



Salesforce のデータを Cloud Storage に連携するバッチ処理を作ったので、その備忘録的記事です。
構成
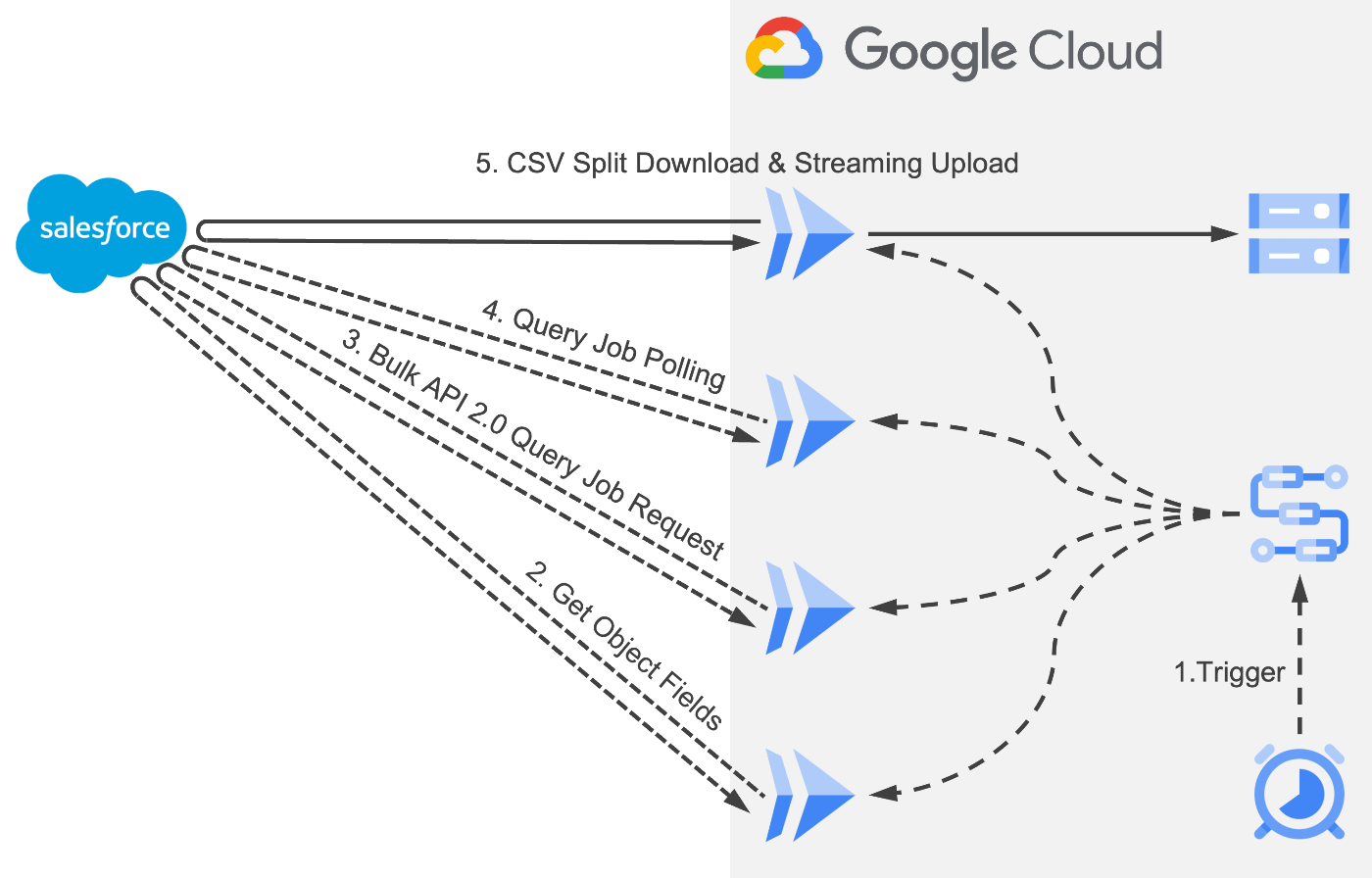
処理一覧
- Cloud Scheduler をトリガーに Workflows を実行
- 取得対象オブジェクト項目名を取得
- 上記 2 で取得した項目名を元に SOQL を生成し Bulk API 2.0 のクエリジョブを作成
- クエリジョブのステータスをポーリング
- クエリジョブ結果を取得し Cloud Storage にストリーミングアップロード
Cloud Run で実行される処理は Python で実装してます。
2〜4 は Cloud Run Service を利用した API で 5 は Cloud Run Jobs を利用しています。
Cloud Storage へのアップロードはストリーミング形式です。
実装
Salesforce データ取得 & Cloud Storage アップロードする処理
Cloud Run で実行する処理です。
Flask のルーティングされた関数から呼び出されます。
Salesforce に対する処理は requests ライブラリと SalesForce Bulk API 2.0
Cloud Storage への処理は google.cloud ライブラリを使用しています。
import io
import os
import json
import requests
from google.cloud import storage
from datetime import datetime
API_VER = 'v59.0'
BASE_URL = 'https://Domain.my.salesforce.com'
TOKEN_URL = f'{BASE_URL}/services/oauth2/token'
API_BASE_URL = f'{BASE_URL}/services/data/{API_VER}'
EXCLUDE_LIST = ['address']
class SalesforceAPI:
def __init__(self, client_id, client_secret):
self.headers = self.get_access_token(client_id, client_secret)
@staticmethod
def get_access_token(client_id: str, client_secret: str) -> dict:
# アクセストークンを取得
payload = {
'grant_type': 'client_credentials',
'client_id': client_id,
'client_secret': client_secret
}
response = requests.post(TOKEN_URL, data=payload)
response.raise_for_status()
tokens = response.json()
return {
'Authorization': f'{tokens.get("token_type")} {tokens.get("access_token")}',
'Content-Type': 'application/json'
}
def get_fields(self, object_name: str) -> list:
# Salesforce オブジェクトの項目名を取得
describe_url = f'{API_BASE_URL}/sobjects/{object_name}/describe'
response = requests.get(describe_url, headers=self.headers)
response.raise_for_status()
describe_data = response.json()
field_names = [[field['name'], field['type']] for field in describe_data['fields']]
fields = []
for column, data_type in field_names:
# Bulk APIは複合項目へのアクセスができないため除外
if data_type not in EXCLUDE_LIST:
fields.append(column)
return fields
def create_bulk_query_job(self, object_name: str, field_names: list) -> str:
# クエリジョブ作成し クエリジョブIDを取得
query = f"SELECT {', '.join(field_names)} FROM {object_name}"
job_data = {
'operation': 'query',
'query': query,
}
job_create_url = f'{API_BASE_URL}/jobs/query'
response = requests.post(job_create_url, headers=self.headers, data=json.dumps(job_data))
response.raise_for_status()
job_info = response.json()
return job_info['id']
def get_job_status(self, job_id: str) -> str:
# クエリジョブの処理状況を取得
job_status_url = f'{API_BASE_URL}/jobs/query/{job_id}'
response = requests.get(job_status_url, headers=self.headers)
response.raise_for_status()
return response.json()['state']
def export(self, job_id: str, bucket_name: str, blob_name: str):
# Salesforce オブジェクトのデータを取得し Cloud Storage にストリーミングアップデート
bucket = storage.Client().get_bucket(bucket_name)
count = 0
locator = ''
try:
while locator is not None:
locator_uri = f'locator={locator}&' if count else ''
results_url = f'{API_BASE_URL}/jobs/query/{job_id}/results?{locator_uri}'
response = requests.get(results_url, headers=self.headers)
records = int(response.headers.get('Sforce-NumberOfRecords', 0))
count += records
obj = io.BytesIO(response.content)
blob = bucket.blob(blob_name)
blob.upload_from_file(obj, content_type='text/csv')
locator = response.headers.get('Sforce-Locator', '')
locator = None if locator == 'null' else locator
except Exception as e:
raise e
API の バージョンや URL の ドメインは各自のものに置き換えてご利用ください。
Bulk API は複合項目のエクスポートに対応していないため、エクスポート対象から除外しています。
API エンドポイント
API エンドポイントは簡単ですが以下の感じです。
Salesforce オブジェクトから項目名を取得・返却する API の例です。
以下のように API から呼び出せるようにすると Cloud Workflows で自動化しやすいですね。
import os
from salesforce import SalesforceAPI
from flask import Flask, request, jsonify, abort
app = Flask(__name__)
salesforce_api = SalesforceAPI()
@app.route('/get_fields', methods=['GET'])
def get_fields():
# Salesforce オブジェクトの項目名を取得
try:
# クエリパラメータからobject_nameを取得
object_name = request.args.get('object_name')
if not object_name:
return jsonify({'error': 'object_name is required'}), 400
# Salesforceの項目名を取得する処理
fields = salesforce_api.get_fields(object_name)
# 結果をJSON形式で返す
return jsonify({'fields': fields})
except Exception as e:
abort(500, description=str(e))
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=int(os.environ.get('PORT', 8080)))
ワークフローの定義
ジョブをポーリングする処理 (jobPolling) とデータ取得・アップロードする処理 (exportJob) は
サブワークフローで実装しています。
main:
params: [args]
steps:
- init:
assign:
- project_id: ${sys.get_env("GOOGLE_CLOUD_PROJECT_ID")}
- job_location: [利用するリージョン]
- object_name: ${args.object_name}
- bucket_name: [Cloud Storage のバケット名]
- getFields:
call: http.get
args:
url: ${"https://[Cloud Run の URL]/get_fields?object_name=" + object_name}
auth:
type: OIDC
result: fields_json
- bulkQuery:
call: http.post
args:
url: https://[Cloud Run の URL]/bulk_query
body:
fields: ${fields_json.body.fields}
object_name: ${object_name}
auth:
type: OIDC
result: job_id_json
- polling:
call: jobPolling
args:
job_id: ${job_id_json.body.job_id}
result: status
- check:
switch:
- condition: ${status != "JobComplete"}
next: finally
next: export
- export:
call: exportJob
args:
project_id: ${project_id}
job_location: ${job_location}
job_id: ${job_id_json.body.job_id}
object_name: ${object_name}
bucket_name: ${bucket_name}
result: status
jobPolling:
params: [job_id]
steps:
- bulkQueryJobPolling:
call: http.get
args:
url: ${"https://[Cloud Run の URL]/get_status?job_id=" + job_id}
auth:
type: OIDC
result: job_status
- checkStatus:
switch:
- condition: ${job_status.body.status in ["UploadComplete", "InProgress"]}
next: wait
next: returnStatus
- wait:
call: sys.sleep
args:
seconds: 60
next: bulkQueryJobPolling
- returnStatus:
return: ${job_status.body.status}
exportJob:
params: [project_id, job_location, job_id, object_name, bucket_name]
steps:
- salesforceToStorage:
call: googleapis.run.v1.namespaces.jobs.run
args:
name: ${"namespaces/" + project_id + "/jobs/" + "bi-sf2bq-export"}
location: ${job_location}
body:
overrides:
containerOverrides:
args:
- --job_id
- ${job_id}
- --object_name
- ${object_name}
- --bucket_name
- ${bucket_name}
result: job_status
Workflows の引数は Salesforce オブジェクト名(object_name)のみです。
引数は Cloud Scheduler から渡します。

Cloud Run へのデプロイ
この記事ではお話ししませんが、デプロイに関する記事を書いたのでこちらを参照ください。
動作確認
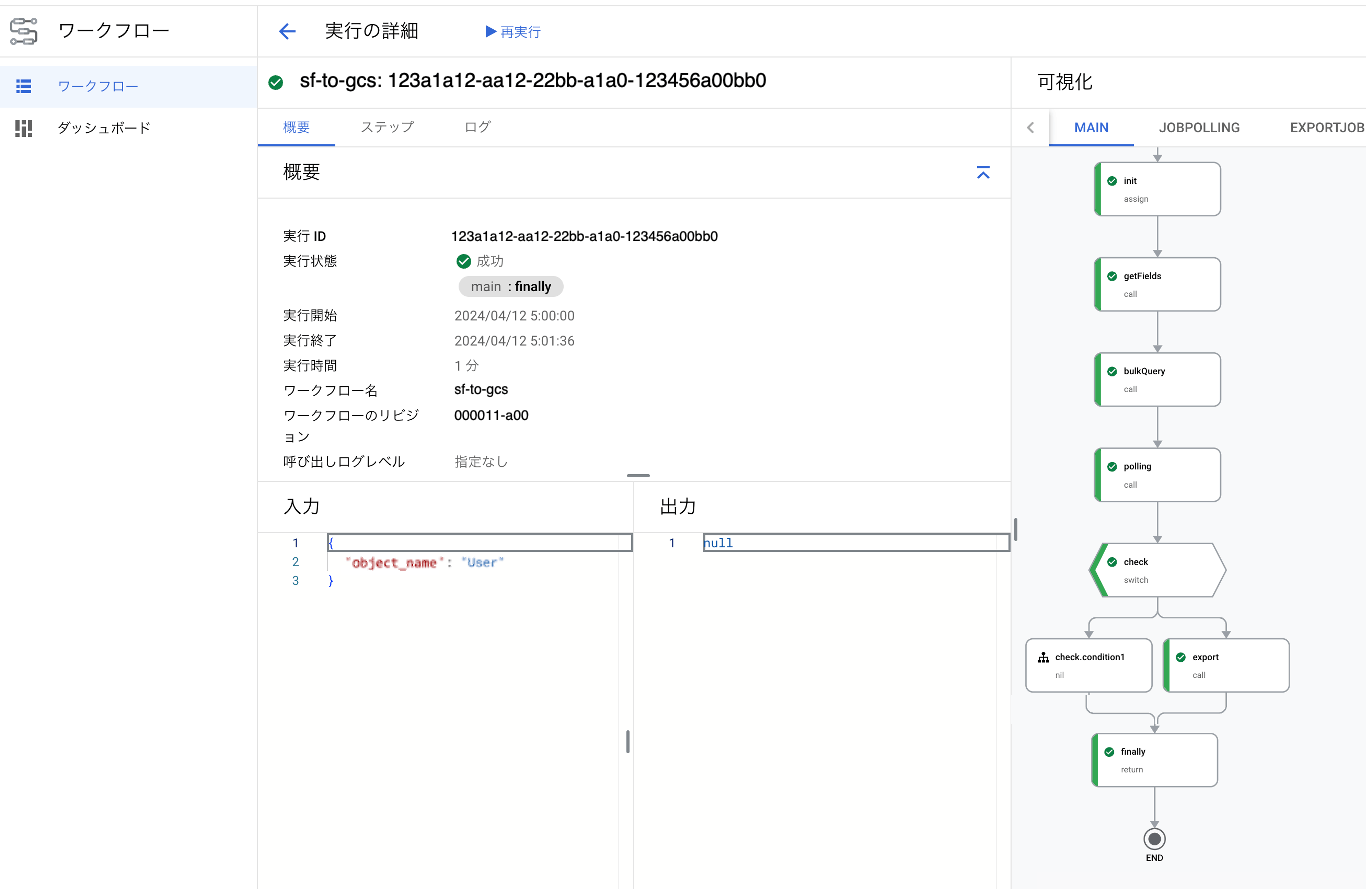
Cloud Scheduler から引数を渡してスケジュール実行してみました。
ちゃんと引数が渡されていますね。(ファイルもちゃんと Cloud Storage にアップロードされていました)
まとめ
Salesforce のデータをデータ基盤に連携したいケースはたくさんあるかと思います。
有料のサービスもいくつかありますが、スモールスタートでデータ基盤を立ち上げる場合など、できるだけコストを抑えて連携したいという時に参考にしていただけると幸いです。

Discussion