こんにちは、初めましての方は初めまして。株式会社 Fusic の瓦です。最近朝早くに起きれず、「『春眠暁を覚えず』とはこのことか」と実感しています。
この記事では OpenAGI: When LLM Meets Domain Experts という論文の解説を行います。この論文では、汎用的な人工知能 (AGI) の実現に向けて、特定のタスクを解くことが出来るモデルを大規模言語モデル (LLM) で組み合わせることでより複雑なタスクを解くシステムの提案をしています。著者らによる実装は Github にあります。
概要
人間はしばしば単純な能力を組み合わせて複雑なタスクをこなしています。AGI の実現にむけて、この複雑なタスクを解決するために単純な能力を組み合わせる機能が必要だと考えられます。
また、ChatGPT の流行に見られるように、近年では LLM の発展が盛んになっています。それに伴い、Auto-GPT や BabyAGI のように、目的を与えると自律的にタスク設計し実行するシステムの開発もされています[1]。これらのシステムでは LLM をタスク設計のために使用し、出力された文から次の行動を決定しています。
この論文ではそのような能力に目を付け、複雑なタスクをこなすために LLM で簡単なタスクを組み合わせるシステムの提案をしています。それに加えて、タスクをこなす能力を向上させるために、Reinforcement Learning from Task Feedback (RLTF) という学習手法も提案しています。これは文字通り「解き終わったタスクの評価から強化学習を行う」手法であり、これによって zero-shot や few-shot でタスクを設計するよりも、より優れた出力が出来るようになったと報告しています。
単純な能力について
ここまで「単純な能力を組み合わせる」と書いてきたのですが、そもそも「単純な能力」とはなんでしょうか?
この論文では「単純な能力」を「あるドメインに特化したモデル」として捉えているように思えます。例えば「ある英語の文書を、要約したドイツ語の文書にしたい」場合は、「英語からドイツ語に翻訳するモデル」と「ドイツ語の自動要約モデル」を組み合わせることで達成できます。
この論文ではこの「単純な能力」を実行するモデルとして、以下の引用画像のモデルを使用しています。
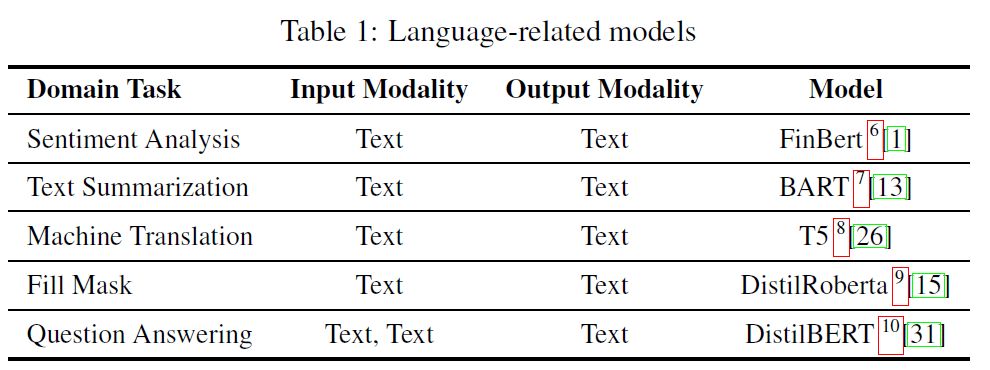
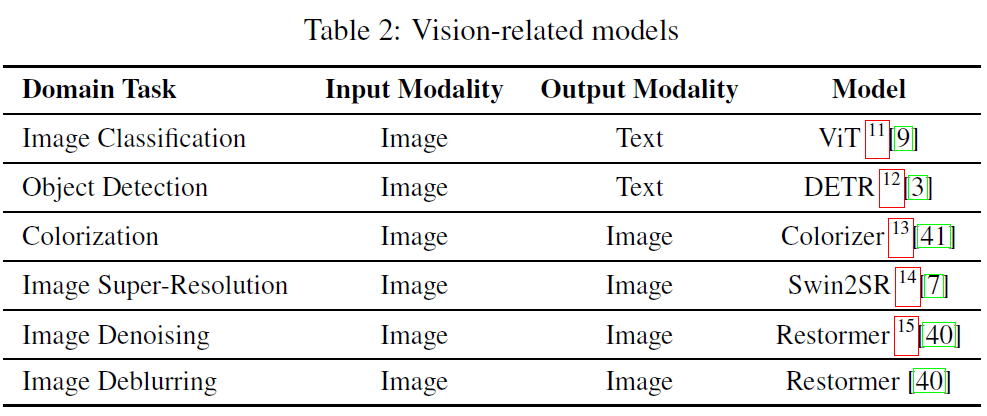
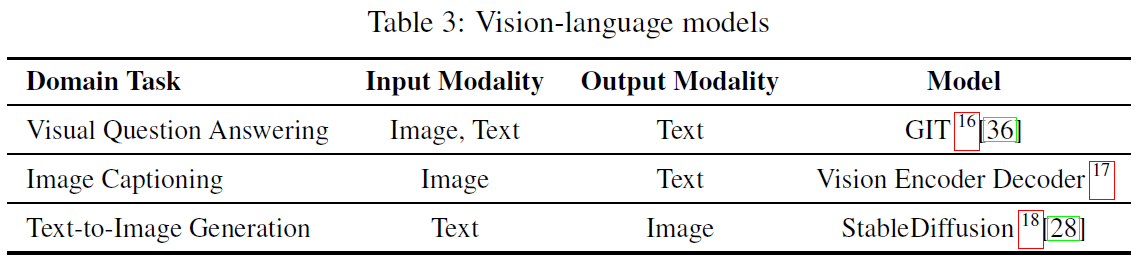
このように各モデル(タスク)に対して「入力」と「出力」を定めています。この設定により、タスクを設定すればそれに対応したモデル使用することが出来ます。また、「"Text Summarization" の出力を "Image Classification" の入力につなげることは出来ない」というような制限を課すことも出来ます。
提案手法
この論文では、解決すべき問題として
- OOD なデータへの対応
- タスク設計の最適化
- 非直列なタスクの設計
の三つをあげています。このうち、最初の二つは RLTF によって、最後の一つは Nonlinear Task Planning によって解決すると述べています。
RLTF
RLTF は「設計し終わったタスクを実行し、その評価から強化学習を行う手法」です。この方法によって、LLM はより良いタスク設計をすることが出来るようになります。また、この方法によって「独自に定義した、解かせたい問題」に対応したタスクの設計を学習できると考えられます。
Nonlinear Task Planning
まず、直列なタスク設計について書きます。このシステムでは、出力する単語を制限することでタスクの設計を行えるようにしています。下図で引用するように、例えばタスク名として "Text" の次に来るのは "Summarization" か "to Image Generation" なので、その二つに限って出力を決定します。
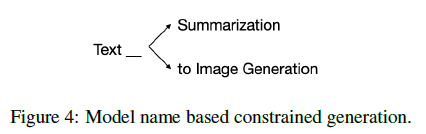
また、タスクを組み合わせる場合は、前のモデルの出力が次のモデルの入力になるように LLM の出力を制限します。下図で引用するように、例えば "Text Summarization" を行うタスクとした場合、タスクの出力はテキストになります。そのため、次に来るタスクは "Text Summarization" 以外でテキストを入力するものとなります。
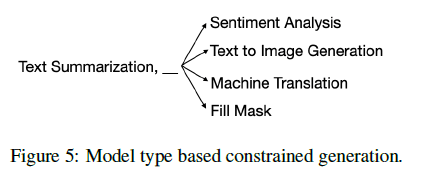
ただこれらの手法では直列にしかタスクを設計できないため、VQA のような入力を二つ (「画像」と「テキスト」) 必要とするモデルではうまく動きません。この問題に対して、制限付きのビームサーチを使用することで対応しています。ビームサーチで複数の解を出力し、それを並列なタスクとして選択することで並列なタスク設計を行っているようです[2]。
実験
タスクを設計する LLM として GPT-3.5-turbo, LLaMA-7b, Flan-T5-Large を使用しています。さらに、zero-shot, few-shot, fine-tuning, RLTF の四つの手法でタスク設計の精度がどう変化するかも実験しています。
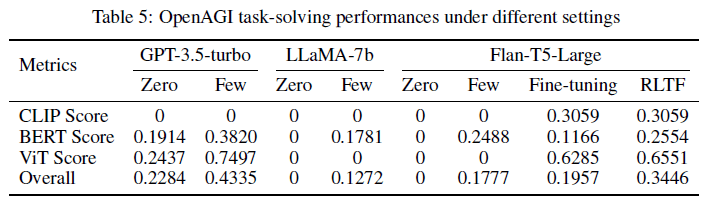
それぞれの評価指標は高ければ高いほどいい性能となります。表を見ると、zero-shot よりも few-shot の方が優れた結果となっており、few-shot の有効性がうかがえます。また Flan-T5-Large の結果では、単純に fine-tuning するよりも RLTF の結果の方が良くなっています。また、GPT-3.5-turbo では恐らく出力の制限が出来ないため、モデル名を繰り返し出力する傾向にあったとのことです。
論文では言及されていませんが、zero-shot, few-shot では CLIP Score がどのモデルでも 0 となっています。CLIP Score は生成された画像のキャプションと実際の画像の類似度を計算する指標らしいのですが、LLM では画像をどう扱えばいいのか分からずうまくタスク設計が出来ないために 0 なのでしょうか。CLIP Score がどのタスクに対して使用されているのかあまり分からないので、詳細が気になるところです。
まとめ
(そもそもどうなれば AGI と呼べるのかという議論はこの論文ではされていませんが)AGI の実現に向けて、この論文ではより多くの範囲のタスクを解けるようなシステムを提案しています。論文中ではテキスト、画像を取り扱っていますが、おそらく独自のタスク(例えば音声認識でテキストにし、それを要約)に対して拡張出来ると思います。まだ「汎用」ではないですが、うまくタスクを組み合わせることでより広範囲の複雑なタスクに対応できるようになると考えると、このシステムの今後の発展に期待が高まります。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusicの機械学習チームがお手伝いたします。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひFusicにご相談ください。お問い合わせからでも気軽にご連絡いただけます。またTwitterのDMからでも大歓迎です!
-
Auto-GPT を使ってみた記事は「自動でタスクをこなす AI を使ってみた」をご覧ください。 ↩︎
-
あまりこの部分の解釈に自信がありません。間違っていたらご指摘お願いします。 ↩︎

Discussion