こんにちは、初めましての方は初めまして。株式会社 Fusic の瓦です。12/14 に沖縄で開催されたスパルタンレースに参加して何とかゴールまでたどり着きました。普段パソコンばっかり触っていると筋力を使う場面がほとんどないので、その日に筋肉痛になるくらい力を使ってかなりいいリフレッシュになりました。今回参加したのは SUPER コースだったので、また機会があれば SPRINT と BEAST にも挑戦したいと思っています。
この記事は「Japan AWS Jr. Champions Advent Calendar 2024」の 14 日目の記事で、SageMaker マネージドの MLflow を試したものとなります。マネージド型の MLflow は、リソースについて考えなくてよかったりロールを用いてアクセスの管理が出来たりするので、これまで AWS 上で機械学習の訓練を行っていた人にはかなり役立つ機能だと思います。
MLflow とは
一言で表すと「機械学習の実験ログ、管理、デプロイを一元化出来るツール」です。例えば以下のようなことが出来ます。
- 訓練中の学習率などのパラメータやロス、精度の変化の記録
- 複数の実験の結果の比較
- 訓練後のモデルを色々なプラットフォームへデプロイ
使い方もかなり簡単で、pip などでインストールして起動するだけでログを記録するためのサーバーが立ち上がります[1]。
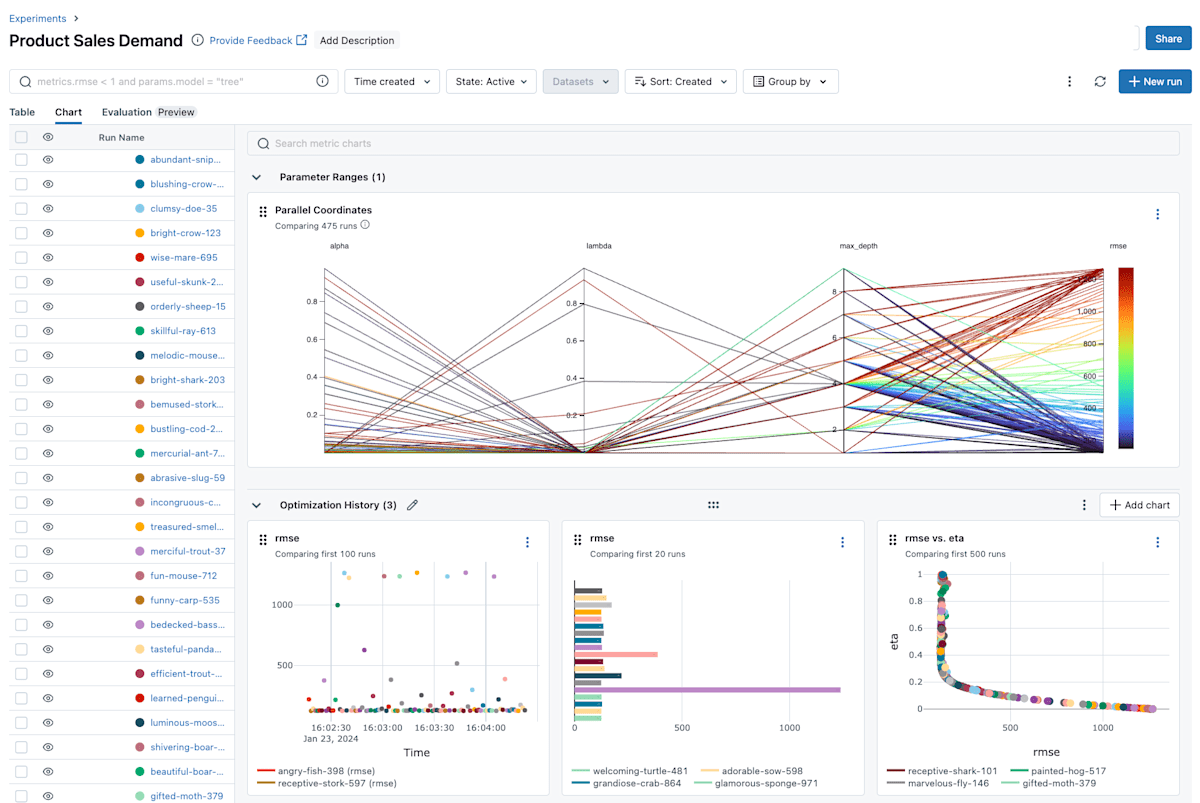
MLflow のサンプル画面 (https://mlflow.org/ より引用)
画面もこんな感じでシンプルなので、個人的には使い勝手がかなり良いなと思っています。Weights & Biases などでも実験管理は出来るのですが、今使っているプランではストレージが足りない、ユーザーをもっと増やしたいなどの要望がある場合には試してみると良いと思います。MLflow で実際に何が出来るかについては良い記事がたくさん転がっているので、ここから先は実際にマネージドの MLflow の立ち上げ方や記録について書いていきます。
MLflow on AWS
マネージドの MLflow を起動する
ここでは SageMaker Studio と Boto3 での起動方法を記載していきます。
SageMaker Studio から起動する
SageMaker Studio を使用するためにはまずドメインを作成します。パッと試す場合は「シングルユーザー向けのセットアップ」で作成するのが良いかと思います。
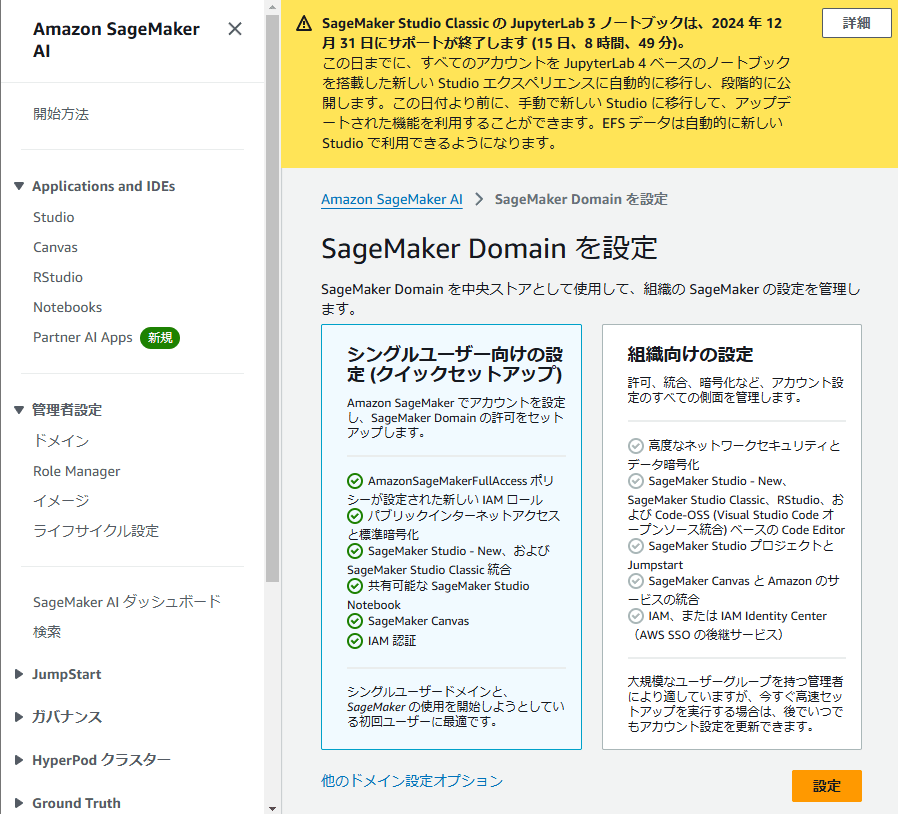
ドメイン作成の画面
ドメインを作成すると、それに紐づいたユーザープロファイルが作成されます。そのユーザープロファイルを選択して、起動を押し、Studio を押すと SageMaker Studio が起動できます。
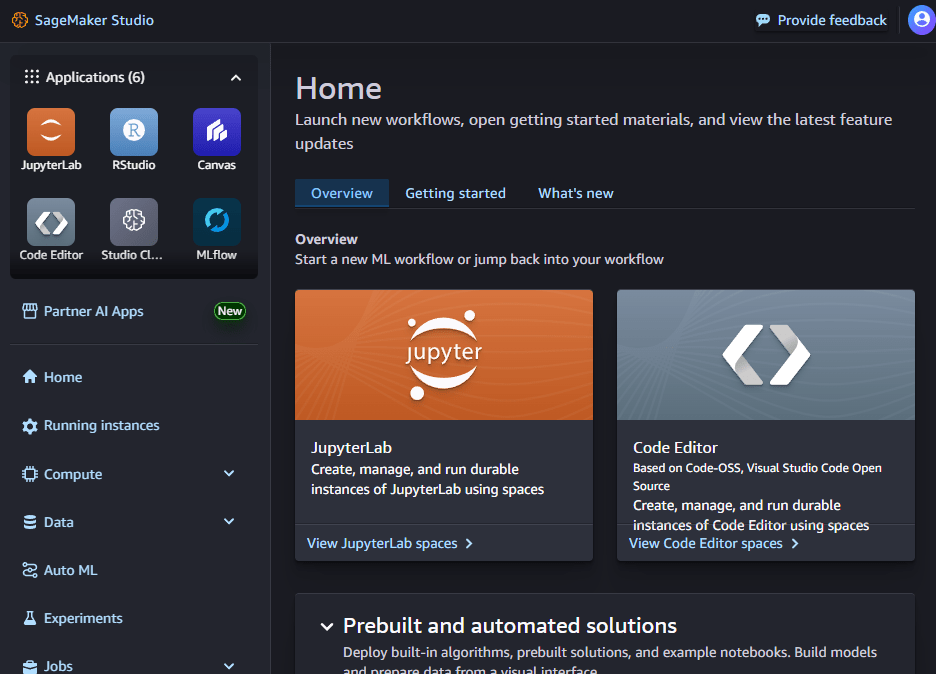
SageMaker Studio のメイン画面
起動後、左上の MLflow を押し、Create を押してサーバーの名前、ファイルなどを保管する S3 の場所を指定すると MLflow サーバーが立ち上がります(立ち上がって使用できるようになるまで 30 分以上かかるので、コーヒーでも淹れて気長に待ちましょう)立ち上げ始めると、詳細の画面が見れるようになります。後で説明しますが、ここの ARN がトラッキングサーバーの URI となるので、実験ログを追加する場合はメモしておきましょう。
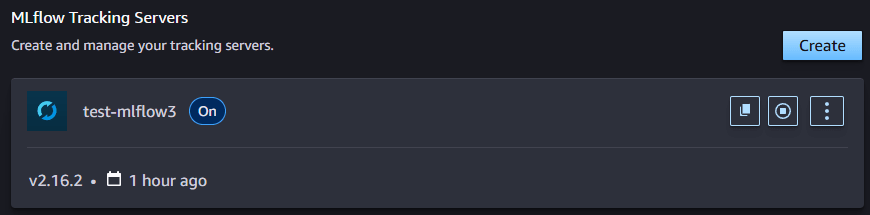
ある程度時間が経つと、上の画像のように Creating から On へと表示が変わります。これで MLflow サーバーが立ち上がっているので、縦三つに並んだ点を押して Open MLflow をクリックすることで MLflow の画面にアクセスできます。
Boto3 から起動する
boto3 を使用して MLflow サーバーを立ち上げる実装を以下に示します。create_mlflow_tracking_server[2] を使うことで、SageMaker Studio で起動するよりも細かい制御が可能です(例えば、訓練後のモデルを SageMaker へ自動で登録するかどうかやメンテナンスウィンドウの設定が出来ます)
import boto3
client = boto3.client("sagemaker")
res = client.create_mlflow_tracking_server(
TrackingServerName="<Tracking Server Name>",
ArtifactStoreUri="<S3 URI>",
TrackingServerSize="Small",
RoleArn="arn:aws:iam::<Account ID>:role/service-role/<RoleName>",
AutomaticModelRegistration=False,
)
print(res["TrackingServerArn"])
これで MLflow のサーバーが立ち上がります(ついでに ARN も表示されます)おそらく投げた直後だと作成中となりまだ使用できないので、client.describe_mlflow_tracking_server[3] でサーバーの状態を見てあげると良いでしょう。
MLflow への書き込み
以上で MLflow の立ち上げは出来たので、実際に書き込みを行ってみます。MLflow のチュートリアル[4]を実行してみます。コード自体はほとんどパクっているので、要点だけまとめておきます(興味ある方はトグルを開くか、元のページを参照してください)
MLflow にログを記録する例
import os
import evaluate
import mlflow
import numpy as np
from datasets import load_dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments
)
# AWS の設定
os.environ["AWS_ACCESS_KEY_ID"] = "AWS ACCESS KEY ID"
os.environ["AWS_SECRET_ACCESS_KEY"] = "AWS SECRET ACCESS KEY"
os.environ["AWS_DEFAULT_REGION"] = "DEFAULT REGION"
# Load the "sms_spam" dataset.
sms_dataset = load_dataset("sms_spam")
# Split train/test by an 8/2 ratio.
sms_train_test = sms_dataset["train"].train_test_split(test_size=0.2)
train_dataset = sms_train_test["train"]
test_dataset = sms_train_test["test"]
# Load the tokenizer for "distilbert-base-uncased" model.
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
# Pad/truncate each text to 512 tokens. Enforcing the same shape
# could make the training faster.
return tokenizer(
examples["sms"],
padding="max_length",
truncation=True,
max_length=128,
)
seed = 22
# Tokenize the train and test datasets
train_tokenized = train_dataset.map(tokenize_function)
train_tokenized = train_tokenized.remove_columns(["sms"]).shuffle(seed=seed)
test_tokenized = test_dataset.map(tokenize_function)
test_tokenized = test_tokenized.remove_columns(["sms"]).shuffle(seed=seed)
# Set the mapping between int label and its meaning.
id2label = {0: "ham", 1: "spam"}
label2id = {"ham": 0, "spam": 1}
# Acquire the model from the Hugging Face Hub, providing label and id mappings so that both we and the model can 'speak' the same language.
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2,
label2id=label2id,
id2label=id2label,
)
ric = evaluate.load("accuracy")
# Define a function for calculating our defined target optimization metric during training
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
# Checkpoints will be output to this `training_output_dir`.
training_output_dir = "./sms_trainer_results"
training_args = TrainingArguments(
output_dir=training_output_dir,
evaluation_strategy="epoch",
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
logging_steps=8,
num_train_epochs=3,
)
# Instantiate a `Trainer` instance that will be used to initiate a training run.
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_tokenized,
eval_dataset=test_tokenized,
compute_metrics=compute_metrics,
)
# mlflow.set_tracking_uri("http://127.0.0.1:8080")
mlflow.set_tracking_uri("<MLflow Tracking Server の ARN>")
mlflow.set_experiment("Spam Classifier Training")
with mlflow.start_run() as run:
trainer.train()
ローカルで MLflow を実行する場合は mlflow.set_tracking_uri("http://127.0.0.1:8080") のように URI を設定すると思いますが、この部分を ARN に変えるだけで AWS へログを投げてくれるようになります。ただしローカルで動かす際は AWS プロファイルを指定しないと記録できないと思うので、適切なプロファイルを設定しましょう(環境変数以外で指定する方法が分かってないので、もし知っている方がいれば教えてください…)
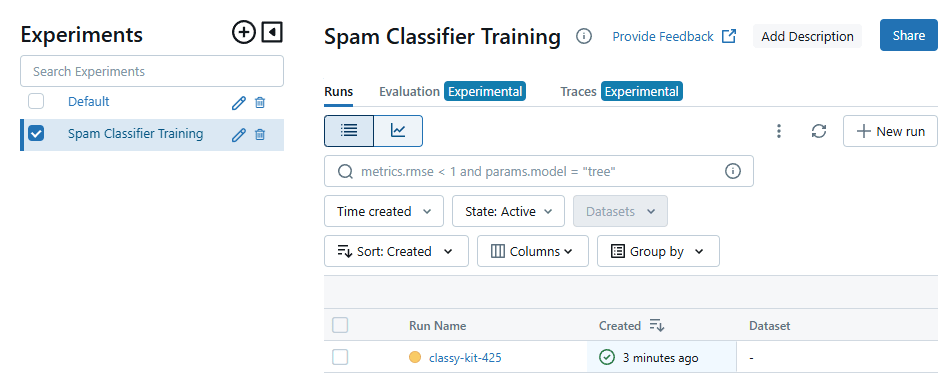
ログの記録に成功すると、上の画像のような画面が表示されます。表示されれば成功です! あとは run を押して表示される Model Metric から訓練経過のグラフを眺めたり、複数の run を指定して compare を押して複数の実験を比較したりして便利な機械学習ライフを送りましょう。
コストについて
コストに関しては https://aws.amazon.com/jp/sagemaker/pricing/ のページを参照して頂ければと思います。例として東京で Small サイズの MLflow サーバーを立てると、0.789$/h * 24h * 30d = 568.08$ となります(ストレージについては考慮していないため、これがおそらく下限となります)
まとめ
この記事では SageMaker マネージドの MLflow を使ってみました。個人で使う場合は MLflow をローカルで立ち上げればいいですが、複数人でコラボレーションした場合などはかなり便利なサービスだと思います。SageMaker マネージドとは言いつつ、特に SageMaker に限った機能でもなく普通の MLflow を扱うように使えるので、機械学習管理サービスの乗り換えを検討している方はぜひ選択肢の一つとして考慮してみてもいいのではと思います。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusic の機械学習チームがお手伝いたします。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひ Fusic にご相談ください。お問い合わせからでも気軽にご連絡いただけます。また Twitter の DM でのメッセージも大歓迎です。
-
https://mlflow.org/docs/latest/getting-started/intro-quickstart/index.html を読むとかなり簡単に MLflow を触ることが出来ると思います。 ↩︎
-
https://boto3.amazonaws.com/v1/documentation/api/1.35.6/reference/services/sagemaker/client/create_mlflow_tracking_server.html ↩︎
-
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/describe_mlflow_tracking_server.html ↩︎
-
https://mlflow.org/docs/latest/llms/transformers/tutorials/fine-tuning/transformers-fine-tuning.html ↩︎

Discussion