こんにちは、初めましての方は初めまして。株式会社 Fusic の瓦です。もう 2023 年も半年が終わろうとしていますね。まだ2023 年が始まって三ヵ月くらいしか経っていない気がするのに不思議なものです。
この記事では Diffusion Models for Non-autoregressive Text Generation: A Survey という論文を紹介したいと思います。この論文は、非自己回帰モデルにおける拡散モデルの論文についてまとめられたものです。また、引用されている論文は大きく二つのカテゴリに分けられて Github のページにまとめられています。この記事では、個々の論文の詳細には立ち入らず、次の記事への宿題としたいと思います。また、断りのない限り図は元の論文から引用したものです。
はじめに
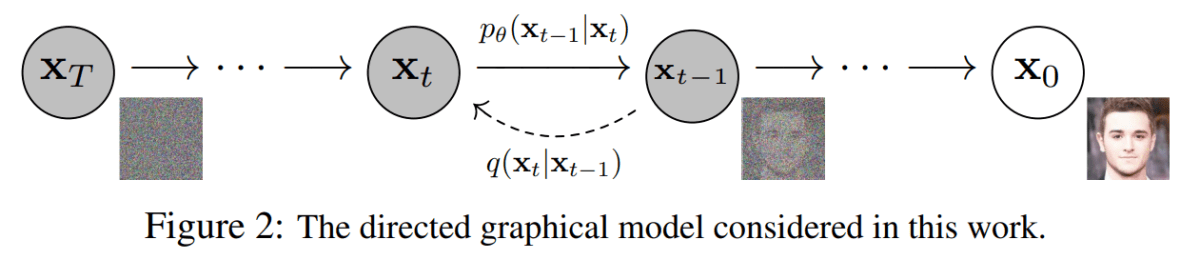
論文[1]の図 2 より参照
近年では画像や音楽の生成において、拡散モデル (Diffusion Model) と呼ばれる手法が使用されています[1:1] [2]。拡散モデルはざっくりと言えば、「何かしらのデータにノイズが乗っている状態のものがあるので、乗っているノイズを除去してデータを復元しよう」という操作をすることで画像や音楽などのデータを生成する手法です(上図の右向きの過程)。埃の積もった写真があって、拡散モデルはその埃を払っているというイメージが分かりやすいかもしれません(それはちょっと違うだろと突っ込まれそうですが)。拡散モデルについて詳しくは mm_0824 さんの【論文解説】Diffusion Modelを理解するや、diffusion model の論文を参照していただければと思います。
画像や音楽の生成において広く使用されている拡散モデルですが、近年ではテキストの生成に対しても拡散モデルを適用した手法が提案されています。テキスト生成には大きく二つのアプローチがあり、その一つは自己回帰モデル (Autoregressive model: AR モデル) と呼ばれる、前から順に単語を生成していく手法です。GPT などのモデルはこちらのモデルです。もう一つは非自己回帰モデル (Non-autoregressive model: NAR モデル) と呼ばれる、各単語を同じタイミングで出力する手法です。「同じタイミング」と書くと少し語弊があるのですが、文全体を一気に生成するようなモデルだと思っていいと思います。
ここで紹介する論文はタイトルの通り、NAR モデルに対して拡散モデルを適用した手法のサーベイ論文になっています。そのためこの記事では、まず初めに NAR モデルについて軽く説明をします。その次に、NAR モデルに対する拡散モデルの適用について見てみます。それから、NAR モデルにおける拡散モデルを適用した手法でどのようなことが課題として取り組まれているかについても簡単に紹介したいと思います。
非自己回帰モデルについて
Transformer や GPT のような AR モデルでは、文の各単語を前から順に出力していきます。これによって前の単語への依存関係を考慮しつつ次の単語の予測が行えます。しかし、文全体を出力するためには単語の数だけ推論を繰り返す必要があり、文が長ければ長いほど推論に時間がかかってしまいます。
この問題に対して、各単語をそれぞれ独立に生成する NAR モデルが提案されています。NAR モデルでは文の単語を並列で推論するため、(単純なモデルであれば)一度の推論で全ての単語を出力できます。このため、単語の数だけ推論を行う必要がある AR モデルと比較すると推論時間が大幅に減ります。しかし、NAR モデルでは単語の依存関係を考慮できないため、AR モデルと比較すると精度は低下します。
精度の低下に対して、知識蒸留(AR モデルでの出力を正解データとして学習する手法)や事前学習モデルの利用が提案されてきました。また近年では拡散モデルによって画像生成の性能が大幅に向上したという背景もあってか、NAR モデルに対して拡散モデルを適用した手法が提案されています。
言語生成に対する拡散モデル
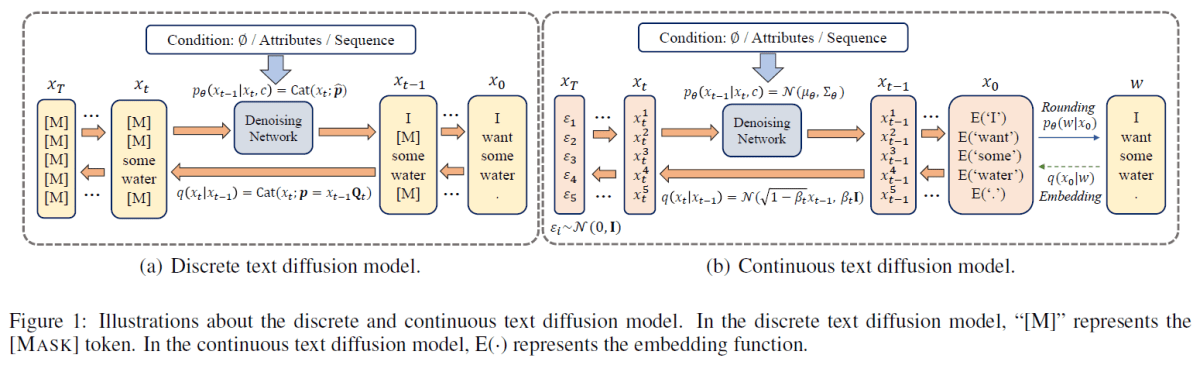
NAR モデルに対する拡散モデルの適用は上図に示すように、トークンのような離散的なものを扱うモデル(右側)と、エンベッディングのような連続的な値をもつものを扱うモデル(左側)というように、大きく二つのカテゴリに分けられます。離散的なモデルでは、トークン自体にノイズをかけ、それを取り除くように学習します。この図では [M] トークンの列から徐々にノイズである [M] トークンが無くなっていくというモデルになっています。連続的なモデルではトークンのエンベッディングに対してノイズをかけ、それを取り除くよう学習します。ノイズが取り除かれたベクトルはエンベッディングと一致するとは限らないため、最後にトークンへと戻す必要がありますが、それ以外は画像生成などで使われている拡散モデルと同じだと思います。
以下にこの論文で取り上げられているモデルの一覧の図を載せます。
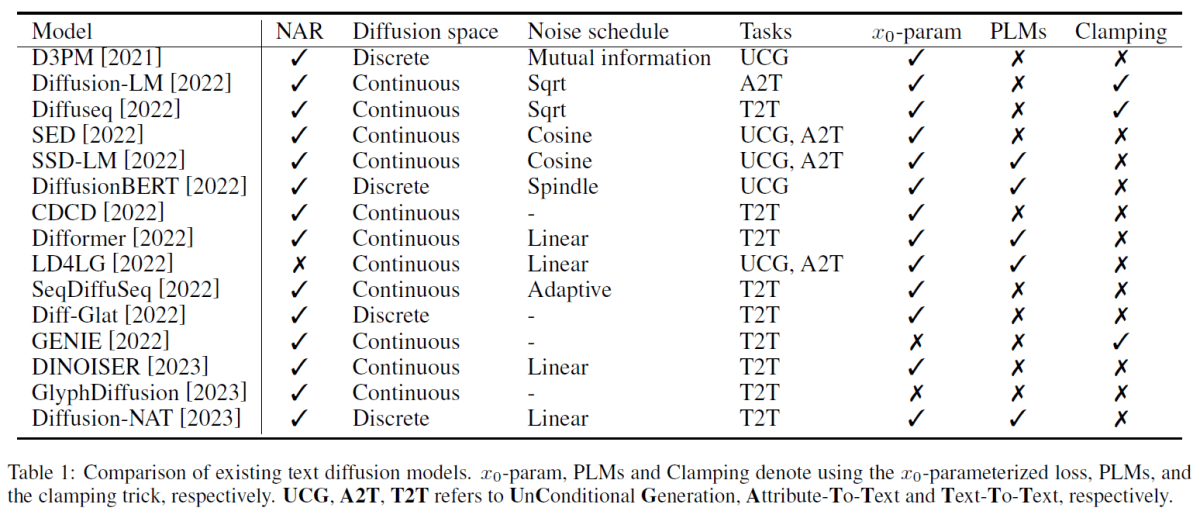
この表を見ると、NAR モデルに対する拡散モデルはかなり最近の研究のようです。また、手法としては連続的なモデルが主に取り組まれていることもわかります。
拡散モデルにおけるテキスト生成のポイント
この論文では NAR モデルに対する拡散モデルの適用において工夫されている点が、以下の四つに分けてまとめられています。
- Denoising Network: ノイズを取り除くモデルの選択
- Noise Schedule: どのようにノイズを付与するか(取り除くか)
- Objective Function: 損失関数の設計
- Conditioning Strategy: 生成するテキストの条件付け
Denoising Netework
Denoising network については、基本的に Transformer ベースのモデルが使用されているようです。また、近年では事前学習モデルを使用することで、下流タスクで大きく性能を改善できることが報告されています。そのため、NAR モデルに対する拡散モデルでも事前学習モデルを使用する手法が提案されています。
Noise Schedule
Noise Schedule については、ノイズを付与する方法が紹介されています。線形にノイズを付与する手法、単語の相互情報量に基づく手法や低頻出な単語に先にノイズを付与する手法などあります。このノイズの付与の仕方によって復元のしやすさが決まるので精度に大きな影響をあたえるのかなと思うのですが、この論文では特に精度の比較はされていないため、個々の論文を読む際にまた詳しく見ていきたいと思います。
Objective Function
Objective Function については、NAR モデルに対する拡散モデルで用いられる損失関数について紹介しています。元々の拡散モデルの損失関数を使うと、推論で出てきた単語のエンベッディングがどの単語のものにも近くならないという問題がありました。そこで、NAR モデルに対する拡散モデルでは以下の式が使用されています。
上の式に加えて、連続的なモデルでは推論したベクトルを単語のエンベッディングに近づけるための損失関数が追加されていたり、離散的なモデルに対して時刻
Conditioning Strategy
Conditioning Strategy については、大きく三つの方法があります。一つ目は何も条件を与えずにテキストを生成する手法です。このモデルでは与えられたノイズのみからテキストを生成するので、基本的なテキスト生成能力を確かめるために使えます。どのような文が出てくるかは分からないため、あまり実用的ではないかもしれません。
二つ目は、何らかの属性(ラベル?)を与える手法です。例えば「野球」のようなラベルを条件として与えることで野球に関した文を生成できたり、「ドイツ語」という条件を与えてドイツ語の文を生成させることが出来ます。
三つめはテキストを与える手法です。この論文では Text-to-text Generation としてまとめられている通り、何らかの系列データを変換したい場合に使える方法です。その一つとして、与えられる文と正解の文を結合してモデルに与える手法が紹介されています。与えられた文と正解の文を結合し、正解文の単語にだけノイズを付与して、そのノイズを取り除くように(正解文を生成できるように)学習を行います。推論時は与えられた文とノイズの付与された文を結合して、ノイズの付与されている部分にのみ推論を行って文を生成します。こうすることで、与えられた文を考慮しながら推論が行えます。
まとめ
この記事では、NAR モデルに対して拡散モデルを適用した手法のサーベイ論文を紹介しました。どれくらいの文が生成できるのかについてはこの論文では触れられていなかったのですが、もし実用的に使えるレベルの文が生成できるのであれば、AR モデルの代わりに出来るのではないかと思います。特に推論速度は圧倒的に NAR モデルの方が速いので、事前学習モデルなどと組み合わせて文の生成が行えるモデルやサービスが出てくるのもそう遠くはないのかもしれません。
この論文ではモデルごとの比較は行っておらず、各論文で提案された手法をまとめて整理していました。そのため、紹介されている論文については、それぞれのカテゴリごとにまた別の記事で紹介したいと思います。
最後に宣伝になりますが、機械学習でビジネスの成長を加速するために、Fusicの機械学習チームがお手伝いたします。機械学習のPoCから運用まで、すべての場面でサポートした実績があります。もし、困っている方がいましたら、ぜひFusicにご相談ください。お問い合わせからでも気軽にご連絡いただけます。またTwitterのDMからでも大歓迎です!

Discussion