はじめに
こんにちは。Fusicの大宮です。
Difyを使えば、RAGアプリケーションを素早く構築できます。
PDFをソースとしてナレッジベースを作り、チャットボットを構築するユースケースも一般的です。
しかし、スキャンされた文字(画像として埋め込まれる)データを含むPDF(以下スキャンPDF)や、
画像ファイルを用いてナレッジを作成してみたところ、期待していた回答が得られないという問題に直面しました。
調査を進めると、根本的な原因は Dify の標準機能では OCR が行われない点にありました。
本記事では、その課題と対処方法、そしてHTML構造保持に関する工夫についてまとめます。
課題1:Dify Extractorではimageのテキストが読めない
本稿では、以下のようなスキャンPDFをナレッジとして登録するときの問題について示します。

1. スキャンPDFをナレッジに追加すると「空データ」になる
スキャンPDFは画像として文字が埋め込まれているだけで、テキストレイヤーが存在しません。
そのためDify Extractorでは文字を抽出できず、ナレッジは空状態で登録されてしまいます。
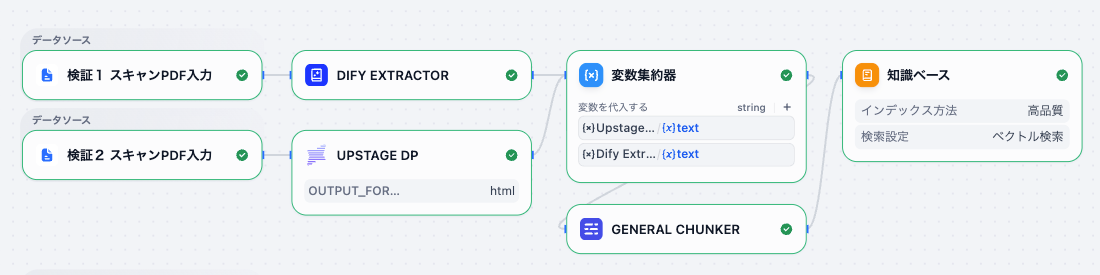
以下のナレッジパイプラインを作成して検証してみました。

以下のDify Extractorの出力結果の通り、
文字を抽出できず、空データが出力されていることが確認できます。

2. 画像ファイルはそもそも選択できない
Difyの標準ナレッジ作成画面とDify Extractorでは、
JPEG・PNGなどの画像ファイルを直接アップロードできません。
【Difyの標準ナレッジ作成画面】 :画像ファイルの選択ができない

【Dify Extractor】 :画像ファイルの入力ができない

つまりDifyの標準機能では、
imageデータのテキストを抽出する機能が備わっていないことがわかります。
対策1:Upstage Document Parse(以下DP)プラグインの活用
これらの問題を回避するため、こちらの記事 でも紹介している
UpstageのDPを利用するプラグインを導入しました。
Upstage Document Parse を活用したプラグインにより、以下の項目が可能になります。
- スキャンPDFでもOCRでテキスト化
- テーブル情報などを含む構造化データを出力
- 画像ファイルからのテキスト抽出
実際に出力を確認
以下の通り、スキャンPDFでもしっかりテキストが抽出されていることが分かり、
OCR自体は問題なく動作してることが確認できました。
【ナレッジパイプラインにUpstage Document Parse プラグインノードを追加】
【テストランの結果 出力されていることを確認】

新たな問題:テーブル内の情報等、誤った回答がある
ナレッジベースを再作成して動作検証を行った結果、誤った回答が確認されました。
- 質問:
「低炭素投資ROI」「Scope3開示率向上」「2024気候戦略案」などが並んでいる
KPI一覧テーブルについて、データ品質上のゆらぎ
(例:仮置き値多数、担当者別定義不一致 など)を記述している列の
ヘッダー名を、テーブルに書かれているとおり正確に答えてください。
- 期待する回答:
「備考(品質ゆらぎ)」
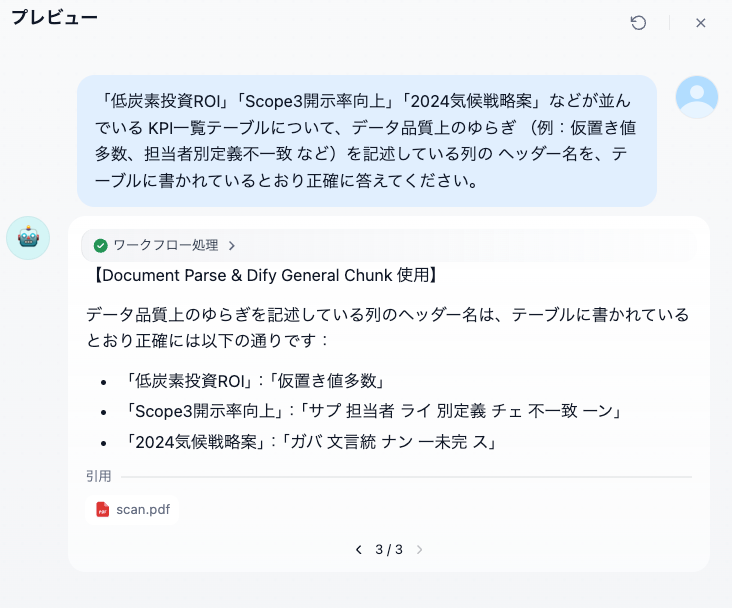
上のようないくつかの質問で、誤った回答をする挙動を確認できました。
調査の結果、以下の問題が判明しました。
課題2:HTML(table)構造を保持できない
Upstage Document Parse はHTML構造で結果を出力します。
しかしDifyのGeneral Chunkerは、HTML構造を理解しないため、次の問題が発生します。
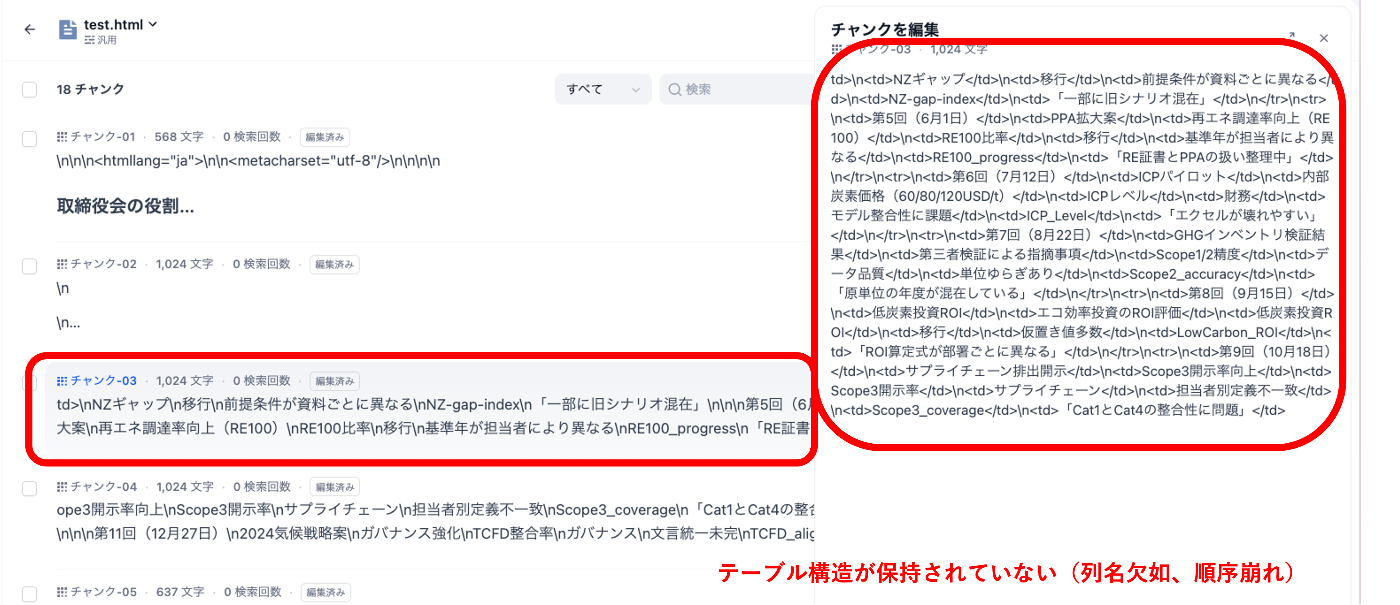
- テーブルが途中で分割されることにより、行・列の対応関係が壊れる
- 対応関係が崩れることで、「この値がどの列なのか」が分からなくなる
- LLMが参照するデータが誤っているため、誤った回答が出力される
以下のとおりHTML(table)構造が崩れている状態であることを確認しました。
対策2:HTML Chunk プラグインを自作して構造を維持
調査の結果
Difyの標準機能だけでHTML構造を保持したチャンキングを行うのは困難であることが分かりました。
そこで独自に簡易的な HTML Chunkプラグインを自作しました。
プラグインの機能
- テーブルが分割される場合、列名(ヘッダ)を自動で補完※
- HTMLの階層構造を解析し、文章ブロック単位で適切にチャンキング
※今回はデモ用にロジックを簡易実装しています。
以下のようにナレッジパイプラインを更新し、ナレッジベースを再作成した結果、
テーブル構造を保持したままチャンキングしていることを確認しました。
【HTML Chunker を追加】

【テーブル構造を保持】

以下の通り、回答精度についても改善したことが確認できました。
- 質問:
「低炭素投資ROI」「Scope3開示率向上」「2024気候戦略案」などが並んでいる
KPI一覧テーブルについて、データ品質上のゆらぎ
(例:仮置き値多数、担当者別定義不一致 など)を記述している列の
ヘッダー名を、テーブルに書かれているとおり正確に答えてください。
- 期待する回答:
「備考(品質ゆらぎ)」

結果
構造を保った状態でチャンキングされたデータをナレッジに登録したところ、
これまで取得できなかったテーブル情報を正しく参照し、
期待通りの回答が返ってくるようになったことを確認しました。
| No | 抽出方法 | チャンカー | 課題・RAGの精度 | 原因 |
|---|---|---|---|---|
| 1 | Dify Extractor | Dify General Chunk | 回答不可 | DifyExtractor OCR非対応のため空データ。 |
| 2 | Upstage Document Parse | Dify General Chunk | 誤ることがある。 | テーブル構造が崩れるため。テキスト抽出に適したChunkingを行う必要あり |
| 3 | Upstage Document Parse | HTML Chunk(自作) | 意図通りの結果 | なし |
まとめ
本検証では、Dify を使用した RAG アプリ構築において次の2つの課題が明らかになりました。
- Difyの "標準機能だけでは"、スキャンPDF・画像を正しく扱えない。
- HTML出力しても、"General Chunker" ではテーブル構造を保持できない。
これらの問題に対し、
- Upstage Document AIによる構造化出力(HTML)
- テーブル構造を保持するチャンキング処理
を組み合わせることで、
スキャンPDF/画像ファイルでもナレッジベースを構築可能であることが分かりました。
今回のDify Extractor × Upstage Document Parseの検証を通して、
RAG構築における、インプットに適した前処理の選択・チャンキング戦略の難しさについて考える機会になりました。
今後も技術調査/検証を継続していきたいと思います。
では!

Discussion