Transformers入門: 初心者でもわかる


Attention Is All You Need(注意機構に注目を)
問題設定:注意機構 に焦点を当て、翻訳の精度向上を目指す。この論文は近年、AI 分野に多大な影響を与えた画期的な論文であり、おそらく皆さんもご存知だろう。今回は、 この論文をスクラッチから実装 してみようと思う。ディープラーニングを習得する上で、論文を実際に実装することは非常に良い練習になると言われている。そのため、有名なこの論文を選択した。すでに多くの実装が公開されているので、質問や不明点があれば、簡単に解決できるだろう。
最初のステップは、もちろん論文を読むことである。この手法が登場する以前、 RNN (リカレントニューラルネットワーク)や 畳み込み層 がよく使われていた。しかし、RNN では前のステップしか見ることができず、文章全体を捉えることが難しかった。また、モデルの スケーリングも困難 で、複数の GPU を使った並列学習ができなかった。Transformers はこれらの問題を解決した。注意機構を導入することで、 文章内のすべてのトークンを参照 できるようになり、並列計算が容易になった。これにより、Billion 規模のパラメータを持つモデルを構築できるようになった。元論文では 65M と 213M のモデルが使われた。
コードは全部 GitHub 上に投稿しました。
GitHub
Transformers の紹介
Transformers のアーキテクチャは、 エンコーダとデコーダー の 2 つのコンポーネントで構成されている。入力は一般的な埋め込み層を通ってベクトルに変換される。Transformers は回帰レイヤーや畳み込み層を使用しないため、文章の順番を考慮できない。この欠点を克服するために、 Positional Encoding (位置エンコーディング)を採用する。これは、順番に応じて各埋め込みに異なる値を加算することで、順番に関する情報を保持する。元論文では、 sin 関数と cos 関数 を組み合わせて使用し、パラメータなしでも同等の性能が得られた。
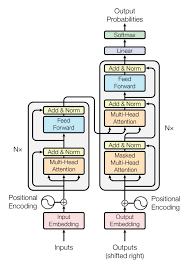
注意機構には 2 種類ある。1 つは 自己注意機構(Self-Attention) 、もう 1 つは Cross-Attention である。異なる点は入力の違いである。自己注意機構では、 クエリ、キー、バリュー を同じベクトルから作成する。一方、Cross-Attention では、クエリを通常の入力から作成するが、 キーとバリューはエンコーダの出力 から作成する。最後に、 FeedForward ネットワーク がある。Transformers は常に同じ隠れ次元を維持するが、この 層だけは次元が異なる 。このブロックは 2 つの全結合層と 1 つの活性化関数からなり、最初の層で隠れ次元を 4 倍にする。活性化関数の後に、次元を元に戻す。
出力は処理された特徴量である。この 特徴量から、lm_head と呼ばれる層 を通して次のトークンを予測する。 lm_head は output_embeddings とも呼ばれ 、元論文では入力の埋め込み層と 同じパラメータ を使用している。これにより、モデル全体のパラメータ数を大幅に削減できる。学習時はすべてのトークンを使って損失を計算するが、推論時は最後のトークンの特徴量から次のトークンを予測する。
Transformerの実装
安定を得るために
モデルを安定させるために、3 つの手法が採用されている。 LayerNorm(層正規化)、ドロップアウト、残差接続 である。深いニューラルネットワークの学習は困難を極め、失敗に終わることが多い。これらの手法は、そのような不安定性を克服するために一般的に用いられている。LayerNorm はバッチノルムを改良したものと言えるだろう。バッチノルムは、バッチ内のすべてのサンプルをほぼ ガウス分布(0,1) に変換するが、問題は各サンプルがバッチ内の他のサンプルに依存することである。これは好ましくないだけでなく、並列計算が難しくなり、Transformers のスケーリングが困難になる。
LayerNorm はバッチ単位ではなく 、各サンプルの隠れ次元をほぼガウス分布(0,1)に変換する。これにより、サンプルをガウス分布に近づけることができ、他のサンプルへの依存関係が発生しない。さらに、並列計算が可能になり、 バッチ計算を待つ 必要がなくなるため、効率的である。なぜガウス分布が望ましいのか?それは、勾配が爆発する のを防ぐからである。極端な入力は勾配を爆発させる可能性が高く、逆に 勾配が 0 になることも多い。活性化関数はこれらの極端な値を抑制するため、勾配が 0 になることをある程度防ぐことができる。したがって、ガウス分布に近い入力は、さまざまな層や活性化関数を通じて爆発することなく、勾配が 0 になる可能性を低減する。

ドロップアウトは、ほぼすべてのアーキテクチャで使われている。処理は単純で、指定した 確率に基づいてテンソルの隠れ次元の要素を 0 にする 。Transformers では頻繁に使用され、 ほぼすべての層の出力に 適用される。ドロップアウトは 過学習を防ぎ 、モデルの偏りを防ぐ。たとえば、モデルが 512 次元のうち 32 要素しか使用していない場合、ドロップアウトはその 32 要素のうち 3 つの値を 0 にする。すると、モデルの性能が低下するため、それまで使用していなかった要素を使用する必要が出てくる。そうしなければ、損失が大幅に悪化するからだ。
最後に、ディープラーニングのモデルは大抵深い。しかし、これは学習を困難にする。 勾配がちゃんと最初の層に届く ようにしなければならないが、途中の層で勾配が 0 になると、その前の層のパラメータが更新されず、学習が進まなくなる。この問題を解決するために、ResNet で提案された 残差接続 が用いられる。このアーキテクチャは、非常に深いネットワークでも適切に学習できることを証明した。この論文は 2015 年に発表され、当時の層数は 10 個程度が限界だった。しかし、ResNet は 152 層のモデルを公開し、深いネットワークでも学習できることを示した。残差接続の特徴は、勾配が 0 にならない ことである。足し算の勾配は 1 であるため、前の層に勾配が伝わる。
モデルが不安定になる原因は、初期値が悪かったり、活性化関数によって勾配が 0 になったりする場合がある。たとえば、ReLU を使用している場合、運が悪いと重みの初期値がすべて負になることがある。そうなると、ReLU は死んでしまい、その層の前のパラメータは勾配が 0 になって更新されなくなってしまう。しかし、残差接続 を使用することで、ある程度の 安定性 が得られる。y=f(x)+x の勾配を計算すると、dy/df=1 と dy/dx=1 となり、連鎖律を用いて両方の勾配を y の勾配である dL/dy として得ることができる。そのため、f(x) の勾配が 0 になっても、その層の入力に勾配が伝わることになる。
アーキテクチャの実装
今回は、各コンポーネントを順番に説明していく。この コードは完璧ではない が、同じことを実装するコードは他にもあり、理解しやすく、ある程度効率的なコードを書いてみた。コードを書いていて気づいたのは、各コンポーネントを慎重に確認する必要があるということだ。バグがあると、モデルの性能が劣化してしまう。
埋め込みとPositionalEncoding
モデルの入力はトークンの ID ベクトルである。これはコンピューターが理解できないので、埋め込み層を使用してベクトルに変換 する。この埋め込み層は、 意味の似ているトークンをベクトル空間で近く に配置する。元論文では、語彙数は 37,000 で、隠れ次元は 512 だった。そのため、埋め込み層の行列は (37000, 512) となる。トークンをベクトルに変換するのは非常に簡単である。トークンの ID は 0 から 36,999 までの 1 つの番号なので、その番号に対応する 埋め込み層の行 が、そのトークンのベクトルとなる。たとえば、ID が 20 なら、埋め込み層の 20 行目を抽出する。 学習を安定 させるために、重みに平方根をかけて掛ける。これは、次の論文で推奨されている方法である。大規模言語モデル事前学習の安定化
class embeddings(nn.Module):
def __init__(self, conf) -> None:
super(embeddings, self).__init__()
self.hidden_dim = conf.transformer.hidden_dim
self.vocabulary_size = conf.tokenizer.vocabulary_size
self.weights = nn.Embedding(self.vocabulary_size, self.hidden_dim, padding_idx=3)
def forward(self, x:torch.tensor):
"""Forward method of the embeddings class, given a tensor with the ids, it returns the embeddings of each token
Args:
x (torch.tensor): tensor containing the tokens ids
"""
x = self.weights(x) * torch.sqrt(torch.tensor(self.hidden_dim))
return x
トークンの 順番を考慮 するために、Positional Encoding を使用する。学習可能なパラメータも使用できるが、Transformers では元論文で提案されている sin 関数と cos 関数の組み合わせ を使用すると同等の性能が得られる。この部分については、本当にさまざまな実装方法がある。ここで紹介する方法は、Transformer の仕組みに最も近いと思われるため、理解しやすいかもしれない。
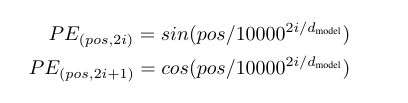
class positional_encoding(nn.Module):
def __init__(self,conf) -> None:
super(positional_encoding, self).__init__()
self.hidden_dim = conf.transformer.hidden_dim
self.max_seq_length = conf.train.max_length
self.encoding = self.generate_encoding(self.max_seq_length)
self.dropout = nn.Dropout(p=conf.transformer.dropout)
def generate_encoding(self, seq_length):
pe = torch.zeros((seq_length, self.hidden_dim), requires_grad=False)
# we just need to compute this once, then is just the same always
for pos in range(seq_length):
for i in range(0, self.hidden_dim//2):
# incorrect implementation, 2*(i+1) is wrong
pe[pos, 2*i] = torch.sin((pos/torch.pow(torch.tensor(10000.0), 2.0*i/self.hidden_dim)))
pe[pos, (2*i)+1] = torch.cos((pos/torch.pow(torch.tensor(10000.0), 2.0*i/self.hidden_dim)))
return pe
def forward(self, x:torch.tensor) -> torch.tensor:
"""Forward of the positional embeddings class
Args:
x (torch.tensor): tensor containing the embeddings. [batch_size, seq_len, hidden_size]
Returns:
torch.tensor: [batch_size, seq_len, hidden_size]
"""
# loop all the batch, no need, just sum and all ok
# x -> [batch_size, seq_len, hidden_dim] and self.encoding -> [max_seq_len, hidden_dim]
x += self.encoding[:x.shape[1]].to(x.device)
return self.dropout(x)
前のコードで、少し気になる点があるかもしれない。self.encoding はバッチサイズを持たないが、これはまったく問題ない。 PyTorch は Broadcasting という機能を持っており、不足している次元には None または 1 を指定することで、その次元に 必要な数だけテンソルをコピー する。この場合、[max_seq_len, hidden_dim] のテンソルを [batch_size, max_seq_len, hidden_dim] に変換し、足し算を行う。PyTorch はこの処理を効率的に行うため、メモリ使用量が増加することはない。したがって、この便利な機能を使用する方が良いと考える。
Multi Head Self Attention(多頭自己注意機構)
注意機構 は Transformers の特徴である。従来の自然言語処理手法では、 文章内のすべてのトークンを参照 していなかったが、Transformers は異なる。注意機構は、文章内のすべてのトークンを参照する。 データベースを検索する ように、3 つのコンポーネント(キー、バリュー、クエリ)を使用して関連する情報を抽出する。
まずは計算の詳細について説明する。最初に クエリとキーを掛け算 する。その結果得られる行列の行はクエリの文章の長さ、列はキーの文章の長さになる。この掛け算は、クエリとキーの 類似度 のようなものになる。元論文では、クエリとキーの要素が平均 0 で標準偏差 1、互いに独立しているという仮説を置いている。そのため、掛け算の結果は 平均が 0 のままだが、標準偏差は隠れ次元の平方根 になる。そこで、元の平均 0 で標準偏差 1 の状態に戻すために、隠れ次元の平方根で割る。これは Softmax 関数を 安定 させるためである。Softmax 関数は対数を確率に変換するが、対数値が大きすぎると Softmax の勾配が小さくなり、好ましくない。
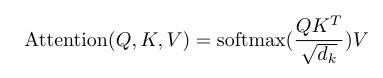
Softmax の出力は、よく見かける Attention Map である。各行のすべての値は 1 で足し算する、Sotmaxは確率を出力するから。その後、この行列を バリューに掛け算 する。最終的に得られる注意機構の出力は、現在処理中の文章に関係するバリューの値である。Softmax とバリューの掛け算は、バリューの値を小さくするだけ である。多くの要素がほぼ 0 になるが、 注目すべき部分は保持されている はずである。Softmax の各行の値を 1 で足し算するため、各行の最大値は 1 になる。
前述したのは通常の注意機構だが、Transformers では Multi-Head Attention を使用する。Multi-Head Attention とは何だろうか?という疑問があるかもしれない。Multi-Head Attention では、 隠れ次元を複数の部分に分割 する。入力は [batch_size, seq_length, hidden_dim] という形をしているが、最後に次元を分割する。元論文では 8 つのヘッドを使用しており、ヘッド次元は 512/8=64 となる。つまり、入力の形は [batch_size, seq_length, num_heads, head_dim] となる。
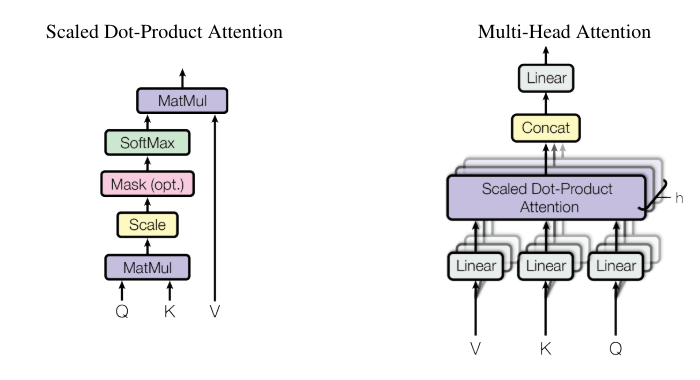
なぜ Multi-Head Attention を使う必要があるのだろうか?計算は前述の通常の注意機構と同じではないか?その理由はある。それは、前述の Softmax 関数である。 1 つのヘッドだけを使用した場合、クエリとキーの掛け算の結果、わずかな要素の値が高くなり、Softmax 関数を適用することでそれ以外の要素は 0 になってしまう。すると、多くの情報が失われてしまう。一方、Multi-Head Attention を使用すると、Softmax 関数は各ヘッドごとに適用されるため、極端に高い値があっても、それが影響するのは 1 つのヘッドのみ になる。Multi-Head Attention は表現力を向上させる。各ヘッドは特定の専門分野に特化していると考えると分かりやすい。たとえば、ヘッド 1 は推理の専門、ヘッド 2 は文章全体の意味を理解する専門など、それぞれが専門分野を持ち、必要な情報が確実に届くように学習できる。

エンコーダの注意機構は、文章内のすべてのトークンを参照する。これは、トークンの位置が文章の半分であっても、未来のトークンにも注意を払うことを意味する。そのため、エンコーダは文章の意味をより深く理解できるようになる。しかし、デコーダーの場合は異なる。デコーダーは次のトークンを予測するため、予測の条件は前のトークンだけ であるべきだ。次のトークンを予測する際に、 未来のトークンを見ることはできない 。
そのため、 注意機構にマスク をかける必要がある。通常の注意機構でも、パディングなどの不要な要素を無視するためにマスクが使用される。マスクは、無視すべき要素を最も小さな値に設定する。Softmax 関数を適用すると、非常に小さな値はほぼ確実に 0 になる。エンコーダのマスクは、未来のトークンに対してすべて最も小さな値を設定する。対角線の次の要素もすべて同じように設定する。
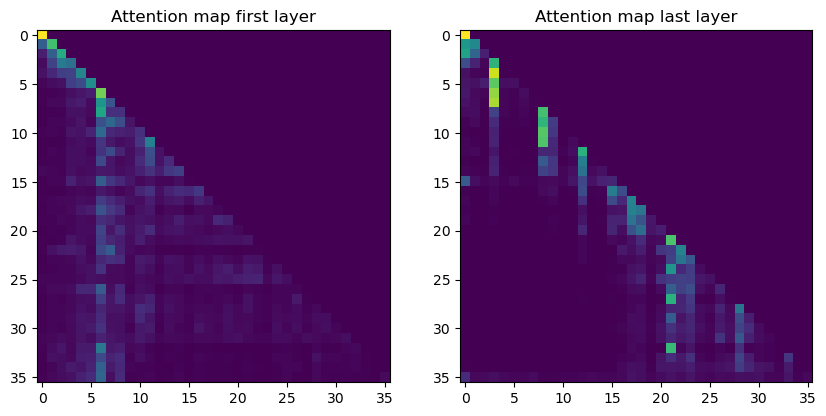
最後に、注意機構には 2 つの種類がある。1 つは 自己注意機構 、もう 1 つは Cross-Attention である。前述したように、異なる点は入力だけである。他の計算やパラメータは同じである。自己注意機構では、クエリ、キー、バリューを 同じベクトル から作成する。このレイヤーの通常の注意機構と同じである。一方、Cross-Attention では、クエリを通常の入力から作成するが、 キーとバリューはエンコーダの出力 から作成する。このレイヤはデコーダーの中にあり、自己注意機構と Cross-Attention レイヤの 2 つのステップがある。
Cross-Attention におけるマスクは、エンコーダと同じ ように、すべてのトークンを参照する。もちろん、パディングなどの不要な要素は適切にマスクされている。自己注意機構では、クエリ、キー、バリューの文章の長さはすべて同じである。入力が同じであるため、長さも同じになる。しかし、Cross-Attention では異なる。入力とターゲットトークンの長さが異なるため、 クエリとキーの長さが異なる 。Attention Mask では PyTorch の Broadcasting 機能を利用することで、この問題を解決している。エンコーダのマスクは次の次元になる [1, 1, 1, seq_len]。PyTorch は足りない次元を自動的にコピーするため、エンコーダとデコーダーの Cross-Attention では同じ注意マスクが使用される。
class multi_head_self_attention(nn.Module):
def __init__(self, conf) -> None:
super(multi_head_self_attention, self).__init__()
self.hidden_dim = conf.transformer.hidden_dim
self.num_heads = conf.transformer.num_heads
self.head_dim = self.hidden_dim // self.num_heads
self.q = nn.Linear(in_features=self.hidden_dim, out_features=self.hidden_dim, bias=False)
self.k = nn.Linear(in_features=self.hidden_dim, out_features=self.hidden_dim, bias=False)
self.v = nn.Linear(in_features=self.hidden_dim, out_features=self.hidden_dim, bias=False)
self.output_projection = nn.Linear(in_features=self.hidden_dim, out_features=self.hidden_dim, bias=False)
def forward(self, x, attention_mask=None, context=None, output_attentions:bool=False):
batch_size, seq_length, _ = x.shape
seq_length_key_value = seq_length
# projection
query = self.q(x)
if context is not None:
_, seq_length_key_value, _ = context.shape
key = self.k(context)
value = self.v(context)
else:
key = self.k(x)
value = self.v(x)
# multi head division, the order has to be [batch_size, seq_length, num_heads, head_dim] because we want to divide the hidden dim, then we just transpose
# QxK: [batch_size, num_heads, seq_length, head_dim] X [batch_size, num_heads, head_dim, seq_length] -> [batch_size, num_heads, seq_length, seq_length]
# (QxK)xV: [batch_size, num_heads, seq_length, seq_length] x [batch_size, num_heads, seq_length, head_dim] -> [batch_size, num_heads, seq_length, head_dim]
query = query.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
key = key.view(batch_size, seq_length_key_value, self.num_heads, self.head_dim).transpose(1, 2)
value = value.view(batch_size, seq_length_key_value, self.num_heads, self.head_dim).transpose(1, 2)
# scaled dot product attention
# key.transpose(3, 2) == key.transpose(2, 3)
attention = torch.matmul(query, key.transpose(3, 2)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
if attention_mask != None:
# print("using mask")
# print(key.shape, attention.shape, attention_mask.shape)
attention += attention_mask[:, :, :query.shape[-2], :key.shape[-2]]
attention = F.softmax(attention, dim=-1)
# [batch_size, num_heads, seq_length, head_dim]
attention_output = torch.matmul(attention, value)
# [batch_size, seq_length, num_heads, head_dim] here we need the continuous() else we get an error because of the strides of the tensor
attention_output = attention_output.transpose(1, 2).contiguous()
# print(attention.shape)
x = attention_output.view(batch_size, seq_length, self.hidden_dim)
x = self.output_projection(x)
if output_attentions:
return x, attention
return x
最後に、continuous() 関数について説明する。この関数は、隠れ次元を元に戻すために必要である。 PyTorch の view 関数は、テンソルの形状のみを変更し、ストライドと呼ばれるメモリの順番のみを変更 する。この関数はメモリ使用量を増やすことなく、テンソルの形状を効率的に変更する。
FeedForward
注意機構のレイヤの後に、エンコーダとデコーダーの両方で FeedForward 層(全結合層)が採用されている。これは 1 つのブロックであり、2 つの全結合層と 1 つの活性化関数 で構成される。元論文では ReLU 活性化関数が使用されている。重要な点は、隠れ次元が変化することである。Transformers は 常に同じ隠れ次元を使用 しているが、FeedForward 層では最初の全結合層によって隠れ次元が 4 倍 になる(512 から 2048 へ)。その後、活性化関数を通過し、最後の全結合層で元の次元に戻る。Multi-Head Self Attention とは異なり、この全結合層ではバイアスを採用している。最初のレイヤでは意味が分かるが、最後のレイヤでのバイアスの役割は少し分かりにくい。 LayerNorm や BatchNorm を使用することで、前のレイヤのバイアスは無意味 になる。正規化を行う際に平均値を引き算するため、バイアスは意味をなさなくなる。
class feed_forward(nn.Module):
def __init__(self, conf) -> None:
super(feed_forward, self).__init__()
self.hidden_dim = conf.transformer.hidden_dim
self.intermediate_dim = conf.transformer.intermediate_dim
self.input_projection = nn.Linear(in_features=self.hidden_dim, out_features=self.intermediate_dim, bias=True)
self.output_projection = nn.Linear(in_features=self.intermediate_dim, out_features=self.hidden_dim, bias=True)
self.dropout = nn.Dropout(p=conf.transformer.dropout)
self.activation = nn.ReLU(inplace=True)
def forward(self, x:torch.tensor, output_activation_state:bool=False) -> torch.tensor:
"""Forward method of the feed forward class, the hidden dim increases and the decreases to the normal hidden_dim
Args:
x (torch.tensor): input tensor from the mhsa, [batch_size, num_heads, seq_length, head_dim]
Returns:
torch.tensor: [batch_size, num_heads, seq_length, head_dim]
"""
x_activation = self.activation(self.input_projection(x))
# the include dropout before the last output_projection
x = self.dropout(x_activation)
x = self.output_projection(x)
if output_activation_state:
return x, x_activation
return x
コード内に x_activation という変数がある。これは、活性化関数の影響を調べるためのものだ。前述したように、ReLU はすべての負の値を 0 にして勾配を消してしまうため、勾配が適切に流れているか確認できるようにした。
LayerNormとドロップアウト
各サブレイヤの後に残差接続があり、その後に LayerNorm が適用 される。Transformers は常に同じ隠れ次元を使用しているが、これは残差接続を簡単に実現するためである。 Transformers は PostLN (後置き正規化)アーキテクチャを採用している。Llama3 や Gwen など、最近のデコーダーでは PreLN(前置き正規化)が使われる傾向にある。PreLN の方が学習を安定させるが、PostLN の方が性能がわずかに優れているようだ。ただし、元論文では 65M パラメータのモデルを学習しており、8B や 72B の大規模なモデルとは比較できないだろう。 ドロップアウトは、各サブレイヤの出力に 適用される。元論文では、ドロップアウトの確率は 0.1 に設定されている。
class layer_norm(nn.Module):
def __init__(self, conf) -> None:
super(layer_norm, self).__init__()
self.eps = conf.transformer.eps
self.hidden_dim = conf.transformer.hidden_dim
self.gamma = nn.Parameter(torch.ones(self.hidden_dim))
self.beta = nn.Parameter(torch.zeros(self.hidden_dim))
def forward(self, x:torch.tensor) -> torch.tensor:
mean = torch.mean(x, dim=-1, keepdim=True)
variance = torch.sqrt(torch.mean((x-mean)**2, dim=-1, keepdim=True))
output = (x-mean) / (variance + self.eps)
output = output * self.gamma + self.beta
return output
エンコーダとデコーダーブロック
Transformers は、エンコーダとデコーダーのそれぞれ 6 つのレイヤで構成されている。エンコーダは自己注意機構と FF(FeedForward 層)を採用し、デコーダーはマスク付き注意機構、Cross-Attention、FF を使用する。デコーダーの入力は最後のトークンまで使用し、 ラベルは 1 から最後のトークンまでとなる 。lm_head はデコーダーの入力の各トークンの 隠れ次元から次のトークンを予測 し、この予測が Transformers の損失となる。そのため、学習時はすべてのトークンを使って損失を計算する。
class encoder_block(nn.Module):
def __init__(self, conf) -> None:
super(encoder_block, self).__init__()
self.msha = multi_head_self_attention(conf)
self.ff = feed_forward(conf)
self.layernorm1 = layer_norm(conf)
self.layernorm2 = layer_norm(conf)
# "We apply dropout to the output of each sub-layer, before it is added to the sub-layer input and normalized"
self.dropout = nn.Dropout(p=conf.transformer.dropout)
def forward(self, x:torch.tensor, attention_mask=None) -> torch.tensor:
hidden_states = self.dropout(self.msha(x, attention_mask))
# the layer norm is after the residual connection, Post LN transformer
x = self.layernorm1(x + hidden_states)
hidden_states = self.dropout(self.ff(x))
x = self.layernorm2(x + hidden_states)
return x
class decoder_block(nn.Module):
def __init__(self, conf) -> None:
super(decoder_block, self).__init__()
self.msha = multi_head_self_attention(conf)
self.ff = feed_forward(conf)
self.layernorm1 = layer_norm(conf)
self.layernorm2 = layer_norm(conf)
self.layernorm3 = layer_norm(conf)
self.dropout = nn.Dropout(p=conf.transformer.dropout)
def forward(self, x:torch.tensor, attention_mask=None, context=None, context_mask=None, output_attentions:bool=False, output_activation_state:bool=False) -> torch.tensor:
# masked self attention, so here we need to use the causal_attention_mask
if output_attentions:
hidden_states, attentions = self.msha(x, attention_mask, None, output_attentions=output_attentions)
hidden_states = self.dropout(hidden_states)
else:
hidden_states = self.dropout(self.msha(x, attention_mask, None, output_attentions=output_attentions))
x = self.layernorm1(x + hidden_states)
# cross attention, here it is not masked so we can use the normal attention mask
if context != None:
hidden_states = self.dropout(self.msha(x, context_mask, context))
x = self.layernorm2(x + hidden_states)
if output_activation_state:
hidden_states, activation_state = self.ff(x, output_activation_state=output_activation_state)
hidden_states = self.dropout(hidden_states)
else:
hidden_states = self.dropout(self.ff(x, output_activation_state=output_activation_state))
x = self.layernorm3(x + hidden_states)
if output_attentions and output_activation_state:
return x, attentions, activation_state
elif output_attentions:
return x, attentions,
return x
class encoder(nn.Module):
def __init__(self, conf) -> None:
super(encoder, self).__init__()
self.num_layers = conf.transformer.num_layers
self.layers = nn.ModuleList()
for i in range(self.num_layers):
self.layers.append(encoder_block(conf))
def forward(self, hidden_states:torch.tensor, attention_mask=None) -> torch.tensor:
for i in range(len(self.layers)):
hidden_states = self.layers[i](hidden_states, attention_mask)
return hidden_states
class decoder(nn.Module):
def __init__(self, conf) -> None:
super(decoder, self).__init__()
self.num_layers = conf.transformer.num_layers
self.layers = nn.ModuleList()
for i in range(self.num_layers):
self.layers.append(decoder_block(conf))
def forward(self, hidden_states:torch.tensor, attention_mask=None, context=None, context_mask=None, output_attentions:bool=False, output_activation_state:bool=False) -> torch.tensor:
# the input is the encoder output, as we will be creating the output in a loop, first token is [EOS]
if output_attentions:
attentions_array = []
if output_activation_state:
activations_array = []
for i in range(len(self.layers)):
if output_attentions and output_activation_state:
hidden_states, attentions, activation_state = self.layers[i](hidden_states, attention_mask, context, context_mask, output_attentions=output_attentions, output_activation_state=output_activation_state)
attentions_array.append(attentions)
activations_array.append(activation_state)
elif output_attentions:
hidden_states, attentions = self.layers[i](hidden_states, attention_mask, context, context_mask, output_attentions=output_attentions, output_activation_state=output_activation_state)
attentions_array.append(attentions)
else:
hidden_states = self.layers[i](hidden_states, attention_mask, context, context_mask, output_attentions=output_attentions)
if output_attentions and output_activation_state:
return hidden_states, attentions_array, activations_array
elif output_attentions:
return hidden_states, attentions_array
return hidden_states
よく忘れがちだが、 LayerNorm には学習可能なパラメータがある ため、1 つの LayerNorm をすべてのレイヤで共有してはならない。各レイヤは独立した LayerNorm を使用する必要がある。一方、 ドロップアウトには学習可能なパラメータがない ため、1 つのドロップアウトレイヤをすべてのレイヤで共有できる。ドロップアウトには、nn モジュールや torch.nn.functional のバージョンがある。nn モジュールの方が便利であり、推論時にドロップアウトの確率を自動的に 0 にすることができる。
コードを書いているときに、残差接続の名前を間違えやすいので注意が必要である。私は x と hidden_states という 2 つの名前しか使っていない。同じパターンを常に使うことで、より分かりやすくなるだろう。
Transformer
長い道のりだったが、ここまでで Transformer クラスを実装できるようになった。このクラスは、前述した各コンポーネントをまとめたものである。Transformer クラスの入力は、 エンコーダの入力トークンと注意マスク、デコーダーの入力トークンと注意マスク である。両方のマスクは、パディング部分を指定するもので、1 は注意すべき部分、0 は無視すべき部分を示す。マスクの処理は Transformer クラス内で行われる。
元論文では Tied_embeddings を使用 している。これは、入力の埋め込み層の重みを lm_head と共有 していることを意味する。 Transformer は隠れ次元を処理し、各トークンの隠れ次元 を lm_head に通して次のトークンを予測する。そのため、埋め込み層と lm_head の次元は同じだが、方向が逆である。 埋め込み層はボキャブラリーサイズから隠れ次元 まで、lm_head は隠れ次元からボキャブラリーサイズまで変換する。その理由は主にパラメータ数の問題である。今回実装した Transformer は 55M パラメータ数を持つ。埋め込み層のパラメータ数を計算してみよう。 ボキャブラリーサイズは 37,000 で、隠れ次元は 512 である。掛け算すると 18,944,000 となり、モデル全体のパラメータ数の約 3 分の 1 になる。したがって、lm_head が独立したパラメータを持てば、その 18M パラメータは 36M になり、モデル全体の半分近くになるだろう。
推論のために Generate 関数も実装した。入力は英語の文章で、エンコーダの入力となる。 デコーダーは 1 トークンずつ処理 し、次のトークンを予測する。最初のトークンは BOS(文頭)トークンで、ロープ(文章)に従って次のトークンを予測する。今回は サンプリングを使用 したいので、top_k によって Softmax の出力をより安定させる。推論の流れは次のようになる。まず、BOS トークンを処理し、Cross-Attention によって入力とのつながりを作る。BOS トークンの隠れ次元を lm_head に通して各トークンの確率を計算し、その確率からサンプリングを行う。サンプリングされた新しいトークンを連結して、もう一度デコーダーの処理を行う。
この実装はあまり効率的ではない。 新しいトークン以外 の埋め込みはすでに計算されているのに、毎回最初から埋め込みを行っている。また、デコーダーのマスク付き注意機構のキーとバリューは変わらないので、クエリだけが変わる。そのため、 kv_cache を使用すべき である。 torch.concat 関数を使用すると、新しいテンソル が作成されるため、メモリ使用量が増えてしまう。さまざまな工夫があるが、今回はシンプルな実装を選択した。
HuggingFace の Transformers ライブラリと同様に、損失の計算は Transformer クラスの forward メソッド内で行う 。コード内に output○○○○ という変数がある。これは、次回のモデルの分析のためである。Attention Map や活性化関数の出力、最後の隠れ次元などを知ることで、初期値の適切さや学習の状態を確認できる。
class transformer(nn.Module):
def __init__(self, conf) -> None:
super(transformer, self).__init__()
self.encoder = encoder(conf)
self.decoder = decoder(conf)
self.embeddings = embeddings(conf)
self.pos_embeddings = positional_encoding(conf)
self.hidden_dim = conf.transformer.hidden_dim
self.vocabulary_size = conf.tokenizer.vocabulary_size
# During training, we employed label smoothing of value 𝜖𝑙𝑠=0.1
self.label_smoothing = conf.transformer.label_smoothing
# call them outside the model, else when loading weights we get an error as the lm_head has no entry
# self.set_tied_embeddings()
def create_causal_mask_with_padding_mult(self, seq_len, padding_mask, device):
"""
Creates a causal mask with padding taken into account.
Args:
seq_len (int): The length of the sequence.
padding_mask (torch.Tensor): A tensor of shape (batch_size, seq_len) with 0 where padding is present and 1 otherwise.
Returns:
torch.Tensor: A tensor of shape (batch_size, 1, seq_len, seq_len) representing the causal mask with padding.
"""
# Create a causal mask
causal_mask = torch.tril(torch.ones((seq_len, seq_len), dtype=torch.float32, device=device))
# Combine with padding mask
padding_mask = padding_mask.unsqueeze(1).unsqueeze(2) # (batch_size, 1, 1, seq_len)
combined_mask = causal_mask.unsqueeze(0) * padding_mask
combined_mask = (1-combined_mask) * torch.finfo(torch.float32).min
# this is of shape [batch_size, 1, seq_len, seq_len]
return combined_mask
def set_tied_embeddings(self):
# the output embeddings layer, is the LM Head, a linear with input hidden_dim and output vocab_size
self.lm_head = nn.Linear(in_features=self.hidden_dim, out_features=self.vocabulary_size, bias=False)
self.lm_head.weight = self.embeddings.weights.weight
def forward(self, src_input_ids:torch.tensor, tgt_input_ids:torch.tensor, src_attention_mask=None, tgt_attention_mask=None, last_hidden_states:bool=False, output_attentions:bool=False, output_activation_state:bool=False):
# we need 2 masks and their padding masks, encoder_mask: [seq_len, seq_len], decoder_mask: [target_len, target_len]
# context_mask: [seq_len, target_len] this is not masked so it can see everything
hidden_states = self.embeddings(src_input_ids)
hidden_states = self.pos_embeddings(hidden_states)
# attention_mask for the encoder, after substracting, the 0 should be attented so we mult the 1 to the min value and then add 1 to have the 0 as good values
dtype = hidden_states.dtype
if len(src_attention_mask.shape) == 2:
attention_mask = src_attention_mask.unsqueeze(1).unsqueeze(1)
attention_mask = (1-attention_mask) * torch.finfo(dtype).min
# encoder
hidden_states = self.encoder(hidden_states, attention_mask)
causal_attention_mask = self.create_causal_mask_with_padding_mult(tgt_attention_mask.shape[1], tgt_attention_mask, device=tgt_input_ids.device)
# decoder
tgt_hidden_states = self.embeddings(tgt_input_ids)
tgt_hidden_states = self.pos_embeddings(tgt_hidden_states)
if output_attentions and output_activation_state:
hidden_states, attentions_array, activations_array = self.decoder(tgt_hidden_states, causal_attention_mask, hidden_states, attention_mask, output_attentions=output_attentions, output_activation_state=output_activation_state)
elif output_attentions:
hidden_states, attentions_array = self.decoder(tgt_hidden_states, causal_attention_mask, hidden_states, attention_mask, output_attentions=output_attentions, output_activation_state=output_activation_state)
else:
hidden_states = self.decoder(tgt_hidden_states, causal_attention_mask, hidden_states, attention_mask, output_attentions=output_attentions, output_activation_state=output_activation_state)
logits = self.lm_head(hidden_states)
# now we compute the loss
criterion = nn.CrossEntropyLoss(label_smoothing=self.label_smoothing)
# the labels are the inputs shifted to the right, we compute all the tokens, but for the loss we shift them
# as we are using the causal mask, we don't need to shift the input_ids before computing
labels = tgt_input_ids[:, 1:].contiguous()
shifted_logits = logits[..., :, :-1, :].contiguous()
# we need to have only 2 dimensions for the crossentropy, so shifted_logits: [batch_size * seq_length, vocab_size] and labels: [batch_size * seq_length]
shifted_logits = shifted_logits.view(-1, self.vocabulary_size)
labels = labels.view(-1)
loss = criterion(shifted_logits, labels)
if last_hidden_states:
if output_attentions and output_activation_state:
return logits, loss, hidden_states, attentions_array, activations_array
elif output_attentions:
return logits, loss, hidden_states, attentions_array
else:
return logits, loss, hidden_states
if output_attentions:
return logits, loss, attentions_array
return logits, loss
def generate(self, src_input_ids:torch.Tensor, tgt_max_length, src_attention_mask=None, do_sample:bool=True, top_k:int=20, bos_token:int=None, stop_tokens:list[int]=None, debug:bool=True):
hidden_states = self.embeddings(src_input_ids)
hidden_states = self.pos_embeddings(hidden_states)
# attention_mask for the encoder, after substracting, the 0 should be attented so we mult the 1 to the min value and then add 1 to have the 0 as good values
dtype = hidden_states.dtype
if len(src_attention_mask.shape) == 2:
attention_mask = src_attention_mask.unsqueeze(1).unsqueeze(1)
elif src_attention_mask == None:
attention_mask = torch.ones_like(src_input_ids).unsqueeze(1).unsqueeze(1)
attention_mask = (1-attention_mask) * torch.finfo(dtype).min
hidden_states = self.encoder(hidden_states, attention_mask)
# bos token
tgt_input_ids = torch.tensor([bos_token], dtype=src_input_ids.dtype, device=src_input_ids.device).unsqueeze(0)
# print(tgt_input_ids.device)
for i in range(1, tgt_max_length-1):
tgt_hidden_states, causal_attention_mask = self.prepare_inputs_for_generation(tgt_input_ids)
tgt_hidden_states = self.decoder(tgt_hidden_states, causal_attention_mask, hidden_states, attention_mask)
logits = self.lm_head(tgt_hidden_states)
# logits [batch_size, tgt_seq_length, vocab_size], we only want the last token
next_token_logits = logits[:, -1, :]
if do_sample:
topk_scores = torch.topk(next_token_logits, dim=-1, k=top_k)
indices_to_remove = next_token_logits < topk_scores[0][..., -1, None]
scores_processed = next_token_logits.masked_fill(indices_to_remove, torch.finfo(next_token_logits.dtype).min)
scores = F.softmax(scores_processed, dim=-1)
if debug:
print(torch.topk(scores, dim=-1, k=top_k))
next_token = torch.multinomial(scores, num_samples=1)
else:
next_token = next_token_logits.argmax(dim=-1)
tgt_input_ids = torch.concat([tgt_input_ids, next_token], dim=-1)
if next_token.item() in stop_tokens:
break
if debug:
return tgt_input_ids, tgt_hidden_states
return tgt_input_ids
def prepare_inputs_for_generation(self, inputs_ids:torch.tensor):
tgt_hidden_states = self.embeddings(inputs_ids)
tgt_hidden_states = self.pos_embeddings(tgt_hidden_states)
tgt_attention_mask = torch.ones((inputs_ids.shape[0], inputs_ids.shape[1]), device=inputs_ids.device)
causal_attention_mask = self.create_causal_mask_with_padding_mult(tgt_attention_mask.shape[1], tgt_attention_mask, device=inputs_ids.device)
return tgt_hidden_states, causal_attention_mask
終わり
"Attention Is All You Need" の発表は、自然言語処理の分野に大きな影響を与えた。この論文は、Transformer と呼ばれる革新的なアーキテクチャを導入し、それまでの主流であったリカレントニューラルネットワーク(RNN)や畳み込みニューラルネットワーク(CNN)に取って代わるものとなった。
この論文の影響は大きく、多くの研究者やエンジニアが Transformer の実装や改良を行った。その結果、自然言語処理のタスクにおける Transformer の活用が急速に進み、さまざまな分野で優れた性能を発揮した。特に、機械翻訳、文章要約、言語生成などのタスクで優れた成果が得られた。
この論文は、Transformer に関するさらなる研究や改良のきっかけにもなった。その後の研究では、Transformer のアーキテクチャをより深く理解し、その長所と短所を分析した。また、Transformer をより効率的に学習させるための最適化手法や、異なるタスクに特化した変種が提案された。
さらに、Transformer は自然言語処理だけでなく、コンピュータービジョンや時系列データの処理など、他の分野にも応用されるようになった。画像やビデオの処理、音声認識、時系列予測など、さまざまな分野で Transformer の変種が開発された。
Transformer の登場は、AI コミュニティに大きな影響を与えた。そのシンプルさ、並列処理の効率、優れた性能により、AI 研究の方向性に大きな変化をもたらした。この論文は、AI におけるトランスフォーマー時代の幕開けとなり、その後の多くの進歩の基礎となった。
Discussion