【生成AI】拡散モデルの影の立役者「AdaLN」を語らせてくれ
はじめに
「最近の画像生成AI、論文読むのが追いつかないよ」と嘆いているのは私だけではないはずだ。
Stable Diffusion 1.5やSDXLが覇権を握っていた頃、私たちはU-Netの構造を数えないくらい見てきた。ResNetブロックがあって、CrossAttentionがあって……というあのお決まりの形だ。
しかし、時代は変わった。FluxやQwenImage、そして最近話題のZ-Imageなど、SOTA(State-of-the-Art)を叩き出すモデルたちは、こぞってDiffusion Transformers (DiT) ベースに移行している。U-NetからTransformerへのパラダイムシフトだ。
その中で、地味ながらも極めて重要な役割を果たしている技術がある。それが Adaptive Layer Normalization (AdaLN) だ。
今日は、数式を見ると蕁麻疹が出るという人でもわかるように、でもエンジニアとして知っておくべき「AdaLNの気持ち良さ」について、少し余談を交えながら語っていきたい。
なぜ普通のLayerNormじゃダメなのか
まず、基本に立ち返ろう。従来のLayerNorm(LN)は、入力されたデータに対して正規化(平均0、分散1にする処理)を行い、そこに学習可能なパラメータであるスケール(
ここで重要なのは、この
つまり、入力が「晴れた日の猫の画像」だろうが「サイバーパンクな夜景」だろうが、学習が終われば同じパラメータで正規化しようとする。これはいわば、どんな客が来ても同じ「いらっしゃいませ」しか言わない店員のようなものだ。汎用的だが、気が利かない。
AdaLNのアプローチ
対して AdaLN は違う。入力条件(Conditioning)に応じて、動的にパラメータを変えてくる。
拡散モデルにおける「条件」とは主に以下の2つだ。
-
時刻
t -
テキスト
y
AdaLNは、これらの条件を受け取って、「今のタイミングとこのプロンプトなら、こういう正規化をすべきだ」と、動的に
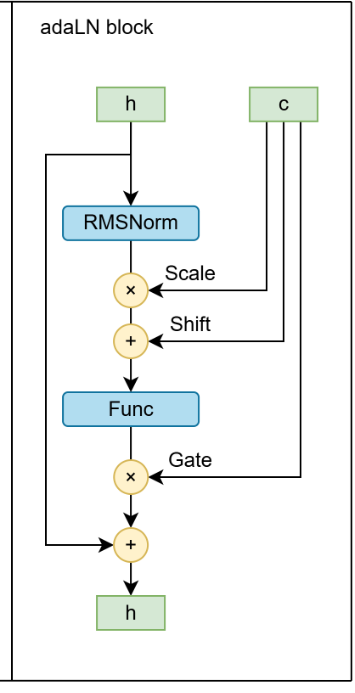
HDM - Home made Diffusion Modelsの技術レポートから取ったものだ。
実装と数式で見るAdaLN
多くのDiTモデルでは、以下のような数式で実装される。特に AdaLN-Zero と呼ばれる手法がデファクトスタンダードになりつつある。
コードで書くと、PyTorch風にはこんなイメージになる。
# mlp_adalnは時刻tやテキストyから、scale, shift, gateを予測するMLP
scale, shift, gate = self.mlp_adaln(condition)
# 正規化の適用
x_norm = self.layer_norm(x) * (1 + scale) + shift
# ゲートによる重み付けと残差接続
x = x + self.mlp(x_norm) * gate
ここで注目してほしいのが、ゲート(
この
ちなみに、このlayer_normはRMSNormである、これはLNの改善版と言われてる。計算コストが低くてパラメータは
実際のモデルでの採用例
最近のモデルの実装を覗いてみると、各社のアプローチの違いが見えて面白い。
-
Z-Image: シンプル・イズ・ベスト。単一のTransformerですべてを処理し、AdaLNの条件には時刻
t - Stable Diffusion 3 (SD3): こちらはDual Stream(画像とテキストを別々に処理)を採用。AdaLNには時刻とテキスト情報を足し合わせて突っ込んでいる。T5という巨大なテキストエンコーダを使っているため、テキストの影響力が凄まじい。
-
Lumina 2.0: 少し変わり種。シフト(
\beta

Stable Diffusion 3はClipの埋め込みをAdaLNで使用する。この図は論文から取ったものだ。
AdaLN vs CrossAttention:役割の違い
ここで一つの疑問が浮かぶ。「テキスト情報を入れるなら、CrossAttentionでいいんじゃないの?」と。
SD1.5時代はCrossAttentionが主役だった。しかし、AdaLNとは役割が明確に違う。
-
CrossAttention: 「局所的(Local)」 な制御。
- 「画像の右上に猫を描いて」といった、空間的な配置や特定のトークンと画像領域の対応付けを担当する。
-
AdaLN: 「大域的(Global)」 な制御。
- 画像全体のトーン、スタイル、あるいは「現在はノイズ除去の初期段階である」といった全体的なコンテキストを注入する。
例えるなら、CrossAttentionは「絵筆で細部を描き込む作業」、AdaLNは「部屋の照明やキャンバスの質感を調整する作業」に近い。最近のモデルは、この両方を巧みに使い分けている(あるいはAdaLNだけで済ませようとしている)のだ。
AdaLN-Zeroと「0初期化」の魔法
さて、ここからが少しエンジニア向けの深い話だ。
AdaLN-Zeroという手法では、学習開始時にゲートパラメータ
「重みを0にしたら学習が進まないんじゃないか?」
直感的にはそう思うかもしれない、私はそうだった。しかし、これが逆に学習の安定化に寄与するのだ。数式で勾配の流れ(Backpropagation)を追ってみよう。
1. 順伝播(Forward)
つまり、初期状態ではそのブロックは「何もしない(恒等関数)」。入力がそのまま出力される。これは、ResNetが深くなっても学習できる理由と同じで、勾配が素通りできることを意味する。
最初は単純なモデルとして振る舞い、学習が進むにつれて徐々に複雑なブロックが機能し始めるイメージだ。
2. 逆伝播(Backward)
では、
連鎖律を使って、入力
初期状態(
これが重要だ。勾配消失も爆発もせず、綺麗に下流へ情報が流れる。
そして、肝心の
この「最初は浅いネットワークとして振る舞い、徐々に深くなる」挙動こそが、巨大なDiTモデルを安定して学習させる鍵となっている。
おわりに
技術の進歩は速い。U-Netの職人芸的な構造に愛着を感じていた私だが、AdaLNを用いたDiTの「シンプルでスケーラブル」な美しさにも惹かれ始めている。U-Netの各ブロックは違う解像度を使う仕組みは結構有用だと思うけど、トランスフォーマーは大量のデータや計算を使えば性能が跳ね上がるのでこれからLLMと同じ流れが来るだろう。
特に、パラメータ数を抑えつつ効率的に条件付けを行うために、Dual Streamのような重厚な仕組みではなく、AdaLN一本で勝負する軽量モデル(Z-Imageなど)のアプローチは、今後エッジデバイスでの生成AI活用において重要になってくるだろう。
次に新しい論文が出たときは、「お、ここはAdaLNを使ってるな? ゲートの初期化はどうしてる?」なんて視点で見てみると、また違った面白さが見つかるかもしれない。
Discussion