こんにちは。FUSSYの funwarioisii です。
みなさんはサーモンランしていますか?なかなかカンストどころか伝説400バッジも取れず悔しがる毎日です。
この記事では私たちが運営しているFUSSYというサービスで、OpenAIの Chat Completions モデルのAPI(以降 Chat API)を利用して「ユーザが投稿すると関連するキャラの履歴書が更新される」という体験を作った話をします。
具体的には以下の3点について解説します。
- サービスの特性
- 履歴書体験を実現する仕組み
- 細かいテクニック
サービスの特性
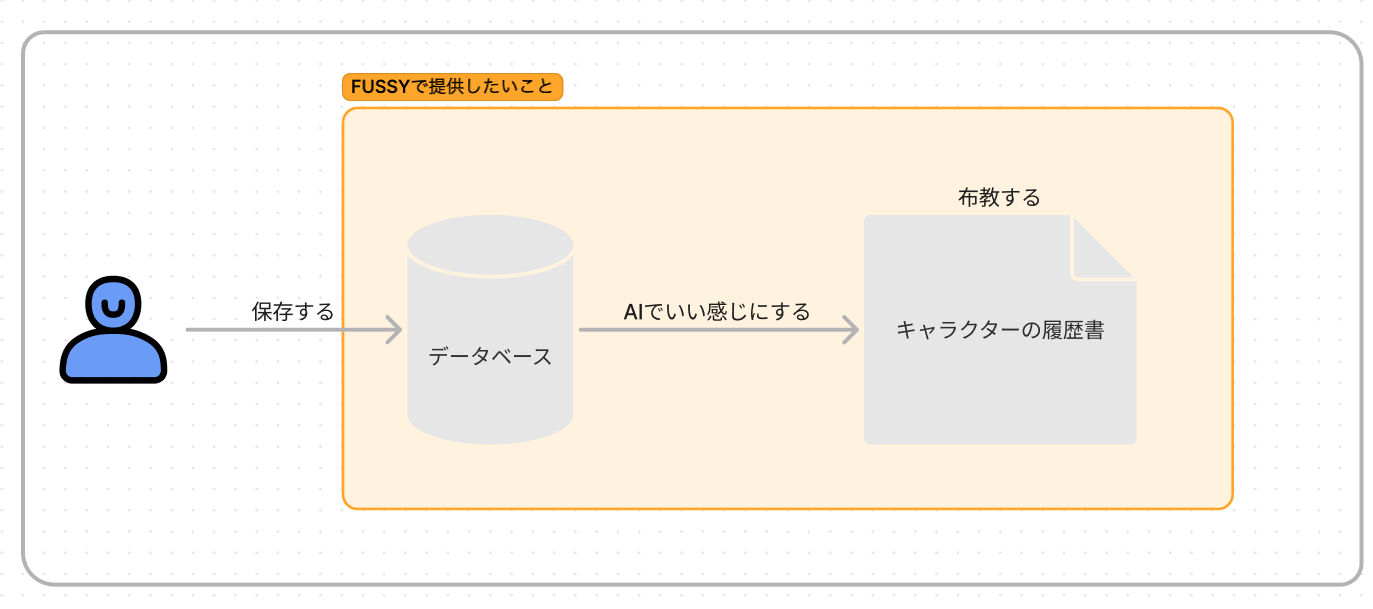
FUSSYは「推しの保存と布教」ができるプラットフォームです。
オタクな皆さんにとって推しの布教という単語は聞き覚えがあることでしょう。
私たちが目指す「推しの保存」は
- 当時の熱量がこの先も残る
- 推しを取り巻く状況が記録として残る
といった形を考えています。
FUSSY では、これらを実現するために「データベース」という機能を開発し提供しています。ユーザは自身が知りえた事実や感動をデータベースに保存できます。
では布教についてはどういう方法が取れるでしょうか?
もちろんデータベースのURLを直接共有することもできます。
より良い方法は、MySQLに入っているデータを皆さんがそのまま公開しないのと同様に、データベースを元に新たな情報として集約することです。
過去にFUSSYでは、データベースに投稿してくださった方と協力して、櫻坂46のガイドブックを作成しました。 https://publuu.com/flip-book/83007/232571/page/1
今回は「履歴書」という形にすることでキャラクターの魅力を詰め、布教に貢献できるのではないかと考えました。
そこで、データベースから履歴書の自動生成を目指します。
履歴書体験を実現する仕組み
開発条件
履歴書体験の実現に向けて、次のような要件がありました
- リスクをコントロールしたい
- 可能な限り履歴書を作れる対象を横展開したい
- ひどいUI/UXにしたくない
後の説明のために「2. 可能な限り履歴書を作れる対象を横展開したい」について少し補足します。
FUSSY では Fave という単位で俳優や作品を分けています。その中に今回履歴書を作る対象にしている「Character」という単位を作りました。Characterに関してはサービス内で露出させていない、管理用の用語です。実態としては「Fave:こち亀 Character:両津勘吉」「Fave:櫻坂46 Character:櫻坂46」のように Character が組織そのものを対象とすることがあります。そのため、この横展開とは「単一の Character のための仕組みにならない」「個体ではなく組織も指定できる」ことを指します。
まず、リスクのコントロールについてです。次の3つを懸念していました。
- 推しの履歴書が汚れるリスク
- システムがハックされ OpenAI のAPIをFUSSYから叩き続ける金銭的リスク
- ソフトウェアエンジニアがプロンプトエンジニアリングに時間を奪われることによる開発の停滞リスク
「推しの履歴書が汚れるリスク」について。
自分の推しに関して間違った履歴書が出てくることほど腹立たしいことはありませんし、制作に携わったすべての方に失礼で迷惑です。生成された履歴書はスタッフがいつでも確認・編集できる必要があります。
「システムがハックされ OpenAI のAPIをFUSSYから叩き続ける金銭的リスク」について。
UGCでは多くの場合、連投対策がされていると思います。これに関して特筆することはありません。
「ソフトウェアエンジニアがプロンプトエンジニアリングに時間を奪われることによる開発の停滞リスク」について。
機械学習モデル・大規模言語モデルの出力は確率的で、入力するプロンプトによって常に同じ値が返されるとは限りません。そのため、安定的に期待する結果を得るための工夫が必要です。
この入力の技法に関してはいくつかまとまりつつあります。
特に https://www.promptingguide.ai や https://gpt-index.readthedocs.io/en/latest/guides/primer/index_guide.html#response-synthesis を参考にしました。
実際に始めてみると、適切なプロンプトを見つけるのには大変苦労します。私は最初に Llama Index の利用を検討していましたが、Index の選択を含めたパラメータの探索に途方に暮れました。
そこで直接APIを利用せず、プロンプトの試行錯誤ができるという点で ChatGPT を使い、履歴書が作れそうかを開発メンバー以外にお願いしました。その中で、「できそうなこと」「できなさそうなこと」「GPT-4ならできそうなこと」を見つけてもらいました。
これにより、「2. 横展開したい」にも早く結論を出せました。

次に UI/UX についてです。LLMを利用したサービスとして、もっとも多くの人が思い浮かべるのは ChatGPT でしょう。次にBing Chat でしょうか。
自分が知りたいことに関する回答が得られるまで、待つことはある程度は我慢できます。ただプロダクトを開発する中で、残念ながら私たちが作ったプロダクトでは「待った以上に面白い履歴書が生成される」という期待を上回れないと考えました。
そのため、「可能な限り最新の情報を出す」という手段をとることにし、「ユーザが投稿したデータがリアルタイムに反映される」というのは一旦諦めています。(結果的には通常1分程度で反映されます。)
これらの検討を重ねて、次の条件で開発を進めました。
- LLMには ChatGPT と同等のモデルを使う
- ボタンを押して履歴書が生成されるという体験ではなく、最も最近更新された履歴書が見られる体験にする
システムのアーキテクチャ
必要な前提条件が揃ったので、どういうアーキテクチャにするかを考えます。
まず、履歴書生成システムを追加する以前のFUSSYのアーキテクチャについて。
FUSSYではサーバサイドを Rails に、フロントエンドを Next.js に、インフラをAWSのECS に頼りながら、開発しています。
この選択は単純に私は RubyとTypeScript が好きだからです。次点で、それほどニッチな選択をしていないから、他の人が参加しやすかろうという判断です。(現在エンジニアは私1人です)
今回の機能開発のために Python もそこに加えることにしました。
その理由は「履歴書をユーザの投稿から生成する」と考えたときに、サーバサイドを支える Ruby でこれをうまくやり続けることは難しいと判断したからです。
開発を始める前はChat APIに限らない選択肢がありました。先述した Llama Index はその一つです。Llama Index は Python のライブラリで、大規模な文書にクエリするシステムを構築しやすいことが売りで、今後を考えると FUSSYのプロダクトと相性が良さそうです。他にも LangChain を始めとして関連するプロジェクトが進むことも考えられます。また、これまで培われてきた日本語の自然言語処理の資産も多くあります。
これを自分が Ruby で再実装するよりも、「むずかしい自然言語処理はPythonにやらせよう」と判断しました。
次に、履歴書生成のために新たに迎えたPythonをどのように運用するかについてです。
ECSで「サービスとして実行し続ける」「リクエストごとにタスクを実行させる」あるいは、Lambdaで「リクエストごとにタスクを実行させる」というのを考えました。
「最も最近更新された履歴書が見られる」という条件の中ではどれでもよく、開発に着手しやすい点と運用が楽な点から Lambda を選択しました。Function URL を有効化し、投稿ごとにサーバサイドの Rails からHTTP通信で起動するようにしました。
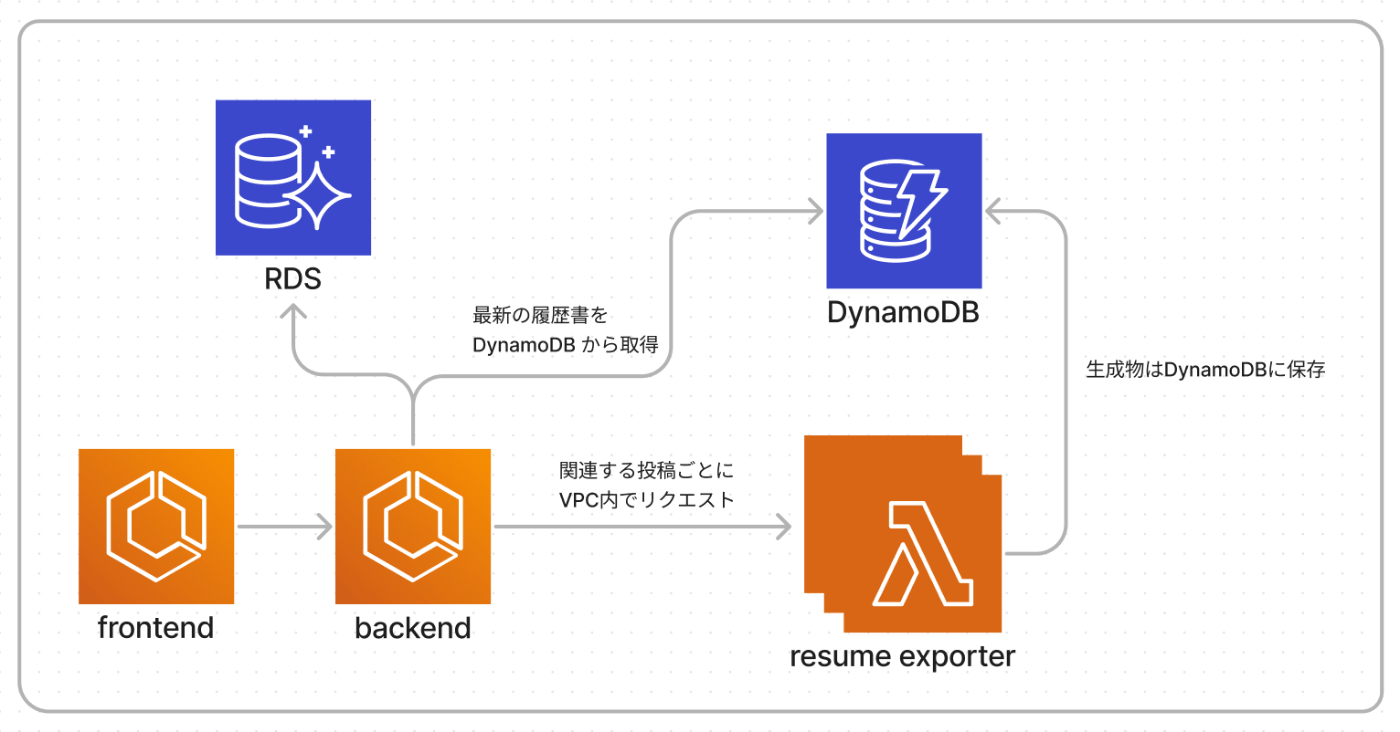
SQSやALBを省いてざっくりと以上の図のようにしています。
resume exporter が履歴書を生成し出力していますが、直接RDSへは接続していません。
主たる理由としてはそこを工夫する時間がなかった点に尽きますが、あまりRDSに接続されているサービスを増やしたくないのも理由の1つです。
履歴書を作って表示する
ざっくりとシステムのアーキテクチャができましたから、後はやるだけです。
まず、表示される履歴書について考えてみましょう。
履歴書には一般的に氏名と学歴や経歴と自己PRなどが必要そうです。
次に、これをWebで表示する方法を考えてみます。
以下の2つが思いつくのではないでしょうか。
- JSON なりの枠に埋めるデータを受け取って表示
- HTML文字列を受け取って
dangerouslySetInnerHTMLを使って表示
1つ目の方法について。Chat GPT で temperature を高めに設定していると、期待通りのスキーマでデータが作られないことがそれなりにあります。
であれば、データが欠損する前提でフロントエンドを書くよりも、フロントエンドのコードの一部を LLM に書いてもらいたいものです。そこで2つ目の dangerouslySetInnerHTML を使ったHTMLの表示を目指します。
LLM からあまり自由に HTML が含まれる文書を返されても困りますから、ある程度フォーマットを定めました。次の例は実際に使っているコードから抜粋しました。
resume_format = """
<article>
<h1>{{ name }}</h1>
<section>
<h2>学歴・職歴</h2>
<p>{{ career }}</p>
</section>
<section>
<h2>スキル・資格</h2>
<p> {{ skill }}</p>
</section>
<section>
<h2>趣味</h2>
<p>{{ hobby }}</p>
</section>
<section>
<h2>資格</h2>
<p>{{ license }}</p>
</section>
<section>
<h2>自己PR</h2>
<p>{{ pr }}</p>
</section>
</article>
"""
基本的にはこのフォーマットに従ったHTMLがChat APIからフロントエンドに到達することを期待します。
さぁ実際にやってみましょう!
https://beta.fussy.fun/board/61 に含まれるデータ数は15万文字です!
これを一度に入力し、履歴書にしてください!というプロンプトは出来ません。(トークンの使用量制限)
逆に、1投稿ずつ履歴書にする方法を考えてみると、今度は情報が断片的で Character の情報と関連付けることが難しいです。ただ、これは後述するプロンプトの工夫で解決できました。
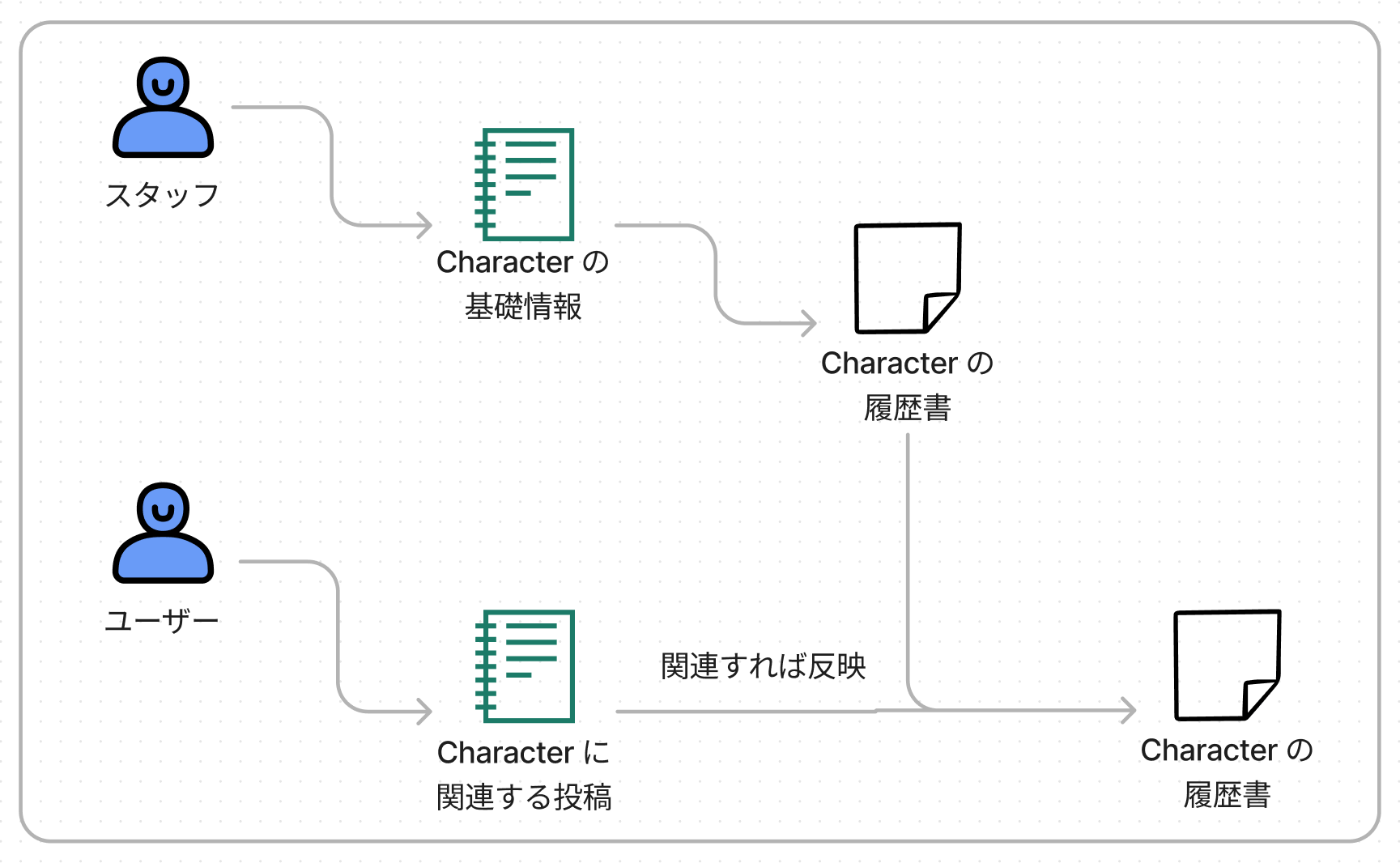
そのため、FUSSYでは次のステップで履歴書を作っています。
- スタッフがキャラクターの基礎情報を作る
- ChatGPTに履歴書にしてもらう
- ユーザの投稿を1件ずつイテレートし、履歴書に変更がありそうなら変更する
この仕組みはユーザ投稿にフックされて履歴書を再生成する方法と相性がよく、ステップ3の処理はそのままユーザ投稿で走る非同期ジョブとして利用しています。
これで履歴書自動生成システムは完成です!
プロンプトの工夫
1つ前の章では、以下のステップで履歴書を生成していると書きました。
- スタッフがキャラクターの基礎情報を作る
- ChatGPTに履歴書にしてもらう
- ユーザの投稿を1件ずつイテレートし、履歴書に変更がありそうなら変更する
実は情報収集の段階からLLMの力を借りて進めていました。
ここでは実際に使ったプロンプトを紹介していきます。
基礎情報を集め、履歴書に変換するための工夫
まず、スタッフがキャラクターの基礎情報を自由なフォーマットで作成すると、Chat API がうまく履歴書に変換しづらいことが予想されます。
そこで、キャラクターの基礎情報が入力できる管理画面では次のように表示していました。
「〇〇」の「△△」について教えてください。
出力のフォーマットは以下に従ってください。わからない場合は不明と書かれたままにしてください。
# フォーマット
1. あだ名・ニックネーム:不明
2. 性格:不明
3. 学歴:不明
4. 経歴:不明
5. 趣味・特技:不明
6. その他:不明
このプロンプトを Bing Chat で実行することで基礎情報を収集する効率化と、そのフォーマット化を図りました。
ここで得られた基礎情報は、次のようなプロンプトで履歴書に変換しています。
# 設定
あなたは{params.character_name}です。
入社が難しい会社に就職したいと思っています。
渡されるデータを履歴書として文章化してください。
# 与えられるデータの仕様
与えられるデータは次のフォーマットに従っています。
[Number]. [Title]:[Content]
# 履歴書としての文章化
履歴書としての文章化は次のフォーマットに従ってください。
{ resume_format }
# データ
1. あだ名・ニックネーム:...
2. 性格:...
3. 学歴:...
4. 経歴:...
5. 趣味・特技:...
6. その他:...
与えたプロンプトからに対する返答はおおよそ次のようになります。
はい。〇〇の履歴書です。
<article>...</article>
返答の最初にHTML以外の返答が入ることが多いです。
プロンプトエンジニアリングして、不要な返答を取り除くのは token と時間を浪費するの、大人しく正規表現で HTML の部分だけ取り出します。
また、ここで生成された履歴書を再び Chat API に修正するように問い合わせています。
これは LlamaIndex のドキュメントにある Create and Refine を参考にしました。
https://gpt-index.readthedocs.io/en/latest/guides/primer/index_guide.html#create-and-refine
FUSSYへの投稿を履歴書に反映させるプロンプトの工夫
次に FUSSY の投稿を作成した履歴書に加えていく処理について。
Chat API では固有表現の扱いが難しかったり、新しい情報が学習データに入っていない問題があります。
そのため、大原部長の履歴書の更新処理に両津に関連する投稿データを渡すと、こち亀の読者であれば分別可能な情報が混入することがありました。そこで、更新時にもスタッフの作成した基礎情報をプロンプトにも含めることにしました。
たとえば system role として次のプロンプトをメッセージの最初に詰めています。
# 設定
あなたは〇〇です。
〇〇に関する情報を与えます。
# 〇〇について
1. あだ名・ニックネーム:...
2. 性格:...
3. 学歴:...
4. 経歴:...
5. 趣味・特技:...
そして、この次に FUSSY の投稿と、以前作成した履歴書を組み合わせるリクエストをしています。
これらの細かい工夫をもとにどうにか安定的に履歴書を生成することが可能になりました。
おわりに
それでは実際にシステムとして使ってみるとどうかというと、(意外と)ちゃんと狙った通りの面白さがありました。自分の投稿で推しの履歴書の自己PR欄が変わるというのは、なかなか珍しい体験ではないでしょうか。
FUSSY では「推しの布教と保存」をもっと楽しくするための開発者を募集しています。ご興味があればお気軽に funwarioisii にお声がけください!

Discussion