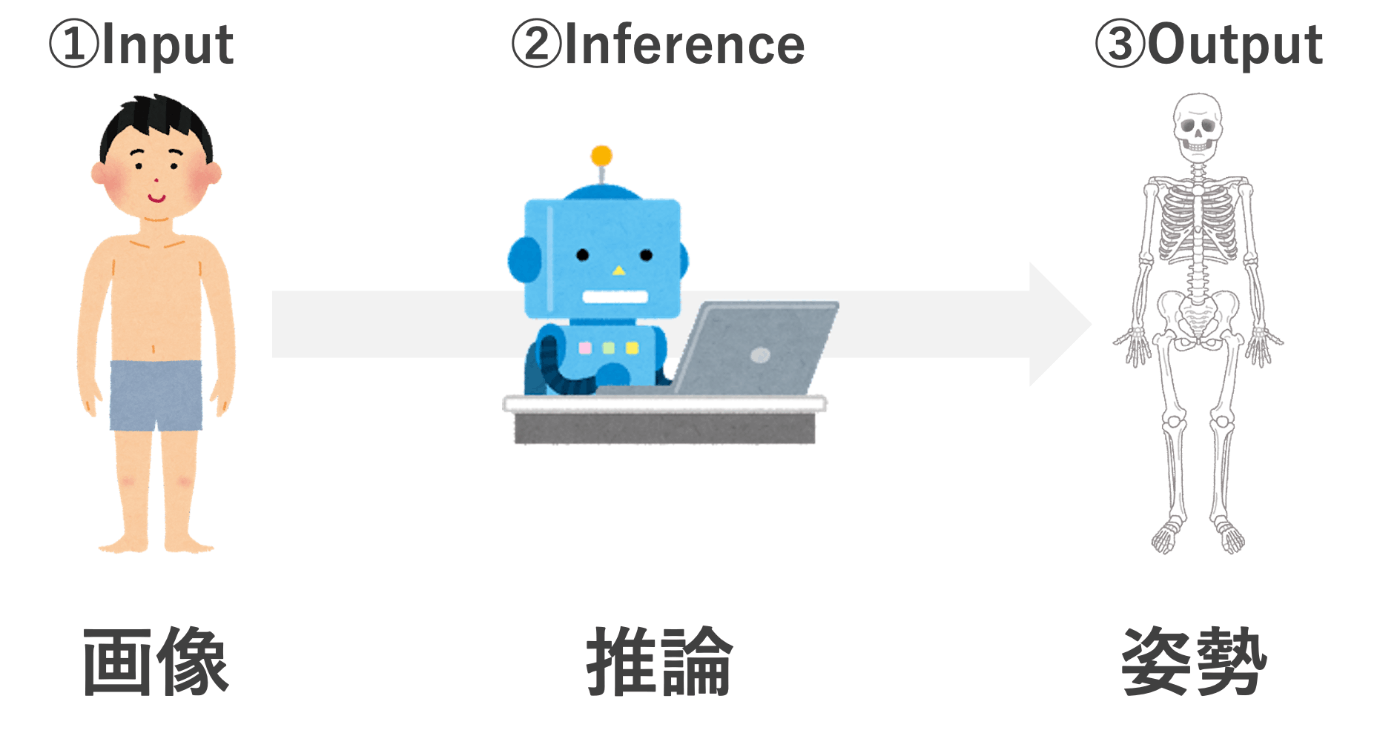
姿勢推定には色々あるのですが、分類するために
-
どのような画像を入力して
-
どのような推論手法で
-
どのような姿勢を出力するのか
という観点で見ます。
2.1 画像の分類
ここからは一般的な可視画像を前提とします。逆に一般的でないインプットについては長くなるので参考にまとめました。以下に書いてみます。
- 特定の状況下に限定した画像
- Multi-view
- アニメ画像
- 赤外線画像
- 動画
2.2 推論手法の分類
推論手法が色々複雑でして、多種多様な手法が提案されています。ベストなモデルが1つあればそれでいいのですが、計算コストであったり実務的な要因によって、何がベストかというのは状況に応じて変わってきます。なので色々知っておくといいなと思ったので色々調べました。
とは言うものの、細かい原理で分類すると無数にあるので粒度は粗めの分類です。
2.2.1 キーポイント検出手法-回帰とヒートマップ
大きく分けて、回帰方式とヒートマップ方式に分かれています。
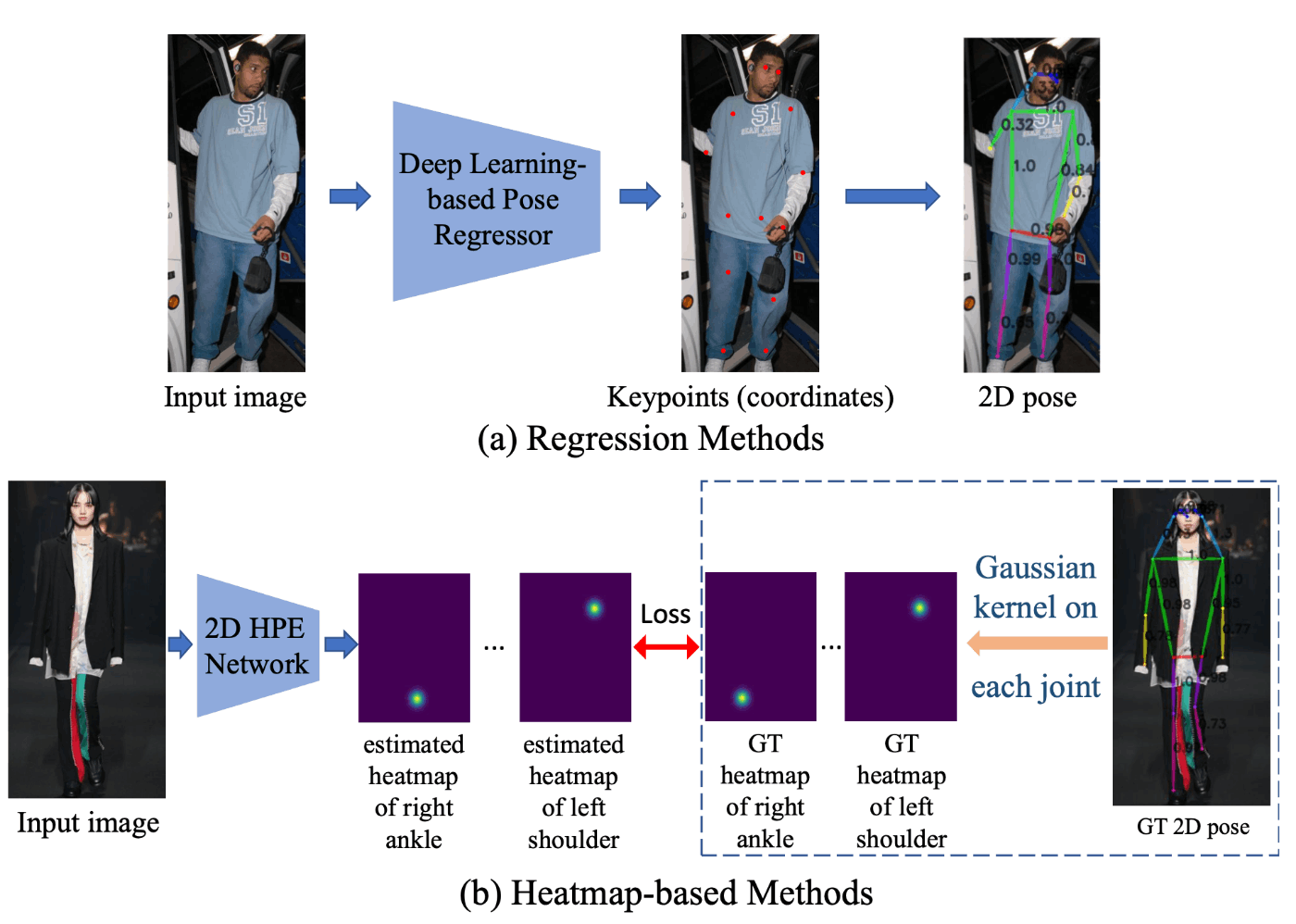
いきなり全部のキーポイントを推定する回帰方式か、各キーポイントの確率分布を出力してそれらをまとめるヒートマップ方式の2種類です。
それぞれの方式の比較をchatgptに表にまとめてもらいました。
| 特徴 | 回帰 | ヒートマップ |
|---|---|---|
| 出力形式 | 各関節点の座標を直接回帰 | 各関節点の存在確率を示す2次元ヒートマップ |
| メリット | - 出力サイズが小さい - メモリ効率が良い |
- 精度が高い - ピクセルレベルでの予測が可能 - サブピクセル精度を達成しやすい |
| デメリット | - 精度が低いことがある - サブピクセル精度を達成しにくい |
- 出力サイズが大きい - メモリ消費が大きい - 後処理が複雑になることがある |
| 適用例 | - 軽量モデル - リアルタイム処理が必要な場合 |
- 高精度が求められる場合 - ピクセルレベルでの詳細な予測が必要な場合 |
リアルタイム処理が必要な場合、回帰モデルがいいと書いてますが、ヒートマップ方式でも高速な手法がありますので、最近は基本ヒートマップ方式でOKという認識で良いと思ってます。
参考
ChatGPTなどの生成AIに姿勢を推定させるPoseGPTというのも提案されています。

2.2.2 複数人を姿勢推定する場合-トップダウンとボトムアップ
こんな感じで画像に複数人がいる場合、結構処理が複雑になってきます。

そのときのアプローチとしてトップダウンとボトムアップの2種類があります。

- トップダウン
トップダウンは以下のステップです。
- 画像内の人を検出する
- 人ごとに画像を切り取る
- 各画像に姿勢推定をする
- 画像をまとめる
やっていることはシンプルですが、人ごとに姿勢推定するので、100人いれば100回姿勢推定する必要があり計算コストが高いです。あと、最初に人検出するモデル(YOLOなど)を用意する必要があります。
- ボトムアップ
一方でボトムアップというのは、一気に姿勢推定する手法でして、以下のステップです。
- キーポイントを検出する
- キーポイントをつなぎ合わせる
のたった2ステップです。計算コストが低いメリットがある分、精度ではトップダウンに劣後します。
ボトムアップだと精度が下がる理由は2つほど考えられて、
1つ目は、トップダウンなら人のサイズは切り取られるので固定化されますが、ボトムアップでは遠い人や近い人など様々なサイズの人に対応する必要があります。近い人はいいですが、遠くて1000ピクセルくらいに潰れた人の姿勢を推定するのは難しいでしょうね。。
2つ目は、キーポイントを一気に検出するわけでして、2人いれば2つの左肩と2つの左肘があるわけです。
このときに、「左肩と左肘の組み合わせ方が2通りあるので、どうつなげるのが正解なん問題」が生じます。
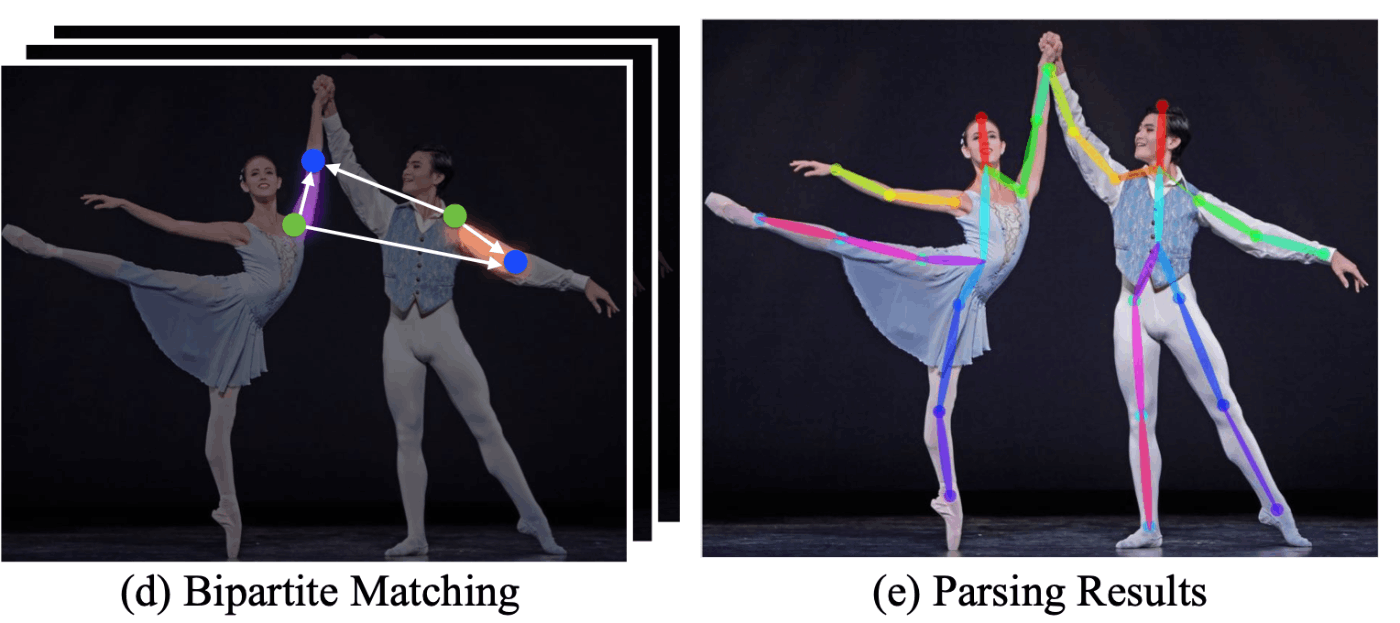
例によってChatGPTに比較させて表を出力します。
| 特徴 | トップダウン方式 | ボトムアップ方式 |
|---|---|---|
| アプローチ | まず人物を検出し、各人物に対して姿勢推定を行う | まず全ての関節点を検出し、それらを人物ごとにグルーピングする |
| 精度 | 高い(個々の人物に焦点を当てるため) | 比較的低い(関節点のグルーピングが難しい場合がある) |
| 速度 | 比較的遅い(人物検出と姿勢推定の両方が必要) | 高速(全ての関節点を一度に検出するため) |
| スケーラビリティ | 人数が多い場合に処理時間が増加する | 人数に影響されにくい(関節点検出が一度で済むため) |
| 適用例 | - 高精度が求められる場合 - 人物ごとの詳細な分析が必要な場合 |
- リアルタイム処理が必要な場合 - 大規模な人数を処理する場合 |
どちらを選択するかは状況次第です。そもそも1人を対象とした手法であればトップダウンでいいでしょうし、群衆の姿勢推定であればボトムアップのほうが高速です。
2.3 出力の分類
出力するのは姿勢なのですが、どのような姿勢を出力するのか種類がいくつかあります。
2.3.1 2D-Poseか3D-Poseか
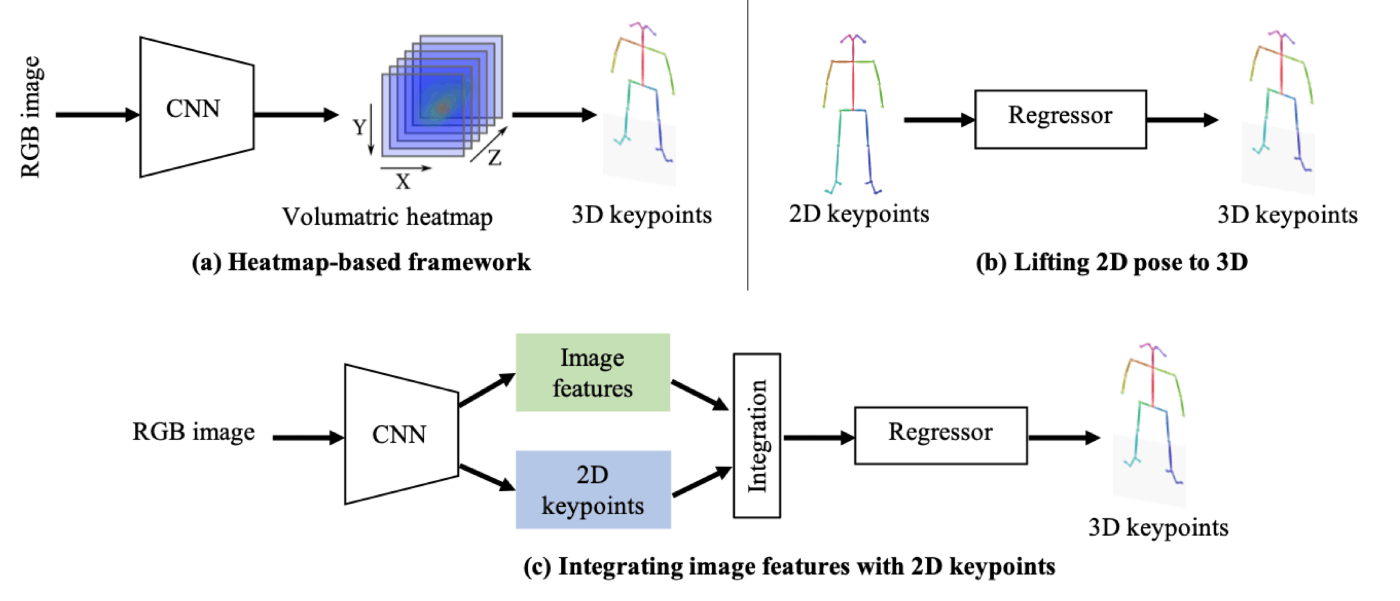
ここまでの姿勢の出力結果は2次元の姿勢でした。人は奥行きがあるので、3次元の姿勢を出力したいときがあります。
このときに様々なアプローチが考えられます。
直接3DPoseを出力するモデルなのか、2DPoseの情報から3DPoseに変換(lifting)するモデルの2種類です。liftingの仕方でも2種類あって、ざっくり表にするとこんな感じです。
| No | 手法 | プロセス | メリット | デメリット |
|---|---|---|---|---|
| 1 | 普通の2DPose | 画像→2DPose | ただの2D-Pose | |
| 2 | 直接3DPose | 画像→3DPose | - 画像から直接3Dポーズを推定できる - 3D空間情報を直接取得可能 |
- 計算コストが高い - 大量の3Dアノテーションデータが必要 |
| 3 | 2DPoseから 3DPose |
2DPose→3DPose | - 2Dポーズから3Dポーズを推定できる - 3Dアノテーションデータの要求が少ない |
- 2Dポーズの誤差が3D推定に影響を与える |
| 4 | 2DPose+特徴量から 3DPose |
2DPose+特徴量 →3D-Pose |
- 2Dポーズと画像情報の両方を利用 - 3Dポーズの精度が向上する |
- 計算コストが増加 - 実装が複雑になる可能性がある |
2.3.2 3D-PoseからMeshを出力する
3D Poseをなんかしらの手法で推定できたら、そこからさらにMesh(3角形がいっぱいあるやつ)にまで拡張することができます。これをどのように利用するのかあまりわかっていませんが、見栄えがよくなるのが嬉しいですね。

2.3.3 姿勢を分類する
姿勢がわかりましたが、それで終わりだと人が見ても理解しにくいです。
結局のところ、**どのような姿勢をしているの?**っていうところまで分類してくれると、人が理解しやすいです。
そのために手法が2つあって、
- 画像から姿勢を推定し、姿勢をさらに分類する
- 画像からいきなり分類したものを出力する(画像分類)
後者の場合、姿勢推定は必要ありません。
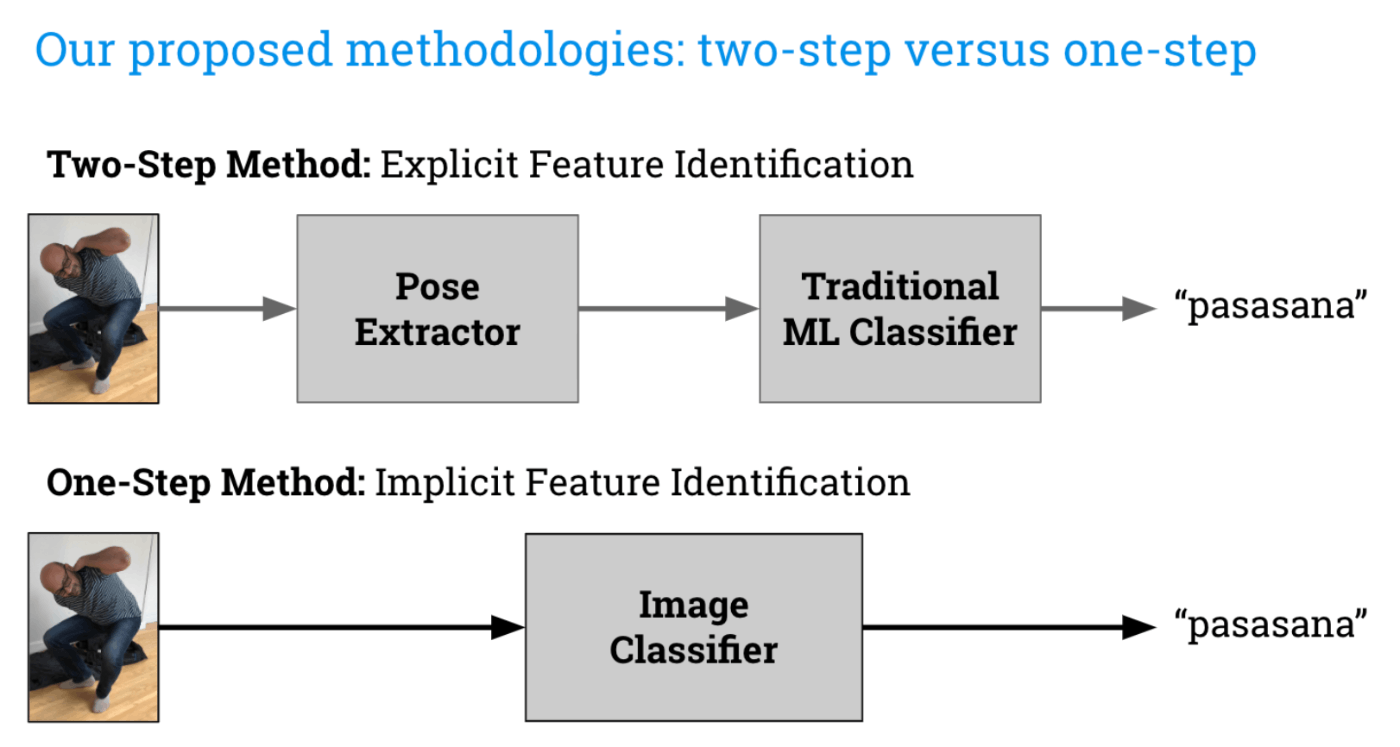
こちらはヨガのポーズを分類する手法です。ちなみにpasasanaは座って瞑想するときの輪縄のポーズ(Noose Pose)だそうです。
2.3.4 姿勢情報から行動を説明する
前と同じくPoseGPTの論文です。今度はトップダウンで姿勢推定した画像をGPT4Vにインプットして行動や服装や姿勢を説明させています。
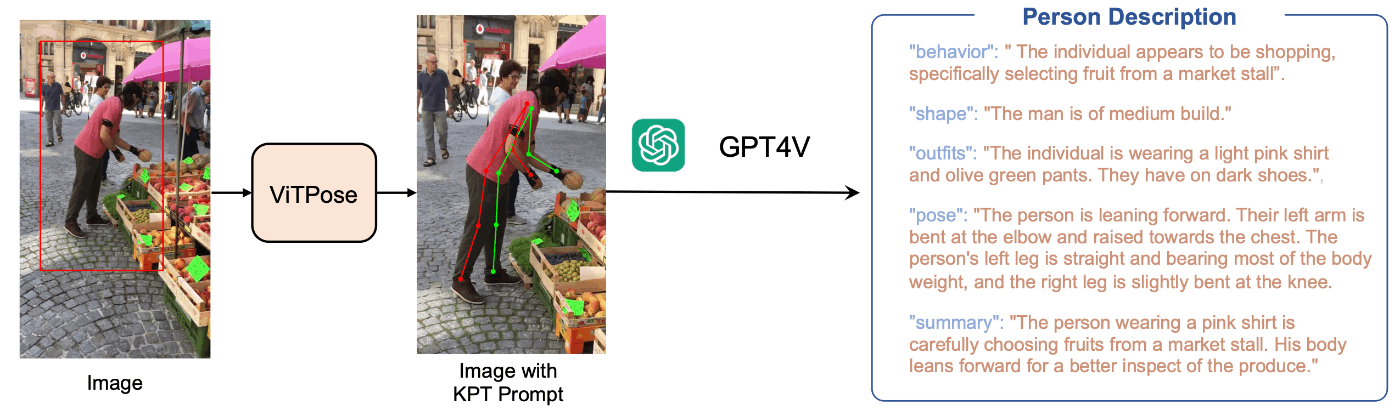
画像とその説明が英語でセットになっていると、TOEICのリスニングの大問1みたいすね。
よく考えると姿勢情報をインプットしなくても、画像のみでこれくらいなら出力できそうな気がするのですが、どうなんでしょう?直感で適当なこと言ってすいません。
ただ、スポーツなどのフォームで、理想的な姿勢と自分のフォームがどれくらい違うのかなどGPT4Vに出力してもらえると面白いかもと思いました。
2.4 参考.状況を絞ったり、インプットを可視画像から変えてみる
2.4.1 多視点画像(Multi-view)の姿勢推定
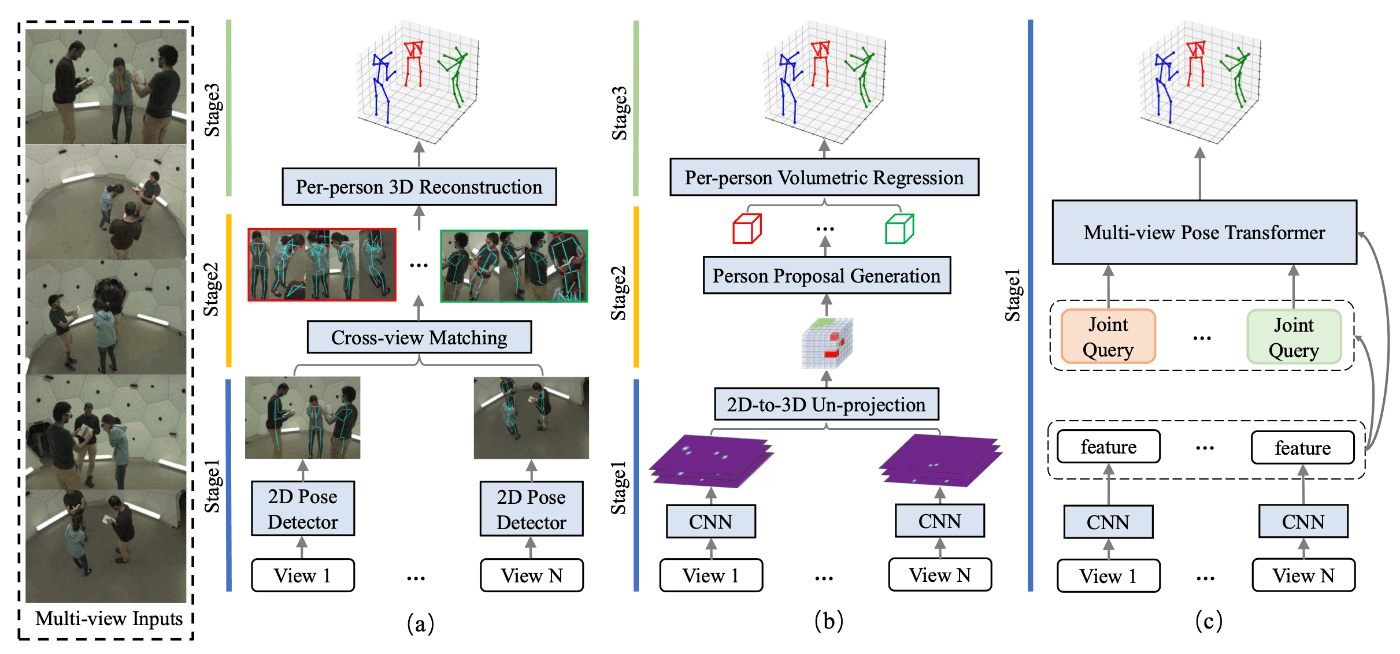
多視点画像から3D-Poseを推定する論文です。手法としてだいたい以下3種類があって、本論文は(c)を採用しています。
(a)reconstruction-based:各視点から得た2D-Poseをインプットして、3D-Poseを出力する
(b)volumetric representation based:各視点から得た深さ情報ありのヒートマップをインプットして、3D-Poseを出力する
(c)direct regression problem:各視点の画像の特徴量をインプットして、一気に3D-Poseを出力する。
屋内防犯カメラや逃走中など、カメラ台数が多い場合に使えそうですね。
2.4.2 状況を限定した姿勢推定
どんな可視画像にも使えるモデルではなく、特定の状況に特化したモデルのほうが高い精度を達成できそうです。
ここではベッドで寝ている人の姿勢推定を紹介します。
ちなみにベッド内の姿勢推定の研究が結構あって驚いたのですが、イントロを見る限り病院で使うことを推定していて、患者の行動を評価することを目的にしているようです。これで睡眠障害や睡眠時無呼吸症候群などの診断を支援することができるようです。
非侵襲で取れるデータなんていくらあっても困らないからいいですね。病院のみならず家庭でも、姿勢情報のみ送信すればプライバシーを保たれたまま診断できそうです。睡眠アプリやスマートウォッチの情報あまりあてにできずに使わなくなったので、勝手に情報持ってこれそうなこちらの研究に期待したいです。

この研究ではベッドに覆われている情報では可視カメラのみではさすがに厳しいだろうということで、遠赤外線カメラも用いて2つの情報で姿勢推定しています。というか寝るときは暗くするので可視カメラでは厳しいのでは?
この他では暗い状況での姿勢推定の論文など、状況を限定したものはたくさんあります。

2.4.3 赤外線カメラ画像を用いた姿勢推定
先程のベッドの例のように、人の赤外線カメラ画像を用いても人のシルエットを得ることができるので姿勢推定できそうです。
人は体温を持っていて勝手に赤外線を放射してくれるので、光源がない夜間などにも利用可能ですね。

2.4.4 2次絵の姿勢推定

Vtuberのポーズから別のVtuberのPoseにスタイルを変更したいときとかに使えるかもですね〜。最近はPoseからアニメ画像を生成するAIも流行ってるみたいですし。
2.4.5 動画の姿勢推定
動画というのは画像の連続なわけでありまして、画像の姿勢推定モデルを各フレームに対して行えばそれでいい話ではあります。
しかしながら、画像間で同じ人がどのように動いているのかをトラッキングしたいときなどは単純な画像の姿勢推定モデルでは実現が難しいです。
動画には動画のモデルが必要になってきます。2つ紹介します。
1つ目はUCバークレーの「Humans in 4D: Reconstructing and Tracking Humans with Transformers」という論文です。Githubもあっていいですね。BERTのように特定のフレームを隠して推論させるという手法で学習させるようです。

浅田真央もくるくる回ってますね。
2つ目は人の姿勢に限らず、移動するものを追跡してくれるOmniMotionというやつです。

動画をどうやって画像に落とし込むかっていうところでセンスが出ます。見栄えがいい画像を作るって結構大事ですよね。論文のタイトルも「Tracking Everything Everywhere All at Once」と強気です。
2.4.6 何でもできるやつ
ここまでは、多種多様なモデルを使って、
1. 画像→2D-Pose→3D-Pose→Mesh→姿勢分類
2. 動画→トラッキング
というタスクを実装してきました。
これに対して、何でもできる強いモデルが1つあればよくないかという強者の考えもあると思います。
というのも、人間の動作には様々な物理的な制約があって、人間の動きの物理的な制約と時間的な制約を理解したモデルを作れば、あとはそれを微調整(ファインチューニング)するだけで行動を説明したりMeshを作ったりできるはずです。
それを実現したのがMotionBERTです。
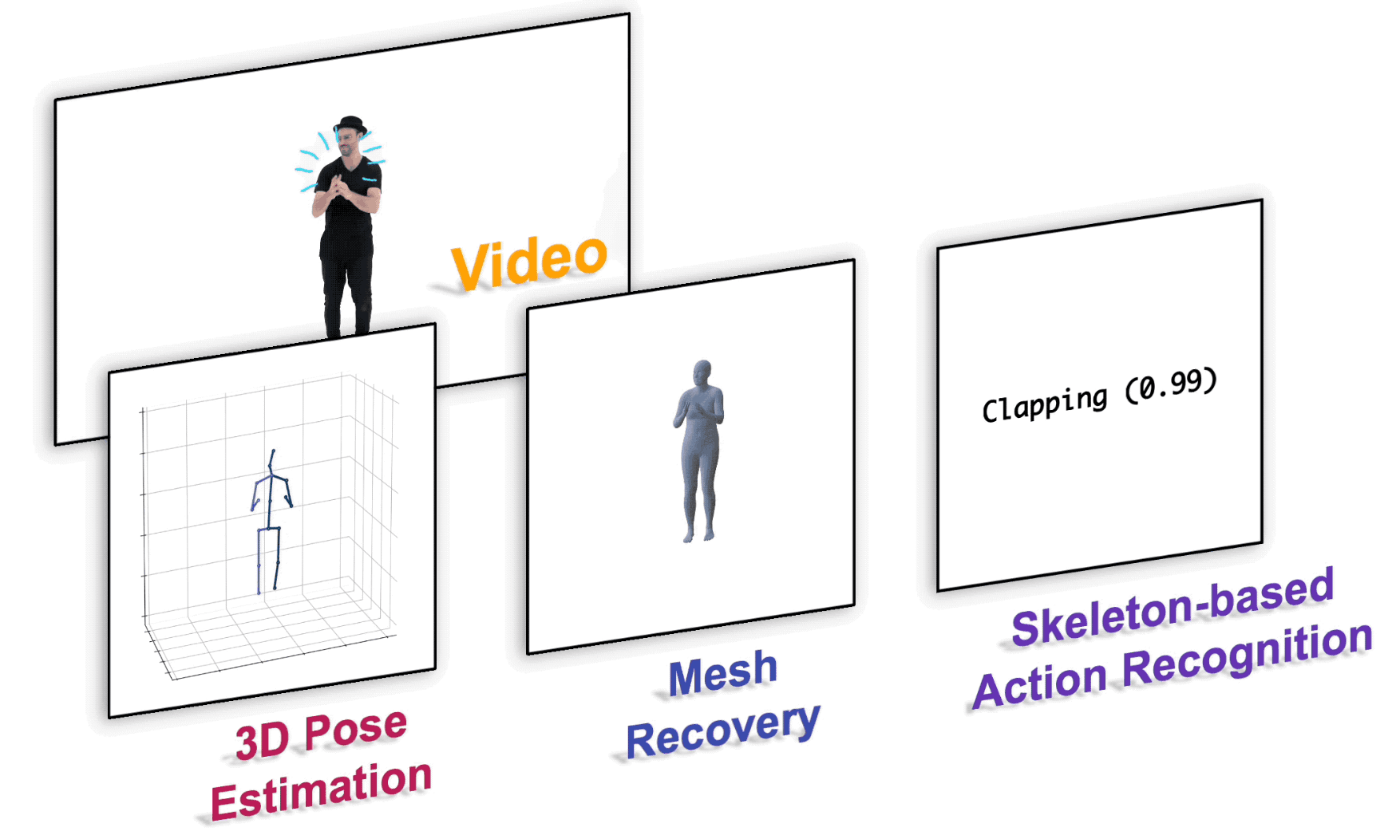
ちなみにこのモデル、**人の3D-Pose推定と人の行動認識でSOTAになっています。**ちゃんと精度も出るんか〜い。
2.4.7 (参考)物体検出モデル
最後に参考までに物体検出モデルも紹介しておきます。
トップダウンモデルを利用するには人検出モデルを使う必要がありますし、物体検出モデルでも姿勢推定をできたりするので。
YOLO-X

物体検出といえばYOLOシリーズですが、その中でもYOLO-XはApache2.0という商用でも使いやすいライセンスなので記載します。こちらのモデルは姿勢推定できないです。トップダウンモデル用の人検出として活用できますね。
他方、YOLO-v8やYOLO-Poseなどは姿勢推定できますが、GPLライセンスなので使いにくいですね〜。
Detectron2

facebook-researchのDetector2です。こちらもApache2.0ですね。
物体検出もできますし、姿勢推定もできますし、ピクセルベースのセグメンテーションもしてくれる最強モデルです。Colabで簡単に試せるのも嬉しいポイントです。
3.モデルまとめ
ここまで姿勢推定の考え方を言ってきましたが、紹介してこなかったやつでもかなりいい感じのモデルがもあるので、一つの表にまとめました。
詳しくはpapers with codeをご覧ください。
| 名前 | 画像 or 動画 |
トップダウン or ボトムアップ |
2D or 3D |
Github リンク |
コメント |
|---|---|---|---|---|---|
| mmPose | なんでも | なんでも | 2D/3D | リンク | 色々なモデルが使えるプラットフォーム。 まずはこれを使う。 |
| ViTPose | 画像 | トップダウン | 2D | リンク | 複数のデータセットでSOTA。 transformer強いすね。 |
| DEKR | 画像 | ボトムアップ | 2D | リンク | HRNet系のやつです。 2021のモデル。 探せばもっといいのあるかも。 |
| MotionBERT | 画像/動画 | - | 2D/3D | リンク | |
| STCFormer | 画像/動画 | - | uplifting | リンク | 2DPose→3DPoseに変換するやつ |
4. 結論
- Transformer強し。
- 初手mmPose。
- 結局のところファインチューニングしやすさ大事。
- あとcolabで論文実装手法を公開してくれる人ほんとに感謝しています。
Discussion