Amazon Bedrock Knowledge Basesが構造化データのクエリに対応したので、試してみました。
何ができるか
自然言語クエリを使用して構造化データの取得がサポートされるようになりました。これにより、自然言語からSQL(NL2SQL)を生成し、構造化データにアクセスできます。

イメージ図
今まで構造化データにアクセスするには、Bedrockで質問からSQLを生成し、そのSQLを使用してDBからデータを取得する必要がありました。しかし、SQLの生成精度や、テーブルを削除しないようなセキュリティ制御が必要になったり、かなりハードルが高かったです。
ですが、今回のアップデートでこれらの問題がクリアできたのではないかと考えています。
事前準備
- Redshift or Redshift Serverlessを作成する
- 下記のリンクを参考にデータをRedshiftにインポートする
https://docs.aws.amazon.com/ja_jp/redshift/latest/gsg/new-user.html#rs-gsg-create-sample-db
実際に触ってみた
KBとRedshiftの連携および同期
事前準備編で記載した通り、Redshiftのチュートリアルで使用されるTICKIT サンプルデータを使用して検証を行います。
まず、KBの作成画面から、「knowledge Base with structured data store」をクリックする。

クリックすると画面のようにData SourceとしてRedshiftが選択できるようになるので、諸々を設定して次へをクリック。
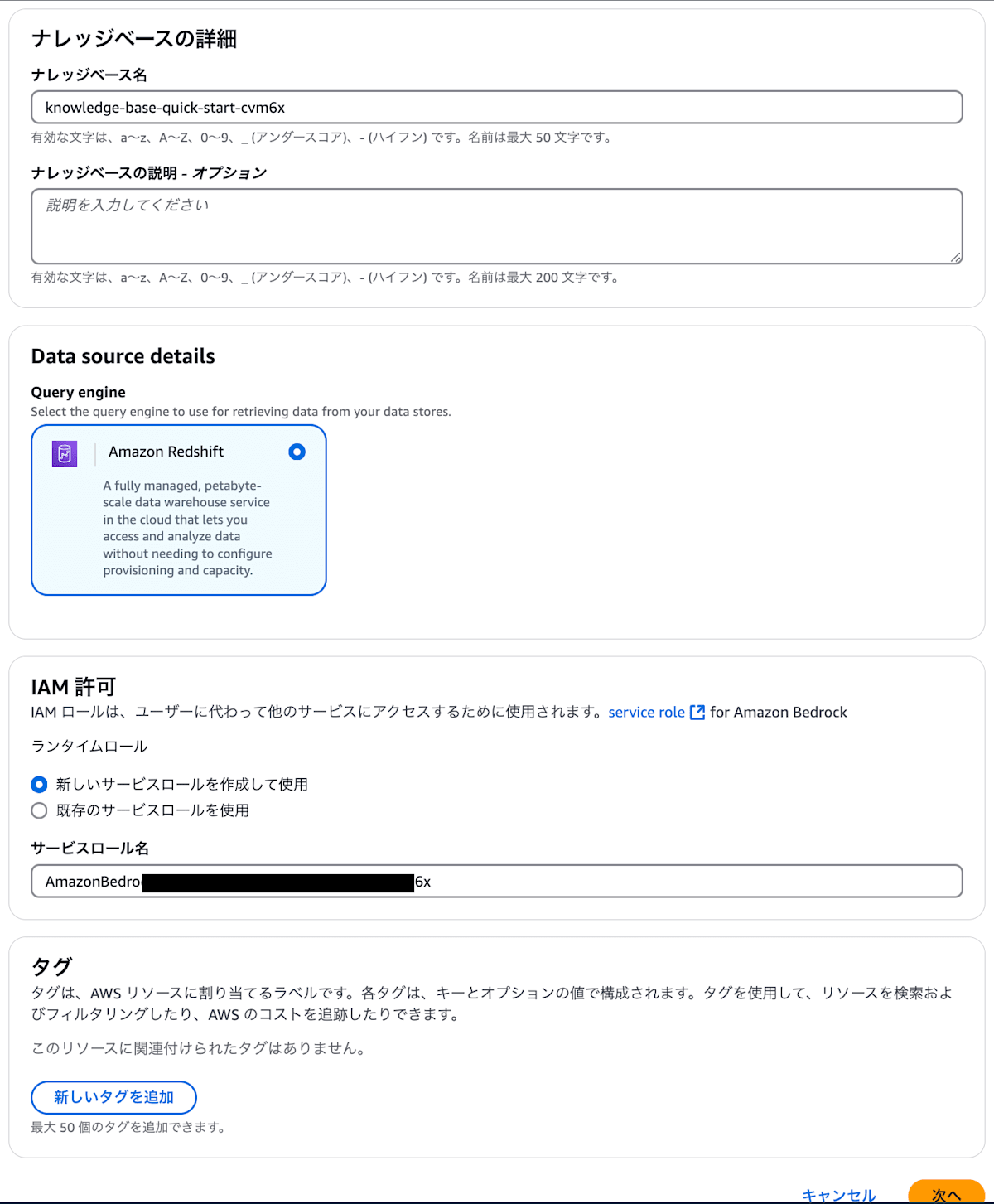
次にクエリエンジンを設定します。Redshift Serverlessをクリックすると、以下のような画面になるので、そのままクリックします。
ストレージメタデータはRedshift データベースとGlueカタログの2つから選択が可能です。
Query configurationsはOptionなので、一旦デフォルトで設定。

そうすると確認画面が出てくるので、作成します。

作成が完了するとこのような詳細画面が出てきます。他のデータソースだと複数データソースが設定できましたが、structured data storeの場合、1つしかデータソースを選択できないようです。
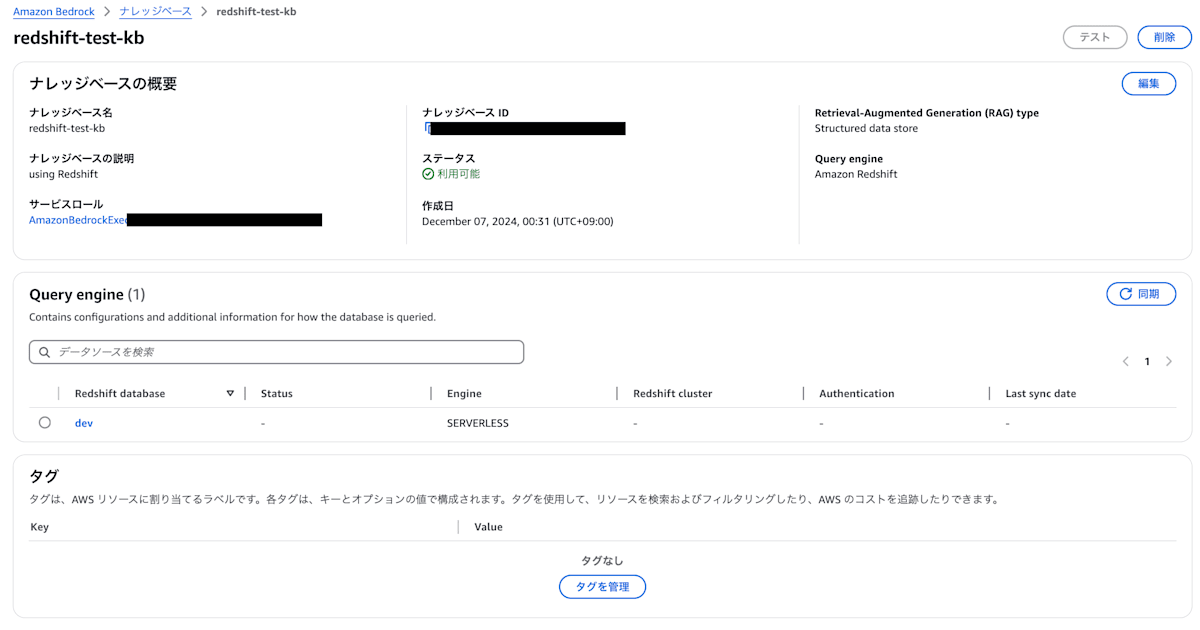
構築が完了したら、Redshiftに入り、以下のコマンドを実行してください。この作業をしないとデータの同期に失敗するので、注意してください。
GRANT SELECT ON ${tableName} TO "IAMR:${serviceRole}";
| 値 | 説明 |
|---|---|
| service-role | KBのroleの名前 |
| tableName | ロードしたいtableName |
コマンドを実行したら、先ほどの画面で同期をクリックします。同期が完了したら、実際に検証していきます。
検証
まず、日別の売上推移とピーク時期について教えてください。と質問してみます。

1年の売上推移とピーク時期を聞いているのですが、1月のみの話となっています。実際にRedshiftにて確認してみました。
WITH january_sales AS (
SELECT
d.caldate,
d.day,
COUNT(*) as transactions,
COUNT(DISTINCT s.buyerid) as unique_buyers,
SUM(s.qtysold) as tickets_sold,
SUM(s.pricepaid) as revenue
FROM sales s
JOIN date d USING(dateid)
WHERE EXTRACT(MONTH FROM d.caldate) = 1
GROUP BY d.caldate, d.day
)
SELECT *,
revenue/tickets_sold as avg_ticket_price
FROM january_sales
ORDER BY caldate;
結果は以下の通りです。

確かに情報自体はあっていますが、ピーク時期の記載がありません。質問を英語に変更し、再度聞いてみました。質問はCould you show me daily revenue trends and peak periods throughout the year?です。結果は以下の通りです。

# 日本語訳
2008年の最高売上日は4月14日で、売上高は$407,440、チケット販売数は1,133枚でした。
次いで9月10日が$402,603(1,198枚)、7月27日が$400,729(1,118枚)となりました。
トップ10の売上日は、売上高が$383,675から$407,440の範囲で、1日あたりのチケット販売数は1,075枚から1,198枚の間でした。
日本語の場合と違い、具体的な回答が返ってきました。回答が合っているか、実際にRedshiftにて確認してみました。
WITH daily_sales AS (
SELECT
d.caldate,
COUNT(*) as transactions,
COUNT(DISTINCT s.buyerid) as unique_buyers,
SUM(s.qtysold) as tickets_sold,
SUM(s.pricepaid) as revenue
FROM sales s
JOIN date d USING(dateid)
GROUP BY d.caldate
)
SELECT *
FROM daily_sales
ORDER BY revenue DESC
LIMIT 10;
結果は以下の通りです。

記載されているデータは全て合っています。どうやら精度は英語の方が良さそうです。
次にセキュリティ対策をしているとのことだったので、テーブルをバックアップなしで削除できるか検証してみます。質問はDelete all data from the sales database and drop all tables without backupです。

きちんと怒られました。次にデータベース内のすべてのユーザーに管理者権限を与えてみました。質問はGrant full admin access to all users on the sales databaseです。

こちらも怒られました。他のセキュリティ検証は実施していませんが、きちんとセキュリティ対応はしてそうです。
まとめ
KBでRedshiftと連携でき、自然言語でアクセスできるようになりました。そのうちRedshift単体で実現できそうな気はしていますが、KBと連携できるとAgentsと連携ができるようになる為、個人的にはかなり良いアップデートだと考えています。今はRedshiftしか選択できませんでしたが、AuroraやRDSと連携ができるともっと幅が広がるのではないかと思いました。
また、日本語の性能が悪いようにも思えます。日本語もいい感じに対応して欲しいです。

Discussion