マルチタスクはどう実現されているか?JavaScriptとPureScriptで学ぶマルチタスクの実装



この記事はJavaScriptとPureScriptでマルチタスクの仕組みがどう実現されているかを解説する記事です。
題材とするのは、PureScriptの非同期処理ライブラリAffです。
実はこのライブラリ、マルチタスクの仕組みを実現する実装のコア部分はJavaScriptで書かれています※。
したがってこの記事に出てくるコードは9割くらいはJavaScriptのコードになります。
なので「PureScriptはわからんけどJavaScriptならわかる」という方の知的好奇心も満たすことができるかもしれません。
目次から「Fiberの実行でまず行われること」にジャンプして下にスクロールしていただければ、JavaScriptのコードが多いということがわかるかと思うので気になる方はまず試しにこちらをぱっと見していただけたらと思います。
こういう話をします
- マルチタスクの方式の話
- Fiberの話
- Affのマルチタスクの仕組みはイベントループ上で実現されているよって話
- イベントループついてイベントごとにこういう処理がされているよって話
- FiberをJoinしたとき何が起きているかって話
では早速はじめましょう!
マルチタスクの方式
マルチタスクにおけるタスクの切り替えには大きく2つの方式があります。
- プリエンプティブ・マルチタスク(非協調的マルチタスクともいう)
- ノンプリエンプティブ・マルチタスク(協調的マルチタスクともいう)
現代的なOSの多くが採用しているのが「プリエンプティブ・マルチタスク」で、PureScriptのAffは「ノンプリエンプティブ・マルチタスク」となります。
それぞれ簡単に説明しましょう。
プリエンプティブ・マルチタスク
次の図はプリエンプティブ・マルチタスクのイメージ図です。
スケジューラー、タスク、タイマーという登場人物がおり、なにやらスケジューラーが一定間隔で指示を出しています。タスクAが動いているときはタスクBは何もしていません。その逆も然りです。タスクはスケジューラーの指示に従います。
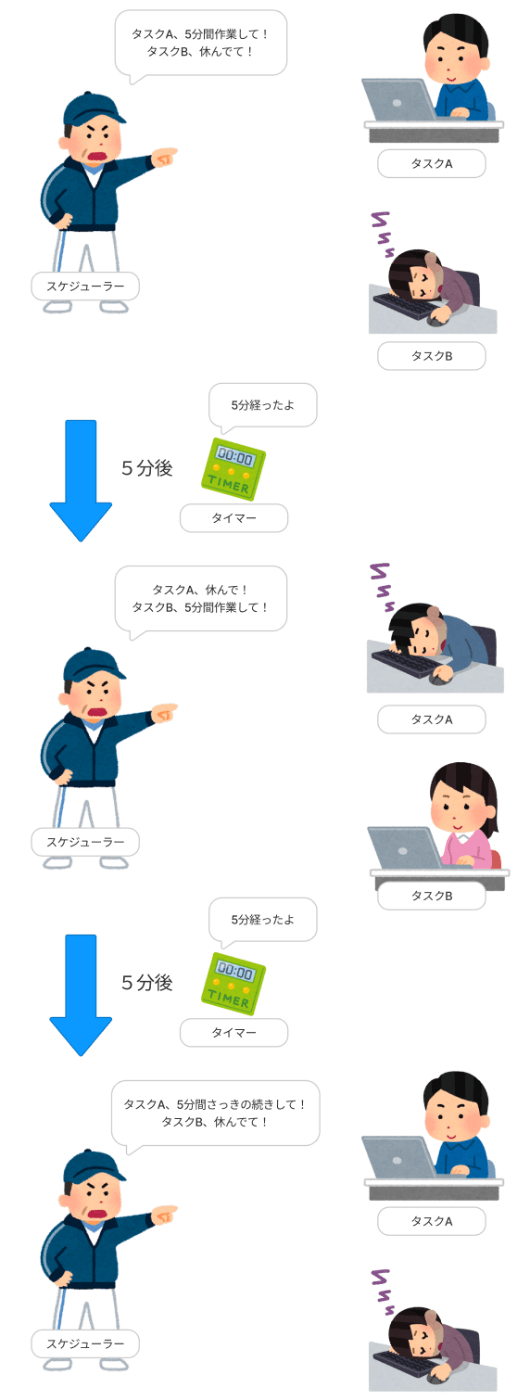
この例では5分作業してとか言ってますが、本当は滅茶苦茶短い時間です。
超高速でタスクを切り替えることで同時に動いてるように感じさせているわけです。
高速で動くことで複数人いるように見せかける忍者の分身の術みたいなものです。

またタイマー君が一定時間経過したことを通知してきていますが、これは実際ではタイマー割り込みという仕組みが使われます。
ここでちょっと割り込みの話をします。
CPUはキーボードやマウスといったデバイスからの要求を受け付け、その要求に対応した処理を行うことができます。この要求を『割り込み』といいます、割り込みには割り込みに対応する処理『割り込みハンドラー』が紐づけられており、割り込みが発生したときは割り込みハンドラーが動きます。
いまのPC/AT互換機ではハードウェアタイマーがチップセットに組み込まれており、そこからの割り込みでタイマーの割り込みハンドラーが動きます。
(余談ですが、ハードウェアからの割り込みとは別にソフトウェア割り込みというのもあり、システムコールに使われていたりします)
ざっくりまとめるとプリエンプティブ・マルチタスクとは『外部からの何らかの強制力によりタスクを切り替える』方式ということになります。
ノンプリエンプティブ・マルチタスク
今度はこちらの図をみてください。
タスクが自ら処理を中断しています。
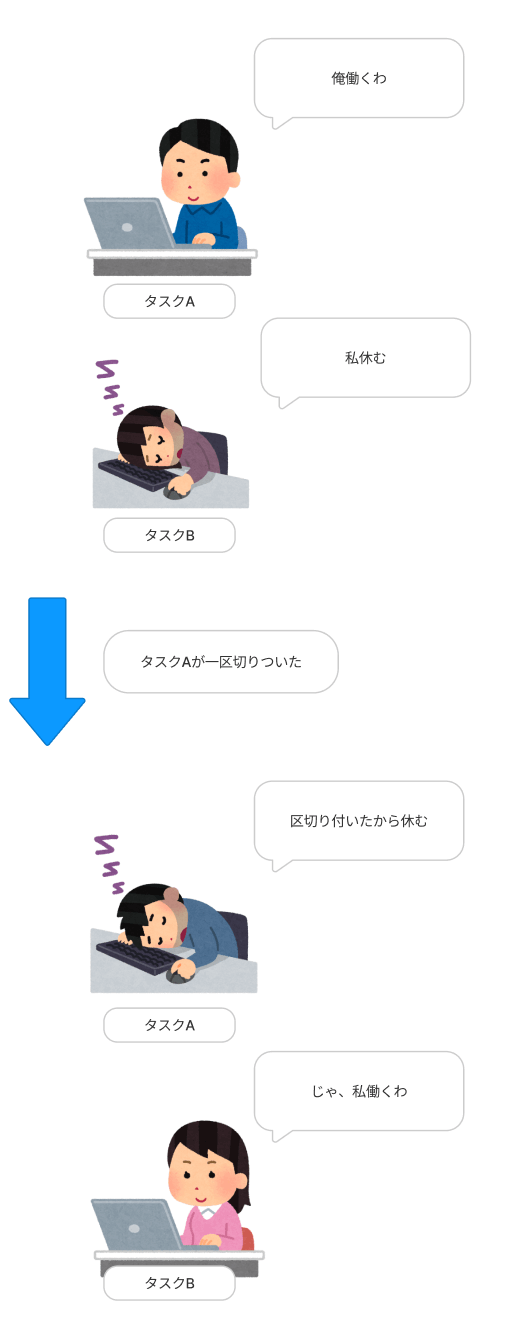
「一区切り付いた」とはひどく曖昧ですが、どういうタイミングでそれを判断して次のタスクに譲るかは実装に依るので致し方ありません。
スケジューラーによって強制的に切り替えが行われるプリエンプティブ・マルチタスクとは異なり、タスク達自らが協調して切り替えを行っていくので協調的マルチタスクと言われるのでしょう。
前述した通りPureScriptのAffはこちらの方式で実装されていますので、本記事ではこれからの方式での実装を説明していきます。
Fiber
Fiberとは軽量スレッドの一種で、ノンプリエンプティブであるという特徴があります。
つまり協調マルチタスク方式で実現されるスレッドです。
なぜ突然Fiberの話をはじめたかというと、PureScriptのAffの実態がFiberだからです。
すなわちPureScriptのAffではFiberが一つの実行単位となります。
AffがFiberとして動いているということはlaunchAff関数のコードを見れば明らかでしょう。
makeFiber関数でFiberを作ってrunという関数を呼び出していますね。
このrun関数によりFiberが実行されることになります。
-- | Forks an `Aff` from an `Effect` context, returning the `Fiber`.
launchAff :: forall a. Aff a -> Effect (Fiber a)
launchAff aff = do
fiber <- makeFiber aff
case fiber of Fiber f -> f.run
pure fiber
-- | Forks an `Aff` from an `Effect` context, discarding the `Fiber`.
launchAff_ :: Aff Unit -> Effect Unit
launchAff_ = void <<< launchAff
Fiberの実行でまず行われること
Fiberを実行するrun関数は次のような定義になっています。
run: function () {
if (status === SUSPENDED) {
if (!Scheduler.isDraining()) {
Scheduler.enqueue(function () {
run(runTick);
});
} else {
run(runTick);
}
}
}
statusについては後述しますが最初は必ずSUSPENDになっているので必ずこの分岐には入ります。
次にSchedulerというものが登場していますね。
isDrainingの結果で分岐は行われるものの結局run(runTick)という関数を呼び出すことになります。
このrun(runTick)がFiberの実行におけるメインの関数なのですが、まず先にSchedulerの説明をしましょう。
Schedulerとは何か
次がSchedulerの定義です。
var Scheduler = function () {
var limit = 1024;
var size = 0;
var ix = 0;
var queue = new Array(limit);
var draining = false;
function drain() {
var thunk;
draining = true;
while (size !== 0) {
size--;
thunk = queue[ix];
queue[ix] = void 0;
ix = (ix + 1) % limit;
thunk();
}
draining = false;
}
return {
isDraining: function () {
return draining;
},
enqueue: function (cb) {
var i, tmp;
if (size === limit) {
tmp = draining;
drain();
draining = tmp;
}
queue[(ix + size) % limit] = cb;
size++;
if (!draining) {
drain();
}
}
};
}();
ざっくり説明します。
-
Shedulerはキューを持っている - キューは関数を保持する
-
drain関数は、キューにある関数を追加された順序ですべて実行する -
drain関数の実行が開始されるとdrain中であることを表すdrainingという変数がtrueとなり、終了するとfalseとなる。 -
enqueue関数で、キューに関数を追加することができる -
enqueue関数で、キューを追加したときdrain中でなければdrain関数を実行する。
enqueueでキューに関数を追加したとき、drain実行中でなければ、追加した関数はすぐ実行されます。
一方drain中であればキューに追加するだけで終わります。この場合キューに追加された関数はdrain中でないときに再度enqueueが呼ばれたら実行されることになります。
基本的にはキューに入れたらすぐ処理されるので、多くの場合キューが保持する関数は一つだけになります。
複数になるのは、drain関数から実行される関数の中でenqueueを呼び出した場合です。
(drain中なので)処理が行われずキューに追加されるからです。
Fiberの実行処理はイベントループになっている
Fiberのrun関数からはrun(runTick)関数が呼ばれていたのでした。
そしてこちらの関数こそFiberの核となる処理なのです。
詳しく解説する前に先に大枠の説明をします。
run(runTick)関数の大枠は
『イベントループ』
という形で実装されています。
どういうことかというと、Fiberは一種のステートマシンとなっており、status(状態)を遷移させながらstep(処理)を実行していくのです。
どういうことか、イベントループが行われているrun(runTick)関数のコードを見てみましょう。
いまは雰囲気だけ感じ取ってもらいたいので諸々の処理は省略しています。
(全体を見たい方はこちらを御覧ください)
statusやstep、bhead、joinsなど色々状態を表す変数が定義されていることとstatusやstepのtagによる分岐があることがわかるでしょう。
function Fiber(util, supervisor, aff) {
var runTick = 0;
var status = SUSPENDED;
var step = aff; // Successful step
var fail = null; // Failure step
var interrupt = null; // Asynchronous interrupt
var bhead = null;
var btail = null;
var attempts = null;
var bracketCount = 0;
var joinId = 0;
var joins = null;
var rethrow = true;
function run(localRunTick) {
var tmp, result, attempt;
while (true) {
tmp = null;
result = null;
attempt = null;
switch (status) {
case STEP_BIND:
status = CONTINUE;
// 略
break;
case STEP_RESULT:
// 略
break;
case CONTINUE:
switch (step.tag) {
case BIND:
// 略
break;
case PURE:
// 略
break;
case SYNC:
// 略
break;
case ASYNC:
// 略
return;
case THROW:
// 略
break;
case CATCH:
// 略
break;
case BRACKET:
// 略
break;
case FORK:
// 略
break;
case SEQ:
// 略
break;
}
break;
case RETURN:
// 略
break;
case COMPLETED:
// 略
return;
case SUSPENDED:
status = CONTINUE;
break;
case PENDING: return;
}
}
}
// 略
}
run関数が実行されると、すぐwhileループが始まります。
ループの中ではstatusにより処理が分岐されており、その分岐ごとの処理で次のstatusが決定されます。このループ処理はreturnに至るまで続けられます。
つまり イベントループ です。
さてstatusの遷移ですが、statusがCONTINUEのときは更にstep.tagで分岐します。
stepがどういう値かは状況によって変わるのですが、CONTINUEのときは必ずAffというオブジェクトになります。
Affは次のような定義になっています。
function Aff(tag, _1, _2, _3) {
this.tag = tag;
this._1 = _1;
this._2 = _2;
this._3 = _3;
}
tagはAffの処理の種類を表しているようなもので以下の値をとりえます。BINDとかPUREとかを見るとなんとなくPureScript側のコードとの繋がりが見えますね。
var PURE = "Pure";
var THROW = "Throw";
var CATCH = "Catch";
var SYNC = "Sync";
var ASYNC = "Async";
var BIND = "Bind";
var BRACKET = "Bracket";
var FORK = "Fork";
var SEQ = "Sequential";
一方で_1,_2,_3といったプロパティはやたら抽象的な名前になっていますが、これはtagの種類や状況によって異なる値を持つことになる(関数だったり、Eitherの値だったり)ので、特定の名前がつけづらかったためだと私は推測しています。
さて、実際状態がどう遷移していくのかですが、すべてのコードを逐一見ていくのは厳しいものがあるので、Fiberの状態遷移図を用意しました。
今回説明に使わないいくつかのtag(THROW,CATCHなど)については図が無用に複雑化するため省略しました。
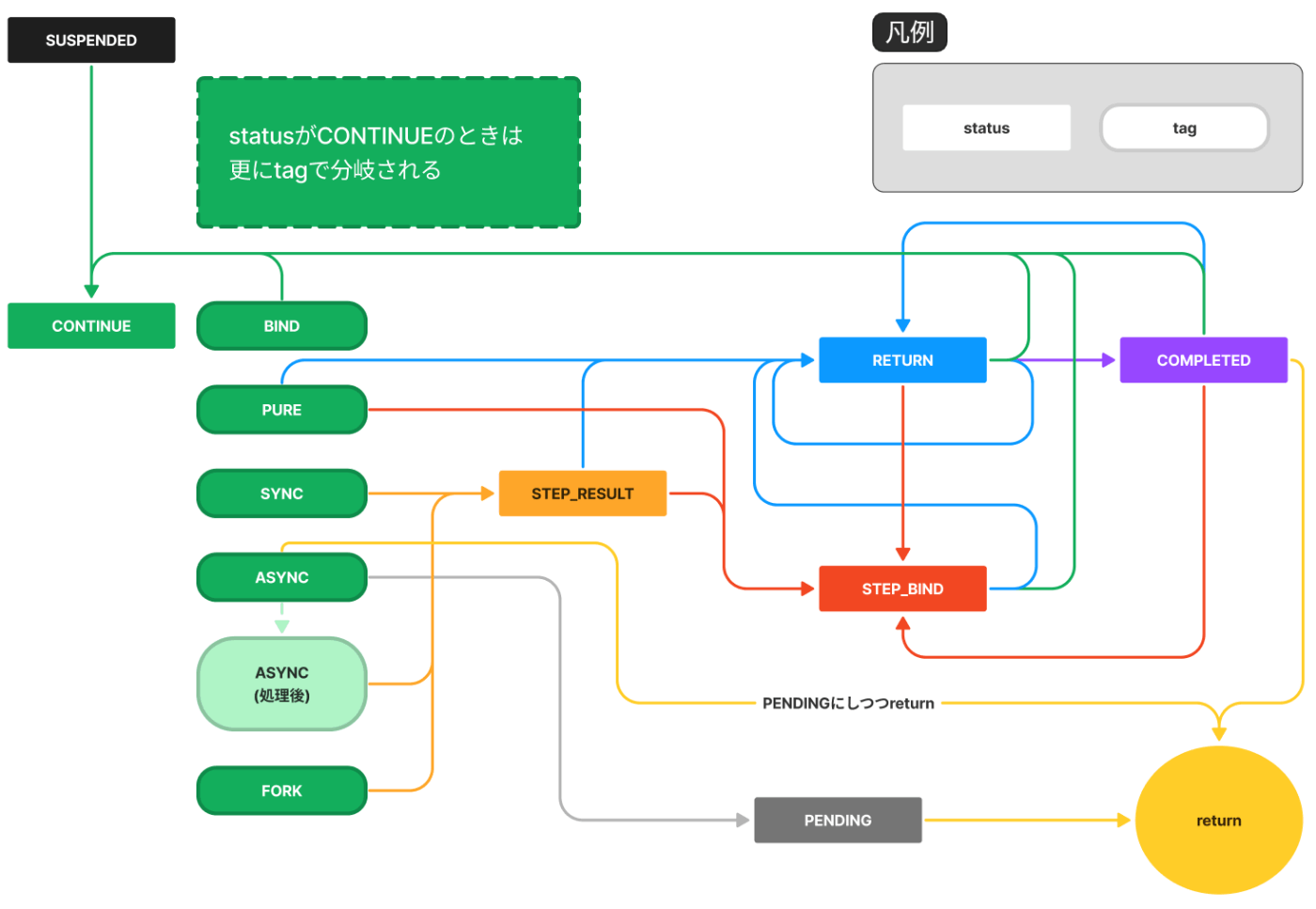
Fiberの状態遷移図
解説
最初はstatusがSUSPENDから始まります。続いてCONTINUEになり、上記で記述した通りstep.tagで処理が分岐します。例えばtagがBINDであればCONTINUEに戻ります。図には描かれていませんが、BINDのときはstepを書き換えてからCONTINUEに遷移するので次は別のtagになります(このあたりは後述します)。
また、statusやtagから複数の矢印が伸びているものは条件によって遷移先が変わるものです。
最終的にreturnのところに到達したらループを抜けるようになっています。
returnに至る経路としては例えば次のような経路があります。
-
PURE→RETURN→COMPLETED→return -
SYNC→STEP_RESULT→RETURN→COMPLETED→return -
ASYNC→return
ASYNCのときの流れは極めて重要なので、ここでちょっと説明しておきます。
ASYNCのときは非同期処理を実行しつつstatusをPENDINGにしてreturnします。
非同期処理の内容によりますが、処理を終える前にrunからreturnするわけです。
これは協調的マルチタスクでいうところの「次のタスクに処理を譲る」という部分に該当します。
ASYNC以外の処理の流れを見てみると基本的には処理の完了を意味するCOMPLETEDからreturnしているわけなので、ここが特別だということがご理解いただけるでしょう。
ちなみにstatusがPENDINGの場合はすぐreturnするようになっているので、ASYNCの処理が終わってreturnしたあとすぐにまたrunを呼び出した場合は何も行われずループが終了するということを意味します。
PENDINGになっているからといって心配する必要はなく、非同期処理の結果が返ってきた後にstatusをSTEP_RESULTに更新するので、結果が返ってきたら処理は次のループに進みます。
このASYNCの処理はあとでまたあとで詳しく書きます。
イベントループのイベントごとの処理
Fiber実行時のイベントループの大枠は掴めましたね。
次はjavascriptのAffオブジェクトとPureScriptのコードとの繋がりを示しながら、Affオブジェクトがイベントループでどう処理されるのかも見ていきます。
Affオブジェクトを作る関数
Affオブジェクトを作るにあたり次の関数が多用されているので、まずこれを先に載せます。
シンプルなクロージャですね。これがどう使われるかはすぐお見せします。
function AffCtr(tag) {
var fn = function (_1, _2, _3) {
return new Aff(tag, _1, _2, _3);
};
fn.tag = tag;
return fn;
}
PURE
最初に説明するAffオブジェクトはtagがPUREになるAffオブジェクトです。
早速AffCtr関数が出てきました。これを_pureという名前でexportしています。
Aff.Pure = AffCtr(PURE);
export const _pure = Aff.Pure;
これがPureScript側ではこう使われています。
instance applicativeAff :: Applicative Aff where
pure = _pure
foreign import _pure :: forall a. a -> Aff a
まぁ名前から想像できていたと思いますが、フツーにpureですね。
つまりpure 値とした場合次のようなAffオブジェクトが作られるということになります。
Aff(PURE, 値)
どう処理されるか
tagがPUREのときの処理はこうです。
case PURE:
if (bhead === null) {
status = RETURN;
step = util.right(step._1);
} else {
status = STEP_BIND;
step = step._1;
}
break;
bheadの有無で分岐しています。
bheadはBINDのところで後述しますが、後続の処理を表す変数です。
つまり後続の処理がなければ次はRETURNになります。
step = util.right(step._1)としていますが、step._1はpureの値でしたね。
util.rightはPureScriptのEitherのRight関数そのものです。
ここではありませんが、イベントループの処理では失敗することが考えられるので値はEitherになっています。
なので単純にstepには値が代入されたと思っていてよいです。
後続の処理がある場合次はSTEP_BINDとなります。
この場合stepには値をそのまま代入しています。
STEP_BINDの方はtagがBINDの説明でしますので、次はRETURNの方の説明をします。
statusがRETURNの場合はこの処理が行われます。
case RETURN:
bhead = null;
btail = null;
if (attempts === null) {
status = COMPLETED;
step = interrupt || fail || step;
} else {
// 処理は省略させてもらった
}
break;
attempsの有無で分岐していますが、attempsはPureScriptのAffのcatchError関数やbracket系の関数を使った場合に使われる変数で、PUREの場合はnullになっています。
また、これらの説明は本筋ではないため解説しません。
(こんな感じで解説しないところはガンガン省略します)
したがってattempsがnullの場合だけ考えればよく、次のstatusはCOMPLETEDだと分かります。
stepも今回の場合はinterruptとかfailは考えなくてよいです。つまりstepはそのままになります。
続いてCOMPLETEDです。
case COMPLETED:
for (var k in joins) {
if (joins.hasOwnProperty(k)) {
rethrow = rethrow && joins[k].rethrow;
runEff(joins[k].handler(step));
}
}
joins = null;
if (interrupt && fail) {
// 省略
} else if (util.isLeft(step) && rethrow) {
// 省略
}
return;
処理冒頭のjoinsはFiberをjoinした場合に使われる可能性がある変数です。
ここはjoinしたときの説明で解説します。
後半の分岐は例外処理周りで大筋から外れるため省略します。
あとはreturnしているので、イベントループはここで終わりです。
これが今回の遷移の様子です。

なんとなくstatusを遷移させながら処理を進めていくイメージが掴めましたでしょうか?
SYNC
次はBINDにいきたいのですが、説明の都合により先にtagがSYNCになるAffオブジェクトの説明をします。
SYNCに関連するjavascriptのコードは次になります。
var SYNC = "Sync";
Aff.Sync = AffCtr(SYNC);
export const _liftEffect = Aff.Sync;
exportされた_liftEffect関数をPureScript側で次のように参照しています。
instance monadEffectAff :: MonadEffect Aff where
liftEffect = _liftEffect
foreign import _liftEffect :: forall a. Effect a -> Aff a
以上の定義から例えば次のようなコードがあった場合(こんなことしなくてもEffect.Class.Consoleのlogを使えばいいのですが。。。)
import Effect.Aff (Aff)
import Effect.Class (liftEffect)
import Effect.Console (log)
example :: Aff Unit
example = liftEffect $ log "example"
作られるAffオブジェクトは次のようになります。
Aff(SYNC, "example"をログ出力する関数)
どう処理されるか
次がtagがSYNCのときの処理です。
case SYNC:
status = STEP_RESULT;
step = runSync(util.left, util.right, step._1);
break;
statusをSTEP_RESULTにして、次のrunSync関数を実行し、その結果を新たなstepとしています。runSync関数の引数はeffは上記のstep._1すなわち上記の例だとログ出力をする関数です。
function runSync(left, right, eff) {
try {
return right(eff());
} catch (error) {
return left(error);
}
}
なのでこのタイミングでログ出力が行われ、結果がEitherのRightに包まれて返ります。これがあ新たなstepとなるわけですね。
続いてSTEP_RESULTです。
stepの値はLeftではなく、今回bheadはnullなのでstatusはRETURNとなります。
case STEP_RESULT:
if (util.isLeft(step)) {
status = RETURN;
fail = step;
step = null;
} else if (bhead === null) {
status = RETURN;
} else {
status = STEP_BIND;
step = util.fromRight(step);
}
break;
今回の場合RETURNはtagがPUREのときと同じで、そのままCOMPLETEDに遷移してreturnします。
今回の遷移の様子はこうです。
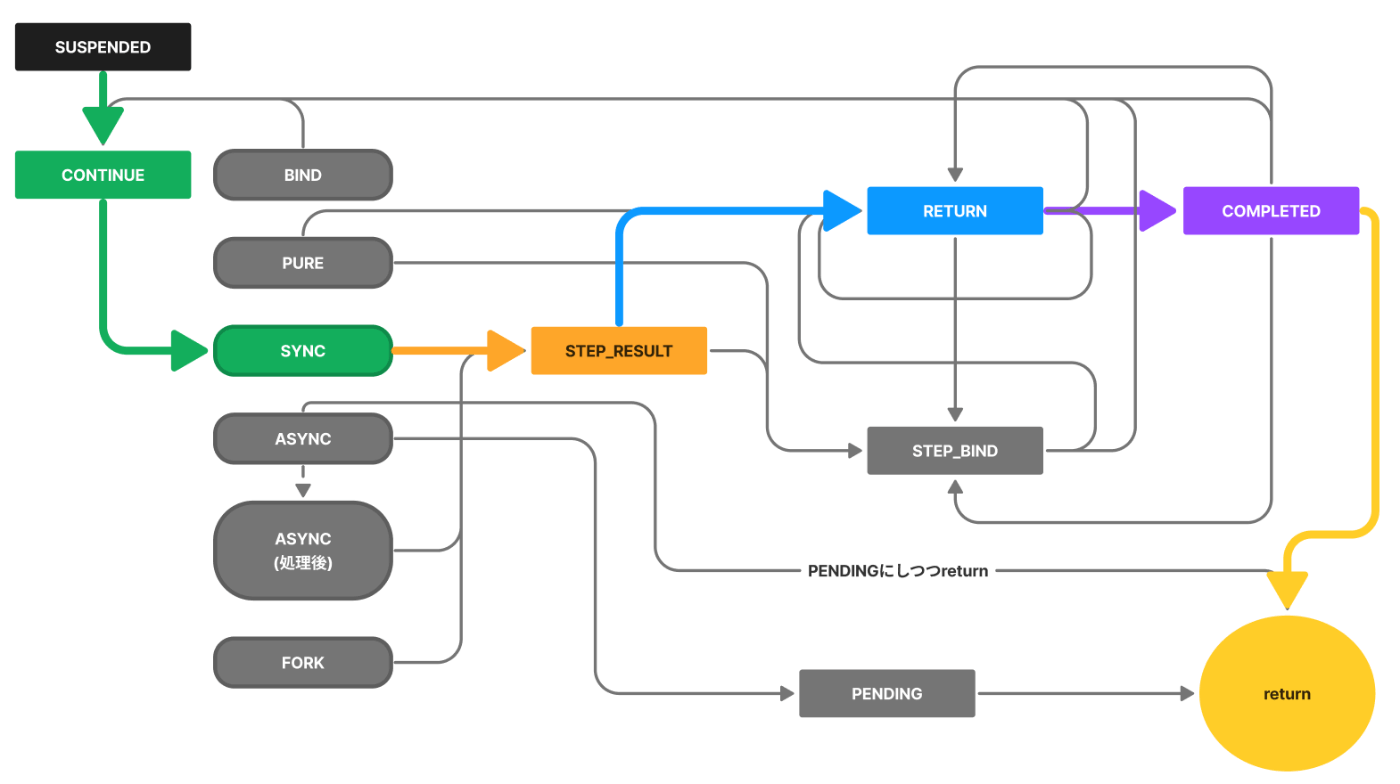
これでSYNCは終わりです。
BIND
次はtagがBINDになるAffオブジェクトです。
BINDに関連するjavascriptのコードは次になります。
var BIND = "Bind";
Aff.Bind = AffCtr(BIND);
export function _bind(aff) {
return function (k) {
return Aff.Bind(aff, k);
};
}
exportされた_bind関数をPureScript側で次のように参照しています。
instance bindAff :: Bind Aff where
bind = _bind
foreign import _bind :: forall a b. Aff a -> (a -> Aff b) -> Aff b
上記から例えば次のようなコードがあるとします。
example :: Aff Unit
example = do
result <- liftEffect $ func1
liftEffect $ func2 result
func1 :: Effect String
func1 = pure "result"
func2 :: String -> Effect Unit
func2 a = log a
すると作られるAffオブジェクトは次のようになります。
Aff(
BIND,
Aff(SYNC, func1),
func1の結果を受け取って、Aff(SYNC, func2 result)を返す関数
)
どう処理されるか
次がtagがBINDのときの処理です。
case BIND:
if (bhead) {
btail = new Aff(CONS, bhead, btail);
}
bhead = step._2;
status = CONTINUE;
step = step._1;
break;
最初はbheadは存在しないので、ifの分岐には入りません。
しかし次の処理でstep._2すなわち後続の処理(今回でいうとfunc1の結果を受け取って新たなAffを返す関数)がbheadに代入されます。
次のstatusはCONTINUEになりますね。 そしてstepがAff(SYNC, func1)`となります。
なので、step.tagごとの処理に進みます。
今度はSYNCですが、ここの処理は説明済みでしたが、今一度見てみましょう。
case SYNC:
status = STEP_RESULT;
step = runSync(util.left, util.right, step._1);
break;
今回の場合runSyncではfunc1が実行され、結果の"result"がRightに包まれ、次のstepになります。
次はSTEP_RESULTに遷移します。
BINDを経由してこのSTATUSに遷移してきた場合はbhead(後続の処理)がある(nullでない)ので、次のstatusはSTEP_BINDになりますね。
また、Rightの中身"result"が取り出されて次のstepとなっています。
case STEP_RESULT:
// stepはRightなのでここには入らないよ
if (util.isLeft(step)) {
status = RETURN;
fail = step;
step = null;
} else if (bhead === null) {
status = RETURN;
} else {
status = STEP_BIND;
step = util.fromRight(step);
}
break;
STEP_BINDの処理で着目するのはbheadが示す関数にstepが渡され、その結果が次のstepになっているというところです。
bheadは
case STEP_BIND:
status = CONTINUE;
try {
step = bhead(step);
if (btail === null) {
bhead = null;
} else {
bhead = btail._1;
btail = btail._2;
}
} catch (e) {
status = RETURN;
fail = util.left(e);
step = null;
}
break;
bheadは後続の処理ですが、今回でいうとfunc1の結果を受け取ってfunc2を呼ぶ新たなAffを返す関数でした。
stepは"result"です。
なのでAff(SYNC, func2 "result")が返ってきて、これが次のstepになります。
btailがなければbheadはnull(後続の処理はない)になります。
statusはCONTINUEになっているので、あとはまたSYNCの処理が行われます。
次のSYNCの処理はfunc2でログ出力だったので"result"がログ出力されます。
(SYNCではなくBINDであればまたbheadは後続の処理となる(nullでなくなる)ので、またSTEP_BINDに遷移してくることになります。)
今回の場合はもう後続の処理はないのでSTEP_RESULT→RETURN→COMPLETED→returnと遷移していき処理が終了します。
今回の遷移の様子です。処理が長くなったため、遷移も複雑になっています。
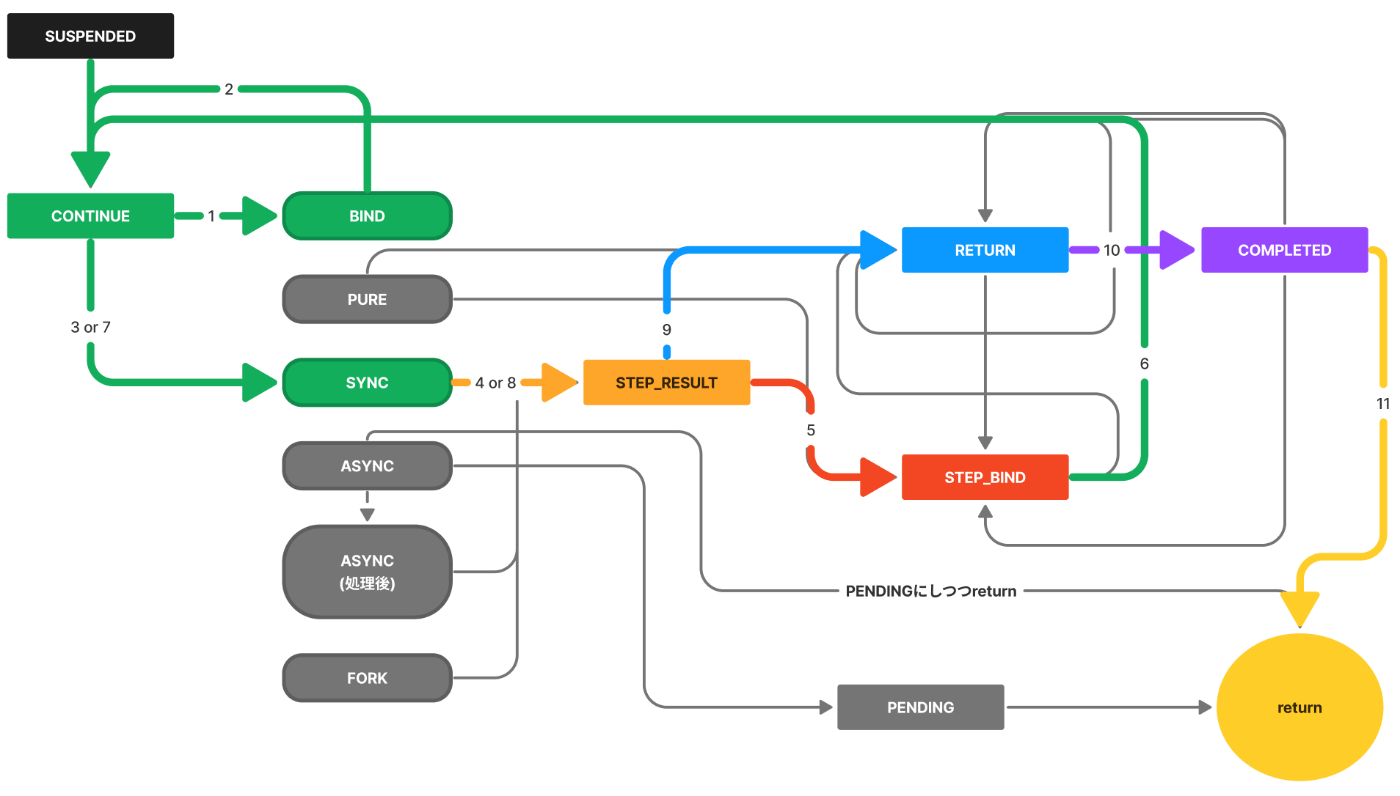
BINDによる後続の処理がある分だけグルグルとループ処理されていく感じがご理解いただけたかと思います。
ASYNC
次に説明するのはtagがASYNCになるAffオブジェクトです。
ここが今回の記事で一番重要な箇所かもしれません。
ASYNCに関連するjavascriptのコードは次になります。
var ASYNC = "Async";
Aff.Async = AffCtr(ASYNC);
export const makeAff = Aff.Async;
exportされたmakeAff関数をPureScript側で次のように参照しています。
(そのまま使えます)
foreign import makeAff :: forall a. ((Either Error a -> Effect Unit) -> Effect Canceler) -> Aff a
上記から例えば次のようなコードがあるとします。
example :: Aff Unit
example = makeAff \callback -> do
log "呼ばれたよ"
callback (Right unit)
pure nonCanceler
すると作られるAffオブジェクトは次のようになります。
Aff(ASYNC, コールバック関数を受け取り、Cancelerを返す関数)
どう処理されるか
次がtagがASYNCのときの処理です(長い)。
まずstatusがPENDINGになります。
そしてrunAsync関数を呼び出し、その結果を次のstepとし、returnで処理を抜けます。
runAsync関数には上記の「コールバック関数を受け取り、Cancelerを返す関数」とこの場で定義した関数が渡されています。
case ASYNC:
status = PENDING;
step = runAsync(util.left, step._1, function (result) {
return function () {
if (runTick !== localRunTick) {
return;
}
runTick++;
Scheduler.enqueue(function () {
// It's possible to interrupt the fiber between enqueuing and
// resuming, so we need to check that the runTick is still
// valid.
if (runTick !== localRunTick + 1) {
return;
}
status = STEP_RESULT;
step = result;
run(runTick);
});
};
});
return;
runAsyncがやってることは単純で、渡れてきた「コールバック関数を受け取り、Cancelerを返す関数」の引数をkとして実行して、その結果返ってくる関数を更に実行しています(effは引数なしの関数を返す関数ってことですね)。
function runAsync(left, eff, k) {
try {
return eff(k)();
} catch (error) {
k(left(error))();
return nonCanceler;
}
}
今回のeffはこのような関数だったので、callback=kとして次が実行されます。
\callback -> do
log "呼ばれたよ"
callback (Right unit)
pure nonCanceler
まずログ出力が行われ、次にcallbackが呼ばれます。
callbackの関数は次の関数でした。ということはresultはRight unitになっているということですね。
function (result) {
return function () {
if (runTick !== localRunTick) {
return;
}
runTick++;
Scheduler.enqueue(function () {
// It's possible to interrupt the fiber between enqueuing and
// resuming, so we need to check that the runTick is still
// valid.
if (runTick !== localRunTick + 1) {
return;
}
status = STEP_RESULT;
step = result;
run(runTick);
});
};
}
一応補足ですが、PureScript側からcallback (Right unit)とした場合、内側のfunctionが実行されます。なぜならばコンパイルされたjavascriptのコードはcallback(new Data_Either.Right(Data_Unit.unit))();となっているからです。
このコールバック関数の説明ですが、先に説明したSchedulerのenqueueで新しく関数をキューに追加しています。
Schedulerのところで説明した通り、drain中はキューに追加するだけで追加した関数の実行は行われません。そして今はFiberのrunの中でdrainをしてこの場にきている(=drain中)ので関数はまだ実行されません。
ちなみにこの関数が実行されたときは、statusがSTEP_RESULTになり、stepがRight unitになった上で、再度Fiberのrunが実行されることになります。
コールバック関数の実行はここで終わりなので、あとはnonCancelerを返してrunAsyncの処理も終わりです。
runAsyncの結果(nonCanceler)はstepに代入され、returnでrun(runTick)を抜けます。
このあとはどうなるでしょうか?
いま実行されていたrun(runTick)とは、drainの中で呼ばれていた(thunk=run(runTick))のでした。その中で上記の通りキューに関数が追加されているので次のループに進むことになります。
function drain() {
var thunk;
draining = true;
while (size !== 0) {
size--;
thunk = queue[ix];
queue[ix] = void 0;
ix = (ix + 1) % limit;
thunk();
}
draining = false;
}
次のループで実行されるthunk()は先程キューに追加された以下の処理です。
if (runTick !== localRunTick + 1) {
return;
}
status = STEP_RESULT;
step = result;
run(runTick);
上での記述と重複しますが、statusをSTEP_RESULTにし、stepはRight unitになり、run(runTick)が実行されます。
続いてSTEP_RESULTの処理ですが、今回の例ではbhead(後続の処理)はないのでRETURNになります。
case STEP_RESULT:
if (util.isLeft(step)) {
status = RETURN;
fail = step;
step = null;
} else if (bhead === null) {
status = RETURN;
} else {
status = STEP_BIND;
step = util.fromRight(step);
}
break;
RETURNになったあとは、他のtagで説明したようにCOMPLETED→returnと進んで処理を終えます。
以上がASYNCの処理です。
今回の遷移の様子を見てみましょう。
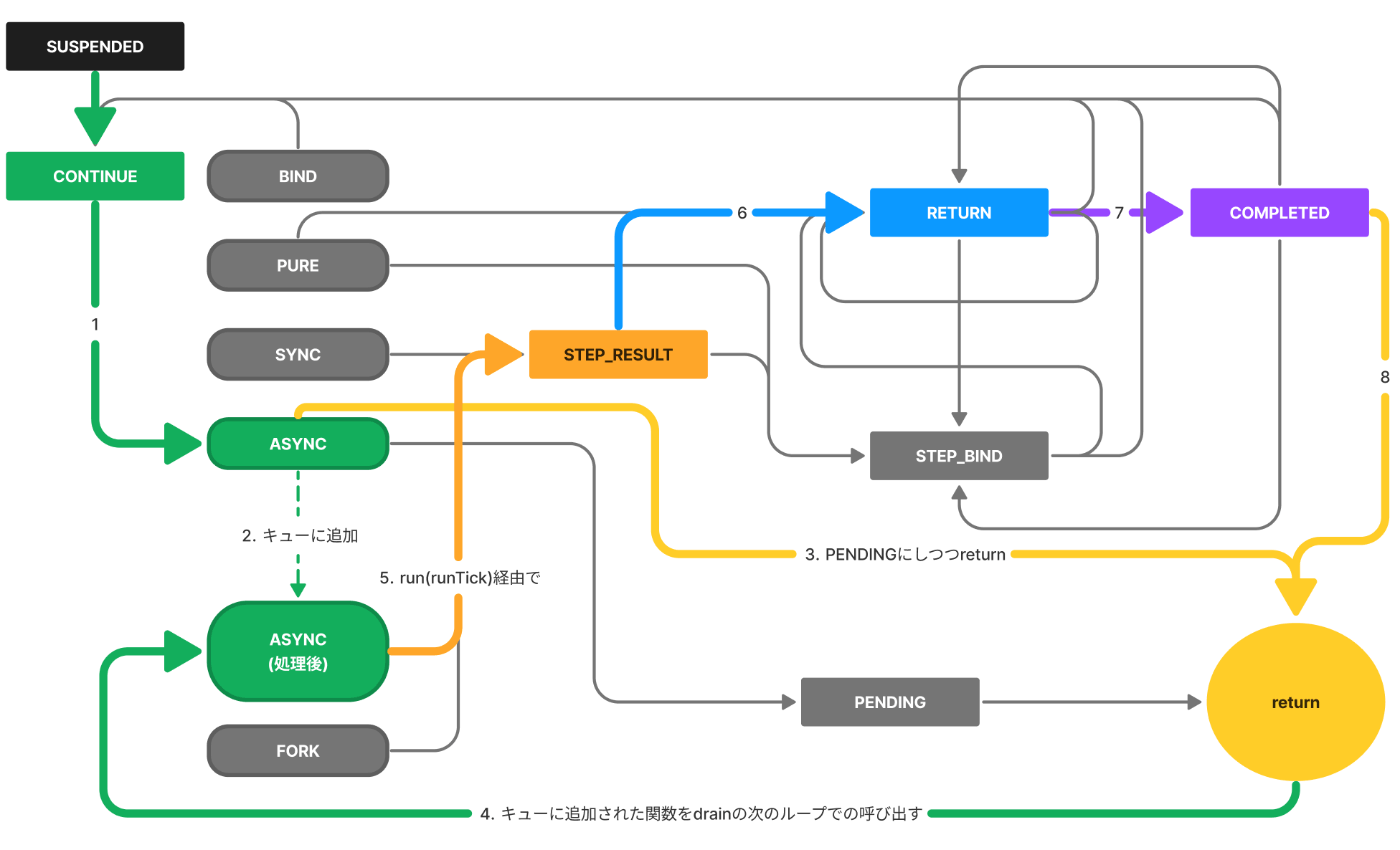
今回はASYNCの処理が「すぐに」実行を終えてキューへの追加が行われたため、同期処理のような流れになりました。
すぐに実行を終えないパターンとしては、PureScriptのAffモジュールに定義されているdelay関数を使った場合が挙げられます。
delay関数はmakeAffと同様にtagがASYNCとなるAffオブジェクトを返します。
delay関数の本体はjavascriptのsetTimeoutによる非同期処理になっており、一定時間経過後にキューへ追加する関数が呼び出されることになります。
このときdrain中でなければこのタイミングで続きの処理が実行されるでしょう。
delayを使った場合の遷移はこうなるでしょう。
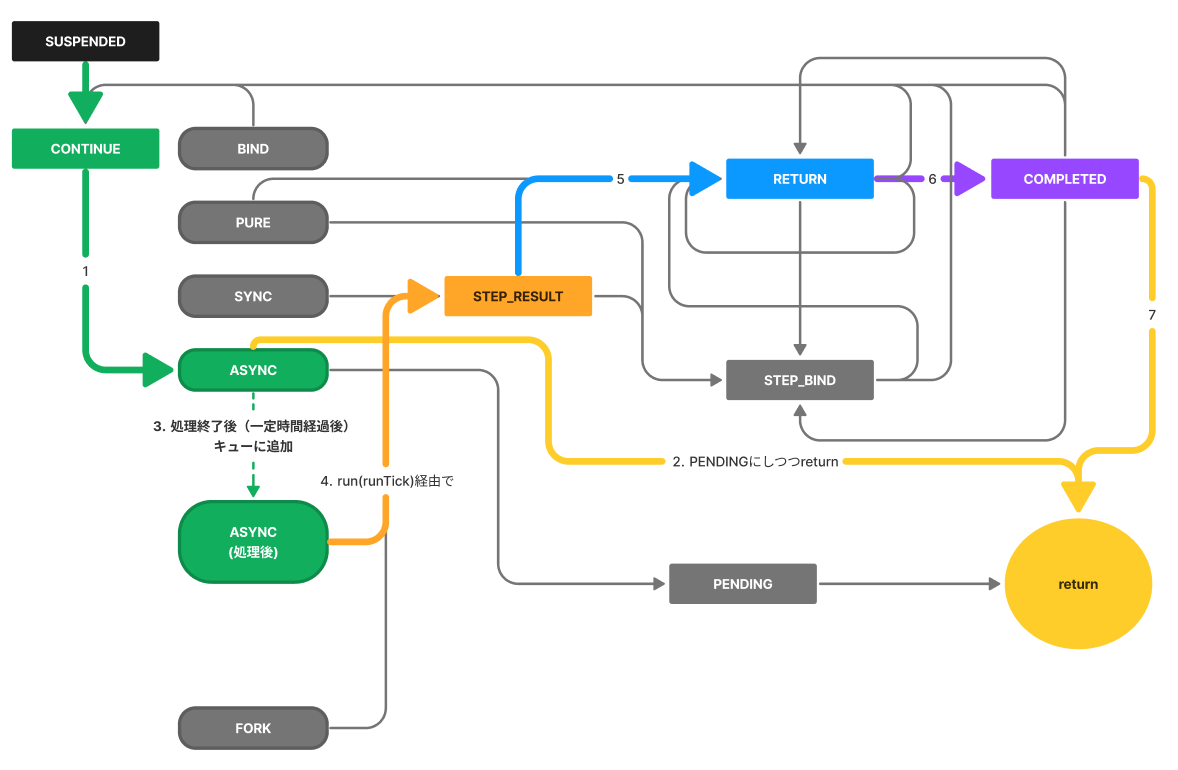
ここは重要なんです
このtagがASYNCのときの処理は、Affの協調的マルチタスクの動作において極めて重要な箇所になります。
なぜならば、実行中のタスク(Fiber)を中断して、別のタスクに処理に実行を譲る箇所が「ここ」だからです。
ここのおかげで複数の処理を切り替えながら動かせるわけなのです。
ちなみにtagがASYNCとなるAffオブジェクトを作ることができる関数はAffモジュールには今のところ次の2つしかありません。
makeAffdelay
自前で非同期処理を書くならば、makeAffを使うことになるでしょう。
実際、Ajaxでリクエストを送るときに使われるライブラリAffJaxはmakeAffを使っています。
(正確に言うとEffect.Aff.CompatモジュールのfromEffectFnAff関数を使っており、この関数がmakeAffを使っている)
FORK
次に説明するのはtagがFORKになるAffオブジェクトです。
FORKに関連するjavascriptのコードは次になります。
var FORK = "Fork";
Aff.Fork = AffCtr(FORK);
export function _fork(immediate) {
return function (aff) {
return Aff.Fork(immediate, aff);
};
}
PureScript側のコードはこうです。
forkAffとsuspendAffの二つがありますが、今回はforkAffだけを見ていきます。
forkAff :: forall a. Aff a -> Aff (Fiber a)
forkAff = _fork true
suspendAff :: forall a. Aff a -> Aff (Fiber a)
suspendAff = _fork false
foreign import _fork :: forall a. Boolean -> Aff a -> Aff (Fiber a)
PureScriptでforkAffを使うと次のようなAffオブジェクトが作られます。
Aff(FORK, true, 何かしらのAFF)
どう処理されるか
これがstatusがFORKの場合の処理です。
Fiberを作っていますね。Fiberで扱う関数step._2はforkAffに渡した関数になります。
またstep._1はtrueだったので、すぐrunが呼ばれることになります。
case FORK:
status = STEP_RESULT;
tmp = Fiber(util, supervisor, step._2);
if (supervisor) {
supervisor.register(tmp);
}
if (step._1) {
tmp.run();
}
step = util.right(tmp);
break;
runの処理が終わったら、ここで作ったFiberを(Rightに包んで)次のstepとし、statusをSTEP_RESULTにして先に進みます。
ここ以降はこれまで説明してきたのと同じで、RETURN→COMPLETED→returnと流れていきます。
(Fiberのrunの中でも処理が行われていますが、流れは同じです)
ここまで見てきて
以上がイベントループの説明となります。
どのようなときにタスクの中断と切り替えが行われるのかご理解いただけたかと思います。
タイマー割り込みとコンテキストスイッチを利用したプリエンプティブな方式では、コードの一行一行ごとにタスクが切り替わる可能性がありますが、比較するとPureScriptのAffの場合は切り替えが行われるタイミングが決まっており表現が正しいかわかりませんがカチッとした印象を受けます。
マルチタスクっていっても結局シングルスレッドなんじゃないか?
JavaScriptはシングルスレッドで動作しているので、その通りです。
そしてここまで説明してきたFiberの動作は、あるスレッド上で動いている「ある単位」の処理を中断して別の処理の実行が開始されるというものであり、結局は同じスレッド上で動作するものでした。
つまりシングルスレッド上でマルチタスクが動作しているということになります。
並列処理ではなく並行処理をしているということですね。
JavaScriptでマルチスレッドで処理を行うならばWebWorkerもしくはそのラッパーライブラリを使うことになるかと思いますが、PureScriptにもWebWorkerを利用するためのライブラリがあるので、PureScriptの場合はこちらを使うとよいかもしれません。
joinしたとき何がおきるか
以上で終わらせてもよかったのですが、FiberをjoinFiberでjoinしたときの動きも興味深いので書いておきましょう。
次の例をもって説明します。
forkAffで、"result"という返すFiberを作り、joinFiberでjoinし受け取った結果をログ出力するだけの簡単な例です。
example :: Effect Unit
example = launchAff_ do
fiber <- forkAff do
pure "result"
result <- joinFiber fiber
log result
どう処理されるか
まずFORKのところで説明したようにforkAffはFiberを作ってrunします。
fiber <- forkAff do
pure "result"
したがって上記が実行された場合次の状態になります。
-
forkAffで作ったFiberの状態-
status=COMPLETED -
step=Right "result"
-
-
launchAff_で作られた処理の大元のFiberの状態-
status=STEP_RESULT -
step="Right forkAffで作ったFiber`
-
次は、大元のFiberの処理の続きなのですが、joinFiberするという後続の処理があるのでSTEP_RESULTの次はSTEP_BINDになって、後続の処理(joinFiber result)が呼ばれます。
続いてjoinFiberの説明にいきましょう。
joinFiberの定義はこうなっています。
joinFiber :: Fiber ~> Aff
joinFiber (Fiber t) = makeAff \k -> effectCanceler <$> t.join k
したがってSTEP_BINDのbheadの結果、今回作られるのは次のようなAffオブジェクトです(後続の処理があるのでBIND)。
Aff(
BIND,
Aff(ASYNC, \k -> effectCanceler <$> t.join k),
後続の処理(ログ出力)
なので、次はAFF(ASYNC,...)が処理されます。
ASYNCの処理では、コールバック関数をkとして\k -> effectCanceler <$> t.join kが実行されますね(このコールバック関数は、処理結果を受け取り残りの処理をする関数をキューに追加するという関数でした)。
なのでここでjoinFiberが呼び出されます。
ということでjoinFiberの説明に戻ります。
実行されたときコールバック関数(今回だと上記のk)をt.joinに渡していますね。
このjoinを見てみましょう。
function join(cb) {
return function () {
var canceler = onComplete({
rethrow: false,
handler: cb
})();
if (status === SUSPENDED) {
run(runTick);
}
return canceler;
};
}
onComplete関数を実行して、statusがSUSPENDならrun(runTick)を呼び出します。
onCompleteはこんな関数です。
function onComplete(join) {
return function () {
if (status === COMPLETED) {
rethrow = rethrow && join.rethrow;
join.handler(step)();
return function () {};
}
var jid = joinId++;
joins = joins || {};
joins[jid] = join;
return function() {
if (joins !== null) {
delete joins[jid];
}
};
};
}
Fiberの処理が完了していた場合
statusがCOMPLETEDすなわちjoinFiberを呼んだタイミングでFiberの処理が終わっていた場合は、join.handlerに設定されていたコールバック関数が呼ばれ、空の関数が返ります。
返される関数はいわゆるCancelerでキャンセル処理が行われたときに呼ばれる関数です。
ここで処理を終わらせるならもうキャンセルの必要はないので空の関数を返しているわけです。
続けましょう。
コールバック関数の定義はこうでしたね。
function (result) {
return function () {
if (runTick !== localRunTick) {
return;
}
runTick++;
Scheduler.enqueue(function () {
// It's possible to interrupt the fiber between enqueuing and
// resuming, so we need to check that the runTick is still
// valid.
if (runTick !== localRunTick + 1) {
return;
}
status = STEP_RESULT;
step = result;
run(runTick);
});
};
}
}
resultはFiberの処理結果なので、これを次のstepとして、statusをSTEP_RESULTにし、run(runTick)を呼んでイベントループに進むということです。
しかしいまはdrain中なのでこの処理はキューに追加されるだけで終わります。
onCompleteの処理が終わったのでjoinは空のCancelerを返して終わります。
effectCanceler <$> t.join kとなっていましたが、これは単にこのCancelerをPureScript側でCanceler型として扱えるようにしているだけです(今回の説明とはあまり関係ない)。
effectCanceler :: Effect Unit -> Canceler
effectCanceler = Canceler <<< const <<< liftEffect
newtype Canceler = Canceler (Error -> Aff Unit)
この処理が終わったあとは、drainの次のループに行き、上でキューに追加していたコールバック関数が実行されることになります。
元々はBINDとして動いていたので、あとは後続の処理(ログ出力)が呼ばれて終わりです。
Fiberの処理が未完だった場合
forkAffの処理が次のようになっていたとします。
example :: Effect Unit
example = launchAff_ do
fiber <- forkAff do
delay $ Milliseconds 1000.0
pure "result"
result <- joinFiber fiber
log result
delayによって遅延されるので、Fiberの処理はまず終わっていない状態になるでしょう。
この場合、onCompleteのこちらのコードが実行されます。
joinsにコールバック関数が追加され、Cancelerが返されます。
こちらのCancelerは呼び出されたらjoinsから追加したコールバック関数を削除します。
var jid = joinId++;
joins = joins || {};
joins[jid] = join;
return function() {
if (joins !== null) {
delete joins[jid];
}
};
joinFiberとしてはここで処理を抜けていくのですが、ではjoinsに追加されたコールバック関数はいつ呼ばれるのでしょうか?
実は既に説明したところにその処理があります。
そこはCOMPLETEDの処理です。
説明しましょう。
今回の場合、delayの処理で一定時間が経過したあとコールバック関数が呼ばれるわけですが、この関数が呼ばれていくと処理が先に進み、今回の場合はPUREの処理が行われて最終的にstatusがCOMPLETEDになるわけです。
COMPLETEDの処理は既にお見せしましたが、joinsの処理は説明を先延ばししていたのでした。
case COMPLETED:
for (var k in joins) {
if (joins.hasOwnProperty(k)) {
rethrow = rethrow && joins[k].rethrow;
runEff(joins[k].handler(step));
}
}
joins = null;
if (interrupt && fail) {
// 省略
} else if (util.isLeft(step) && rethrow) {
// 省略
}
return;
見るとここでjoinsに追加されているすべてのコールバック関数が実行されることがわかります。
今回の場合ログ出力が行われるわけですね。
この処理の流れから、joinFiberにより処理がブロックされる理由・仕組みがご理解いただけたのではないかと思います。
おまけ:いかなるときにキューの中身は複数になるのか
多くの場合、キューに追加される関数は複数個になる前に処理されて無くなります。
では、どういう場合に複数個になるのか気になったので調べてみました。
例えば次のようにしたとき、キューの内容の関数が複数になります。
main :: Effect Unit
main = do
launchAff_ do
a <- forkAff do
delay $ Milliseconds 100.0
pure "a"
a1 <- joinFiber a
log $ "bar:" <> a1
a2 <- joinFiber a
log $ "baz:" <> a2
pure unit
更に次のようにした場合、キューは複数個の関数を持ち、forkAffしたFiberの中のjoinsも複数の関数を持つことになります。
main :: Effect Unit
main = do
launchAff_ do
a <- forkAff do
delay $ Milliseconds 100.0
pure "a"
_ <- forkAff do
a' <- joinFiber a
log $ "bar:" <> a'
_ <- forkAff do
a' <- joinFiber a
log $ "baz:" <> a'
pure unit
理解の確認
ここまでの内容が理解できたか確認するために、Javaで書いたコード例と同じような動作を期待するPureScriptのコードを書き、それが期待通り動かないことと、期待通り動かすにはどうしたらよいかを見ていきます。
Javaの例のあとに示すPureScriptのコードがなぜ期待通り動かないのか想像してみてください。
では、まずJavaで次のようなコードがあるとします。
並列でログ出力するだけの単純なコードです。
import java.util.stream.IntStream;
import java.util.List;
import java.util.stream.Collectors;
public class Example {
public static void main(String[] args) {
createThreads().forEach(thread -> {
thread.start();
});
}
private static List<Thread> createThreads() {
return IntStream.rangeClosed(1, 5)
.boxed()
.map(String::valueOf)
.map(name -> {
return new Thread(() -> {
System.out.println("Start:" + name);
System.out.println("End:" + name);
});
})
.collect(Collectors.toList());
}
}
出力結果はタイミングによりますが次のようになります。
Start:2
Start:1
End:1
Start:5
End:5
Start:4
Start:3
End:3
End:2
End:4
同じような処理をPureScriptで書く場合、どのように書けばよいでしょうか。
Javaと同じノリで次のように書けばいいでしょうか。
main :: Effect Unit
main = launchAff_ do
parSequence_ tasks
-- ログ出力するだけのAffを5個作るだけ
tasks :: Array (Aff Unit)
tasks = range 1 5 <#> \i -> do
log $ "Start:" <> show i
log $ "End:" <> show i
このコードを実行したときの結果はどうなるかというと、このようになってしまいます。
Start:1
End:1
Start:2
End:2
Start:3
End:3
Start:4
End:4
Start:5
End:5
なぜこのようになるのでしょうか?
・
・
・
・
・
・
はい。
単にAffを作っただけではタスクは切り替わらないからですね。
makeAffかdelayを使わねばなりません。
具体的には2つのログ出力の間にdelay関数を入れてやるか、次のようにmakeAffの中でログ出力を行うラッパー関数を用意してやります(こんなことやらんでしょうけど)。
main :: Effect Unit
main = launchAff_ do
parSequence_ tasks
tasks :: Array (Aff Unit)
tasks = range 1 5 <#> \i -> do
affLog $ "Start:" <> show i
affLog $ "End:" <> show i
affLog :: String -> Aff Unit
affLog s = makeAff \callback -> do
log s
callback (Right unit)
pure nonCanceler
すると結果はこのように変わります。
Start:1
Start:2
Start:3
Start:4
Start:5
End:1
End:2
End:3
End:4
End:5
ただし、Javaの例のように実行する度に結果が変わることはありません。
そもそもJavaはプリエンプティブな方式ですしね。
あとがき
私がAffのJavaScript側のコードを初めて見たのは、PureScriptが出力したJavaScriptのコードをデバッグしていたときでした。
ステップ実行していったときAffのイベントループ内に出てしまって、「なんでループしてるんだ???」とギョッとしたものです。
それからしばらく経った頃、Affについての理解が浅いなー、と思って使い方を調べているうちに実装自体に興味がわいて奥深くまで入り込んでいくことになって、上記のイベントループに再会したときは感慨深いものがありました。
色々わかったあとはモヤモヤしたものが晴れ、スカッとした気分になったのですが、みなさんはいかがでしたでしょうか?
大昔に自作OSを作ったときマルチタスクとマルチスレッドを実装したことがあるのですが、当然プリエンプティブなやつだったので、今回ノンプリエンプティブという別の方式を実際のコードを例に知ることができ、その結果両者を比較したときの解像度が上がりました。
そうそう、Aff.jsのコードを読んだり動かしたりしながら調査しているとき、「色々なことができるように複雑になっているけど、最低限の機能になるまで削ぎ落としたらシンプルになって理解しやすくなるのでは?」と思い、例外処理とかキャンセル処理とかの機能を落とした版のAffを作ってみたりしました。
このアプローチをとってみて次のよかったことがありました。
- 余計なところが目に入らなくなり、知りたいところに集中できる
- 動作を理解せずに機能を削るのは不可能※なので、嫌でも理解度が上がる。
- 上記を行うことで副次的に(これはこういう仕組みだったのかということを)学べることもある。
※引数を減らしたりするとPureScript側にも影響してコンパイルエラーになったり、コンパイルエラーにならなくても無限ループになってしまったりした。これを解消することで学ぶこともできた。
一方で、時間は余計に掛かりましたね。
一から写経するなどして自分で書いてみるのが一番理解できる(私はフリーモナドとか拡張可能作用とかは全部写経した)のですが、もっと時間が掛かるので、(うまく機能を削れる版を作れるなら)こういったアプローチは折衷案として良いかもしれないと思います。
ということで今回の記事を終わりにしたいと思います。
何か得られるものがありましたら幸いです。それでは。
Discussion
Aff の実装一回見たとき何してるのか分からなくて結局今まで読んでなかったんですが、この記事でだいたいの仕組みが分かりました
ありがとうございます!
kill とかエラー処理周りの流れも追ってみます
ありがとうございます!
お役に立てたなら何よりです。