自己紹介
こんにちは、Fusicのハンです。
普段は日本語音声合成(TTS)モデルの開発や、Document AI+LLMを使った業務効率化、その他AIに関する相談・実装支援などを行なっています。
株式会社Fusicは、AWS/Web/アプリ/IoT/AIといった幅広い技術領域の知見を活かし、IT活用の構想づくりからシステム開発・運用まで一気通貫で伴走支援している会社です。
もしご興味あれば、ぜひお気軽にお声かけください!
はじめに
最近、生成AIまわりの進化スピードが本当に速く、関連ツールやプラットフォームも次々にアップデートされています。
そんな中、Difyを試してみたところ、組み込みのテキスト抽出の精度がやや物足りない場面がありました。
そこで今回は、Upstageが提供する高精度OCRサービス、Upstage Document Parse(以下、DP)をDifyのプラグインとして使えるようにしてみました。
結果的に、添付ファイルのテキスト抽出精度を向上させつつ、ツールとして再利用しやすい形にできたので、その手順とポイントを記録しておきます。
環境設定
Debug環境でDifyプラグインを作成・テストするために、以下の準備を行いました。
- Difyにサインイン
- Difyプラグインパッケージの入手
- (任意)Python 3.12のVirtual環境を作成
- Pythonバージョンの問題でデフォルトrequirementsインストールができなかったため
python3.12 -m venv ~/.venvs/dify_dp_tool
プラグイン作成プロセス
1. 新規プラグイン作成
まずは空のプラグインを作ります。
./dify-plugin-darwin-arm64 plugin init
- Profile作成(ツール名、説明など)
- 言語選択(Pythonのみ)
- Permission設定(今回は Tools / Apps / Endpoints を有効化)
・・・
Apps:
Enabled: [✔] Ability to invoke apps like BasicChat/ChatFlow/Agent/Workflow etc.
Resources:
Storage:
Enabled: [✘] Persistence storage for the plugin
Endpoints:
→ Enabled: [✔] Ability to register endpoints
実行後、以下のようなディレクトリ構造が生成されます。
YOUR_TOOL/
├── _assets
├── GUIDE.md
├── main.py
├── manifest.yaml
├── PRIVACY.md
├── provider
├── readme
├── README.md
├── requirements.txt
└── tools
2. Debugモードでの動作確認
まずは空のツールがDifyに認識されるか確認します。
-
Debug Key取得
Difyウェブ → 右上 → 『プラグイン』
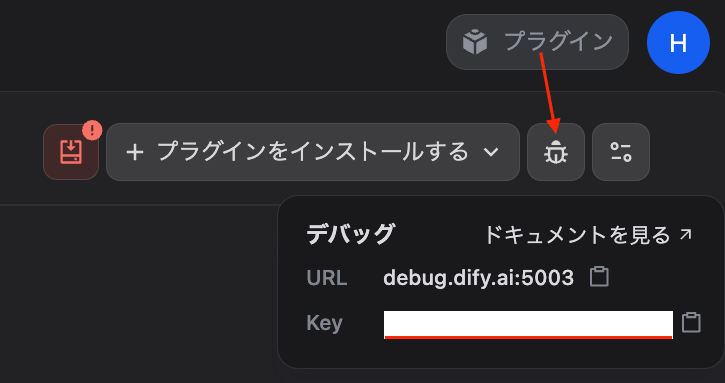
.envファイル作成
# URL / Port / Debug Keyを入力
INSTALL_METHOD=remote
REMOTE_INSTALL_URL=debug.dify.ai:5003
REMOTE_INSTALL_PORT=5003
REMOTE_INSTALL_KEY=********-****-****-****-************
- テスト起動
python main.py
Difyの画面上に作成した新規ツールが表示されればOKです。

3. プロバイダー定義と検証
プラグインの作成は主に『provider/』と『tools/』で行います。
- 詳細はドキュメント参考
まずはUpstage API Keyの利用が必要なので、API Keyを取得する仕組みを作ります。
provider/YOUR_TOOL.yaml
credentials_for_provider:
upstage_api_key:
help:
en_US: Get your Upstage API key from Upstage(https://console.upstage.ai/api-keys)
ja_JP: Upstage API key(https://console.upstage.ai/api-keys)
label:
en_US: Upstage API key
ja_JP: Upstage API key
placeholder:
en_US: Please input your Upstage Document Parse API key
ja_JP: Upstage Document Parse APIキーの入力
required: true
type: secret-input
url: https://console.upstage.ai/api-keys
# 以下はテストのため作成したもの
test_input:
help:
en_US: テストのために作成(help)
ja_JP: テストのために作成(help)
label:
en_US: テストのために作成した(label)
ja_JP: テストのために作成した(label)
placeholder:
en_US: PLACEHOLDER
ja_JP: PLACEHOLDER
required: true
type: text-input
上記コードを追加し、Difyツールの画面を確認してみました。

ここに入力されたKey情報を用いて『4.ツール実装 → Upstage APIの利用』を行います。
provider/YOUR_TOOL.py
API Keyのバリデーションを行う関数を定義できます。今回は個人利用が目的で簡略化してpassしていますが、任意のモデルの呼び出しやkey_validationの実装も可能かと思います。
def _validate_credentials(self, credentials: dict[str, Any]) -> None:
try:
api_key = credentials.get("upstage_api_key", None)
# モデル呼び出しやValidation確認のコードなど
...
except Exception as e:
raise ToolProviderCredentialValidationError(str(e))
4. ツール実装
UpstageのDPを用いて、以下の一連の作業を行うコードを作成します。
- インプット:PDF/JPGなどのファイル
- タスク:構造化+テキスト抽出(DP)
- アウトプット:テキスト抽出の結果
tools/YOUR_TOOL.yaml
ユーザーが設定可能なパラメーターを定義します。
Upstage DP APIドキュメントを確認すると以下のように様々なオプションがありますが、今回はoutput_formatsだけを選択式で設定します。
- model(モデルの選択)
- chart_recognition(チャートの認識)
- merge_multipage_tables(1ページの収まらず、複数ページに書かれたテーブルのマージ)
- output_formats(Html / Markdown / Text)
- base64_encoding
- その他
また、参考にした『teddynote-lab/dify-upstageparser-plugin』gitコードでは、
- as_file(Document AIの結果をファイルとして保存するオプション)
のパラメーターも実装してますので、ぜひご参考ください。
parameters:
- name: files
type: files
required: true
label:
en_US: upload file
ja_JP: ファイル アップロード
human_description:
en_US: upload the file to be parsed
ja_JP: ファイル アップロード
llm_description: upload the file to be parsed
form: llm
- name: result_type
type: select
required: false
default: md
label:
en_US: result form type
ja_JP: 結果の形式
human_description:
en_US: the type of the result
ja_JP: 結果の形式
options:
- value: md
label:
en_US: md
ja_JP: md
- value: html
label:
en_US: html
ja_JP: html
- value: text
label:
en_US: text
ja_JP: テキスト
llm_description: the type of the result. Either `md`, `html`, or `text`.
form: form
Difyツールの画面を確認
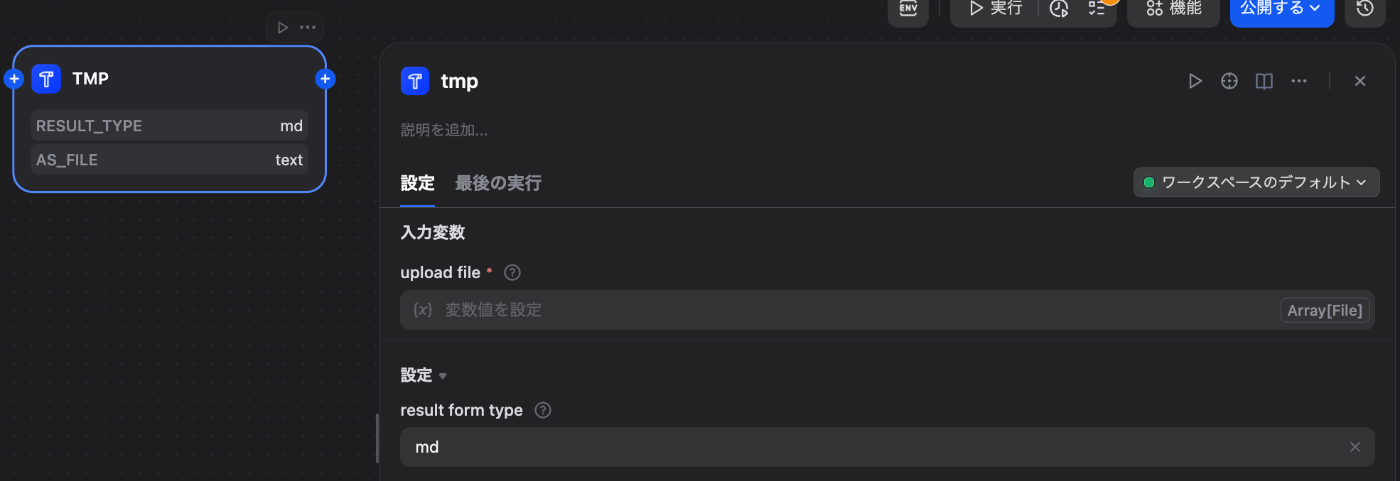
tools/YOUR_TOOL.py
実際にDPを行うコードを作成します。『teddynote-lab/dify-upstageparser-plugin』gitコードで、
- DocumentParserClientのコード
- Cacheを用いた効率化(API利用料・推論時間)
など、詳細の実装が確認できるので、ご興味のある方はぜひご参考ください。
必要なのは『_invoke』のコードであり、最低限、以下処理が考えられます。
- Upstage API Keyの取得
- パラメーターの取得
- API Request
- 結果の後処理
- 出力:テキスト・イメージ・音声など様々な形式で出力可能
実際のOCR実行コードの例(簡略化)。
def _invoke(self, tool_parameters: dict[str, Any]) -> Generator[ToolInvokeMessage]:
# Upstage API Keyの取得
api_key = self.runtime.credentials.get("upstage_api_key")
# Toolのパラメーターの取得
files = tool_parameters.get("files", None) # File Objectのリスト
result_type = tool_parameters.get("result_type", None)
# File Objectのダウンロード
file = files[0] # 一つの入力想定
file_url = file.url
・・・
with open(file_path, "wb") as f:
f.write(file_content)
# Document Parseの実行
url = "https://api.upstage.ai/v1/document-digitization/async"
files = {"document": open(file_path, "rb")}
data = {
"output_formats": result_type, # Toolのパラメーター
"ocr": "auto", # その他、Upstage DP APIのパラメーター
"model": "document-parse-250618"
・・・
}
response = requests.post(url, headers=headers, files=files, data=data)
result = postprocess(response, result_type) # 適切な後処理
# 結果
yield self.create_text_message(result)
これで、『空のツール作成』→『API Key設定』→『パラメーター設定・タスクの実装』が終わりました。
似たような流れで、Difyには無い様々なカスタムツールが作成できそうです。
ツールを試す
Difyのワークフローで、以下のように比較テストしました。
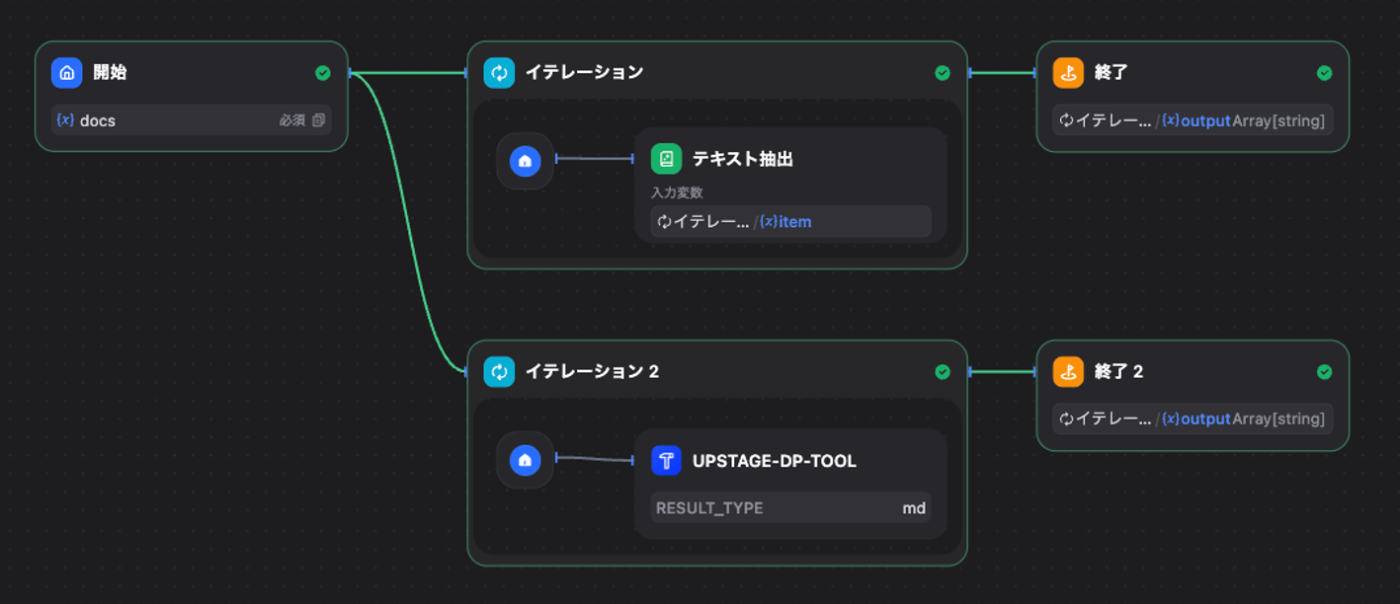
- インプット:4種類のドキュメント(届出書・見積書・料金表・レポート)
- モデル①:Difyデフォルトモデル
- モデル②:Upstage Document Parse
- 出力:各モデルの結果
結果と考察
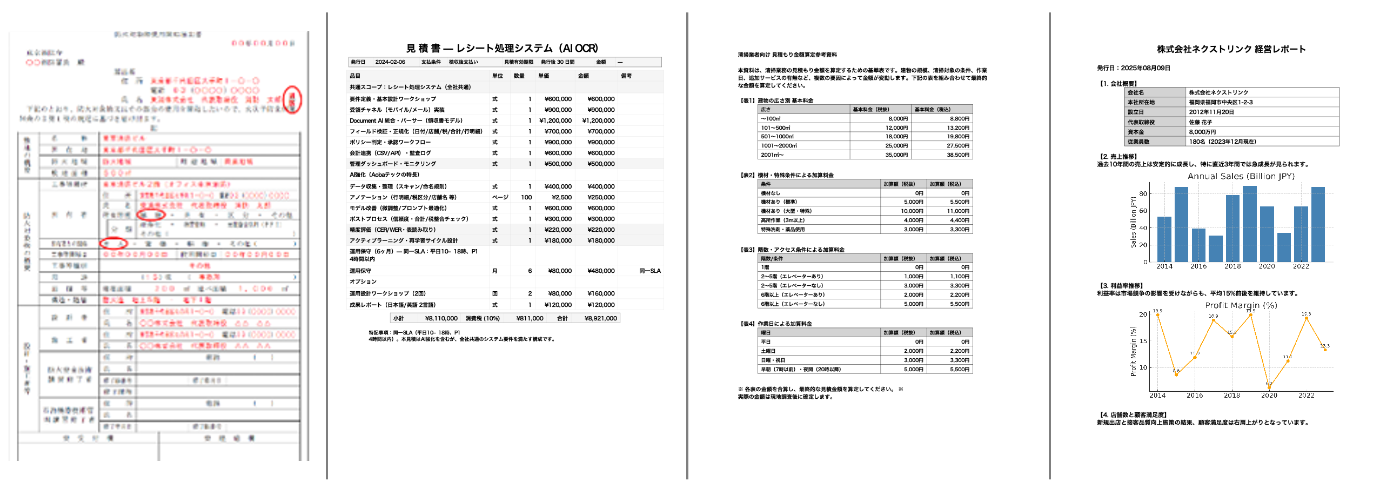
- インプットドキュメント:すべて仮のサンプルデータ
- ① 届出書:ファイル形式がイメージ
- 解像度を低くしてアップロードしています。
- ② 見積書:テーブル情報
- ③ 料金表:複数テーブル情報
- ④ レポート:グラフ情報
- ① 届出書:ファイル形式がイメージ
- Difyデフォルトモデル

- text形式(のみ)で出力
- イメージ形式ファイルのテキスト抽出に失敗
- PDFで書かれているテキスト、テーブルは認識可能
- グラフの情報やイメージがない
- 構造化(文書構造・テーブル構造)情報がない
- Upstage Document Parse

- html形式で出力
- 全データのテキスト抽出に成功
- 完璧ではないが、複雑なテーブル情報の抽出が可能
- グラフ情報の読み取り(テーブルに変換)、イメージの別途抽出が可能
- 構造化(Title / Head / Table / Image / テーブル構造 等)情報がある
細かい精度や内容の確認はしてないが、以下のような精度向上が期待できると思います。
- 画像形式のファイル(スキャン・写真など)
- 複雑なテーブル(HTML抽出で構造保持可能)
- 簡易的なグラフ(テーブル化や画像抽出が可能)
今回の実装で、Difyでも高精度なDocument AIが使えるようになり、業務効率化や精度検証がしやすくなりました。
今後はLLMとの組み合わせで、さらに自動化や高度な解析の可能性を探っていきたいです。
参考サイト

Discussion