こんにちは、Fusicのハンです。株式会社Fusicでは機械学習関連のPoCから開発・運用まで様々なご相談に対応してます。もし困っていることがありましたら気軽にお声かけてください。
今回は「TTSモデルの軽量化」というコンセプトで2023年2月発表されたLightweight and High-Fidelity End-to-End Text-to-Speech with Multi-Band Generation and Inverse Short-Time Fourier Transformという論文を紹介しようと思いますので、よろしくお願いします。
Lightweight and High-Fidelity End-to-End Text-to-Speech with Multi-Band Generation and Inverse Short-Time Fourier Transformは、VITSのVocoderを「Multi-Band GenerationとiSTFT(inverse Short-Time Fourier Transform)」に置き換える手法を提案しています。普段目にする論文は「VC・TTSの性能やZero-Shot生成」に関するものが多いという感想でしたが、非常に興味深い論文だと思いました。またコードや学習済みモデルもGithubに公開されてますので、すごくありがたいです。
STFT(Short-Time Fourier Transform)とMulti-Band
論文名から分かると思いますが、「STFT」と「Multi-Band構造」がこの論文の軸になる概念です。なので、この概念を理解することで大分論文の理解度が上がるのではないかと思います。
STFTの良さはなに?
STFTは音のSpectrogramを生成する方法の一つで、「時間・周波数の観点」で音を分析する時に使われます。一般的に音の可視化を考えると、時間ドメインの波形を思い出すことが多いと思いますが、
- 周波数の可視化
- 時間変化による周波数の変換分析
- 音のパタン分析
- 情報圧縮の効率
などを考えるとSpectrogramの方は優れている面が多いので、音声分析の領域ではよく使われている概念です。
STFTに関しては数多い情報があると思いますので、ここでは簡単な例でSTFTを利用するとどのような情報が得られるかを確認したいと思います。
波形は扱いにくい
下の波形は、以下のようなコードで生成した2つのコサイン信号を
- 2秒間合体
- 1秒ずつ切って連結
した物の一部です。
freq1 = 60 # 60Hz
freq2 = 120 # 120Hz
# シグナル生成
signal1 = np.cos(2 * np.pi * freq1 * t)
signal2 = 2 * np.cos(2 * np.pi * freq2 * t)
波形(Signal) 60Hz 120Hz(dBは60Hzの2倍)の組み合わせ
(Time単位が0.xxである事に注意)
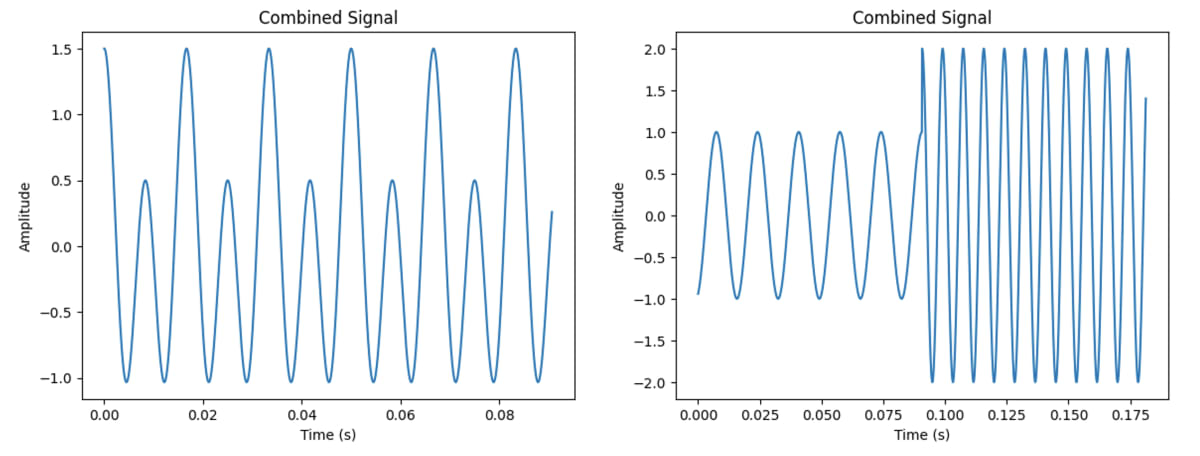
一見シンプルに見えますがこれはただ単純な例であって、実際音の波形は
- より複雑な周波数信号の組み合わせである。
- 数秒の音でもかなり長いデータになる。
という問題があるので、実はかなり扱いにくい形であります。
STFTで得られるMagnitude/Phase情報
波形データをSTFTすると、複素数の形で結果が生成され、これにより振幅(Magnitude)と位相(Phase)の情報を抽出することができます。
Magnitudeは、その時刻・周波数ドメインでどれだけ強い信号(dB)が出ているかを確認する尺度となり、STFTの絶対値を取ることで得られます。
Phaseは複素数の角度を抽出したもので、その時間に周波数成分がどれだけ移動したかを示しています。
STFTから得られたAmplitude(Magnitude)情報

STFTから得られたPhase情報

上記の2つの波形を使用して、振幅(Magnitude)と位相(phase)を抽出して視覚化しました。
Magnitude Spectrogramを通じて、60Hzと120Hzで信号が検出されていることや、120Hzの信号が2倍強いことも確認できます。
また、Phase Spectrogramから信号の角度によってピーク時点などを把握することも可能です。
注意すべき点は、このSpectrogramは、STFTのWindow Sizeの変化によって時間/周波数情報間のトレードオフが発生することです。
例えば、正確に60Hz/120Hzを抽出するためには、Window Sizeを大きくすることが助けになりますが、この場合、2番目のSpectrogramの1秒地点での境界線がぼやける現象が発生します。
この情報は、圧縮した形でありながら音の特徴を保存しているという観点から、波形情報と比べ「扱いやすい情報」とも言えます。
上で説明した波形(Wave)からSTFTの変換、そして振幅(Magnitude)/位相(Phase)の抽出は、機械学習モデルを利用するのではなく、信号処理アルゴリズムを利用したものです。そのため、これを逆算することで、振幅/位相情報から波形を生成することが可能です。この過程を「iSTFT(inverse STFT)」と言います。
Multi-Bandの良さはなに?
ここでのMulti-Bandという意味は、「全ての帯域(Full-Band)の波形を一気に生成するのではなく、いくつかの細かい帯域(Sub-Band)に分けて別の処理を行う」という意味で理解すれば良いと思います。本論文で参照したMULTI-BAND MELGAN: FASTER WAVEFORM GENERATION FOR HIGH-QUALITY TEXT-TO-SPEECHでのFigure1を添付します。
出典:MULTI-BAND MELGAN: FASTER WAVEFORM GENERATION FOR HIGH-QUALITY TEXT-TO-SPEECH
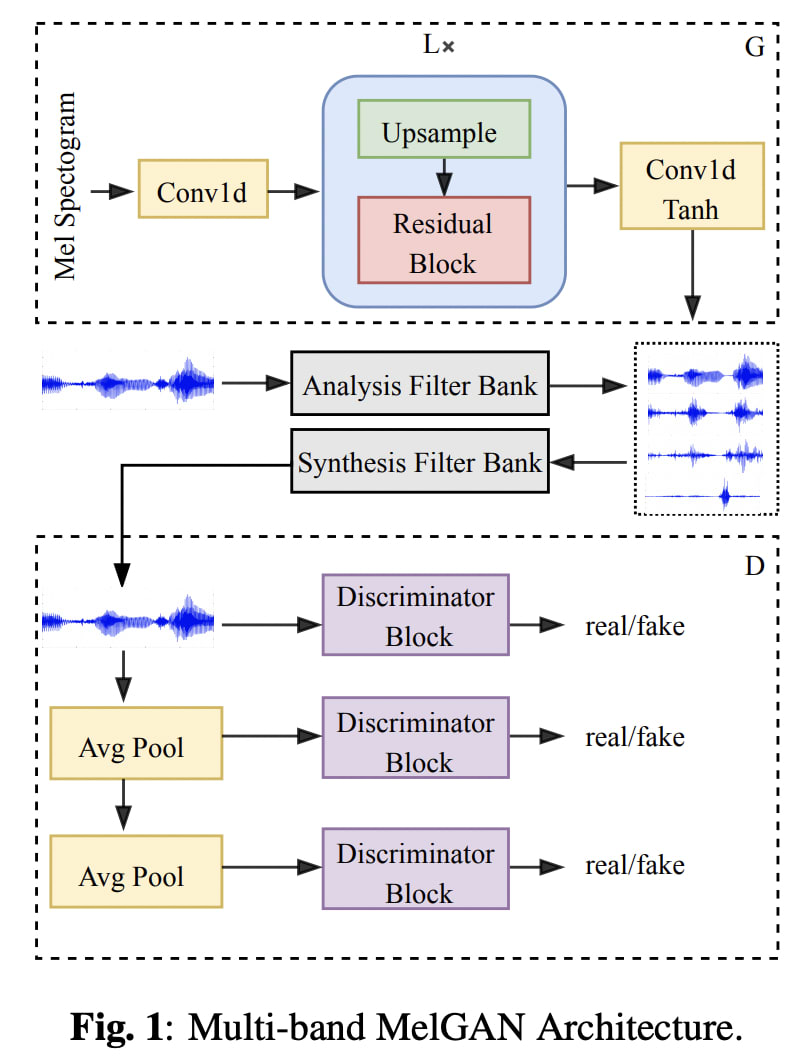
図の上部と中央部に注目してください。G(Generator)は、それぞれ異なる帯域の4つのWaveを生成し、それらを合成して1つのWaveを作成した後、D(Discriminator)に送信しています。このような、Multi-Bandを利用することで
- Sub-Bandから生成されたWaveを用いたLossが取れる。
- Sub-Bandのノイズが合成の祭、緩和される可能性がある。
- 特定帯域Sub-Band別の最適化を行うので、学習の収束が早い。
- Sub-Band処理を並列化することで、学習・推論速度が早い。
などの効果が期待されます。
論文について
この論文の主な内容を要約すると、VITSのGANベースのボコーダを、Multi-BandとiSTFTを利用したボコーダに置き換えたことです。
従来のGANベースボコーダは、複数のCNN層を持つモデルで構成されています。これによって、学習・推論速度が遅くなる懸念があり、ブラックボックスモデリングに基づくため、学習の不安定さや生成結果の分析にも困難があるという問題点があります。
しかし、iSTFTは明確な信号処理アルゴリズムに基づいて動作するため、ブラックボックスに関する問題点を解決でき、学習・推論時間に関する利点を得ることができます。また、並列化したMulti-Bandモデリングを使用することで、iSTFT過程で失われた音声情報を相互補完するボコーダが構成できます。
以下の図は、論文から取り出したモデルの構造を示しています。
出典:論文

左側は、Text-Spectrogramペアを使用して中間表現(z)を生成するプロセスで、VITSと同じ構造を持っています。デコーダ(ボコーダ)以降の流れは、論文で新たに提案されたMulti-Band + iSTFTボコーダの構造です。
Magnitude・Phase Spectrogramsの生成
zは、推論過程でText情報のみを使用して生成できる(H-dim, times)のサイズの中間表現で、Spectrogramに似た形を持っています。この中間表現を利用して、iSTFTの入力として必要な2種類のスペクトログラム(Magnitude・Phase)を4つずつ生成します。Output Convolution層は1つのモジュールで、一つ出力を生成し、それを4グループ2セットに分割してSpectrogramを生成するため、計算コストが効率的です。
iSTFTを利用した波形生成
上で説明したように、Magnitude・Phase情報があれば、Waveを生成することができます。4つのSpectrogramペアを利用して、それぞれの波形を生成します。
Pseudo-QMFを利用したMulti-Band分解と結合
Pseudo-QMFは、デジタル信号処理で使用されるフィルタバンク技術で、入力信号を複数の高周波と低周波バンドに分解したり、結合するために使用されます。
本論文では、これを用いて入力されたオリジナル波形を4つのMulti-Bandに分解し、上でiSTFTで生成したそれぞれの波形とMulti-Resolution STFT Lossを計算します。周波数領域ごとに分離された波形を、さらに3つのスケールを利用してLossを計算することで、さまざまなパターンと変化を学習することができます。
そして最後に、4つの分離された波形を1つに結合し、最終的なオリジナル波形と比較してLossを計算しています。Pseudo-QMFアルゴリズムを利用した結合方法(Fixed Synthesis Filter)と、学習可能な「4Channels → 1Channel」のConvolutionレイヤーを利用した結合方法(Trainable Synthesis Filter)を使用した、2つのモデルを提案します。
実験結果
出典:論文
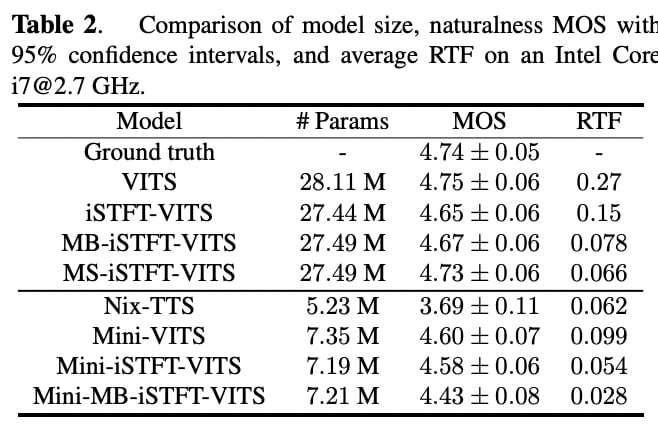
- iSTFT-VITSモデル:VITSモデルのボコーダーのCNNレイヤーを減らし、iSTFTを適用したモデル。本論文で紹介されたボコーダーのマルチバンド技術が入っていないバージョン
- MB-iSTFT-VITS:Fixed Synthesis Filterを利用して、固定された合成フィルターを使用して4つの波形を合成するモデル
- MS-iSTFT-VITS:Trainable Systhesis Filterを利用して4つの波形を合成するモデル
- Nix-TTS:知識蒸留を利用した軽量化モデル
- Mini-MODELS:パラメータを縮小したモデル
テーブルの上部で分かるように、MS-iSTFT-VITSモデルはオリジナルのVITSと似たような性能を持ちながら、4倍程度速いRTFを持っています。また、iSTFT-VITSと比較して精度・速度の面でも優れており、
- Multi-Bandを利用した学習が効果的である。
- 並列化によってさらに速い推論が可能である。
ことが分かります。
しかし、このマルチバンド技術を使用するためには、ある程度の規模(パラメータ)のモデルが必要であることが、2つ目の実験結果からわかります。
推論速度の面では前述実験と同様の傾向を示していますが、Mini-MB-iSTFT-VITSの精度は低く測定されました。これは、小さなモデルではMulti-BandのiSTFTに必要な十分な情報を取れないリスクがあることを示唆しています。
感想
学習・推論時間に役に立つ方法であり、Decoderの構造だけを入れ替えることで様々な手法に適応できるものだと思います。特にコードーが公開されているので、非常に活用度のある手法であると思います。今後Multi-Band・iSTFTを用いた実験を行ったらまた関連投稿を書きますので楽しみにしてください。

Discussion