PointNet、PointNet++、VoxelNetに続き、本日はPointPillars論文レビューをさせていただきます。 その名の通りPoint Pillarsはpillarsと(柱)関連があります。 Point Pillarsは、point cloudをpillarに分けて3dobject detectionを実行します。
Point Pillars論文はCVPRで2019に出た論文です。 著者はAlex H. Langetal.です。 早速論文のレビューに入ってみます!
PointPillars 紹介
Point Pillarsの簡単な紹介
- PointPillars はPointNet の仕組みを活用する。
- Point Pillarsは、point cloudを柱に(pillar)分けてencodingを行う。
※ここでencodingとは、LiDARを通じて持ってきたpoint cloud情報を後に出てくる2D convolutional layerが使用できる形態に変換する過程を意味する。 ある意味、前処理の過程かもしれない。 PointPillars のencoding 段階ではneural network が活用される。
最近の研究方向
- 最近の研究では、3D object detection の問題をbird's eye view (BEV) 方式で解決しようとしている。
- BEV を使用すると、オブジェクトサイズの曖昧性と (scale ambiguity) occlusion に影響を少なく受ける。
※ オブジェクトの曖昧性とは、距離によってオブジェクトの大きさが異なって見える問題を意味するものと解釈される。 - 最初に出たBEV方式はhand-crafted featureを使用した。
- しかし、hand-crafted featureを使用するdetectorは変形された入力に強健でないという短所がある。
- このような問題を解決するために、VoxelNetが開発される。 VoxelNetは、point cloudをvoxelに変換し、各voxelにPointNetを適用する方式である。
- VoxelNetは性能が良いが、4.4fpsでreal-timeに適していない。
- SECONDはVoxelNetの速度を大幅に向上させたが、3D convolutionを使用するため、依然としてconvolution layerでボトルネック現象が発生する。 (3D convolutionは2Dで次元がもう一つ追加されるのでcomputation量がすごく増える。)
※ SECONDは20fpsで作動し、決して遅いとは言えない。 だが、PointPillarsは62fpsなので相対的な観点から遅いと言えるようだ。 - PointPillars は柱から学習をするnovelencoder を提案する。
- この方式は、neural networkを使用するencoderであるため、フィーチャーに対する情報を学習することができ、フィーチャー抽出をよりうまく行うことができる。
※これに反対に、fixed encoderは学習が不可能な固定されたencoderであり、フィーチャー抽出がうまくできない可能性がある。 - Encoderを経て出たデータは、2D convolutional layerに入れる形式で出てくる。
- 2D convolution は3D convolution より速いため、Point Pillars の演算はGPU で効果的に計算される。
- Point PillarsはLiDARのpoint cloudデータ以外にも様々なデータを統合して使用できる。 例えば、radar point cloudもLiDAR point cloudと一緒に使用できる。

- 上の図は、BEV testで様々なモデルの実験結果である。 Testは計3つのクラスを探知する実験だった。 各モデルの名前は以下のように表現される。
PP: PointPillars
M: MV3D
A: AVOD
C: ContFuse
V: VoxelNet
F: Frustum PointNet
S: SECOND
P+: PIXOR++
PointPillarsの貢献
- Point Pillars 著者たちの貢献は以下の通りである。
- Novel point cloud encoder を提案し、end-to-end 学習を可能にした。
- 3D object detectionを2D convolution演算だけで行うので、62fps速度で動作する
- KITTIBEV、3D benchmarkでstate-of-the-art(SOTA)性能を見せる。
- Ablation実験を通じてPointPillarsが使用する多様なモジュールの役割と機能の効果を調べる。
Point Pillarsの構造

- 上の図はPoint Pillarsの全般的な構造を示す図である。 大きく3つの段階で構成される。
- まず、フィーチャー encoder networkでpoint cloudはpseudo-imageに変換される。
- そして2D convolutional backboneを経る。
- 最後のdetection headで探知を行い、3D bouding boxを予測する。 Detection head はSSD を使用する。
Pointcloud to Pseudo-Image

- 今回のセクションでは、point cloudデータがpseudo-imageに変換される過程を説明する。
- Point cloudの一つのpointはlと定義する。 l というベクトルは次のような元素を持つ。 l = {x, y, z, r, xc, yc, zc, xp, yp}
- x、 y、 z はpoint の座標を意味する。
- r はreflectance rateである。
- xc、yc、zc は一つの pillar の中に属するすべての point の中心座標から離れた距離である。
- xp、yp はpillar の中心x、y 座標から離れた距離である。
- すなわち、l はD=9 次元の大きさのベクトルである。
- Point Pillars では、non-empty pillar の個数をP に制限する。
- そして、一つのpillarに属することができるpointの個数をNに制限する。 もしpointの個数が多すぎるとrandom samplingが使われる。 逆にpointの個数が足りなければzero paddingが使われる。
※ ここでzero paddingは空いている空間を0で満たしてくれるという意味だ。 CNN で使用するzero padding と異なる。 - それで作られるstacked pillarsというdense tensorの大きさは D x P x N である。
- Pillar のフィーチャーを符号化するためにPointNet を簡素化したネットワークを使用する。
Linear layer、batch normalizatoin(BN)、ReLUが使われ、C x P x N サイズのtensorを生成する。
※ ここでLinear layerはまるで1 x 1 convolution演算のように作動する。 - そして、max poolingを通じてCxPサイズのtensorであるlearned featureを生成する。
- Encodingされたlearned featureはC x H x Wサイズのpseugo-imageに統合される。 ここでH、Wはpoint cloudをグリッドで割ったときの高さ幅である。
Backbone
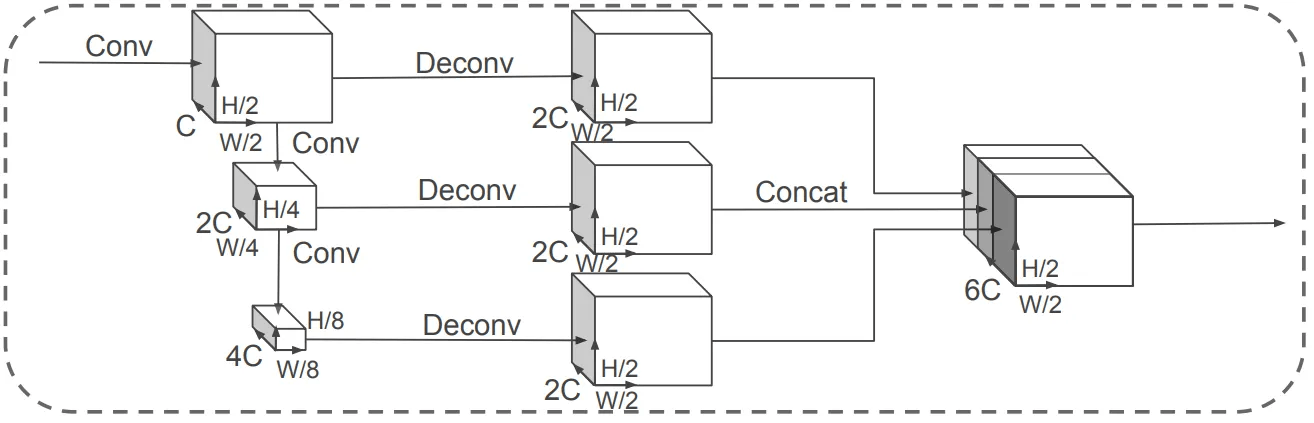
- 2D convolutionを実行するbackboneは、入力されたpseugo-imageから3つのblockを作る。
- 各ブロックを作るために使われるConv演算をBlock(S, L, F)と定義する。 S はstride サイズ、L は 3 x 3 2D convolution layer の個数、F は出力チャンネルの大きさである。 Block(S、L、F)内で実行されるすべての2D convolution演算の後にBNとReLUが適用される。
- 生成されたブロックの大きさはそれぞれ(C、H/2、W/2)、(2C、H/4、W/4)、(4C、H/8、W/8)である。
- 各ブロックはtransposed 2D convolutionを通じてupsamplngされる。
- この時、upsampling演算をUp(Sin、Sout、F)と定義する。 Sin、Soutはそれぞれinitial strideとfianl strideを意味する。 F は最終的に出力するチャンネルの大きさである。
- Upsamplingを実行するために使用されたtransposded 2D convolution演算後にBNGo ReLUが適用される。 Upsampling完了後、blockは全て(2C、H/2、W/2)サイズのblockになる。
- 3つのブロックはconcatenatedを通じて一つの大きなtensorを成す。 このときconcatenatedされたtensor の大きさは(6C, H/2, W/2)である。
Detection Head
- Detection headでSingle Shot Detector (SSD) 方式を使用する。
- SSD を使用したloss は3 次元空間での高さ情報がない。 したがって、bouding boxの高さを除いたprediction boxのregression結果をground truth boxと比較した。
Point Pillarsの詳しい説明
Network
- Point Pillars のすべての重みは、均等分布を使用して (uniform distribution) 任意に初期化される。
- Encoder network でC = 64 である。
- Carクラスを探知する時とcyclist、pedestrainを探知する時にそれぞれ異なるhyparameterを使用する。
- Car探知時は、backboneでS=2、cyclist、pedestrianを探知する時はS=1である。
- 二つのネットワークともに3つのブロックを生成する。 この時、ブロックを作るために使用する2D convolution演算は、ブロック1(S,4,C)、ブロック2(2S,6,2C)、ブロック3(4S,6,4C)で定義される。
- そして、upsampling のときに使われるtransposed 2D convolution 演算は、それぞれUp1(S,S,2C)、Up2(2S,S,2C)、Up3(4S,S,2C) と定義される。
- 3 つのブロックはすべてconcatenatedされ、6C 個のフィーチャーを持つtensor となる。 このtensorはdetection headに伝達される。
Loss
- Ground truth, prediction bounding box, anchor はすべて (x, y, z, w, l, h, θ) と定義する。
- Ground truth とanchor の違いを下の式で示すように表現する。

- Superscriptgtとaはground truthとanchor boxを意味し、daはanchor boxの底の対角線の長さである。
- 実際に Point Pillar の detection head が予測するregression target 値は、predicted bounding box の x, y, z, w, l, h, θ ではない。 実際に予測する値は以下の値である。 Superscriptpはprediction bounding boxを意味する。 以下の値はpredictionとanchorの違いを意味する。

- Localization loss は以下のように定義される。

- しかし、上記の方式を使えば、predicted boxとground truthの間の角度差が0、180度の時に全てlossが同じになる。 それで dirrection loss を追加し、これはsoftmax function である。
- Classification loss はRetinaNet のfocal loss を使用する。 Classification loss は以下のように定義される。 pa はanchor にオブジェクトが属する確率である。

- 上の式において、α、γ はhyperparameter であるが、α = 0.25、γ = 2 である。
- Point Pillars の最終的なloss はmulti-task loss であり、以下のように定義される。 Npos はpositive anchor の数である。 βloc, βcls, βdir はそれぞれ2, 1, 0.2 である。

Training Detail
- Optimizer でAdam を使用し、initial learning rate は 2 x 10^-4 である。
計160epochの間に学習が行われ、15epochごとにlearning rateが0.8倍減少する。 - Validationはbatchの大きさが2であり、testingはbatchの大きさが4である。
実験結果
Dataset
- KITTI object detection benchmark を使用した。 一つのネットワークはcarを探知するように学習し、もう一つのネットワークはcyclistとpedestrainを探知するように学習した。
Settings
- 一つのpillarの底の大きさは0.16x0.16mだ。
- P = 12,000、N = 100 と定義する。
- VoxelNetと同様に二つの方向のanchorを使用する。 (0度と90度のanchor)
- 予測されたbounding box と ground truth を (GT) マッチングするために IoU 指標が活用される。
- Positive predictionはGTとIoUの点数が最も高いか、postive match thresholdの値より大きいと良い。 Negative predictoinはGTとIoUの点数がnegative thresholdより低ければよい。 IoU点数がその間にある値であれば学習から除外される。
- Inference の時 axis aligned non maximum suppressionを (NMS) 使用する。 このとき、overlap threshold は0.5 である。 この方法はrotational NMS と性能は似ているが、はるかに速いという。
※ Axis aligned NMS は一般的なNMS と同じ意味のようである。 しかし、正確なことはコードを見ないと分からない。 - Car 探知のための point cloud の大きさはx, y, z 軸基準で [(0, 70.4), (-40, 40), (-3, 1)]m である。 Caranchorは、サイズは基本的に(w、l、h)=(1.6、3.9、1.5)mである。 そして、anchorの中心は-1m地点に位置する。 Positive match threshold와 negative thresholdはそれぞれ 0.6, 0.45です。
※ Point cloudのx、y軸の長さがそれぞれ70.4、80mである。 これを0.16mで割ると正確に定数に落ちるが、それぞれの値は440、500だ。 すなわち、Point Pillarsはpoint cloudを400 x 500 gridに分けるが、一つのcellは0.16 x 0.16mの大きさの正方形である。 - Pedestrain、cyclist探知のための詳細は省略する。
Data Augmentation
- まず、すべてのpoint cloudからクラス別GT databaseを(DB)作る。 一つのポイントクラウドにGT DBからcar、pedestrain、cyclistをそれぞれ15、0、8個の任意に選択して追加する。 このようにした時、SECONDのdata augmentation方式より性能が良かった。
- それぞれのGT box が個別にdata augmentation を経る。 Rotation が適用されるが、[-π/20, π/20] 間の値を均等に使用する。 N(0, 0.25)分布からGT box のx, y, z の値を個別に変動する。
- Global data augmentationも実行する。 まず、x軸基準でrandom mirroring flipを実行する。 そして、global rotation、scalingを行う。 最後にglobal translationを行うが、x、y、z値はN(0、0.2)分布から選択する。
Results

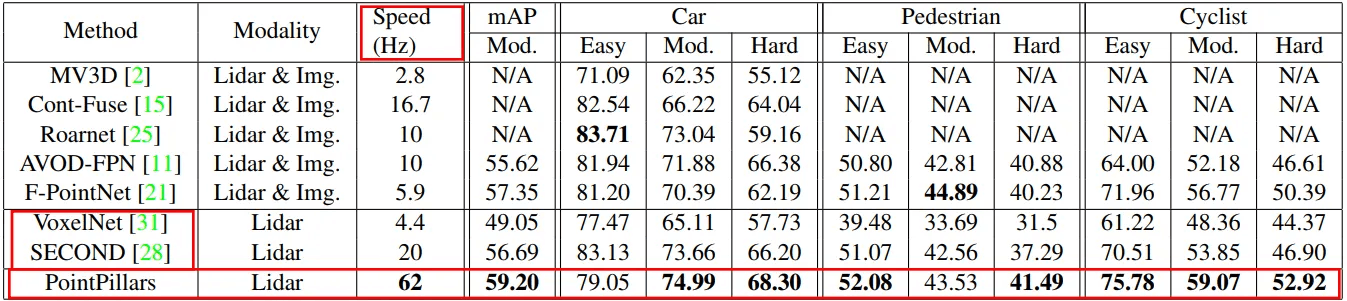
- 上の2つの表を見ると、Point PillarsはBEV、3D作業で他のSOTAモデルより良い性能を見せた。 このとき使われた指標はmAP である。 速度を見れば非常に速いことがわかる。

- mAP はオブジェクト方向に対する探知性能を評価することはできない。 そこで、average orientation similarity (AOS) の指標が活用される。 上表は実験結果だ。
- Point PillarがAOSの点数もやはり他のモデルよりほとんど良かった。
※ SubCNN方式はイメージだけで学習されたモデルだが、pedestrianの方向を非常によく予測する。 なぜだろうか? 気になる。
Qualitative Analysis


1 番目の写真と2 番目の写真は、実験結果をイメージに投影した図である。 一番目の写真はよく予測した結果で、二番目の写真はよくできなかった結果だ。
自動車に対する探知はほとんどうまく行う。 しかし、partially occludedまたは距離が遠いGTは予測に失敗する場合がある。 そして、carと似たvanまたはtramを車と誤認識する場合もある。 Pedestrain とcyclist はcar より探知性能が低い傾向がある。
二番目の写真aを見るとcyclistを逃した。 二番目の写真Dは、pedestrainとtableをcyclistと誤認識した。 2番目の写真bを見ると、周辺環境にある電柱、木によってpedestrain探知に失敗する場合がある。
リアルタイム推論速度
- Point Pillars はリアルタイムで動作する。 Intel i7 CPU と 1080ti GPU で実験を行った時、各stage で所要される時間は以下の通りである。
Filter based on rage: 1.4ms
Points are orgatinzed in pillars: 2.7ms
Pillar tensors uploaded to GPU: 2.9ms
Encoding: 1.3ms
Pseudo-image: 0.1ms
Backbone and detection head: 7.7ms
NMS on CPU: 0.1ms - それで最終16.2ms に実行される。 これは変換すると62fps となる。
Encoding
- Point Pillarsがこのように早くできる理由は、encoding stageで時間を大幅に短縮したからだと言える。
- VoxelNetは190ms、SECONDは50msがかかる。
Slimmer Design
- VoxelNet、SECONDは二つのPointNet構造を使用するのに対し、PointPillarsは一つのPointNet構造だけを使用する。
- 甚だしくは使用するPointNetの出力チャンネル数は他の二つの方式に比べて小さい。
- 他の2つの方式と同じ構造で実験を進めた時、性能にはあまり差がなかったという。
TensorRT
- 推論を行う際にNVIDIAのTensorRTライブラリを使用した。
- PyTorchを使う時より45.5%速度が速くなった。 (PyTorch는 42.4fps)
The Need for Speed
- Point Pillars は105fps の速度で実行されることもある。
- LiDAR が20fps の速度で実行されるので、このように速い必要がないことも考えられる。 しかし、2つの考慮事項がある。
- KITTI benchmarkのデータは、車両のフロントビューにのみGTがラベリングされている。 実際、自動運転自動車はフロントだけでなく、360度全体を探知しなければならない。
- 105fps という数値は、high-power desktop GPU で得られた値である。 実際、自動運転車はこのように良い性能のハードウェアで作動しない可能性がある。 すなわち、これより低い値で実行することができる。

Ablation Studies
Spatial Resolution
- 性能と速度はtrade-off 関係の中にある。 小さいサイズのpillarを使えば精密なlocalizationが可能だ。 逆に大きなpillarを使うと速度が速くなる。
- Pillarの大きさを変えながら実験を進めた。
- 0.28x0.28m pillarを使用した時、最大105fpsで作動し、0.12x0.12mの大きさのpillarを使用した時より性能が少ししか落ちなかった。
- Pillarの大きさは{0.122, 0.162, 0.22, 0.242, 0.282}m²で実験を行い、各実験で使用したPの個数は16000, 12000, 12000, 8000, 8000である。
Per Box Data Augmentation
- VoxelNetとSECONDはcar、pedestrain、cyclistクラスに全てdata augmentationを遂行する。
- しかし、PointPillarsではdata augmentationにも適切な程度があるという仮定を立てた。
- Pedestrainにdata augementationをした時、むしろ性能がさらに落ちた。
Point Decorations
- VoxelNet で一つのpoint の表すために使用した7 つのフィーチャーを使用する。
- PointPillars はそこにxp, yp を追加して9次元フィーチャーを使う。
- 追加したときにmAPが0.5 上がった。
Encoding

- PointPillars で提案したnovel encoder の影響を確認するために、他の3D object detector にnovel encoder を使ってみた。
- Learne dencoder方式がfixe dencoderより性能が常に良かった。
- Pillarのサイズが小さい時、VoxelNetがPoint Pillarsより良い性能を見せた。
- これは、VoxelNetの方がparameterの数が多く、推論する時により長い時間を使うため、公平な比較ではない。
- 重要なことは、Point Pillars で提案した pillar-wise で学習を行ったことが効果的だということだ。
結論及び感じた点
結論
- PointPillars は、pilar-wise でend-to-end に学習した 3D object detector である。
- KITTI benchmarkで他のモデルよりBEV、3D作業でより良い性能を見せ、実行速度もはるかに速かった。
感じたこと
- これまでdetection headのlocalization regression outputがpredicted bounding boxの座標、大きさ、回転方向だと思っていた。 しかし、コードを開いてみると、anchor boxとの差の値がoutput値だった。
出典
- PointPillars: Fast Encoders for Object Detection from Point Clouds, Alex H. Lang et al., 2019–05–07
- PointPillars-GitHub, Alex-nutonomy, 2019–05–06

Discussion