この記事はFusic Advent Calendar 2023の11日目の記事です。
Terraformを使ってADFを作ってみたいと思います。
環境
Terraform: v1.6.6
Azure CLI: 2.55.0
事前準備
Terraform用のサービスプリンシパルの作成、ADFの有効化、リソースグループ、ストレージアカウント、tfstateファイル格納用コンテナの作成を行っておきます。
az login
az account set --subscription "<Subscription ID>"
az ad sp create-for-rbac --name <service_principal_name> --role Contributor --scopes /subscriptions/<subscription_id>
az provider register --namespace "Microsoft.DataFactory"
RESOURCE_GROUP_NAME=<resource group name>
STORAGE_ACCOUNT_NAME=<storage account name>
CONTAINER_NAME=<container name>
az group create --name $RESOURCE_GROUP_NAME --location japaneast
az storage account create --resource-group $RESOURCE_GROUP_NAME --name $STORAGE_ACCOUNT_NAME --sku Standard_LRS --encryption-services blob
az storage container create --name $CONTAINER_NAME --account-name $STORAGE_ACCOUNT_NAME
このとき出力されたサービスプリンシパルのクライアントIDやパスワードは、Terraformのprovider設定に必要ですのでメモしておきます。
実装
ファイル全体
全体を一つにしたものは以下に記載します。
tfファイル全体
provider "azurerm" {
features {}
subscription_id = var.subscription_id
tenant_id = var.tenant_id
client_id = var.client_id
client_secret = var.client_secret
}
terraform {
required_providers {
azurerm = {
source = "hashicorp/azurerm"
version = ">=3.75.0"
}
}
backend "azurerm" {
resource_group_name = "<resource group name>"
storage_account_name = "<storage account name>"
container_name = "<container name>"
key = "terraform.tfstate"
}
}
# ストレージアカウント作成
resource "azurerm_storage_account" "main_sa" {
name = "<storage account name 2>"
resource_group_name = var.rg_name
location = var.location
account_tier = "Standard"
account_replication_type = "RAGRS"
}
# コンテナ作成
resource "azurerm_storage_container" "src_container" {
name = "src-container"
storage_account_name = azurerm_storage_account.main_sa.name
container_access_type = "private"
}
resource "azurerm_storage_container" "dst_container" {
name = "dst-container"
storage_account_name = azurerm_storage_account.main_sa.name
container_access_type = "private"
}
# Data Factory作成
resource "azurerm_data_factory" "factory" {
name = "<data factory name>"
location = var.location
resource_group_name = var.rg_name
public_network_enabled = false
}
resource "azurerm_data_factory_linked_service_azure_blob_storage" "blob_link_service" {
name = "blob-link-service"
data_factory_id = azurerm_data_factory.factory.id
connection_string = azurerm_storage_account.main_sa.primary_connection_string
use_managed_identity = true
}
# Data Flow作成
resource "azurerm_data_factory_dataset_delimited_text" "src" {
name = "src_file"
data_factory_id = azurerm_data_factory.factory.id
linked_service_name = azurerm_data_factory_linked_service_azure_blob_storage.blob_link_service.name
column_delimiter = ","
row_delimiter = "\n"
first_row_as_header = true
encoding = "UTF-8"
azure_blob_storage_location {
container = azurerm_storage_container.src_container.name
filename = "src.csv"
dynamic_path_enabled = true
path = "@convertFromUtc(utcNow(),'Tokyo Standard Time','yyyy-MM-dd')"
}
}
resource "azurerm_data_factory_dataset_delimited_text" "dst" {
name = "dst_file"
data_factory_id = azurerm_data_factory.factory.id
linked_service_name = azurerm_data_factory_linked_service_azure_blob_storage.blob_link_service.name
column_delimiter = ","
row_delimiter = "\n"
first_row_as_header = true
encoding = "UTF-8"
azure_blob_storage_location {
container = azurerm_storage_container.dst_container.name
filename = "dst.csv"
dynamic_path_enabled = true
path = "@convertFromUtc(utcNow(),'Tokyo Standard Time','yyyy-MM-dd')"
}
}
resource "azurerm_data_factory_data_flow" "data_flow" {
name = "data-flow"
data_factory_id = azurerm_data_factory.factory.id
source {
name = "srcResource"
dataset {
name = azurerm_data_factory_dataset_delimited_text.src.name
}
}
sink {
name = "dstResource"
dataset {
name = azurerm_data_factory_dataset_delimited_text.dst.name
}
}
script = file("./data_flow.txt")
}
# パイプライン作成
resource "azurerm_data_factory_pipeline" "pipeline" {
name = "data-factory-pipeline"
data_factory_id = azurerm_data_factory.factory.id
activities_json = <<JSON
[
{
"name": "data-flow",
"type": "ExecuteDataFlow",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"dataflow": {
"referenceName": "${azurerm_data_factory_data_flow.data_flow.name}",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine"
}
}
]
JSON
}
ポイント
Data Factory
ストレージアカウントやコンテナを用意した後はData Factoryの大枠を作成します。
Linked Serviceの部分は接続するリソースによって、Terraformのリソースも変わってくるので注意が必要です。今回はBlobストレージにしています。
# Data Factory作成
resource "azurerm_data_factory" "factory" {
name = "<data factory name>"
location = var.location
resource_group_name = var.rg_name
public_network_enabled = false
}
resource "azurerm_data_factory_linked_service_azure_blob_storage" "blob_link_service" {
name = "blob-link-service"
data_factory_id = azurerm_data_factory.factory.id
connection_string = azurerm_storage_account.main_sa.primary_connection_string
use_managed_identity = true
}
Data Flow
データの起点であるsourceと終端であるsink、間の処理であるdata flowを作成します。
sourceとsinkでは対象のパスを動的にして、処理を実行した日(JST)を yyyy-mm-dd のフォーマットにしたフォルダーにあるファイルを対象にしています。
# Data Flow作成
resource "azurerm_data_factory_dataset_delimited_text" "src" {
name = "src_file"
data_factory_id = azurerm_data_factory.factory.id
linked_service_name = azurerm_data_factory_linked_service_azure_blob_storage.blob_link_service.name
column_delimiter = ","
row_delimiter = "\n"
first_row_as_header = true
encoding = "UTF-8"
azure_blob_storage_location {
container = azurerm_storage_container.src_container.name
filename = "src.csv"
dynamic_path_enabled = true
path = "@convertFromUtc(utcNow(),'Tokyo Standard Time','yyyy-MM-dd')"
}
}
resource "azurerm_data_factory_dataset_delimited_text" "dst" {
name = "dst_file"
data_factory_id = azurerm_data_factory.factory.id
linked_service_name = azurerm_data_factory_linked_service_azure_blob_storage.blob_link_service.name
column_delimiter = ","
row_delimiter = "\n"
first_row_as_header = true
encoding = "UTF-8"
azure_blob_storage_location {
container = azurerm_storage_container.dst_container.name
filename = "dst.csv"
dynamic_path_enabled = true
path = "@convertFromUtc(utcNow(),'Tokyo Standard Time','yyyy-MM-dd')"
}
}
resource "azurerm_data_factory_data_flow" "data_flow" {
name = "data-flow"
data_factory_id = azurerm_data_factory.factory.id
source {
name = "srcResource"
dataset {
name = azurerm_data_factory_dataset_delimited_text.src.name
}
}
sink {
name = "dstResource"
dataset {
name = azurerm_data_factory_dataset_delimited_text.dst.name
}
}
script = file("./data_flow.txt")
}
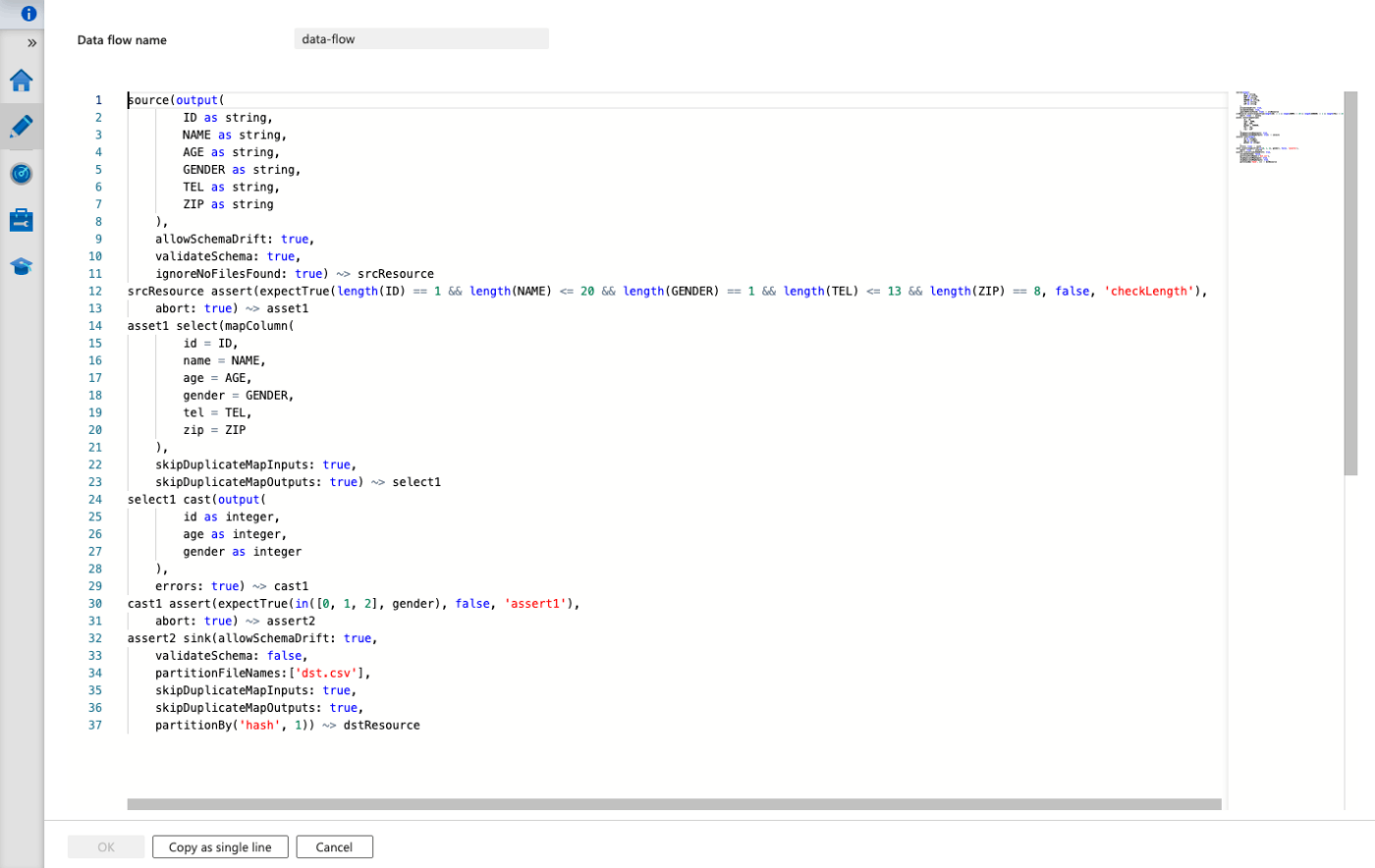
また、data flowの内容は以下のように定義します。
この内容を何も見ずに作成するのは非常に大変かと思いますので、Terraformから作成するよりは、手動でフローを確認しながら作成し、それをTerraformに残すというやり方の方が良いのかなと思います。
data_flow.txt
source(output(
ID as string,
NAME as string,
AGE as string,
GENDER as string,
TEL as string,
ZIP as string
),
allowSchemaDrift: true,
validateSchema: true,
ignoreNoFilesFound: true) ~> srcResource
srcResource assert(expectTrue(length(ID) == 1 && length(NAME) <= 20 && length(GENDER) == 1 && length(TEL) <= 13 && length(ZIP) == 8, false, 'checkLength'),
abort: true) ~> asset1
asset1 select(mapColumn(
id = ID,
name = NAME,
age = AGE,
gender = GENDER,
tel = TEL,
zip = ZIP
),
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> select1
select1 cast(output(
id as integer,
age as integer,
gender as integer
),
errors: true) ~> cast1
cast1 assert(expectTrue(in([0, 1, 2, 9], gender), false, 'assert1'),
abort: true) ~> assert2
assert2 sink(allowSchemaDrift: true,
validateSchema: false,
partitionFileNames:['dst.csv'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
partitionBy('hash', 1)) ~> dstResource
Azure Potal上では、Data Factoryの右上のこの部分をクリックすると、表示している内容が上記のような形式で確認できます。
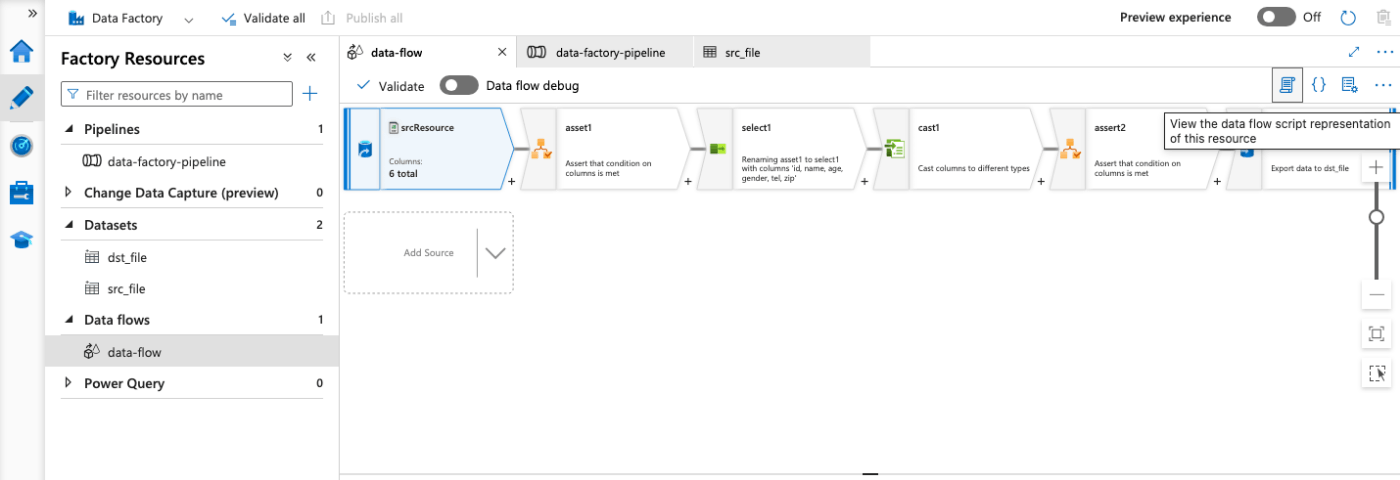
パイプライン
実際に処理を実行される単位としてはパイプラインという単位でトリガーされます。
上記で作成したdata flowやその他の処理は、アクティビティというものとしてパイプライン上で組み合わせられます。例えば、data flowが完了したら特定のファイルをコピーするといった処理や、複数のデータフローを一つのパイプラインにまとめるといったことが可能です。
# パイプライン作成
resource "azurerm_data_factory_pipeline" "pipeline" {
name = "data-factory-pipeline"
data_factory_id = azurerm_data_factory.factory.id
activities_json = <<JSON
[
{
"name": "data-flow",
"type": "ExecuteDataFlow",
"dependsOn": [],
"policy": {
"timeout": "0.12:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"dataflow": {
"referenceName": "${azurerm_data_factory_data_flow.data_flow.name}",
"type": "DataFlowReference"
},
"compute": {
"coreCount": 8,
"computeType": "General"
},
"traceLevel": "Fine"
}
}
]
JSON
}
結果
このTerraformを流してからData Factoryを見てみると、以下のようにData Flowとパイプラインが完成していることが確認できます。
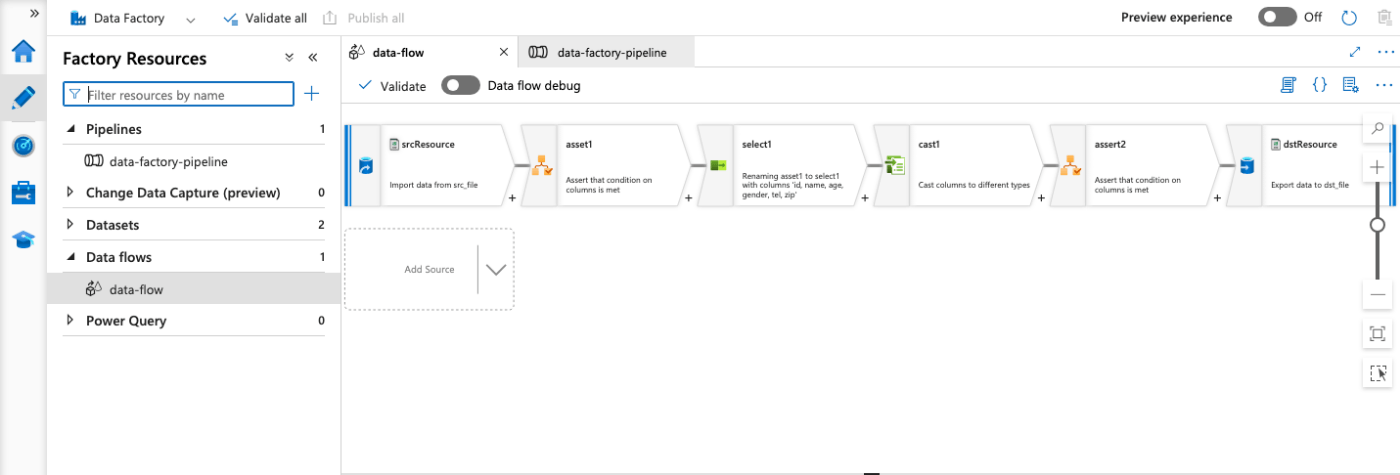
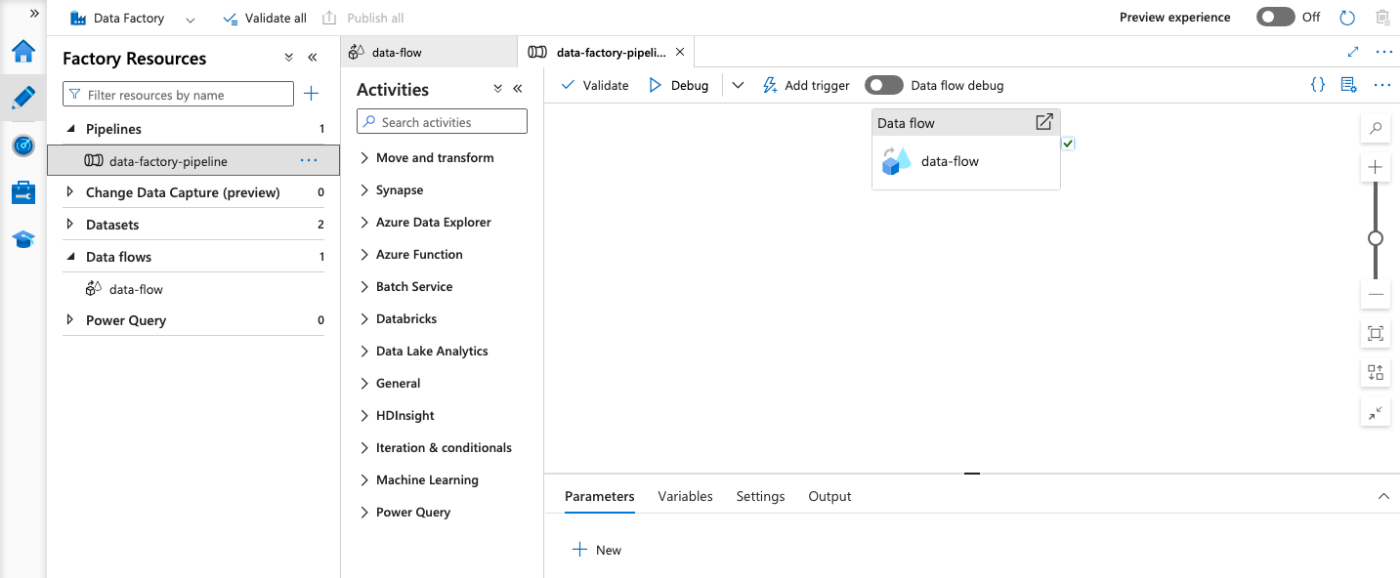
動作確認
以下のようなデータのCSVファイルをsrc-containerに配置します。
ID,NAME,AGE,GENDER,TEL,ZIP
1,test1,10,0,000-0000-0000,000-0000
2,test2,20,1,000-0000-0000,000-0000
3,test3,30,1,000-0000-0000,000-0000
4,test4,40,2,000-0000-0000,000-0000
5,test5,50,2,000-0000-0000,000-0000
この状態でデータパイプラインのトリガーを手動で実行します。
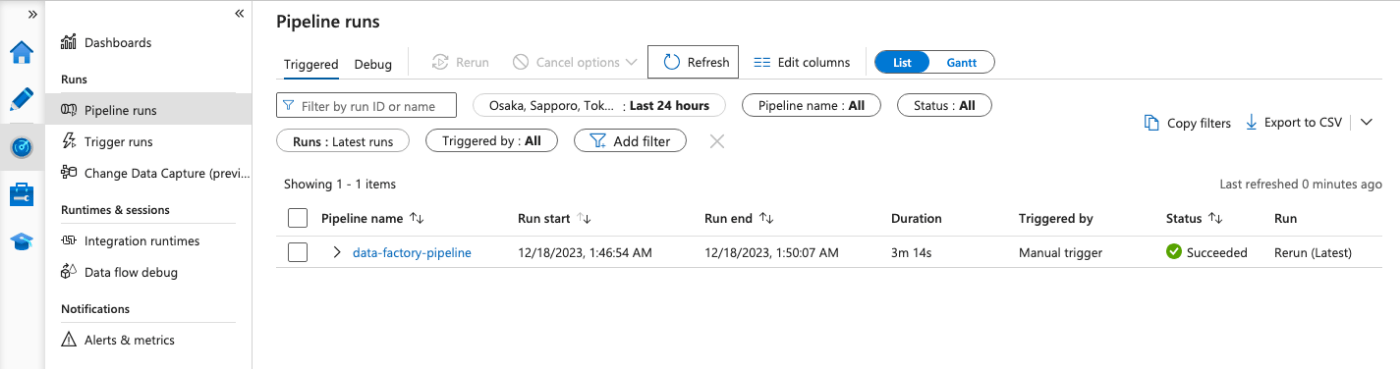
数分程待ってみると、パイプラインの実行が成功していることが確認できました。
送信先のコンテナを見ると、ちゃんと以下のようなファイルが作成されていることも確認できます。
カラム名の変更が行われていて、動作は問題なさそうです。
id,name,age,gender,tel,zip
1,test1,10,0,000-0000-0000,000-0000
2,test2,20,1,000-0000-0000,000-0000
3,test3,30,1,000-0000-0000,000-0000
4,test4,40,2,000-0000-0000,000-0000
5,test5,50,2,000-0000-0000,000-0000
では次にGENDER列の数字を一つだけ3にしたファイルを置いてからパイプラインを実行してみます。
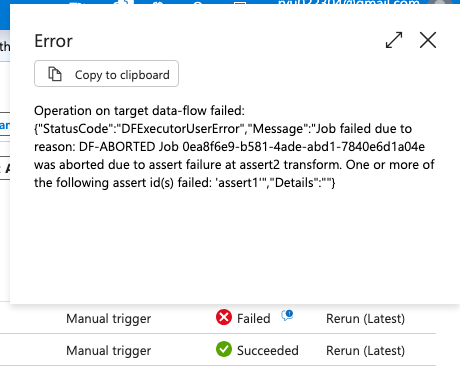
上記のようにエラーになりました。 assert1 のエラーになっていますので、数値のチェックも問題なかったようです。
まとめ
TerraformでADFを作成しました。
複数のdata flowを作成するときはやはりIaC化しておいた方が、楽になるので良いかと思います。
ただ、複雑なパイプラインになってくるとTerraform上で表現することが難しくなってくるので、data flowとパイプラインの大枠だけを作成しておき、パイプラインの詳細は手動で作成するという使い分けも行ったほうが良いかもしれません。
また、Terraformとは関係ありませんが、ADFで処理がうまく行かない時は非常に沼に陥るのでデバッグモードの活用が非常に重要でした。
参考

Discussion