Redshift 覚書


Redshift
AWS で利用可能なサービス。パブリッククラウドサービスで安価に利用できるDWH製品。
列指向型データベースで列の集計処理などに最適化されているため、その類の用途で非常に有用なデータベースと言える。
特定のワークロードにに特化したデータベースのため用途を考慮して利用すべき。
- 向いているワークロード
- 大規模なデータセット(数GB~PB)
- データの更新は一括。OLTPのような処理は想定しない
- 1つ1つのSQLは複雑だが同時実行数は少ない。
仕組み
Redshift は主にリーダーノード、コンピューティングノードの2コンポーネントから物理的にはクラスターが構成される。
また、コンピューティングノードの中は、ノードスライスという処理の実行単位に論理的に分割されている。
リーダーノード
- クライアントプログラムから直接接続されるいわば司令塔。
- 実行計画に基づいて、コードをコンパイルし、コンパイル済みのコードをコンピューティングノードに配布する。コンピューティングノードに格納されているテーブルがクエリで参照されている場合にのみ、コンピューティングノードに SQL ステートメントを配布。
- 他のすべてのクエリは、リーダーノードのみで実行される。
コンピューティングノード
- テーブルデータを参照する SQL の実際の実行箇所。
- リーダーノードでコンパイル済みのコードを実行し、中間結果をリーダーノードに返送。中間結果は、リーダーノードにおいて最終的に集計される。
- 各コンピューティングノードの専用 CPU、メモリ、接続されているディスクストレージは、ノードタイプによって異なる。
ノードスライス
- コンピューティングノードはスライスという処理の実行単位に分したもの。
- 各スライスは、ノードのメモリとディスク容量の一部を割り当てられて、ノードに割り当てられたワークロードの一部分を処理する。
- リーダーノードは、スライスへのデータの分散を管理し、クエリまたは他のデータベース操作のワークロードをスライスに分配します。
- ノードあたりのスライスの数は、クラスターのノードサイズによって決定される。
▼ 参考:

その他以下の水平分散型構成、ストレージIO削減のアーキテクチャーを取っており、可用性やパフォーマンスを最適化
MPP (Massive Parallel Processing)
- リーダーノードが1タスクを複数のコンピューティングノードで分散割当して実行。
- コンピューティングノードを追加することで容易にスケールアウト可能
シェアードナッシング
- SPOFとなる共有ディスク無し。
- コンピューティングノード追加=ノード+ディスクがセットで増えるイメージ
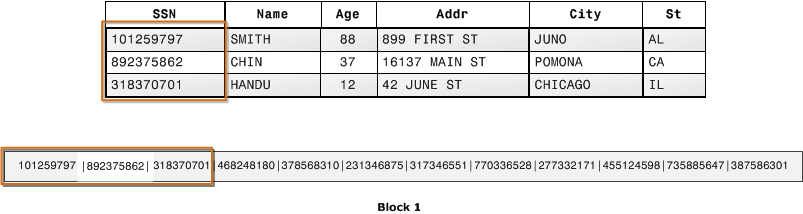
列指向データストレージ
- 通常のRDBMSだと行レコードのデータがディスクブロックに格納されるような形となるが、列指向型の場合は、各列の値がディスクブロックにシーケンシャルに格納されるので列の集計処理が特に高速にできる。
- 特定の列を集計するようなDWHの処理で、必要な総ディスク I/O と、ディスクからロードする必要のあるデータ量が大幅に減少する。
- Redshift ではブロックサイズが1MBのため、必要なIO要求数が少なくて済む。
データ圧縮
- データは自動的に圧縮されてストレージに格納されるので、読み込み時のディスクIOが小さくて済む。
- クエリを実行すると、圧縮されたデータがメモリに読み込まれ、クエリの実行の間に圧縮解除される。
- 列指向ストレージで類似データが集まっているのでより一層圧縮率が高い。
- 圧縮アルゴリズムは列ごとに指定可能。推奨をanalyze compression [テーブル名]で得ることも可能。
- Redshift は自動的にテーブルの列を自動的に圧縮する。(ENCODE AUTO)これで、Amazon Redshift がテーブルにあるすべての列の圧縮エンコードを自動的に管理できる
- テーブル内のいずれかの列に圧縮エンコードを指定すると、テーブルは ENCODE AUTO に設定されない。Amazon Redshift は、テーブルにあるすべての列の圧縮エンコードを自動的に管理しないようになる。
- 列ごとに圧縮エンコードは指定される。
▼ 参考:
イメージとしてはBlackbelt参照だがこの辺りの図がわかりやすい。
ノードスペック変更
伸縮自在なサイズ変更:
- 伸縮自在なサイズ変更を使用して、ノードタイプ、ノード数、またはその両方を変更可能。
- 通常、伸縮自在なサイズ変更には 10~15 分かかる。
- ターゲットノードタイプが既存のノードタイプと同じ場合は、自動的に新しいノードにデータを再配布し、内部的に新しいクラスターは作成されない。この場合、クエリが一時的に停止され、接続はオープンのまま維持される。検証したところ数分程度クエリが停止。エラー自体は起きず暫く応答がなくなった後にそのままクエリが進行)
- ターゲットノードタイプが既存のノードタイプと異なる場合は、最新のスナップショットからこのクラスターにデータをコピーしし、データ転送中、Redshift は読み取り専用モードで動作し、すべての書き込みがブロックされる。Redshift は新しいクラスターのエンドポイントを自動的に更新し、既存のクラスターのエンドポイントと一致させる。その後、元のクラスターへのすべての接続が一度切断される。
バックアップ
Redshift クラスターのバックアップはRDS同様スナップショットを用いて行う。
RDS と異なり、結構できることが多い印象を受ける。
- 前回のスナップショット以降にクラスターに加えられた増分変更を追跡する、増分スナップショット。
- 自動・手動の2種類がある
- 自動の場合、スナップショットが8時間ごと、または、5GBのデータの変更ごとに取得される
- 自動スナップショットのスケジュールをcron式などで定義可能
- 別リージョンにスナップショットをコピーすることができる
- 特定のテーブルを除外してスナップショットを取得可能
- スナップショットからの復元時は、クラスター全体、または、特定のテーブル(一度に復元できるのは1テーブル)といった単位でリストアが可能。
▼ 参考:
拡張VPCルーティング
デフォルトだと Redshift はインターネット経由でS3バケットにアクセスしてデータのロードやアンロードを実行する。
Redshift が存在するVPCにS3エンドポイントを作成して、サブネットのルートテーブルにS3へのルーティングをS3 VPCエンドポイントを経由するように設定することで、Redshift にて拡張VPCルーティングを有効化すると、Redshift <==> S3 の通信がS3エンドポイントを経由するように構成可能。
▼ 参考:
パラメータグループ
変更できるパラメータグループのパラメータは少なく、10固程度。変更の反映のためには対象クラスターの再起動が必要。
-
auto_analyze- デフォルト値: true
- テーブルの統計情報を自動で収集するかどうかを定義。
- テーブルの10%が更新されたら、自動統計情報収集が走る。(SHOW analyze_threshold_percent;で閾値は確認できる。)
-
enable_user_activity_logging- デフォルト値: false
- 有効化するとユーザーアクティビティログを S3 に対して監査ログとして出力可能。
-
require_ssl- デフォルト値: false
- Redshift に対するSSL接続を有効化するかどうか。
- falseだとSSL接続もできるし、非SSL接続もできる。trueだとSSL接続のみできる。
-
search_path- デフォルト値: $user, public
- PostgreSQL でもあるパラメータだが、デフォルトのスキーマを定義する。デフォルトだとユーザー名に一致するスキーマ、それがなければpublicスキーマ。
-
statement_timeout- デフォルト値: 0 (無制限)
- クエリの実行時間が指定した値(ms)を超えたらRedshift側からクエリがキャンセルされるタイムアウト値。
-
enable_case_sensitive_identifier- デフォルト値: true
- データベース、テーブル、および列の名前識別子が大文字と小文字を区別するかどうかを決定する構成値
- 大文字は""で囲むと保持されて解釈される
結果キャッシュ
Redshift では、クエリの実行時間を短縮し、システムパフォーマンスを向上させるために、特定の種類のクエリの結果をリーダーノード上のメモリにキャッシュする仕組みがある。
具体的には以下の条件に全て該当する場合に、新しいクエリに対してキャッシュされた結果を使用します。イメージとしてはMySQLのクエリキャッシュに近い。
- クエリを発行したユーザーは、クエリで使用されるオブジェクトへのアクセス権を持っている。
- クエリ内のテーブルまたはビューは変更されていない。(実際のクエリで参照されないテーブルデータの部分が少し変わるだけでもNG)
- クエリでは、GETDATE のような、実行するたびに評価する必要がある関数は使用しない。
- クエリは Amazon Redshift Spectrum の外部テーブルを参照しない。
- クエリの結果に影響を与える構成パラメーターが変更されない。(?)
- クエリは、キャッシュされたクエリと構文的に一致。
なお、その他考慮点としては、
- サイズの大きなクエリ結果セットはキャッシュしない。
- 現在のセッションで結果キャッシュの利用を無効にするには、
enable_result_cache_for_sessionパラメータを off にする。検証したところ、off にしたセッションで発行されたクエリは結果キャッシュとして他のセッションでも利用できず、off にしたセッションでは他のセッションの結果キャッシュも利用できない。 - クエリで結果のキャッシュを使用されるかどうかを判断するためには、
SVL_QLOGシステムビューの結果を見る。- source_query 列がソースクエリのクエリ IDを返していれば、結果キャッシュから返している。
- source_query 列が Null ならば結果キャッシュから返していない。
ユーザー管理
Redshift で作成・管理できるユーザーとして、スーパーユーザーとユーザーが存在する。
スーパーユーザー
- スーパーユーザーは、すべてのデータベースのデータベース所有者と同じ特権を持つ。
- クラスターの起動時に作成したマスターユーザーとは、スーパーユーザー。
- スーパーユーザーは、すべての System views、及び、PostgreSQL カタログテーブルを表示できる
create user adminuser createuser password '1234Admin';
alter user adminuser createuser;
ユーザー
- Amazon Redshift へのログイン時に認証に利用される。
- スーパーユーザーはユーザーの一種。
- Amazon Redshift ユーザーアカウントを作成および削除できるのは、データベーススーパーユーザーのみ。
- ユーザーは、データベースおよびデータベースオブジェクト (例えば、テーブル) を所有でき、それらのオブジェクトに対する特権をユーザー、グループ、およびスキーマに付与して、各オブジェクトに対するアクセス権限を付与するユーザーを管理する。
- 対象データベースオブジェクトを作成したユーザー、また、スーパーユーザーのみが、当該データベースオブジェクトに対する特権を照会、変更、または付与できる。
select * from pg_user;
S3 からのデータロード
Redshift -> S3 間で通信することでデータのロードが出来る。なお、複数ファイルに分割した方が Redshift では高速にロードが可能。
重要な点として、
- ファイルの数がクラスターのスライスの数の倍数になるようにデータをファイルに分割することで、Amazon Redshift はスライス間でデータを均等に分割。
- スライス数がノードサイズで決定される。
ファイル分割数やスライス数を意識して各パターンで検証しどれが最も速いか検証する。
前提としては、10000000レコードの10GB程度のCSVファイルをロードする。
結果、ファイル分割した方が多少高速になった。
1. ファイル分割せずに1ファイルで10000000レコードをロード
相当に時間がかかってしまった。
drop table item1;
create table item1 (ID int ,COL1 int,COL2 varchar(5),COL3 varchar(4000));
copy item1 from 's3://<S3バケット名>/data/bigdata_10000000.csv'
iam_role '<IAMロール名>'
delimiter ',';
INFO: Load into table 'item1' completed, 10000000 record(s) loaded successfully.
COPY
時間: 149043.449 ms
2. 4ファイル分割してそれぞれ2500000レコードずつ、計10000000レコードをロード
# aws s3 ls s3://<S3バケット名>/data/
2021-11-09 09:40:23 2548621132 big1.csv
2021-11-09 09:40:23 2549732590 big2.csv
2021-11-09 09:40:23 2549732546 big3.csv
2021-11-09 09:40:23 2549731862 big4.csv
drop table item1;
create table item1 (ID int ,COL1 int,COL2 varchar(5),COL3 varchar(4000));
copy item1 from 's3://<S3バケット名>/data/'
iam_role 'arn:aws:iam::xxxxx:role/redshift-role'
delimiter ',';
INFO: Load into table 'item1' completed, 10000000 record(s) loaded successfully.
COPY
時間: 116400.087 ms
ソートキー
ソートキーで指定したテーブルの列を基準にストレージ上にデータをソートして保存するための設定。
Redshift の仕組み上、各列を1Mブロックに格納していくがソートキーで指定した列のそのブロックの最大、最小値をメタデータとして各ブロックに保存する。
そのため、範囲が制限された述語をクエリが使用する場合、クエリプロセッサは最小値と最大値を使用して、テーブルスキャン中に多数のブロックをすばやくスキップすることができる。例えば、日付でソートされた 5 年間のデータがテーブルに保存されており、クエリによって 1 か月間の日付範囲が指定されていると仮定した場合、スキャンからディスクブロックの最大 98% を削除できます。データがソートされない場合は、より多くの (場合によっては、すべての) ディスクブロックをスキャンする必要があります。
また、単純にソートキーで指定した列でソートした場合にソート処理をスキップすることができるのでパフォーマンスが向上する。
### Sort Key で検索なし
dev=# alter table sh.sales alter sortkey(prod_id);
dev=# select count(*) from sh.sales where time_id between '2013-01-01 00:00:00' and '2015-01-01 00:00:00';
count
---------
3160521
(1 行)
時間: 124.092 ms
### Sort Key で検索
dev=# alter table sh.sales alter sortkey(time_id);
dev=# select count(*) from sh.sales where time_id between '2013-01-01 00:00:00' and '2015-01-01 00:00:00';
count
---------
3160521
(1 行)
時間: 26.995 ms
### Sort Key で検索なし
dev=# alter table dms.item1 alter sortkey(col3);
dev=# select id,col1,col2 from dms.item1 where id between 10000 and 20000 order by id;
id | col1 | col2
-------+------+-------
10000 | 189 | tZPxb
10001 | 737 | dSdKM
10002 | 882 | GThYJ
10003 | 981 | NrxJN
10004 | 493 | lToxb
10005 | 200 | zfyRF
10006 | 73 | DfJRg
10007 | 36 | nsAlO
10008 | 762 | AEPhR
10009 | 22 | DgKtP
10010 | 155 | WMulD
10011 | 803 | cHJej
10012 | 652 | bSCWS
10013 | 681 | HAAnC
10014 | 365 | siQnK
10015 | 89 | weEqC
10016 | 939 | UrKJs
10017 | 802 | eEnPV
10018 | 994 | tTjyO
10019 | 446 | gIGtS
10020 | 628 | JqqEP
10021 | 517 | OByZt
10022 | 185 | QPsRJ
10023 | 172 | bhytb
10024 | 689 | uQSzb
10025 | 943 | qMieJ
10026 | 174 | NKmaZ
10027 | 866 | nuLlX
10028 | 190 | qkJKE
10029 | 154 | vCtdN
10030 | 340 | jJhZy
10031 | 546 | DSjQR
10032 | 695 | cMTjA
10033 | 132 | yUfku
10034 | 931 | TXQPk
時間: 5996.154 ms
### Sort Key で検索
dev=# alter table dms.item1 alter sortkey(id);
dev=# select id,col1,col2 from dms.item1 where id between 10000 and 20000 order by id;
id | col1 | col2
-------+------+-------
10000 | 189 | tZPxb
10001 | 737 | dSdKM
10002 | 882 | GThYJ
10003 | 981 | NrxJN
10004 | 493 | lToxb
10005 | 200 | zfyRF
10006 | 73 | DfJRg
10007 | 36 | nsAlO
10008 | 762 | AEPhR
10009 | 22 | DgKtP
10010 | 155 | WMulD
10011 | 803 | cHJej
10012 | 652 | bSCWS
10013 | 681 | HAAnC
10014 | 365 | siQnK
10015 | 89 | weEqC
10016 | 939 | UrKJs
10017 | 802 | eEnPV
10018 | 994 | tTjyO
10019 | 446 | gIGtS
10020 | 628 | JqqEP
10021 | 517 | OByZt
10022 | 185 | QPsRJ
10023 | 172 | bhytb
10024 | 689 | uQSzb
10025 | 943 | qMieJ
10026 | 174 | NKmaZ
10027 | 866 | nuLlX
10028 | 190 | qkJKE
10029 | 154 | vCtdN
10030 | 340 | jJhZy
10031 | 546 | DSjQR
10032 | 695 | cMTjA
10033 | 132 | yUfku
10034 | 931 | TXQPk
時間: 5548.262 ms
マテリアライズド・ビュー
Redshift でも PostgreSQLやOracleのようにソース表のデータの実体を保持するマテリアライズドビューを作成することが出来る。
- スナップショットに含めるかどうかを指定することが出来る。(BACKUP句)
- 自動でリフレッシュするかどうか指定することが出来る。Redshift は、ベーステーブルが変更された後、できるだけ早くマテリアライズドビューを自動更新する。(AUTO REFRESH句)
CREATE MATERIALIZED VIEW MV1
BACKUP NO
SORTKEY (col1)
AUTO REFRESH YES
AS select col1,count(*) from big group by col1;
- 基本的な動作として増分リフレッシュができれば増分リフレッシュ。それが不可能であれば完全リフレッシュとなる。
-
STV_MV_INFOビューから、 is_stale でそのマテビューが最新かどうか判断可能。state=1 ならば増分リフレッシュ可能。
dev=# select * from STV_MV_INFO;
-[ RECORD 1 ]----+---------------------------------------------------------------------------------------------------------------------------------
db_name | dev
schema | public
name | mv1
updated_upto_xid | 3523261
is_stale | t
owner_user_name | awsuser
state | 1
autorefresh | t
autorewrite | t
-
SVL_MV_REFRESH_STATUSビューからどの程度の頻度でリフレッシュされているかが判別可能。
dev=# select * from SVL_MV_REFRESH_STATUS;
-[ RECORD 1 ]+---------------------------------------------------------------------------------------------------------------------------------
db_name | dev
userid | 100
schema_name | public
mv_name | mv1
xid | 3523039
starttime | 2021-11-21 14:48:47.140913
endtime | 2021-11-21 14:51:01.90037
status | Refresh successfully updated MV incrementally
refresh_type | Auto
-[ RECORD 2 ]+---------------------------------------------------------------------------------------------------------------------------------
db_name | dev
userid | 100
schema_name | public
mv_name | mv1
xid | 3523470
starttime | 2021-11-21 14:55:17.258456
endtime | 2021-11-21 14:57:24.361968
status | Refresh successfully updated MV incrementally
refresh_type | Auto
-[ RECORD 3 ]+---------------------------------------------------------------------------------------------------------------------------------
db_name | dev
userid | 100
schema_name | public
mv_name | mv1
xid | 3523262
starttime | 2021-11-21 14:52:03.199686
endtime | 2021-11-21 14:54:16.903826
status | Refresh successfully updated MV incrementally
refresh_type | Auto
フェデレーテッドクエリ
- 外部のデータソースに対してクエリをデータベースリンクのような形で実行できる機能
- 横串検索により以下の外部データベースに対してクエリ実行可能
- RDS MySQL
- Aurora MySQL
- RDS PostgreSQL
- Aurora PostgreSQL
- Secret Managerに格納した認証情報を、Redshiftクラスターに関連づけたIAMロール経由で取得する。
- 横串検索を実行すると、Amazon Redshift は、まずリーダーノードから RDS または Aurora DB インスタンスへのクライアント接続を確立し、テーブルメタデータを取得。また、コンピューティングノードから、Amazon Redshift は述語がプッシュダウンされたサブクエリを発行し、結果の行を取得。
- OLTP系の外部データベースのライブデータを組み合わせて検索したい場合に、サブクエリにフェデレーテッドクエリを定義して返却された結果を更にRedshiftに格納されたデータと統合することなどの用途が考えられる。
- 外部データベースへの読み取りアクセスのみ許可されており、書き込みは不可。
- 逆方向へのアクセス(=> Redshift)はできない。
-- 外部スキーマ定義
CREATE EXTERNAL SCHEMA pg
FROM POSTGRES
DATABASE 'sample'
SCHEMA 'public'
URI '<エンドポイント名>'
PORT 5432
IAM_ROLE '<IAMロールARN>
SECRET_ARN '<Secret Manager ARN>';
-- 外部スキーマ定義情報
SELECT * FROM svv_external_schemas WHERE schemaname = 'pg' ;
-- 外部データベースのテーブルメタデータ情報
SELECT * FROM svv_tables where table_type = 'EXTERNAL TABLE' AND table_schema = 'pg';
実際にRDS PostgreSQL側のログを見たところ、Redshift側のリーダーノード、コンピューティングノードから接続がなされていることが判別できる。
2021-11-29 03:07:59 UTC:10.10.6.26(57484):[unknown]@[unknown]:[5286]:LOG: connection received: host=10.10.6.26 port=57484 => リーダーノード
2021-11-29 03:07:59 UTC:10.10.6.15(42772):[unknown]@[unknown]:[5287]:LOG: connection received: host=10.10.6.15 port=42772 => コンピューティングノード
WLM
- WLM (Work Load Management)は、Redshiftに対して実行されるクエリに対して割り当てるリソース制御をする。
- 事前にWLMとして、キューを用意しておき、キューに対して割り当てるメモリの割合、並列度、タイムアウトの時間を指定することで、過剰にクラスターでリソースを使わないように制御する。
- 割り当てられるWLMとしてはユーザーに対してWLMキューを割り当てるユーザーグループ、SQLに対してWLMを割り当てるクエリグループがある。
- Redshift ではデフォルトでWLMキューが1つ用意されており、5並列で実行が可能。何かユーザーグループやクエリグループが指定されなければ使用される。つまり、5並列クエリまではアクティブに実行されるが、その間にそれ以上クエリを投げても先に投げている5クエリのどれかが終了しない限り、待機する。

- 例えばアプリケーションから実行される短期間のクエリを実行する際に、長時間かかるバッチ向けのクエリでWLMのキューが埋まっている場合、アプリケーションからのクエリは待機しなければならない。そのため、アプリケーションからのクエリについては優先度の高いキューに配置しておき、長時間かかっても良いバッチ用のクエリは優先度の低いキューで実行するような考え方もできる
- 自動WLMはメモリ%、クエリ並列度は指定せずRedshiftが自動的にこれらを管理する。クエリの優先度はキューごとに指定する。
バキューム
Redshift では定期的なメンテナンスとしてバキューム処理が存在する。主な役割としては以下の2つを実行する。
- update や delete で発生するデッドタプル(どのトランザクションからも不可視)なタプルの領域回収を行う。
- ソートキーに基づき再ソートを行う。
PostgreSQL と異なり、vacuum の動作としてデフォルトが vacuum full。またソートキーに基づきソートをし直すという動作がある。
圧縮エンコードのテスト
圧縮エンコードを各列ごとに指定できるので試しに同一のデータが格納された列同士でどの程度圧縮の効果があるのかテスト。
# 大量データを生成
drop table cartesian_venue;
create table cartesian_venue(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer);
insert into cartesian_venue
select venueid, venuename, venuecity, venuestate, venueseats
from venue, listing;
insert into cartesian_venue select * from cartesian_venue;
insert into cartesian_venue select * from cartesian_venue;
insert into cartesian_venue select * from cartesian_venue;
select * from cartesian_venue limit 5;
venueid | venuename | venuecity | venuestate | venueseats
---------+--------------------+--------------+------------+------------
24 | Conseco Fieldhouse | Indianapolis | IN | 0
24 | Conseco Fieldhouse | Indianapolis | IN | 0
24 | Conseco Fieldhouse | Indianapolis | IN | 0
24 | Conseco Fieldhouse | Indianapolis | IN | 0
24 | Conseco Fieldhouse | Indianapolis | IN | 0
select count(*) from cartesian_venue;
count
-----------
311075152
# 生成したデータのvenuename列のデータでそれぞれ圧縮エンコードが異なるテーブルを作成
drop table encodingvenue;
create table encodingvenue (
venueraw varchar(100) encode raw,
venuebytedict varchar(100) encode bytedict,
venuelzo varchar(100) encode lzo,
venuerunlength varchar(100) encode runlength,
venuetext255 varchar(100) encode text255,
venuetext32k varchar(100) encode text32k,
venuezstd varchar(100) encode zstd);
insert into encodingvenue
select venuename as venueraw,
venuename as venuebytedict,
venuename as venuelzo,
venuename as venuerunlength,
venuename as venuetext32k,
venuename as venuetext255,
venuename as venuezstd
from cartesian_venue;
# 1M のデータブロックが各列ごとにいくつか確認すると各列の圧縮効果が分かる。値が低いほど効果大のため、この例の場合、zstdが最大効果。raw に比べると120倍以上の圧縮効果
select col, max(blocknum)
from stv_blocklist b, stv_tbl_perm p
where (b.tbl=p.id) and name ='encodingvenue'
and col < 7
group by name, col
order by col;
col | max
-----+------
0 | 1221
1 | 62
2 | 16
3 | 20
4 | 224
5 | 434
6 | 10
# 検索速度の差異
select count(venuezstd) from encodingvenue;
count
-----------
349959546
(1 行)
時間: 1102.792 ms
select count(venueraw) from encodingvenue;
count
-----------
349959546
(1 行)
時間: 4589.244 ms
# どの列も全く同じデータなのでzstd圧縮エンコードによる圧縮効果が推奨
analyze compression encodingvenue ;
Table | Column | Encoding | Est_reduction_pct
---------------+----------------+----------+-------------------
encodingvenue | venueraw | zstd | 99.58
encodingvenue | venuebytedict | zstd | 0.00
encodingvenue | venuelzo | zstd | 55.43
encodingvenue | venuerunlength | zstd | 77.01
encodingvenue | venuetext255 | zstd | 97.87
encodingvenue | venuetext32k | zstd | 98.90
encodingvenue | venuezstd | zstd | 0.00
よく使うクエリ
テーブル情報一覧
- size は 1MB のデータブロック単位
select database,schema,"table", encoded, diststyle, sortkey1,sortkey_num,skew_sortkey1,skew_rows,size,tbl_rows,pct_used,unsorted,vacuum_sort_benefit from svv_table_info order by 1,2,3;
特定テーブルのsliceへのデータ分散情報
select trim(name),slice,sum(rows) from stv_tbl_perm where name='big'
group by name,slice order by slice;
参考資料
Discussion