以前に私がレビューしたPointNet++と違って、VoxelNetは3D Object Detectionが可能なネットワークです。 さらに、この論文はCVPRで2018年に発表されました。
VoxelNet開発以前の研究紹介
- まず、Point Cloudの利点についてご紹介いたします。カメラで得られる画像と比較して、LiDARで取得されるPoint Cloudは深度情報を含んでいます。そのため、物体の位置をより正確に把握でき、物体の形状をより良く認識することが可能です。
- しかしながら、欠点も存在します。Point Cloudはスパース(Sparse)な特性を持ち、位置によって密度の変動が大きい(Variable Density)という課題があります。
- この問題を解決するために開発された先行研究の方法について説明いたします。主に4つの方法に分類されます。
- 1つ目の方法は、3D Point Cloudを遠近法的視点から見た2D画像に変換する手法です。ただし、Point Cloudを2D画像に変換すると深度情報が失われるため、性能に限界があります。
- 次に、Hand-crafted Featureを使用する方法があります。Hand-crafted Featureとは、専門家が多様な特徴量の中から重要なものを選び出して利用する手法を指します。しかし、この方法では重要な特徴量を選び損ねると、新しいデータに対して堅牢性が欠けるという欠点があります。
- 最近では、PointNetおよびPointNet++という手法が登場していますが、これらの手法はPointの数が多い場合、計算量とメモリ消費量が増加するという課題があります。
※ PointNet++は、Farthest Point Sampling(FPS)アルゴリズムを使用して所定の数のPoint Cloudを抽出し、学習を進めますが、入力されるPointの数が多い場合、FPSアルゴリズムの実行に時間がかかるという問題があります。 - さらに、Point CloudとRGB情報を組み合わせて使用するMulti-modal方式もあります。この方法は情報量が多いという利点がありますが、カメラとLiDARの同期やキャリブレーション(Calibration)作業が非常に困難です。
※ ただし、同期とキャリブレーションの問題を解決すれば実用化が期待できるため、Multi-modal方式は非常に興味深い手法と考えられます。
VoxelNetとは?
- VoxelNetは、Faster R-CNNのRPN(Region Proposal Network)方式を用いて3Dオブジェクト検出を行うネットワークです。ただし、RPNは密度が均一でデータ構造が体系的な形式(例えば画像や映像)に適していると言えます。この論文では、Point CloudにRPNを適用する手法を開発しています。
- VoxelNetは、まずPoint CloudをVoxel(ボクセル)に変換し、そのVoxelから情報を抽出してRPNを利用してオブジェクトのバウンディングボックスを予測する構造を持っています。
- 論文では、自動車、歩行者、サイクリストの検出を行っています。ただし、これらの3つのクラスを一度に検出するのではなく、個別に検出する手法を採用しています。以下の図は論文に掲載されている図であり、3つの結果を統合したものです。
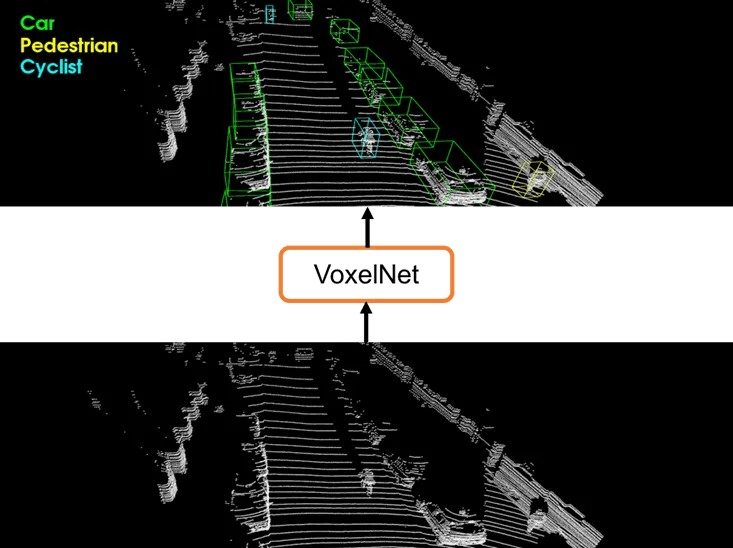
- VoxelNetは、KITTI Car Detection Benchmarkにおいて、他の最先端の3Dオブジェクト検出モデルを大きく上回る性能を示しています。
VoxelNetの構造
- VoxelNetは、主に以下の3つのモジュールで構成されています。

- Feature Learning Network: Point CloudをVoxelに変換し、エンコーディングを行うモジュール。
- Convolutional Middle Layers: 3D畳み込み(3D Convolution)を使用してVoxelの局所的な特徴を学習するモジュール。
- RPN(Region Proposal Network):高次元情報からオブジェクトのバウンディングボックスを予測するモジュール。
Feature Learning Network
Feature Learning Networkは、Point CloudをVoxel-wise Featureに変換するプロセスを実行します。その主な手順は次の通りです。

Voxel Partitioning
- 下の写真のように、3D スペースを同じサイズの Voxel に分割します。

- D x H x W 長さの3D空間で、一つのVoxelの長さをvD、vH、vWと定義し、Voxel Gridの大きさを定義します。 Voxel Gridのサイズは以下のように定義されます。
D’ = D/vD
H’ = H/vH
W’ = W/vW
Grouping
- Voxel Partitioningが終わったら、そのVoxelの中に属しているPoint CloudをGroupingする段階です。
- この時、Point Cloudの希少な特性と密度の可変性によって、VoxelごとにPointの数が異なります。 下の図では、Voxel 1 の中に最も多くのPointがあります。

Random Sampling
- Pointの数が多すぎると、計算量とメモリ消費量が大きくなります。 また、一つのVoxelの中にほくろが多すぎると、偏った予測結果が生じる可能性があります。
- それで、Random Samplingを通じて、一つのVoxelの中に最大T個のPointだけが残るようにDownsamplingします。
Stacked Voxel Feature Encoding
- Voxel Feature Encoding (VFE) Layerを幾重にも積み重ねたものをStacked VFEと呼びます。 一つのVFE Layerは下の絵のようです。

- まず、一番最初のVFE Layerにはtx7の大きさの情報が入ってきます。 この時、tはVoxelの中の属するPointの数であり、7は以下の情報を意味します。
x
y
z
x — vx
y — vy
z — vz
r
- x, y, zはPointの座標を示し、vx, vy, vzはVoxel内のすべての点の中心座標を指します。rはLiDARセンサーによって取得された反射強度(Received Reflectance)の情報です。
- これらの情報がPointごとにFully Connected Neural Network(FCN)に入力されます。FCNを通過すると、Pointの次元が増加します。その後、要素ごとにMax Poolingが実行されます。このMax Poolingを通過して得られる特徴をLocally Aggregated Featureと呼びます。Locally Aggregated Featureは、それぞれのPointの特徴と結合され、Point-wise Concatenated Featureが生成されます。
- このとき、FCNはLinear、Batch Normalization(BN)、ReLUレイヤーで構成されています。そのため、VFE(Voxel Feature Encoding)Layerで学習される実質的な要素は、LinearおよびBNレイヤーです。
- 複数のVFE Layerを積み重ねたものをStacked VFEと呼びます。Stacked VFEを通じてPoint-wise Featureが生成されます。このPoint-wise FeatureはさらにFCNと要素ごとのMax Pooling(Element-wise Max Pooling)を経由して、Voxel-wise Featureへと変換されます。

これまでVoxelのPoint CloudをVoxel-wise Featureに変換する過程を見てきました。 ところで、Voxelの中で空いているVoxelも存在します。 このようなVoxelはStacked VFEを経ません。
Sparse Tensor Representation
- それぞれのVoxelは一つのVoxel-wise Featureを持つようになります。 この時、Voxel-wise FeatureはC次元のベクトルで表現されます。 各Voxel別Featureの集合をC x D' x H' x W' サイズの4D Tensorで表現することができます。 これをSparse Tensor Representationと呼びます。
- 空のVoxelはSparse Tensor Representationで0に初期化します。 下の図では、3 が空の Voxel の場合です。

Convolutional Middle Layers
- これまでPoint Cloudが4D TensorであるSparse Tensor Representationに変換される過程を見てきました。 Convolutional Middle Layersでは、4D入力データであるSparse Tensor RepresentationからFeatureを抽出します。
- Convolutional Middle Layersは下の絵のように見えます。 ちなみに、下の図は自動車を探知する際に使われるConvolutional Middle Layersの仕組みです。 歩行者とサイクリストを探知する際には、以下の構造と違いがあります。

- Convolutional Middle Layersの中には3つのConvolutional Layerが存在します。 一つのConvolutional Layerは、3D Conv Layer、BN Layer、ReLU Layerで構成されます。
- 3D Conv Layerは以下のように簡単に表現することができます。
Conv3D(cin, cout, k, s, p) - cinとcoutはそれぞれ入力、出力チャンネルを意味します。 k、s、pはそれぞれKernel、Stride、Paddingの大きさを意味します。 2D Convolutionと違って、3D Convolutionはk、s、pがすべて3次元データです。
- VoxelNetでは3つのConvolutional Layerが存在しますが、それぞれのLayerの中には次のような3D Conv Layerが存在します。
Conv3D(128, 64, 3, (2,1,1), (1,1,1))
Conv3D(64, 64, 3, (1,1,1), (0,1,1))
Conv3D(64, 64, 3, (2,1,1), (1,1,1)) - Convolutional Middle Layersを経て、最終的に64x2x400x352サイズのテンソルが出力されます。
- ここまでConvolutional Middle Layersの構成について見てきました。
Region Proposal Network

- Convolutional Middle Layersから出力された64 x 2 x 400 x 352テンソルが128 x 400 x 352にReshapeされます。 そしてRegion Proposal Networkに(RPN)入ります。
- RPNは3つのConvolutional Blockを持っています。 それぞれのブロックは、最初にStride2であるConvolution演算で入力データをDownsamplingします。 そしてStride1人Convolution演算をq回実行します。 上の図を見ると、それぞれのブロックでStrideが1人Convolutionを3、5、5回実行していることが分かります。 そして、すべてのConvolution演算の後にはBNとReLU Layerが存在します。
- 各Convolutional Blockで生成された3つの出力テンソルは、Deconvolution演算を経て256x200x176サイズのテンソルにUpsamplingされます。 Upsamplingされた3つの結果物はConcatenatedされ、768 x H'/2 x W'/2 サイズのFeature Mapを形成します。 上の図を参照してください~
- Upsamplingする時、Deconvolutionが実行されると言いました。 各Convolution Blockの結果物に実行されるDeconvolution演算は次のとおりです。
Deconv2D(128, 256, 3, 1, 0) x 1
Deconv2D(128, 256, 2, 2, 0) x 1
Deconv2D(256, 256, 4, 4, 0) x 1
※ DeconvolutionをTranspose Convolutionとも呼びます。 PyTorchでは、Deconvolutionを実行するにはConvTranspose2d関数を使用します。 - ConcatenatedされたFeature Mapは二つのBranchに入ります。 それぞれのBranchではProbability Score MapとRegression Mapを生成します。 それぞれのMapを生成するために使用されるConvolution演算は次のとおりです。
Conv2D(768, 2, 1, 1, 0) x 1
Conv2D(768, 14, 1, 1, 0) x 1 - 上記のConvolution演算によって生成されたProbability Score MapとRegression Mapのサイズは、それぞれ2 x H'/2 x W'/2 と 14 x H'/2 x W'/2 です。
- Probability Score Mapでチャンネルが2であるのは、VoxelNetが2つのAnchorから予測結果を生成するからです。 一つのPredictionは7つの情報で表現されます。 それでRegression Mapの結果が7x2個 = 14なんです。 Regression Mapの結果は後から詳しく出てきます。
Efficient Implementation of Stacked VFE
- 今回のSectionではStacked VFEの効果的な処理方法について話します。 流れが途切れそうなので、Stacked VFEの説明以降ではなく、Section 3.4で説明します。
- Stacked VFE演算が並列処理されるようにVoxelNetを設計しました。 つまり、複数のVoxelがStacked VFEで同時に処理される可能性があります。 コースは以下の図の通りです。

- まず、Voxel Input Feature Bufferが生成されます。 大きさはK x T x 7です。 KはNon-empty Voxelが収容できる最大個数です。 Tは一つのVoxelの中に入ることができる最大Pointの数です。 7は一つのPointが持つ7つの情報を意味します。
- そしてVoxel Coordinate Bufferも生成されます。 大きさはK x 1 x 3です。 3はVoxelのx、y、z座標を盛り込むためです。
- Voxel Input Feature Bufferを生成するために、一つのPoint Cloudから任意にPoint一つを抽出します。 この時、該当Pointが属するVoxelの座標をHash Keyとして使用し、Hash TableにLookupします。 この作業はO(1)の演算速度で実行されます。 もし、当該Voxelが既に生成されている場合は、当該PointをVoxel Input Featureに挿入します。 もし、そのVoxelにT個のPointがすでに割り当てられたとしたら、このプロセスは無視されます。 もし、当該Voxelが生成されなかった場合は、Voxel Input Feature Bufferに当該VoxelのPointを管理できるスペースを割り当て、当該Pointを挿入します。 そして、Voxel Coordinate BufferにそのVoxelの座標を入れます。 このすべてのプロセスは、Point Cloudに属するPointの数であるnの数と比例した時間の複雑さを持ちます。 それで、Voxel Input Feature BufferとVoxel Coordinate Bufferを生成するのに合計O(n)がかかります。
- Voxel Input Feature Bufferの生成が完了すると、GPUでそれぞれのVoxelはStacked VFEを並列に計算することができます。
- Voxel Input Feature Bufferに属するすべてのVoxelがStacked VFE演算を経ると、Voxel-wise Featureになります。 Voxel Coordinate Bufferに含まれるVoxelの座標情報を活用してSparse Tensor Representationを生成することができます。 このようにして生成されたSparse Tensor Representationは4D形態のテンソルですが、これはConvolutional Middle LayersとRPN段階の両方でGPUで効果的に処理できます。
VoxelNetの自動車探知のための詳細説明
- 自動車探知のためにKITTIデータセットが使用されます。 Z、Y、X軸にそれぞれ[-3、1]、[-40、40]、[0、70.4]メートルのPoint Cloudデータが使用されます。
※ Z軸で負数が出る理由は、LiDARが車の上に設置されているからだと思います。 LiDARの高さが0ではないかと思います。 - vD、vH、vW はそれぞれ0.4、0.2、0.2 メートルと定義します。 そのため、D'、H'、W'はそれぞれ10、400、352で計算されます。
- 一つのVoxelの中に属することができる最大Pointの個数Tは35と定義します。
- Stacked VFEで二つのVFE Layersを使用します。 二つのLayerは以下のように定義されます。 第一因子は入力次元、第二因子は出力次元を意味します。
VFE-1(7, 32)
VFE-2(32, 128) - Feature Learning Networkが最終的に生成するSparse Tensor Representationは128 x 10 x 400 x 352 サイズになります。
- Section 3.2 で既にConvolution Middle Layersの詳しい説明をしているので省略します。
- Convolution Middle Layerの結果であるテンソルを64 x 2 x 400 x 352から128 x 400 x 352にReshapeした後、RPNに入力します。 128 x 400 x 352はそれぞれチャンネル、Height、Widthを意味します。
- RPNでは一つの大きさのAnchorだけを使用します。 Anchorのサイズは、l=3.9、w=1.6、h=1.5メートルです。 そしてz軸基準-1.0メートルにAnchorの中心点が位置します。 そしてAnchorはZ軸を基準に0度と90度回転した2種類が存在します。
- Positive AnchorとNegative Anchorを定義するために、Bird's Eye Viewで見たIoUを使用します。
- Grud Truth BoxとIoUが0.6より大きいか、IoUが最も高い場合、AnchorはPositiveとみなします。
- すべてのGround Truth BoxとIoUの点数が0.45より小さい場合は、Negative Anchorとみなします。
- IoUが0.45以上、0.6以下なら学習する時に無視します。
- 下のLoss Functionから出てくるPositive Classification LossとNegative Classification Lossの加重値であるαとβはそれぞれ1.5と1に設定します。
学習するときはSGDを使用し、最初の150Epochの間は0.01のLearningRateを使用し、次の10Epochの間は0.001を使用します。 Batchのサイズは16 Point Cloudsです。
VoxelNetの学習過程
Loss Function
- NposはPositive Anchorの個数、NnegはNegative Anchorの個数を意味します。
- 3D Ground Truth Boxは7つの変数で定義されます。 それぞれの変数は次のとおりです。(xcg、ycg、zcg、lg、wg、hg、θg)で表現します。 xcg、ycg、zcgはそれぞれGround Truth Boxの中心座標x、y、zを意味します。 lg、wg、hgはGround Truth BoxのLength、Width、Heightをそれぞれ意味します。 θgはZ軸を基準にどれだけ回転したかを表す角度で、単位はRadianです。
- Postive Anchor Boxは7つの変数で定義されます。 それぞれの変数は次のとおりです。(xca、yca、zca、la、wa、ha、θa)。 それぞれの変数は、3D Ground Truth Boxを定義する時に使用した変数と意味が同じです。
- Loss Functionは以下のように定義されます。 pi^posとpj^negはそれぞれPositive Anchorの確率とNegative Anchorの確率を意味します。

- この時、uiはPredictionとAnchorBoxの違いを定義したベクトルです。 このベクトルは、Regression Mapから出たベクトルで、元素が7つです。 そしてui*はGround Truth BoxとAnchor Boxの違いを定義したベクトルです。 このベクトルは7つの元素を持ち、以下のように定義します。

- 第1項と第2項は、それぞれPositive AnchorとNegative AnchorのClassification Lossです。 LclsはBinary Cross Entropy Lossと定義されます。 ここでBinary Cross Entropy Lossを使用できる理由は、VoxelNetはMulti-classを探知するDetectorではないからです。 VoxelNetは「自動車か?違うか?」だけを区別します。 α、βは重み付け変数です。 LregはRegression Lossで、Smooth L1 Lossと定義されます。
Data Augmentation
- Training Point Cloudsが4,000個しかないので、Data Augmentationは必須です。 全部で3つのData Augmentationがあります。
- 最初のData Augmentationです。 Ground Truth Bounding BoxをZ軸基準に[-π/10, +π/10]の間の値だけ回転する方式です。 回転をしたときに他の物体と衝突しない場合にのみ、最初のData Augmentationが適用されます。
- 2番目のData Augmentationは、Point Cloud内のすべてのPointに[0.95、1.05]の間の値をかける方式です。 これにより、VoxelNetはより堅牢になる可能性があります。
- 3番目のData Augmentationは、(0, 0, 0)地点でZ軸を基準に[-π/4, +π/4]の間の値だけ全てのPointを回転させる方式です。 こうすると、車が回転するのと同じ効果を与えることができるそうです。 正確には理解できませんが、まあ、そうだそうです。
実験結果
- VoxelNetはKITTI 3D Object Detection Benchmarkで実験されました。 KITTIデータセットは7,481個のTraining Point Cloudsと7,581個のTesting Point Cloudsで構成されています。
- データセットには、車、歩行者、サイクリスト クラスがあります。 各クラスはEasy、Moderate、Hardの難易度に分けられます。 物体の大きさ、Occlusion State、Trucation Levelによって難易度が分けられます。 OcclusionとTruncationは以下のようなことを言います。

- Testingデータセットは提供されませんので、Trainingデータセットを3,712個のTraining Point Cloudsと3,769個のTesting Point Cloudsに分けました。
- 実験をする時、PredictionとGrond Truth Boxの間のIoU点数が0.7より大きいと正解とみなされ、実験表にある指標はすべてmAPです。
Evaluation in Bird’s Eye View (BEV)

- SOTA
Evaluation in 3D

- 2Dで予測するBEVとは異なり、3D Detectionはさらに難しい作業です。 それで点数が大体小さく出ます。 それでもVoxelNetのSOTA性能を見せます。
Evaluation on KITTI Test Set

- KITTIサーバーにあるKITTI Test Point Cloudsで行った実験結果です。
- VoxelNetはPoint Cloudデータだけを使用しましたが、他のMulti-modalデータを使用したモデルよりも優れた性能を発揮しました。
Visualization and Inference Time

- VoxelNetの推論時間は225msです。 TitanX GPUと1.7 Ghz CPUで実行しました。 推論時間について詳しく調べてみると、以下のようになります。
Voxel Input Feature Computation: 5ms
Feature Learning Network: 20ms
Convolutional Middle Layers: 170ms
Region Proposal Network: 30ms
結論
- Voxel別、Point別並列処理ができるようにネットワークを開発し、実行速度が速いです。
- KITTIデータセットで学習した時、自動車、歩行者、サイクリスト探知分野でState-of-the-artの性能を見せました。
- VoxelNetの推論時間が225msです。 1秒におよそ4枚のPoint Cloudsを処理できるということですが、Real-timeとは程遠いです。
出典
- VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection, Yin Zhou et al., 2017–11–17

Discussion