こんにちは!Fusic 機械学習チームの塚本です。
機械学習モデルの開発から運用までなんでもしています。もし、機械学習で困っていることがあれば、気軽にお問い合わせください。
定式化をする時に、だいたいが問題をグラフで表現して、それを入力として定式化をしていくって流れをとっていきます。
今回はJSP(Job Shop Scheduling)に近いものを案件で取り扱うことがあり、論文とかはもちろんあるんですが、意外と記事とかはないんだなあって感じだったので、書いておきます。
問題設定
ジョブショップスケジューリング問題は、複数のジョブがあり、各ジョブは特定の順序で複数の機械で処理される必要がある状況を指します。各ジョブの各工程の処理時間は既知であるとし、具体的な目標は色々ですが、よくあるのは全体の完了時間(Makespan)の最小化がよくあがります。
データ設定として、例えば下のようなものがあったりします。
ジョブと機械
- ジョブ: 3つ(
J_1, J_2, J_3 - 機械: 3台(
M_1, M_2, M_3
| ジョブ | 工程1( |
工程2( |
工程3( |
|---|---|---|---|
| 2時間 | 4時間 | 3時間 | |
| 3時間 | 3時間 | 4時間 | |
| 1時間 | 3時間 | 4時間 |
定式化のためのグラフ表現
グラフ
定式化を起こす前にまずグラフとして、オペレーション同士の関係性などを表現することでグラフ的な解析や視覚化や定式化のやりやすさが結構変わってきます。
ジョブショップでよく使われるグラフ表現はDisjunctive Graphというものがあります。
各工程間の関係性と、同一マシン内での関係性を一つのグラフで表現したものです。
[↓参考]
このグラフは、以下の要素で成り立っています。
1. ノード
- 各ノードはオペレーションを表します。
- ノード
(j,i) j i
2. Conjunctive Edges: 同一ジョブ内のオペレーションの順序を表します。
3. Disjunctive Edges: 同一マシン上の異なるジョブのオペレーション間の順序を表します。
ソースノードとシンクノードの設定
例えば、3つのジョブにそれぞれ3つずつオペレーションが存在し、3つのマシンで処理されるものを考えると、以下のようなグラフとなります。
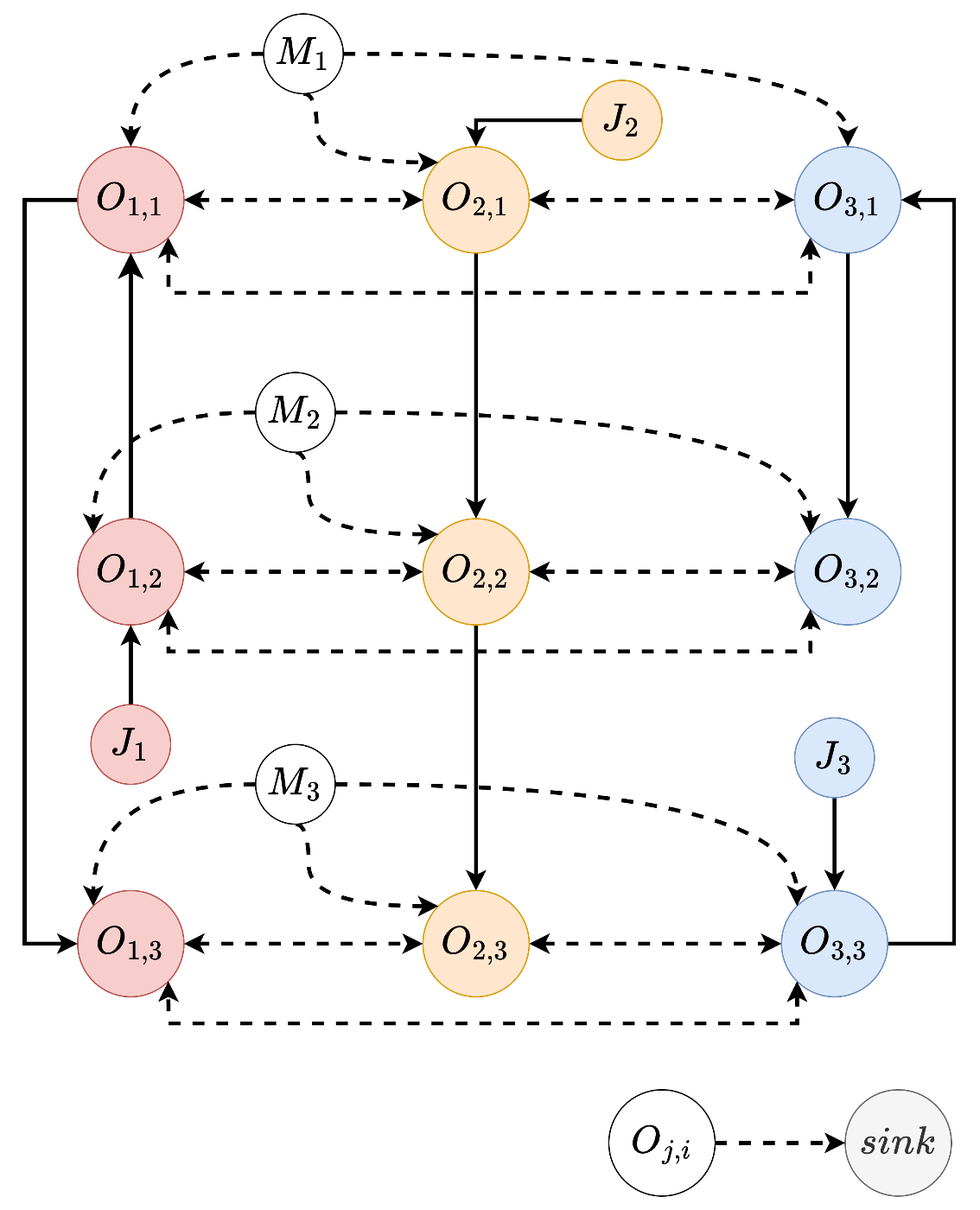
Conjunctive Edgesに繋がるソースノードとしてジョブ、Disjunctive Edgesにつながるソースノードとしてマシンを与えています。
マシン
また、オペレーションにsinkノードを繋げています。
これを追加すれば、最終的なジョブの完了時間(makespan:
sinkは仮想ノードではあるので、これの開始時間みたいにすると変ですが、簡単のため今回はこうします。
定式化
各種記号定義
これから使う記号を定義しておきます。
定式化
ここまでのグラフを使って定式化を行います。
定式化は一般的なJSPのメイクスパンの最小化を行います。
決定変数はConjunctive EdgesとDisjunctive Edgesの枝の選択を0-1変数
目的関数
- フロー整合条件
-
全てのオペレーションが処理されること
\sum_{e \in \delta^+(n) \cap E^d} x_e = 1, \ n \in O -
実行順序制約
同一ジョブ内のオペレーションの順序を守るための制約です。
- マシン割り当てに関する制約
s_u + p_u + L(x_e - 1) \le s_v, \ e=(u, v) \in E^d
参考実装
今回はpulpを利用して、CBCソルバーで上の例を解いてみます。
普通は、JSPで厳密解を求めようとするのはほとんどの場合で無理なので、基本はヒューリスティックソルバーを利用したりなんかが多いです。私はOR-toolsを利用していました。
import pulp as pl
# g: nx.DiGraph
# prob: LpProblem, LpMinimize
# x[e]: e \in Ed, LpBinary
# s[n]: n \in g.nodes, lowBound=0, LpInteger
# 目的関数
prob += s[Consts.sink]
# 制約条件
# 1. フロー整合条件
for o in O:
prob += (
pl.lpSum([x[e] for e in g.in_edges(o) if e in Ed])
- pl.lpSum([x[e] for e in g.out_edges(o) if e in Ed])
== 0,
f"flow_conservation_{o}",
)
for m in jsp.machines:
prob += (
pl.lpSum([x[e] for e in g.out_edges(m)]) == 1,
f"machine_start_{m}",
)
prob += (
pl.lpSum([x[e] for e in g.in_edges(Consts.sink) if e[0].machine == m]) == 1,
f"machine_end_{m}",
)
# 2. すべてのオペレーションが処理される
for o in O:
prob += pl.lpSum([x[e] for e in g.in_edges(o) if e in Ed]) == 1, f"operation_{o}"
# 3. 実行順序制約
for u, v in Ec:
prob += s[u] + g.nodes[u]["t"] - s[v] <= 0, f"conjunctive_{u}_{v}"
# 4. マシン割り当てに関する制約
for u, v in Ed:
prob += (
s[u] + g.nodes[u]["t"] + Consts.L * (x[u, v] - 1) <= s[v],
f"disjoint_{u}_{v}",
)
解いた結果
Objective: 13.00
-
M_1 O_{2,1} O_{1,1} O_{3,1} -
M_2 O_{1,2} O_{2,2} O_{3,2} -
M_3 O_{3,3} O_{1,3} O_{2,3}
ベンチマークとか
ここに扱いやすいJSPのベンチマークとその解が上がっています。
上でも書いた通り、厳密解として求めることは難しいと思います。
詳細は書きませんが、10ジョブx10マシンをGUROBIソルバー, 4スレッド実行で30分やってもMIP-GAPは80%程度にしかなりません。

Discussion