dbt事始め② with Snowflake


一回目はこちら
参考・・・というか、こちらをテキストに色々やってみた次第です。クラメソさんほんと偉大
今回はここから(自分でModelを開発する(そしてデプロイ))
Modelを開発して、デプロイしてみる
ブランチを切る
左上の「+create_new branch..」 をクリック

適当なBRANCH NAMEを入力して、「Submit」
成功すると、ブランチ名が「branch: add-customers-model」
Modelファイルを作成する
では、sourceのファイルは、BigQueryのPublicデータベースで公開されているサンプルデータ?を用いていたので、Snowflakeでやるなら・・・・
snowflake_sample_data.tpch_sf1からcustomer, ordersのテーブルをソースファイルとして、変更をしてみました。
with customers as (
select
c_custkey as customer_id,
c_name as name,
c_address as address
from snowflake_sample_data.tpch_sf1.customer
),
orders as (
select
o_orderkey as order_id,
o_custkey as customer_id,
o_orderdate as order_date,
o_orderstatus as status
from snowflake_sample_data.tpch_sf1.orders
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.name,
customers.address,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
こちらを dbt run をすると、Model:customerが実行され、Snowflake上にViewが作成されました。
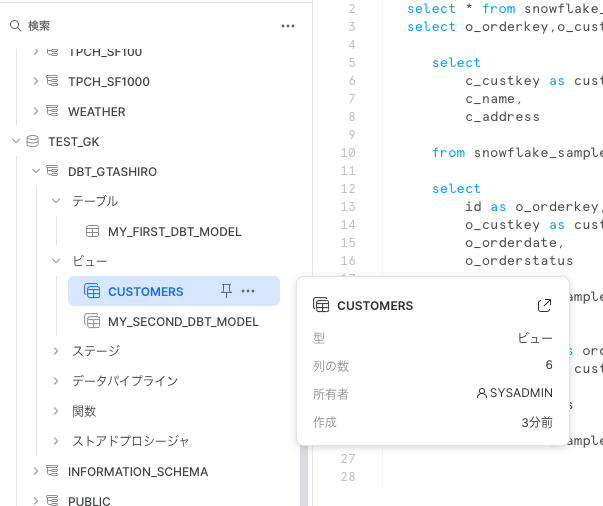
データをプレビューすると
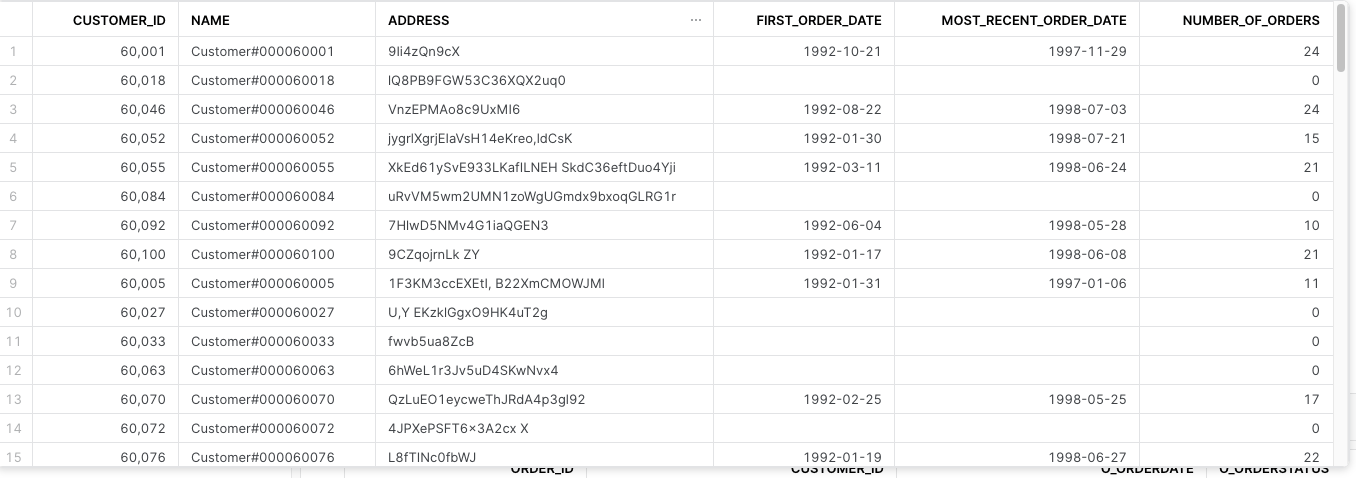
のようになりました。
生成するモデルの種類(テーブル/ビュー)を指定してみる
dbtはDWH側に生成するモデルの種類を指定できます。
| type | 補足 | |
|---|---|---|
| view | default | |
| table | ||
| ephemeral | 一時的 | モデルはデータベースに直接組み込まれていませんが、代わりに共通のテーブル式として依存モデルに取り込まれます。 |
| incremental | 増分追加 | モデルは最初はテーブルとして作成され、その後の実行で、dbtは新しい行を挿入し、変更された行をテーブルに更新します。 |
設定ファイルで指定する
models:
jaffle_shop:
+materialized: table
example:
+materialized: view
ここの意味は、jaffle_shopは、基本、tableでモデルを作る
exampleの配下は view で作るという意味になります
※dbtのモデルはデフォルト viewで作成
Modelファイルに直接記述しての指定
も可能とのこと。
上記では、 dbt_project.yml で指定したが、
直接、models/example/my_first_dbt_model.sqlに記載するでも良くて、ファイルに直接書く方を優先させるそう

SQLの先頭にこのよう記載するとのこと
ファイルを save して、 dbt run --full-refresh する。
--full-refreshをつけないと、作り変えにはならないらしい・・・

↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
--full-refresh をつけると消えるぽい

Modelを分割する
先程の customersは、WITHがいっぱいある・・・・これでも問題はないけど、dbtを使うメリットとしては、ここをスッキリ書く、再利用可能な状態で・・・など可読性と管理がしやすくなるので推奨されてるっぽいです。
WITH句にかいていたModelを抜き出して、新しいModelファイルを作る
情報のソースを明示する
select
c_custkey as customer_id,
c_name as name,
c_address as address
from snowflake_sample_data.tpch_sf1.customer
select
o_orderkey as order_id,
o_custkey as customer_id,
o_orderdate as order_date,
o_orderstatus as status
from snowflake_sample_data.tpch_sf1.orders
これで、ソースデータからの取り込みを記載してみる
with customers as (
select * from {{ ref('stg_customers') }}
),
orders as (
select * from {{ ref('stg_orders') }}
),
customer_orders as (
select
customer_id,
min(order_date) as first_order_date,
max(order_date) as most_recent_order_date,
count(order_id) as number_of_orders
from orders
group by 1
),
final as (
select
customers.customer_id,
customers.name,
customers.address,
customer_orders.first_order_date,
customer_orders.most_recent_order_date,
coalesce(customer_orders.number_of_orders, 0) as number_of_orders
from customers
left join customer_orders using (customer_id)
)
select * from final
{{ ref('hogehoge') }} と記載することで、
- そのModelの結果を引き継ぐことができる
- 依存関係が明確になる
- リネージュに記載される!
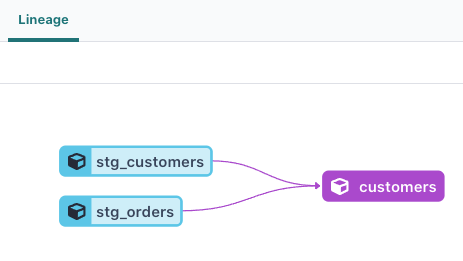
dbt run --full-refresh をして実行します。

Tableに
- CUSTOMERS
- MY_FIRST_DBT_MODEL
- STG_CUSTOMERS
- STG_ORDERS
Viewに
- MY_SECOND_DBT_MODEL
という形になりました
Modelをテストする
テストの設定ファイルを作成する
dbtは、データのテストもできます。
フィールドで
- unique
- not_null
とかができます。
DWH製品では、SQL文では、各種制約が効かないことが多いですし、各フィールドの検証が走らせることができます。
例としては、JOINする際にIDがちゃんとユニークであるか?などもでき、そこでデータJOINの品質などを担保することができます。
version: 2
models:
- name: customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_customers
columns:
- name: customer_id
tests:
- unique
- not_null
- name: stg_orders
columns:
- name: order_id
tests:
- unique
- not_null
- name: status
tests:
- accepted_values:
values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
- name: customer_id
tests:
- not_null
- relationships:
to: ref('stg_customers')
field: customer_id
テストを実行する
テストは、dbt test を実行する。

今回は、テストが失敗しています
※というのも、BigQuery用のデータをもとにしたテストなので・・・・厳密にテストは書いていないので
- name: stg_orders
description: This model cleans up order data
columns:
- name: order_id
tests:
- unique
- not_null
# - name: status
# tests:
# - accepted_values:
# values: ['placed', 'shipped', 'completed', 'return_pending', 'returned']
↑コメントアウトしてみた
description でコメントも残すことができる・・・・んだけど、yamlファイルの「#」でコメント書くこともできるし・・・・うーん・・・
色々終わったら、Commitして、mainブランチにマージして終わります。
Projectをデプロイ環境にデプロイする。
homeに戻り、Deployment Environments > から、 「create a new one now」をクリックします

デプロイのためのセッテイングを行います。

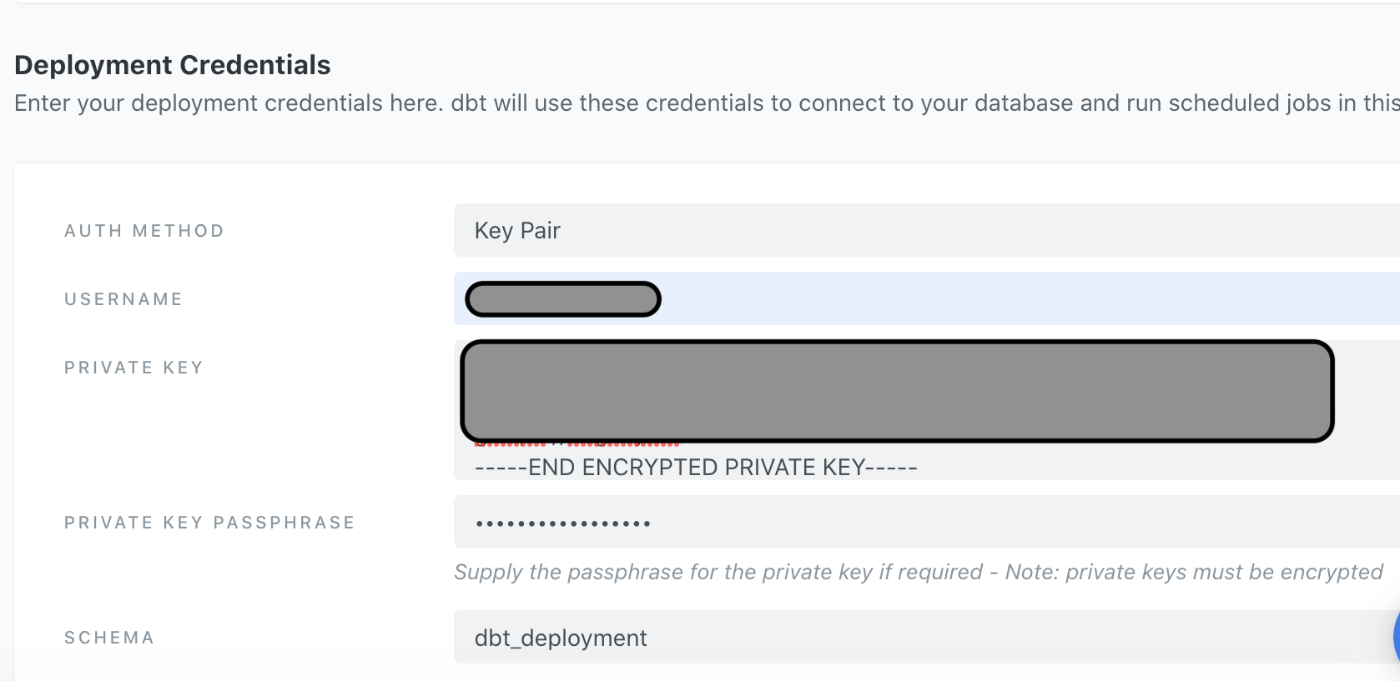
Deployment Credentialsを設定。
Key Pairでやります
USER NAMEは、適宜・・・
Jobを作成する
dbt cli と dbt Cloudの最大の違いはここにあるとおもいます。
定期的に実行するJobを組むことができます。
このあたりは、各種ワークフローエンジンの役割かもしれません・・・いい具合の組合せは今後の課題かなと思ってます。
Environments GK_Deploy202202 から、「New Job」を選びます。
NAME : 適宜
ENVIRONMENT:適宜(今回は、GK_Deploy202202)
DBT VERSION:↑ENVIRONMENTを選んだら出てきた値をそのまま
コマンドで、
dbt run
dbt test ← を add command
RUN SCHEDULE? : こちらのチェックを外した(テストなので)

Saveして、保存
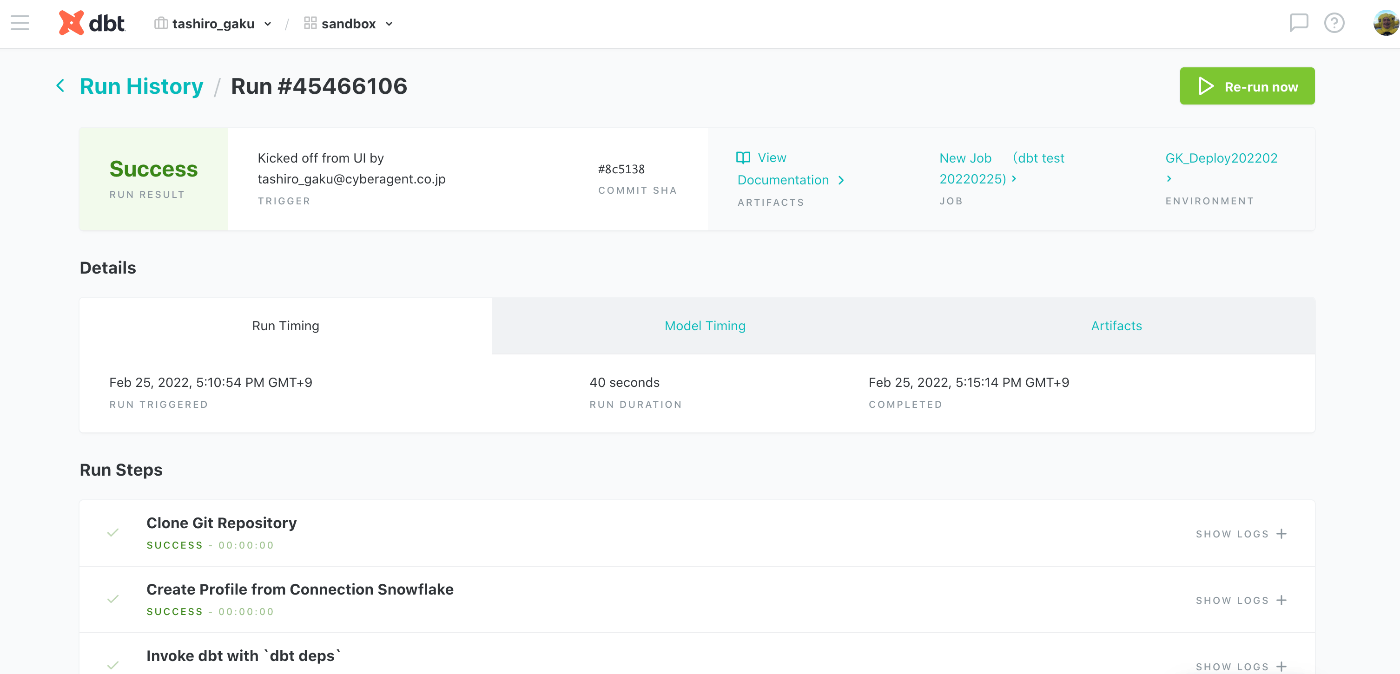
その後、「Run now」で実行してみる。

動かしました
Discussion