ざっくりつかむ!LangChainのメンタルモデル
はじめに
昨今の激アツChatGPTブームを見ると、これをアプリとして開発してみたいと思う方も多いのではないでしょうか。気になって調べてみるとLangChainやLlamaIndexというライブラリに行き着く方も多いはずです。
そしてすぐ壁に直面すると思います。
結局これらのライブラリが
- 何で
- どういう時に
- どう使えば良いのか
わからない!
そうです。私です。
特にLangChainは初めてLLMアプリ開発される方には少し難解です。LangChainは非常に積極的な開発がされているライブラリで、課題や良い方法が発見されればそれをすぐ実装!というスピード感で動いています。
その分、ドキュメントこそ整備されているものの膨大な情報量に迷子になりやすい状況です。
そこで、今回はLangChainのメンタルモデルを簡単に説明してみることにしました。
全体感が抑えられていればコアな情報、追加で必要となる機能などの分別もつきやすくなるはずです。ReactはUI=f(state)の考えを抑えるとスッと頭に入ってきます。
また、実際に動かせるようTypeScriptのサンプルコードも用意しています。これを読まれる方はフロントエンド経験ある方が多いかなぁと思いTypeScriptにしました。
記事を読み終わったらNext.js API Routesなどに突っ込んでLLMアプリを作ってみてください。結構お手軽なのにやれることが多くて楽しいですよ!
前提知識
LangChainの説明をする上で少なからずLLM(大規模言語モデル)の知識が必要となります。といっても、組み込みだけであれば内部の仕組みを詳しく知る必要はありません。
大事なのことはLLMがText to Text、つまり文章が入力されて新たな文章が出力される関数であるということです。
TypeScript的に考えると以下のようになります。

Pythonは同期処理メインなことが多いのですが、今回はTypeScriptでAPIコールしますのでPromise<string>が正確ですね。
stringが入れたらstringが出てくる…!とてもシンプルです。
LangChainの構成要素
さっそくLangChainを掴んでいきましょう。
全体像は以下のようになっています。

Models, Prompts, Chains, Agents, Memory, Indexesの6つですね。
先ほどお伝えしたように、それぞれの機能に開発された理由とモチベーションが存在します。
最小の構成要素、まずModelsから始め徐々に理由とその機能を抑えていきましょう。
サンプルコードは以下のリポジトリにあります。
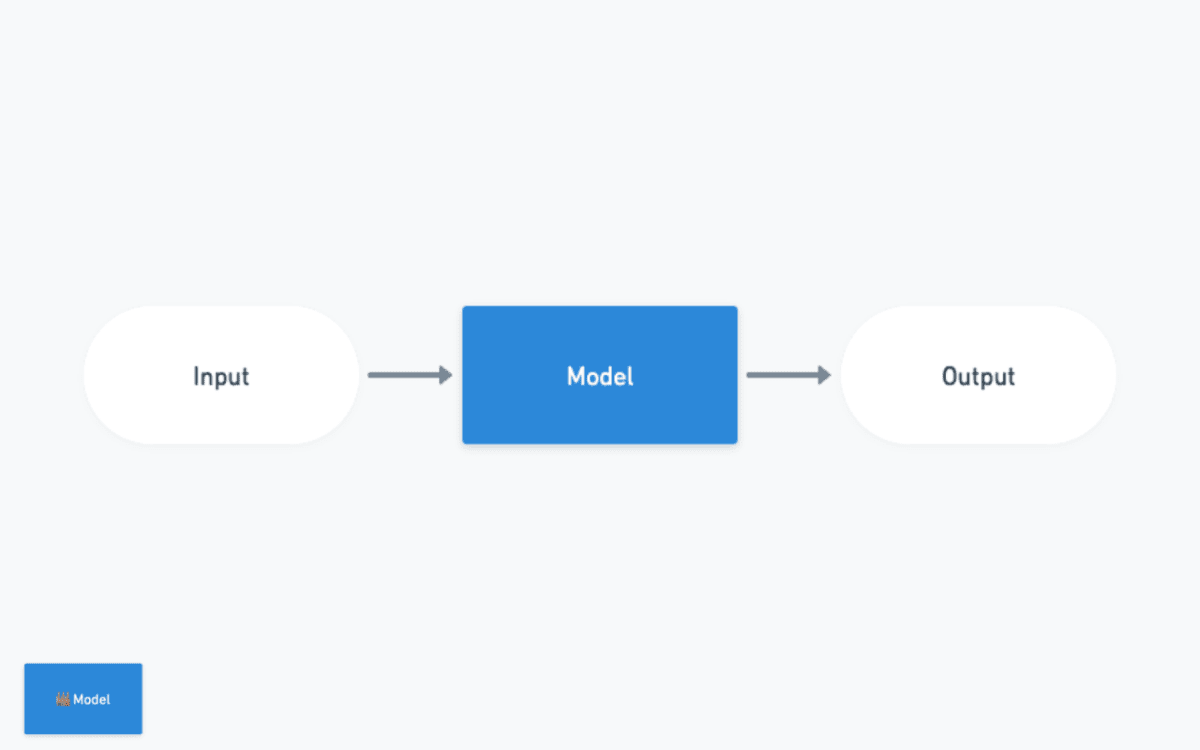
Models
モチベーション:LLMを簡単に動かしたい
なにはともかくまず動かしたいです。その際にはModelsを利用しましょう。
// src/01_model.ts
import { OpenAI } from "langchain/llms/openai";
require("dotenv").config();
export const run = async () => {
const model = new OpenAI();
const res = await model.call(
"カラフルな靴下を作る会社の良い名前を考えてください。"
);
console.log(res);
};
run();
modelを定義してstringを入れてcallする!すごいシンプルです。これだけでもLLMを動かすことができます。(尚、別途.envにAPIキーを設定してください)
ModelsはさまざまなLLM系APIの最小のWrapperです。OpenAI APIが最も有名かと思いますが、HuggingFaceやClaudeなどの他のサービスと連携することもできます。
Prompts - Prompt Template
モチベーション:LLMへの入力を効率的に取り回したい
ChatGPTを利用していると複数回同じような入力をするケースがあると思います。翻訳などは特に
プロの翻訳家のように振る舞ってください。
できるだけ原文のニュアンスを保持しつつ{targetLanguage}に翻訳してください。
というように、プレースホルダを用いて効率的に扱いたいですよね。
この効率的なプロンプトの運用、また後述するChainsと連携するために存在する機能となります。
// src/02_prompt_template01.ts
import { PromptTemplate } from "langchain/prompts";
require("dotenv").config();
export const run = async () => {
const prompt = new PromptTemplate({
inputVariables: ["product"],
template: "カラフルな{product}を作る会社の良い名前を考えてください。",
});
console.log(await prompt.format({ product: "靴下" }));
};
run();
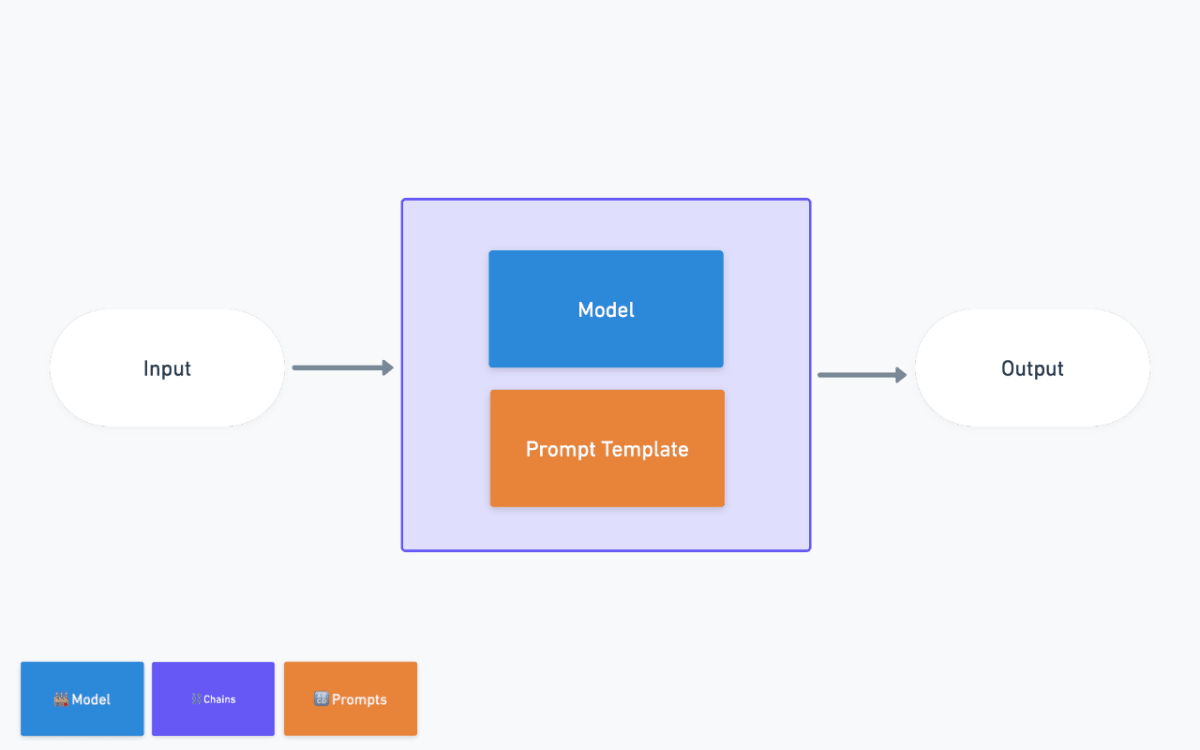
Chains - LLMChain
モチベーション:LLMの入力を便利に、汎用性を持たせたい
上記のModelとPrompt TemplateをさらにWrapし以下のように扱います。
// src/03_chains01_llmchain.ts
import { OpenAI } from "langchain/llms/openai";
import { PromptTemplate } from "langchain/prompts";
import { LLMChain } from "langchain/chains";
require("dotenv").config();
export const run = async () => {
const prompt = new PromptTemplate({
inputVariables: ["product"],
template: "カラフルな{product}を作る会社の良い名前を考えてください。",
});
const model = new OpenAI();
const chain = new LLMChain({ llm: model, prompt });
const res = await chain.call({ product: "靴下" });
console.log(res);
};
run();
LLMChainというclassを呼び出しpromptとmodelを渡せばOKです。
前回までPromptTemplateは毎回文字列にする必要がありました。LLMChainを利用すると定義した引数がLLMへの引数になるため、より効率的に扱うことができます。
ここからLangChainが力を発揮します。このChainという単位でLangChainはさまざまに便利な機能を提供します。
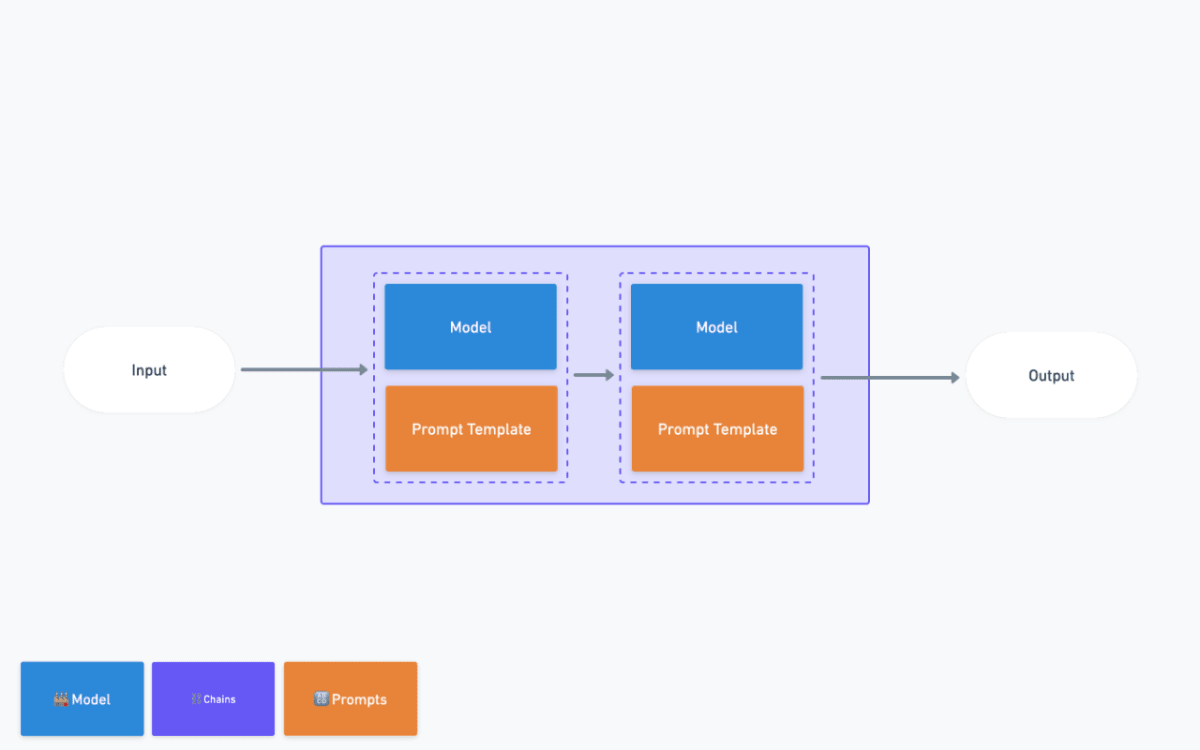
Chains - Simple Sequential Chain
モチベーション:LLMを用いた入出力の変換を連続で行いたい
ChatGPTを用いて文章の変換をおこなっていると、翻訳→要約というように作業を連鎖的に行いたいケースがあると思います。その際に使われるのがSequential Chainです。
先ほどあげたLLMChainを複数個、さらに一段階ラップすることによって使用します。
// src/03_chains02_sequentialchain.ts
import { OpenAI } from "langchain/llms/openai";
import { PromptTemplate } from "langchain/prompts";
import { LLMChain, SimpleSequentialChain } from "langchain/chains";
require("dotenv").config();
export const run = async () => {
//1つ目のChain
const outlinePromptTemplate = new PromptTemplate({
inputVariables: ["title"],
template: `あなたは脚本家です。劇のタイトルが与えられたら、そのタイトルの概要を書くのがあなたの仕事です。
タイトル: {title}
概要:`,
});
const outlineModel = new OpenAI();
const outlineChain = new LLMChain({
llm: outlineModel,
prompt: outlinePromptTemplate,
});
//2つ目のChain
const reviewPromptTemplate = new PromptTemplate({
inputVariables: ["outline"],
template: `あなたはニューヨーク・タイムズの批評家です。劇のあらすじを聞いて、その劇の批評を書くのがあなたの仕事です。
劇の概要: {outline}
批評:`,
});
const reviewModel = new OpenAI();
const reviewChain = new LLMChain({
llm: reviewModel,
prompt: reviewPromptTemplate,
});
const overallChain = new SimpleSequentialChain({
chains: [outlineChain, reviewChain],
verbose: true,
});
const review = await overallChain.run("夕暮れ時のビーチで起こる悲劇");
console.log(review);
};
run();
上記は「劇作家が概要を書き」次段で「批評家が批評を作る」というSequentialChainとなります。(公式exampleより引用)
SimpleSequentialChainをインスタンス化する際に、実行したい順序にLLMChainを渡しましょう。
この際、複数のインプット/アウトプットが欲しいというケースがあるでしょう。その際はSequentialChainを利用すると実現が可能となります。
Memory
モチベーション:文脈を維持したままやり取りを行いたい
これまではstring→(LLM)→stringといった形でLangChainを扱ってきました。しかし、これは状態が保持されておらずChatGPTのような"以前のやり取りを反映した出力”ができません。これを解決するのがMemoryです。
以下のように専用のChainを用意しmodelと記憶領域であるmemoryを与えます。

// src/04_memory01.ts
import { OpenAI } from "langchain/llms/openai";
import { BufferMemory } from "langchain/memory";
import { ConversationChain } from "langchain/chains";
require("dotenv").config();
export const run = async () => {
const model = new OpenAI({});
const memory = new BufferMemory();
const chain = new ConversationChain({ llm: model, memory: memory });
const res1 = await chain.call({ input: "こんにちは! サガワです。" });
console.log({ res1 });
const res2 = await chain.call({ input: "私の名前はなんですか?" });
console.log({ res2 });
};
run();
上記を実行すると、2回目のリクエスト時に1回目のやりとりが反映されていることが確認できます。
コンソールで実行できるサンプルも用意したため試してみてください。
// src/04_memory02_chatdemo.ts
import { OpenAI } from "langchain/llms/openai";
import { BufferMemory } from "langchain/memory";
import { ConversationChain } from "langchain/chains";
import readline from "readline";
require("dotenv").config();
//会話記録保持のため関数の外出し
const model = new OpenAI({});
const memory = new BufferMemory();
const chain = new ConversationChain({ llm: model, memory: memory });
const run = async (input: string) => {
const res = await chain.call({ input: input });
console.log({ res });
};
//標準入出力の定義
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout,
});
//入力の待機関数の定義
const waitForUserInput = () => {
rl.question("あなたの入力を待っています: ", (input) => {
run(input).then(() => waitForUserInput()); //再帰的に呼び出し
});
};
//会話の開始
waitForUserInput();
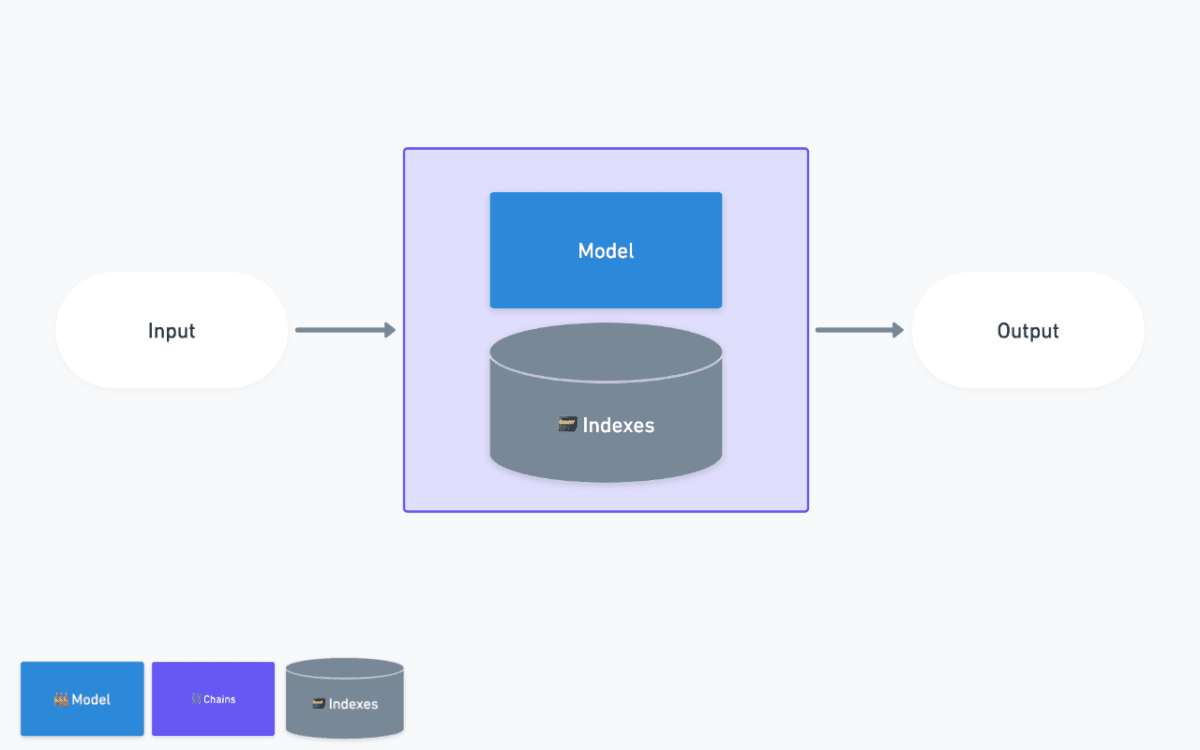
Indexes - ベクトルストアの利用
モチベーション:必要な情報を参照し回答を作成したい
例えばOpenAIのモデルであるgpt-3.5-turboやgpt-4は2021年9月までの知識しか持ちません。これは最新の情報を考慮し回答させたい場合に不都合です。また、QAbotを作成したい際には、ある特定の情報を参照しその情報に基づいた回答を作成したいというケースがあります。
これらを解決するのがIndexesです。
専用のchainを用意しそこにmodelと情報の格納場所であるvectoreStoreを与えます。
// src/05_indexes03_retrievalqa.ts
import { OpenAI } from "langchain/llms/openai";
import { RetrievalQAChain } from "langchain/chains";
import { HNSWLib } from "langchain/vectorstores/hnswlib";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
require("dotenv").config();
const run = async () => {
const vectorStore = await HNSWLib.load("store", new OpenAIEmbeddings());
const model = new OpenAI({});
const chain = RetrievalQAChain.fromLLM(model, vectorStore.asRetriever());
const res = await chain.call({
query: "アレックスは何者?",
});
console.log({ res });
};
run();
これでQABotのようなアプリが作成できるのですが、次の3点が疑問になると思います。
- そもそもどんなリソースを読み込んでいるのか
- ベクトルストアとは何か
-
RetrievalQAChainとは何か
実は、この一連の流れである 「リソースを用意してベクター化しretrieve(取得)する」 という行為こそ、現在のLLMを用いたQABotで重要な仕組みです。新しい概念ですので、以下で説明します。
1. コンテキスト長との戦い
色々なスタート地点があるのですが、筆者はLLMのコンテキスト長に目を向けると課題がわかりやすくなると感じています。
まず、LLMになにも制限がないのであれば以下のようなプロンプトでQABotが作れるはずです。
あなたはQABotです。ユーザーからの入力を受け付け質問に回答します。
以下のドキュメントを参考に回答を作成してください。
(--ドキュメント全ページ20万文字--)
Q:{User Input}
A:
しかしこれはうまくいきません。LLMには基本的に扱える文字列長に制限があるためです。
例えばgpt-3.5-turboだと日本語換算で2500字前後、gpt-4だとその倍程度です。
また、これは命令文(prompt)だけではなく出力長にも影響があります。つまり、入出力合計で2500字(5000字)以内でなくてはいけないということです。
したがって、制限の中どうにかして関連する文脈をLLMに渡し返答してもらう必要があります。
2. ベクトル検索
ここで「検索」を使用します。検索というとキーワード検索を思い浮かべるかもしれませんが、LLMアプリではよくベクトル検索が使用されます。これはキーワードが含まれなかったとしても、文脈や意味的な類似性をもとに結果を返せる仕組みがLLMと相性が良いからでしょう。
どういったものか少しだけ解説します。
ベクトル検索はクエリとターゲット文章の意味的な方向性を比較し、似ていれば返すという仕組みの検索手法です。
例えば以下のような文章がデータベースに保存されていたとします。
1. Next.jsはReactのフレームワークです。
2. TypeScriptを用いることでJavaScriptに型を導入できます。
3. 私はピザが好きです。
次に、以下のような文字列をクエリとすると…
フロントエンド開発の環境
結果として1, 2が返却されます。
文章にはなんとなくその「方向性」があります。ベクトル検索はその方向性を利用し、似た矢印の向きや長さをみて近似している文章を返却する仕組みとなります。
これにより、キーワードが含まれていなくても意味的に近い文章が返却できます。
3. Word Embedding
ではその「文章ごとの方向性・ベクトルをどのように定義するのか」というところで利用されるのが Word Embedding(単語の埋め込み) です。
詳細は割愛しますがこれを利用すればテキストをベクトルに、もっと詳細にいうと数字の配列にすることができます。
| Embedding | Sentence |
|---|---|
| [0.12, 0.75, 0.33] | Next.jsはReactのフレームワークです。 |
| [0.15, 0.72, 0.35] | TypeScriptを用いることでJavaScriptに型を導入できます。 |
| [0.67, 0.89, 0.01] | 私はピザが好きです。 |
このあたりで先ほどの疑問が解決できるのではないかと思います。
- そもそもどんなリソースを読み込んでいるのか
- ベクトルストアとは何か
- RetrievalQAChainとは何か
そもそもどんなリソースを読み込んでいるのか
これはターゲットとなる文章、文字列です。
ベクトルストアとは何か
ターゲットの文章をベクトル化し、先ほどのテーブルのようにベクトルと文章のペアとして保存したものです。
RetrievalQAChainとは何か
ベクトル検索を内部に組み込んだChainです。主な手順としては
- クエリ自体をEmbeddingでベクトル化する
フロントエンド開発の環境→(Word Embedding)→[0.13, 0.76, 0.32]
- ベクトルストアでクエリのベクトルと類似したターゲットのベクトルを探す
- 例:
[0.13, 0.76, 0.32]と類似した[0.12, 0.75, 0.33],[0.15, 0.72, 0.35]
- 例:
- ベクトルをkeyとしてターゲット文章を取得する
- 例:
[0.12, 0.75, 0.33]→Next.jsはReactのフレームワークです。 - 例:
[0.15, 0.72, 0.35]→TypeScriptを用いることでJavaScriptに型を導入できます。
- 例:
- 取得した文章をプロンプトに入力し回答を得る
// 例
あなたはQABotです。ユーザーからの入力を受け付け質問に回答します。
以下のドキュメントを参考に回答を作成してください。
(挿入部)
Next.jsはReactのフレームワークです。
TypeScriptを用いることでJavaScriptに型を導入できます。
(さらに追加でretrieveされたドキュメントの文章...)
Q:{User Input}
A:
Indexes - ベクトルストアの作成
以上で、ストアから必要情報を抜き出して回答を作れるようになりました。
最後にまだ扱っていない「ベクトルストアの作成方法」について、この作成ツールもLangChainは用意しています。すごいライブラリです。
具体的にはDocument Loaders, Text Splittersというツールです。これらを用いて最後に各種Vector Storesでベクトルストアが保存できます。
やりたいことは
- テキストを用意する
- テキストをちょうど良い長さにする(長すぎるとコンテキスト長に収まらないため)
- ちょうど良い長さの文章をベクトルにする
の3つです。ここでそれぞれのツールが使えます。
例えば以下のモジュールを利用すればGitHubの情報が読み込めます。
import { GithubRepoLoader } from "langchain/document_loaders/web/github";
export const run = async () => {
const loader = new GithubRepoLoader(
"https://github.com/hwchase17/langchainjs",
{ branch: "main", recursive: false, unknown: "warn" }
);
const docs = await loader.load();
console.log(docs);
};
run();
このようにして用意したテキストをText SplittersとVectore Storeに渡すことでベクトルストアが作成できます。
import { HNSWLib } from "langchain/vectorstores/hnswlib";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import * as fs from "fs";
require("dotenv").config();
export const run = async () => {
const text = fs.readFileSync("materials/story_by_gpt.txt", "utf8");
// テキストの分割
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 500 });
const docs = await textSplitter.createDocuments([text]);
//ベクトルストアの作成
const vectorStore = await HNSWLib.fromDocuments(docs, new OpenAIEmbeddings());
vectorStore.save("store");
};
run();
このようにしてベクトルストアの作成と、それを用いたIndexに関連するChainが作成できます。
少々長い説明になってしまいましたが、VectorStoreを用いること、内部でベクトル検索が動いてプロンプトが作成されているという概念をつかんでおくと全体間が把握しやすくなるはずです。
Agents
モチベーション:タスク設計からAIに考えて実行してほしい
Agentを定義し、そこにmodelとtoolsを渡して実行します。
構造としてはシンプルでChainの代わりにAgentが用意されており、新たにtoolsという概念が登場しています。

// src/06_agents.ts
import { initializeAgentExecutorWithOptions } from "langchain/agents";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { SerpAPI } from "langchain/tools";
import { Calculator } from "langchain/tools/calculator";
require("dotenv").config();
export const run = async () => {
const model = new ChatOpenAI({ modelName: "gpt-4" });
const tools = [new SerpAPI(), new Calculator()];
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: "chat-zero-shot-react-description",
verbose: true,
});
const result = await executor.call({ `今日の東京の最高気温を摂氏で調べてください。またその数値を2倍した値はいくつですか?` });
console.log(`Got output ${result.output}`);
};
run();
Agentは命令を受け取ると与えられた道具(ツール)を最適な順番に並び替え、命令を実行します。
非常に曖昧な概念なので内部を覗いて具体化してみます。
まずTool自体は非常にシンプルで次のような構造です。

文字列が入出力の関数と、名前、説明文のみです。
さらにこのToolがLLMに渡された直後どのような動きをするのか見てみましょう。

この最後に生成される['検索関数','電卓関数']のようなツールの順番が特定できる出力が肝です。(実際の挙動とは若干異なります)
つまりAgentがやっていることは、タスク(ゴール)とtool群を受け取り、toolの説明文もLLMに渡して最適な順番を出力させるという仕事です。
これにより外部への検索機能であったり、計算問題の機能を付与しつつ、その柔軟な実行を任せることができます。
順番が決定されれば内部では((input:string)=>Promise<string>)で、文字列受け渡しの関数が実行されていきます。

おわりに
以上がLangChainのざっくりとしたメンタルモデルとなります。これからLLMアプリ開発を始める方の簡単な地図になれば嬉しいなぁと思います。
今回の概要を押さえておくと、
「Retrievalをもう少し拡張させたいな…よしLlamaIndex試してみよう!」
など他のライブラリ、後続のLLMライブラリの理解もしやすくなるはずです。
テンポ良く説明しようと思ったのですが途中ちょっと長くなってしまいました。もっと話したいけど深掘りすぎると細かくなるので…
Embeddingはまた別の文献などで調べてみてください。これだけでもすごいおもしろいです。
それではこのあたりで!またお会いしましょう!
Discussion
LangChain触ってみたかったので入門としてとても参考になりました!!!
すごいライブラリですね!!!