はじめに
Fusicのレオナです。今回はUpstageのDocumentAIと情報抽出モデルが使用できるMCPサーバーを試してみます。なお、弊社は生成AI分野における包括的な協業を目指し、Upstageと業務提携を結んでおります。詳細はこちらからご覧ください。
MCP: Model Context Protocolとは
Anthropicが公開したIntroducing the Model Context Protocolから引用すると、MCPは複数のシステムに散在するデータを統一的に管理するためのオープンスタンダードです。コンテンツリポジトリ、業務用ツール、開発環境など、さまざまなデータソース間で、安全かつ効率的に情報をやりとりする手法となります。
MCPのGeneral architectureについて

- Host:
- Claude Desktop や VS Code, Cursor,Windsurf,ClineなどのLLMを搭載した全体のアプリケーションを指す
- MCP Client:
- サーバーと1:1の接続部分であり、サーバーとの通信を維持するクライアント
- MCP Server:
- 標準化されたModel Context Protocolを通じて特定の機能を提供するプログラム
- Local Data Sources:
- MCP サーバーが安全にアクセスできるローカルのファイルやサービス
- Remote Services
- MCPサーバーが接続できる、インターネット上で利用可能な外部システム(例:API経由でアクセスできるものなど)
今回のUpstage MCP Serverは、この仕組みの中で Remote Servicesに該当します。
Upstage MCP Serverとは?
Upstage MCP Serverは、Claude DesktopなどのMCP Clientを通して、PDFや画像、Office系ダイルを自然言語でテキストを抽出・構造化して返すことができます。
テキストを抽出・構造化についてはUpstageのDocumentAIモデルであるDocumentParseと情報抽出モデルであるUniversal Information Extractionが提供されています
詳しくは以下のブログをご覧ください。
ローカルでMCPサーバーを立てる方法を本ブログで解説しますが、AWS MarketplaceでもUpstage MCPとして提供されています。
MCPサーバーを使うための準備
必要なもの
今回は、Macの環境になります。MCP HostはClaude Desktopを使用しました。
Pythonパッケージ兼プロジェクト管理ツールであるuvを利用します。詳細は、公式ページを参照してください。
- ターミナルで
brew install uvでuvをインストール - ターミナルで
uv python install 3.10でPython 3.10版をインストール - ターミナルで
uv pip install mcp-upstageでMCPサーバーのインストール
Claude Desktopとの連携
Claude DesktopからMCPサーバーを利用するには、設定ファイル claude_desktop_config.json にサーバーの定義を追加します。
{
"mcpServers": {
"mcp-upstage": {
"command": "uvx",
"args": ["mcp-upstage"],
"env": {
"UPSTAGE_API_KEY": "<your-api-key>"
}
}
}
}
設定ができたら画像の通りになります。
使ってみる① DocumentParse
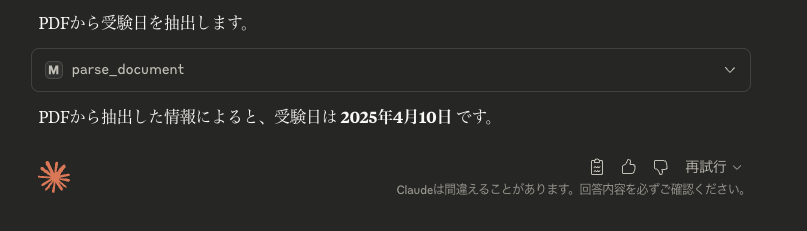
今回はAWS認定の結果PDFを使用して、受験日を聞いてみます。以下がデータになります。

質問:mcp-upstageのparse_documentを使って'<PDFがあるpath名>.pdf'のいつ受験したか日付だけを教えてください
結果:parse_documentを使用して正しい日付を取得できました。
使ってみる② Universal Information Extraction
同じく、AWS認定の結果PDFを使用して、受験日を聞いてみます。
質問:mcp-upstageのextract_informationを使って'<PDFがあるpath名>.pdf'のいつ受験したか日付だけを教えてください
結果:extract_informationを使用して正しい日付を取得できました。

最後に
本ブログでは、Upstage MCPサーバーを使ってClaude Desktopからドキュメント解析を実行する手順を紹介しました。自然言語でPDFや画像から必要な情報を取り出すことができました。

Discussion