【Medium】Key Trends in Modern Data Stack
がく@ちゅらデータエンジニア です。
※2022年9月よりちゅらデータ株式会社にJoinしました
データエンジニアリングな話題などをMediumで毎朝、サジェストされるんですが、これちゃんと読んでいかんとなーということで、読んだメモなどを残しておこうと思って書いて行こうと思います。
概要
今日はこちら
「モダンデータスタックの主要トレンド」
Modern Data Stackは爆発的な成長を遂げている。世界的に見るとベンチャーキャピタルは、この2年間で120億ドルを投資している。
その中でも、Snowflakeは超大型IPOを果たし、現在は年間10億ドルの収益を上げている
クライド技術により、SaaSが増えました。そして、Modern Data Stackのおかげでエンドユーザ向けにパーソナライズされたサービスを構築できるようになりました。
In future, company of any size — small, medium or enterprise will not just be a software driven but also data driven, especially in decision making
(今後、どんな規模の企業でも意思決定がデータ主導になっていく)
- クラウドの採用(特に、Storage!)とSaaSの成長で、データは指数関数的に増加している。IDCによると2025年までに175ゼタバイト(=175兆ギガバイト)のデータが生成されると予測
- 今後も年率23%増の予測。
- Modern Data Stackは、クラウドデータウェアハウスを中心とした、クラウドネイティブツールの集合体で構成
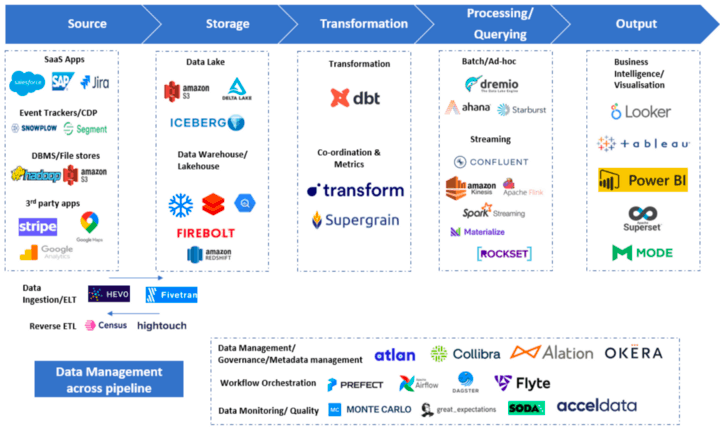
データエコシステムが成熟しつつある。
- データの取り込み( FivetranやHevodata)
- クラウドデータウェアハウス(SnowflakeやBigQuery)
- データの変換(dbtやDataform)
- インサイトの取得(Prosessing/Querying) AIやML
- リバースELT(hightouch, Census)
- データマネージメント、ワークフローオーケストレーション、データ観測性、データクオリティ(Atlan、Prefectなど
A.データストレージ技術の根本的な転換がイノベーションの原動力
A. Fundamental shift in data storage technologies is main driver of innovation
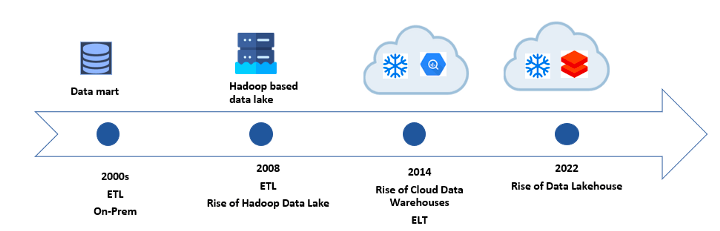
- 2014に登場したクラウドデータウェアハウス(SnowflakeやAmazon Redshift、BigQueryも・・)が、Modern Data Stackの興隆の変曲点
- ETLからELTへ変わってきている
- ELツール(Fivetranなど)とTツール(dbtなど) が生まれてきた
データレイクとデータウェアハウス
データレイクの長所と短所
- ◯ あらゆる種類の生データを保存するのに適している
- ○ 機械学習の実施に素晴らしいツール
- X BI/SQLはやりにくい
データウェアハウスの長所と短所
- ◯ 構造化データに最適
- X 機械学習のサポートは良くない
データレイクハウス
データレイクとクラウドデータウェアハウスの長所を統合。
SnowflakeのData CloudとDatabricksのData lake houseは、このイノベーションのトップランナー
(田代コメント)
SnowflakeにDatalake層(スキーマ)を作って、そこに全部ぶっこめばいいと思ってる。
B.データで何ができるか データプロダクトの台頭
B. What more I can do with data — Rise of data products
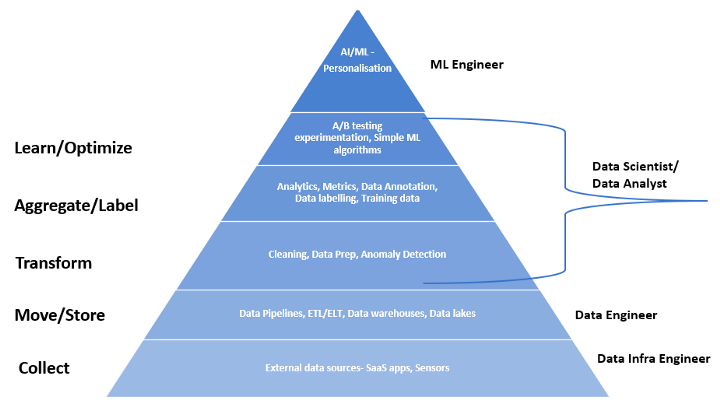
出典:データサイエンスニーズの階層化
- データの取り込み、保存、処理のための技術スタックはかなり進化して、だいぶ整ってきている
- 近年は、リアルタイムストリーミングや機械学習、データプロダクトに焦点が当てられるようになってきた
データを活用したデータプロダクトの例
→ Netflixのパーソナライズド・レコメンデーションシステム
C.リアルタイム/ストリーミングパイプラインの必要性が主流になる
C. Need for real-time/streaming pipeline will become mainstream
- 現在の主流は、バッチ処理ベース
- 現在リアルタイムストリーミングでの例としては
- Netflixのパーソナライズド・レコメンド
- Uberのダイナミックプライシング
- オンライン詐欺の検出
- リアルタイムデータメッセージングとストリーミングパイプラインのコストは下がってきている
- しかし、その開発・管理は、バッチに比べるととても複雑
- リアルタイムデータパイプラインなどに関わるデータスタックとしては
- Kafka
- Apache Spark
- ClickHouse - リアルタイムデータ分析
- Meterialize、Apache Flink - リアルタイム処理
- Amazon Kinesis, Google Pub-Sub : クラウドホスト型ストリーミングエンジン
(感想)
クラウド技術、その中でも特に、クラウドストレージ技術が肝になって、データイノベーションのきっかけになったと思う。
そこのコスト(値段とメンテナンスに係る手間)が激減したのでそれ以外の「やりたいこと」に力を避けるようになったってのが大きいと思う。
「C.リアルタイム/ストリーミングパイプラインの必要性が主流になる」
については、ちょっと懐疑的(特に日本において)
ただ、データイノベーションはすごい速度でなされているので、リアルタイム処理ってのもどんどん浸透していくかも・・・とはおもう。バッチ処理と変わらずできるように抽象化されていくだろうなぁとは思いますね
Discussion