目的
- Sentinel-2データの土地利用分類。
Sentinel-2 は、ESA(欧州宇宙機関)が提供する リモートセンシングでもっともよくつかわれるフリーの高品質なデータです。
土地利用分類の分類を自前で学習して分類してみようという企画です。
リモートセンシングのデータの基礎操作を一通りやってみます。

参考
-
Sentinel-2 などの用語説明について
-
NDVI (植生/NDWI・水指数)について
NDVI(正規化植生指数)は、衛星画像の赤色バンドと近赤外バンドを用いて植生の活性度を評価する 指標です。
値は -1〜1 の範囲をとり、値が高いほど植生が活発であることを示します。NDWI(水域指数)は、近赤外バンドと短波赤外バンドを使って水域の分布を抽出する指標です。
どちらもリモートセンシングで土地被覆分類や環境モニタリングに広く利用されています。計算式とバンド
-
NDVI = (B08 - B04) / (B08 + B04)
- B08: 近赤外バンド(NIR, 10m解像度)
- B04: 赤色バンド(Red, 10m解像度)
-
NDWI = (B08 - B11) / (B08 + B11)
- B08: 近赤外バンド(NIR, 10m解像度)
- B11: 短波赤外バンド(SWIR, 20m解像度)
-
Sentinel-2 のデータ取得方法
Sentinel-2 データの主な取得方法は以下の通りです。
① Copernicus Open Access Hub(旧:SciHub)
- Sentinel-1~5シリーズのデータがすべてダウンロード可能。
- Copernicus Open Access Hub
- アカウント登録(無料)が必要。
- Webブラウザ上でエリア・期間・雲量などを指定して検索・ダウンロード可能。
- ただしHPを操作して手動で zip ファイルを持ってくる必要があるという制限がある。
② Sentinel Hub(Commercial API/無料枠あり)
- PythonなどからAPI経由で取得可能。
- Sentinel Hub
- 30日間の無料枠あり。それ以降は 300 EURO/月~
③ Google Earth Engine(GEE)
- ダウンロードせず、解析・可視化・雲除去などをスクリプトで実行可能。
- Google Earth Engine
- 登録が必要
- 前回の Tech-Blogのお題
https://zenn.dev/fusic/articles/d21ac63d8d3c69
④ AWS Open Data Registry(Amazon S3)
- Sentinel-2のL1C/L2Aデータを HTTP または S3 API 経由で取得可能。
- 登録などは不要
- AWS Open Data Registry: Sentinel-2
今回は④ AWS Open Data Registryを利用します。
②のSentinel Hub APIを使った自動ダウンロード例は、
src/utils/download_sentinel.py および configs/sentinel-hub/ で実装しています。
興味がある方はそちらをご参照ください。
実装
こちらで実装を公開しています。
1. 衛星データを取得
# 個別に処理
python -m src.pipeline.download \
--output data/example_run2 \
--config "configs/download_fukuoka.yaml" \
--name fukuoka
# まとめて処理
bash scripts/download_sentinel2.sh
設定ファイル(YAML形式)に記載されたパラメータ(緯度・経度・期間など)に基づき、Sentinel-2 衛星データを自動でダウンロードします。
- 設定ファイルからダウンロード条件(座標・期間・バンドなど)を読み込み
- AWSから、指定範囲・期間・雲被覆率の衛星画像を検索・ダウンロード
- クラスデータが入っているSCLから、有効領域の MASK.tifを作成
- MASK.tif から、有効画素率でフィルタリング
AWS COG + STAC のデータを、ESA公式のAPI(Sentinel-Hub)で雲の少ない日時のL2A(Sentinel-2のプロダクト)と同等のデータに加工します。
2. 雲除去処理の実行
# 個別に処理
python -m src.pipeline.cloud_removal \
--input-dir "data/example_run/Sentinel-2/fukuoka"
# まとめて処理
bash scripts/cloud_removal_sentinel2.sh
ダウンロード済みのSentinel-2 L2Aデータに対して雲除去を行います。
src/pipeline/cloud_removal.py は、指定ディレクトリ内の各日付シーンごとに雲マスクを適用し、雲や影の影響を受けたピクセルを自動的にマスク(無効化)します。
- SCLバンドやdataMaskバンドを用いて雲・影領域を判定
- 雲・影と判定されたピクセルを、全バンド画像で無効値(例:-9999)に置換
- 雲除去済みの画像を上書き保存
この処理により、後続の解析やモザイク処理で雲の影響を大幅に低減できます。
3. 複数の日時の雲除去された部分でモザイク処理(統合処理)を行う
# 個別に処理
python -m src.pipeline.mosaic \
--input-dir "data/example_run/Sentinel-2/fukuoka" \
--method best
# まとめて処理
bash scripts/mosaic_sentinel2.sh
複数日時の雲除去済みSentinel-2データ(各日付サブフォルダ内のBANDS.tif等)を統合し、雲の少ないピクセルを優先的に選択して1枚のモザイク画像を作成します。
- 複数の日付サブフォルダのBANDS.tif(およびSCL.tif, MASK.tif)を収集
- SCL(シーン分類)情報を活用し、雲や影の少ないピクセルを優先して統合
-
best:各ピクセル位置で最も良好な(雲のない)値を選択 -
median:雲のないピクセルの中央値を合成
-
- SCL.tifやMASK.tifも同様にモザイク処理
この処理により、複数日時のデータから雲の影響を最小限に抑えた高品質な合成画像を得ることができます。
4. ESA WorldCoverという土地利用分類の教師データを集める
# 個別に処理
python -m src.utils.download_worldcover_datasets \
--bbox 30 129 34 132 \
--output "data/wc2021_kyusyu_bbox" \
--version v200/2021/map/
# まとめて処理
bash scripts/download_worldcover_for_label.sh
上記のような ESA WorldCover(2021年版など)の土地利用分類データを、指定した範囲(国名またはバウンディングボックス)で自動的にダウンロードします。
- 指定範囲に重なる3度×3度タイルのリストを自動で計算
- 各タイルのGeoTIFF(例: ESA_WorldCover_10m_2021_v200_N33E130_Map.tif)をS3から取得
- 国名指定(--country)もしくは緯度経度範囲(--bbox)で取得範囲を指定できます。
取得したデータは後続のラベル生成や機械学習にそのまま活用できます。
ラベルの内容は以下になります。
- 0 : データなし(マスク領域)
- 10 : 樹木被覆
- 20 : 低木地
- 30 : 草地
- 40 : 農地
- 50 : 建物域(市街地)
- 60 : 裸地/疎植生地
- 70 : 雪氷域
- 80 : 常時水域
- 90 : 湿地(草本湿地)
- 95 : マングローブ
- 100 : コケ・地衣類
5. NDVI(植生/NDWI・水指数)を特徴量として計算
# 個別に処理
python -m src.pipeline.preprocess \
# まとめて処理
bash scripts/preprocess_sentinel2.sh
Sentinel-2データに対してNDVIやNDWIなどの植生・水域指標を計算し、特徴量として保存します。
- 設定ファイル(YAML)から計算対象のバンドやパラメータを読み込み
- 各シーンのBANDS.tif等から必要なバンド(例:B04, B08, B11)を抽出
- NDVI, NDWIなどの指標をピクセルごとに計算
この処理により、後続の機械学習や解析のための特徴量データセットが作成されます。
6. 教師データを作成
# 個別に処理
python -m src.utils.worldcover_to_label \
# まとめて処理
bash scripts/create_labels_of_bbox.sh
WorldCoverの土地利用分類データ(ラベル画像)と、Sentinel-2の観測データを重ね合わせて、機械学習用の教師データ(ラベル画像)を作成します。
- WorldCoverディレクトリからラベル画像(GeoTIFF)を読み込み
- Sentinel-2ディレクトリ内の各シーンと空間的に重なる範囲を抽出
- 必要に応じてリサンプリングや座標系変換を行い、ラベル画像と観測データのピクセルを対応させ、土地利用クラス(例:森林、農地、水域など)のラベルを割り当て
この処理により、衛星画像と正解ラベルが対応した教師データセットを生成、土地利用分類などの機械学習タスクに活用できます。
7. RandomForestで、学習
# 個別に処理
python -m src.pipeline.train \
--config configs/train.yaml \
--output-dir data/outputs/model_example \
--verbose 1
# まとめて処理
bash scripts/train_model.sh
前処理済みの特徴量データと教師データ(ラベル画像)を用いて、RandomForestによる土地利用分類モデルの学習を行います。
-
設定ファイル(train.yaml)から学習パラメータや入力データのパスを読み込み
\quad - data/example_run/Sentinel-2/kitakyusyu
- data/example_run/Sentinel-2/oita
- data/example_run/Sentinel-2/karatzu
-
NDVIやバンド値などの特徴量と、対応するラベル画像を読み込んで学習用データセットを作成
-
RandomForestの分類モデルを訓練データで学習
-
学習過程や評価指標(例:精度、損失、混同行列など)を出力
この処理により、衛星画像から土地利用を分類するための機械学習モデルが作成されます。

8. RandomForestで推論します
# 個別に処理
python -m src.pipeline.predict \
--config configs/predict.yaml \
--model-dir data/outputs/model_example \
--input-dir "data/example_run/Sentinel-2/fukuoka" \
--output-dir "data/outputs/prediction_example/fukuoka"
# まとめて処理
bash scripts/predict_sentinel2.sh
学習済みのRandomForestモデルを用いて、Sentinel-2データに対する土地利用分類の推論(予測)を行います。
-
設定ファイル(predict.yaml)から推論パラメータや入力データのパスを読み込み
-
特徴量データ(NDVIやバンド値など)を読み込み
-
学習済みモデルをロードし、各ピクセルごとに土地利用クラスを予測
-
予測結果をラスタ画像(GeoTIFF等)として保存
-
学習データで使っていない以下の地域の推論を行った。
- data/example_run/Sentinel-2/fukuoka
- data/example_run/Sentinel-2/hita
この処理により、未知の地域や時期の衛星画像に対して土地利用分類結果を得ることができます。
結果の検証
推論結果
左から、推論結果(predict.tif), 正解ラベル(label.tif)との差分, 元の衛星データ になります。
- 水田のラベル(地上の水域)をうまく推論できない。
- asoの推論では、教師データに火山の岩山のような地形がないので、岩肌の分類ができていない。
水田のラベルは、ESA World Cover の教師でデータは 40: 農地 として分類されており、
畑と水田が同じ扱いになっています。
水田は、季節により、30:草地, 40 : 農地, 90 : 湿地(草本湿地) 等、かなり特徴量が変わるので水田文化のところでは、難しいラベル構成といえそうです(ちなみに推論は1月~2月なので、草地が近いか)。
また、今回使った教師データには、岩肌のデータが少なく学習できていませんでした。
全般的に下記の 土地利用分類ののラベルを学習するにはデータバリエーションが足りない印象です。
- 0 : データなし(マスク領域)
- 10 : 樹木被覆
- 20 : 低木地
- 30 : 草地
- 40 : 農地 ← 学習データほぼなし
- 50 : 建物域(市街地)
- 60 : 裸地/疎植生地 ← 学習データほぼなし
- 70 : 雪氷域 ← 学習データほぼなし
- 80 : 常時水域
- 90 : 湿地(草本湿地)
- 95 : マングローブ
- 100 : コケ・地衣類
左図:推論結果, 中央図:ラベルとの差分(間違い), 右図(元の画像)
- fukuoka
水田部分を、木々として誤検出

- hita
水田部分を、木々として誤検出

- aso
水田、岩場を誤検出

学習データを改善してみた場合
学習に使った地域は、水田が少なく、岩場もない。多様性が少ないといえる。
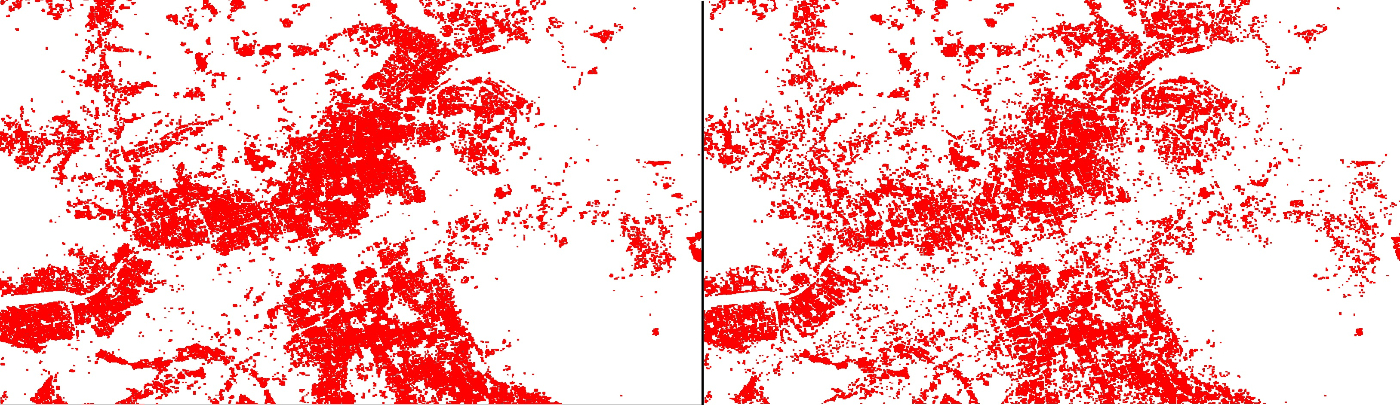
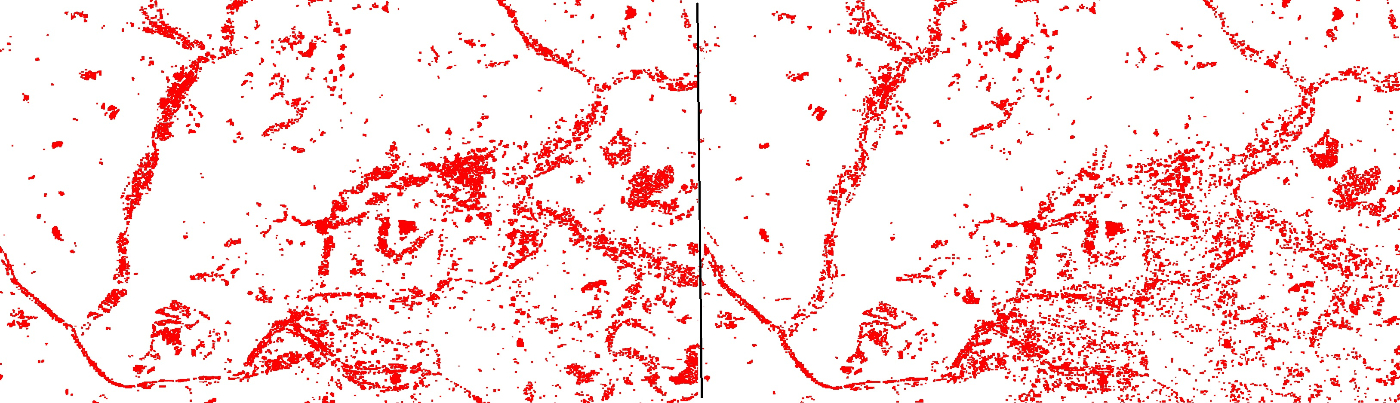
水田と岩場など豊富な環境があるasoを加えて学習し推論してみた。(左:前回、右:asoを増やした結果)
水田の誤検出が面積比では30%以上減っているように見える。
- fukuoka
- hita
より改良を行っていく場合には、以下が考えられます。
- 照度差や季節差の影響を低減する前処理(明るさの正規化、対照的な指標の追加)
- クラス不均衡への対策(重み付け・層別サンプリング)
- NDVI/NDWI 以外のNDMI/NBR/MSAVI/EVIなどの特徴量の導入
まとめ
Sentinel-2 の L2A データを AWS COG から取得し、雲除去・モザイク統合を経て ESA WorldCover の教師ラベルと組み合わせ、NDVI/NDWI などの特徴量を計算して土地利用分類モデルを自前で学習・推論する手順を一通りやってみました。
RandomForestを使った学習で、少ない学習データで、それなりの精度が出せることがわかりましたが、これをベースに、前処理や特徴量、データセットのクラス不均衡対策などで精度アップしていく余地があります。

Discussion