畳み込み層モデルによる環境音認識
これは僕の最初の深層学習の実践です。Pytorchの本の練習もやったけどチュートリアルを行うと自分のプロジェクトは別物だろう。僕は言語について結構興味があるから録音データの処理について勉強したかった。
データ処理
前に言った本は三つのファイルで全部の活動ができましたからそのファイルを参考にした。一つはモデルを結成ファイル、二つはデータセットの処理と最後に学習(マイン)のファイルでした。ディレクトリはこんな風になります。
- models.py
- training.py
- dsets.py
録音データを画像として扱いたかったからスペクトログラムを変更して、そのあとメル尺度を使って、メルスペクトログラムを結成しました。Pytorchのメルスペクトログラム関数は色々なパラメータがある、複数のパラメータを試して最後は1x128x431次元のベクトルを得ました。
左辺の1はチャネル素である、例えばステレオは二チャネル数、一チャネル数はモノラル録音だ。その後テンソルはまだ正規化してないから全部の教師データの平均値と標準偏差を計算して、Pytorchの正規化関数を使った。
最初の段階
全部のデータ分析はJupyterNotebookで行う、一番試してやすい環境と思う。前に記すしたディレクトリは実行する時少し時間がかかるからあんまり便利じゃない。だから沢山調整している時、最初の段階、JupyterNotebookは非常に便利だと思う。
それだけじゃない、グラフを作る時も分かりやすいと思う。例えば、このプロジェクトを作っていた時、全部の学習ループやモデルは結成したけど過学習の問題が現れた。
過学習
過学習を解決為にデータ拡張を使いたかったけどどうすればいいのか全然分からなかった。データは画像として扱っていたけど大体のデータ拡張技術は使えない、フリップすれば時間がどうなるか、ろくなことにならないだろう。だから使った手法は画像を複数の部分を排除する。
それを実際どのようになる気になったからグラフを作るしかないだろう。その時もう一度JupyterNotebookを使ってコードを実行して、データ拡張の結果を見た後、良く理解出来た。
学習ループ
マインのファイルで学習が行う、ループについてあんまり話すところがない結構普通だと思う。だから学習のメトリックと損失関数について説明したいところがある。
損失関数
使った損失関数はCrossEntropyLoss、この関数はモデルの出力、ロジットテンソル、にSoftMaxをかけると一番高い確率を取ってその後ターゲットに比べる。だからモデルの最後の層はSoftMaxじゃない、普通の全結合層である、バッチx50次元のベクトルを出力する。
損失だけは良い分析が出来ないので他のメトリックを使う方がいいと思う。分類のタスクでは簡単な分析出来るメトリックは
- 正確率
- 適合率、推薦された数から幾つかは正しかった。
- 再現率、その種類数から幾つかが推薦された。
- F1score
適合率と再現率の調和平均を取った値はF1scoreといいます。問題によって、適合率の方が大事、けど他の場合再現率の方が優先されることがある。
モデル
色んな畳み込み層ネットワークを試した、その中から三つのモデルは目立つ。
- Resnet18、Pytorchの18層Resnetモデルの実行だ。
- 8層の畳み込みmaxpoolを使えない,avgpoolだけを使う、Resnet18のように。
- 4層の畳み込みモデルmaxpool使ってる。
画像の次元を減る為に、8層のモデルでストライド2畳み込みを使ってる、4層の場合ストライドの代わりにmaxpool層を使ってる。二つの方法は良い結果を出したけど、ストライドには少し精度が高い。
データ拡張
録音データは大体少ないからデータ拡張が必要になる。画像の場合色んな手術を使えるけど、録音んデータの場合全部は使えない、例えばフリップしたら時間の次元が逆になる、音は逆でしたら変になるでしょうね。だからクロップとマスクは使った技術だ。
例えば、ALEXNETはクロップを使って、ランダムだから新しいデータを結成出来た。マスクは画像の一つや複数の部分を排除することだ。
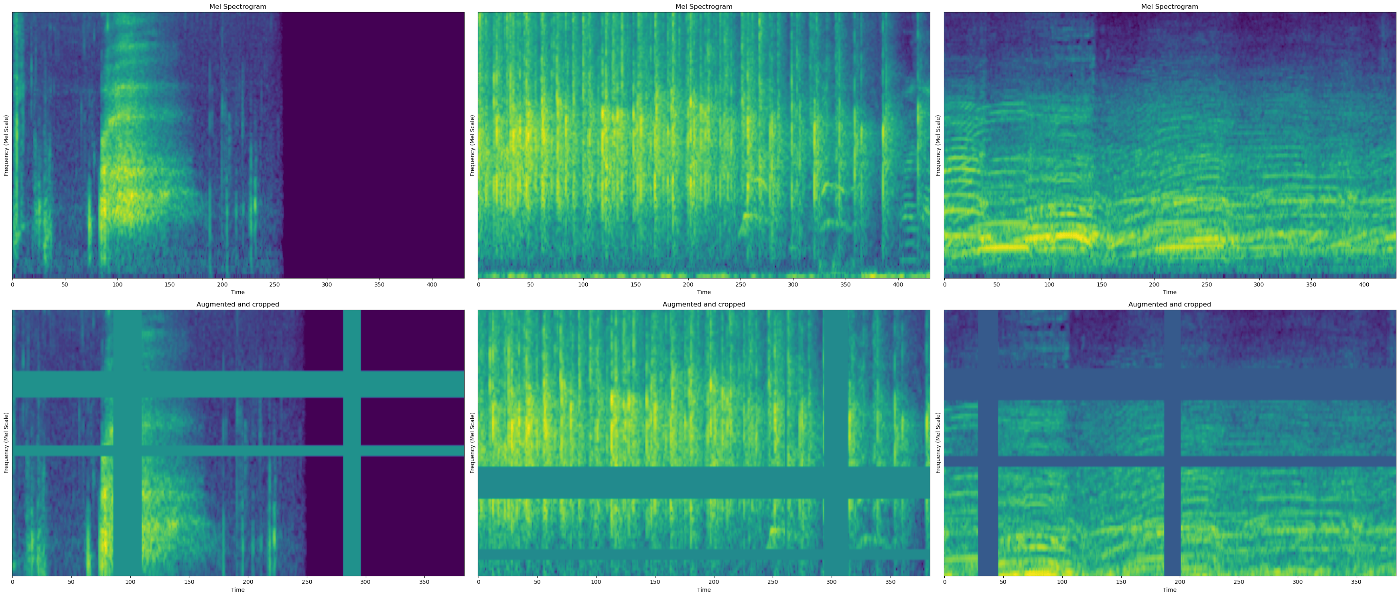
このように1600サンプル数から8000サンプル数までデータを作った。このデータ拡張はランダムだから過学習を対策として使える。もしランダム価値や関数を使う時、忘れなくシード値を決めてください。同じ結果を得る為にシードを決めよう。
次元
僕は他人のプロジェクトを参考にするときデータの次元が分からない場合が多い、データ次元を理解できない場合モデルの使い方も分からないから本当に大きいな問題になる。だからデータの次元について話したい。バッチサイズはテンソルのdim=0の部分になる、今は無視する。
最初のtorchaudio.load()のテンソルは普通のx次元テンソル、xは録音の時間とサンプルレートの掛け算だ。スペクトログラムの変化をかけた後、テンソルの形は1x128x431。
クロップの後テンソルは1x100x384次元になる。その後モデルは畳み込み層をかけて、チャネル数を増やしながら画像の次元を減っていく。全結合層の前に、4層畳み込みモデルの場合、テンソルの形は521x2x11。全結合層の後、ターゲットテンソルと同じように50次元のテンソルになる。
コード
コードは全部GitHubに登録された、model.pyファイルで色々なモデルが記されたけど、大体使えないからモデルのセクションで説明したモデルのみ良い結果出さない。GitHubへのリンク
Discussion