ローカルで無料で使える!OpenAI Whisperによる文字起こしツールの構築方法
はじめに
音声の文字起こしは、会議の議事録作成、インタビューの書き起こし、動画コンテンツの字幕作成など、様々な場面で必要とされる作業です。クラウドベースの文字起こしサービスは多数存在しますが、料金がかかったり、プライバシーの懸念があったりします。
本記事では、OpenAIが公開しているオープンソースの音声認識モデル「Whisper」を使って、完全無料でローカル環境で動作する文字起こしツールを構築する方法を解説します。インターネット接続不要で、プライバシーを確保しながら高精度な文字起こしが可能です!
以下のレポジトリからローカルに環境構築して実行することでwhisperを使用できます!
Whisperとは?
Whisperは、OpenAIが2022年9月に公開したオープンソースの音声認識モデルです。以下の特徴があります:
- 多言語対応(日本語を含む80以上の言語)
- 複数のモデルサイズ(tiny〜large)から選択可能
- 高い認識精度
- 完全にローカルで動作可能
- MITライセンスで商用利用も可能
環境構築手順
1. 必要なソフトウェアのインストール
まず、以下のソフトウェアが必要です:
- Python 3.8以上
- FFmpeg(音声処理に必要)
Pythonのインストール
公式サイト( https://www.python.org/ )からダウンロードするか、Homebrew(Mac)やChocolatey(Windows)などのパッケージマネージャーを使ってインストールできます。
FFmpegのインストール
-
Macの場合:
brew install ffmpeg -
Windowsの場合:
公式サイト( https://ffmpeg.org/download.html ) からダウンロードするか、以下のコマンドでインストール:choco install ffmpeg -
Ubuntuの場合:
sudo apt update && sudo apt install ffmpeg
2. プロジェクトの作成
任意のディレクトリに新しいフォルダを作成し、そこに移動します:
mkdir whisper-transcription
cd whisper-transcription
3. 仮想環境の作成
Pythonの仮想環境を作成して有効化します:
python -m venv venv
# Macの場合
source venv/bin/activate
# Windowsの場合
venv\Scripts\activate
4. 必要なパッケージのインストール
以下の内容でrequirements.txtファイルを作成します:
openai-whisper>=20231117
streamlit>=1.27.0
torch>=2.0.0
torchaudio>=2.0.0
numpy==1.26.4
pandas>=1.3.0
pydub>=0.25.1
librosa>=0.10.0
soundfile>=0.12.1
重要: NumPyのバージョンを1.26.4に固定していることに注意してください。これは、NumPy 2.x系とTorch/Whisperの互換性問題を回避するためです。
次に、パッケージをインストールします:
pip install -r requirements.txt
アプリケーションの作成
1. コマンドライン版の文字起こしスクリプト
まず、コマンドラインから使用できる基本的な文字起こしスクリプトtranscribe.pyを作成します:
#!/usr/bin/env python3
"""
Whisper文字起こしコマンドラインツール
"""
import os
import sys
import time
import argparse
import whisper
def main():
"""メイン関数"""
parser = argparse.ArgumentParser(description="Whisper文字起こしツール")
parser.add_argument("--file", required=True, help="文字起こしを行う音声ファイルへのパス")
parser.add_argument("--model", default="base", choices=["tiny", "base", "small", "medium", "large"],
help="使用するWhisperモデルのサイズ")
parser.add_argument("--language", help="音声の言語(例: ja, en)。指定しない場合は自動検出")
parser.add_argument("--output", help="出力テキストファイルのパス。指定しない場合は標準出力")
args = parser.parse_args()
# ファイルの存在確認
if not os.path.exists(args.file):
print(f"エラー: ファイル '{args.file}' が見つかりません。", file=sys.stderr)
return 1
print(f"モデル '{args.model}' をロード中...", file=sys.stderr)
start_time = time.time()
# モデルのロード
model = whisper.load_model(args.model)
print(f"モデルロード完了({time.time() - start_time:.2f}秒)", file=sys.stderr)
print("文字起こし処理中...", file=sys.stderr)
# 文字起こしオプション
options = {}
if args.language:
options["language"] = args.language
# 文字起こし実行
result = model.transcribe(args.file, **options)
# 結果の出力
if args.output:
with open(args.output, "w", encoding="utf-8") as f:
f.write(result["text"])
print(f"文字起こし結果を '{args.output}' に保存しました。", file=sys.stderr)
else:
print("\n" + "="*80, file=sys.stderr)
print("文字起こし結果:", file=sys.stderr)
print("="*80, file=sys.stderr)
print(result["text"])
print(f"\n処理時間: {time.time() - start_time:.2f}秒", file=sys.stderr)
return 0
if __name__ == "__main__":
sys.exit(main())
2. Webインターフェース版(Streamlit)
次に、ブラウザから操作できるWebインターフェースを持つアプリケーションapp.pyを作成します:
#!/usr/bin/env python3
"""
Whisper文字起こしWebアプリ(Streamlit使用)
"""
import os
import sys
import time
import tempfile
import whisper
import torch
import streamlit as st
from datetime import datetime
# ページ設定
st.set_page_config(
page_title="Whisper文字起こしツール",
page_icon="🎤",
layout="wide"
)
# キャッシュ設定(モデルを再ロードしないようにする)
@st.cache_resource
def load_whisper_model(model_name):
"""Whisperモデルをロードする(キャッシュ使用)"""
device = "cuda" if torch.cuda.is_available() else "cpu"
return whisper.load_model(model_name, device=device)
def check_ffmpeg():
"""FFmpegがインストールされているか確認"""
if os.system("ffmpeg -version > /dev/null 2>&1") != 0:
st.error("⚠️ FFmpegがインストールされていません。https://ffmpeg.org/download.html からダウンロードしてください。")
st.stop()
def get_available_models():
"""利用可能なWhisperモデルの一覧を返す"""
return ["tiny", "base", "small", "medium", "large"]
def main():
"""メイン関数"""
st.title("🎤 Whisper文字起こしツール")
st.markdown("""
OpenAIのWhisperモデルを使用して、音声ファイルからテキストへの文字起こしを行います。
""")
# FFmpegの確認
check_ffmpeg()
# サイドバー設定
st.sidebar.title("設定")
# モデル選択
model_option = st.sidebar.selectbox(
"モデルサイズを選択",
options=get_available_models(),
index=1, # baseをデフォルトに
help="大きいモデルほど精度が上がりますが、処理時間も増加します。"
)
# 言語選択
language_option = st.sidebar.selectbox(
"言語を選択(自動検出する場合は空欄)",
options=["", "en", "ja", "zh", "de", "fr", "es", "ko", "ru"],
index=0,
format_func=lambda x: {
"": "自動検出", "en": "英語", "ja": "日本語", "zh": "中国語",
"de": "ドイツ語", "fr": "フランス語", "es": "スペイン語",
"ko": "韓国語", "ru": "ロシア語"
}.get(x, x),
help="音声の言語を指定します。自動検出も可能です。"
)
# デバイス情報表示
device = "GPU (CUDA)" if torch.cuda.is_available() else "CPU"
st.sidebar.info(f"使用デバイス: {device}")
if device == "CPU":
st.sidebar.warning("GPUが検出されませんでした。処理が遅くなる可能性があります。")
# サイドバーにGitHubリンク
st.sidebar.markdown("---")
st.sidebar.markdown("[GitHubリポジトリ](https://github.com/yourusername/whisper-transcription)")
# ファイルアップロード
uploaded_file = st.file_uploader("音声ファイルをアップロード",
type=["mp3", "wav", "m4a", "ogg", "flac"],
help="対応フォーマット: MP3, WAV, M4A, OGG, FLAC")
if uploaded_file is not None:
# ファイル情報表示
file_size_mb = uploaded_file.size / (1024 * 1024)
st.info(f"ファイル: {uploaded_file.name} ({file_size_mb:.2f} MB)")
# 音声再生機能
st.audio(uploaded_file, format=f"audio/{uploaded_file.name.split('.')[-1]}")
# 文字起こし実行ボタン
transcribe_button = st.button("文字起こし開始", type="primary")
if transcribe_button:
# 処理開始
with st.spinner("文字起こし処理中..."):
# 一時ファイルとして保存
with tempfile.NamedTemporaryFile(delete=False, suffix=f".{uploaded_file.name.split('.')[-1]}") as tmp_file:
tmp_file.write(uploaded_file.getvalue())
temp_filename = tmp_file.name
try:
# モデルロード
load_start = time.time()
progress_text = st.empty()
progress_text.text("モデルをロード中...")
model = load_whisper_model(model_option)
load_end = time.time()
progress_text.text(f"モデルロード完了({load_end - load_start:.2f}秒)")
# 文字起こし処理
progress_text.text("文字起こし処理中...")
transcribe_start = time.time()
# 言語オプション設定
options = {}
if language_option:
options["language"] = language_option
# 文字起こし実行
result = model.transcribe(temp_filename, **options)
transcribe_end = time.time()
progress_text.empty()
# 処理時間計算
transcribe_time = transcribe_end - transcribe_start
total_time = transcribe_end - load_start
# 結果表示
st.markdown("### 文字起こし結果")
st.success(f"処理完了(文字起こし: {transcribe_time:.2f}秒、合計: {total_time:.2f}秒)")
# テキスト結果表示
st.markdown("#### テキスト")
st.text_area("", value=result["text"], height=200)
# ダウンロードボタン
st.download_button(
label="テキストをダウンロード",
data=result["text"],
file_name=f"{os.path.splitext(uploaded_file.name)[0]}_transcript.txt",
mime="text/plain"
)
# タイムスタンプ付きの詳細結果
with st.expander("詳細(タイムスタンプ付き)"):
# テーブル表示用のデータ準備
table_data = []
timestamp_text = ""
for segment in result["segments"]:
start_time = segment["start"]
end_time = segment["end"]
text = segment["text"]
# 時間をフォーマット (HH:MM:SS.ms)
start_formatted = str(datetime.utcfromtimestamp(start_time).strftime('%H:%M:%S.%f'))[:-3]
end_formatted = str(datetime.utcfromtimestamp(end_time).strftime('%H:%M:%S.%f'))[:-3]
table_data.append({
"開始": start_formatted,
"終了": end_formatted,
"テキスト": text
})
timestamp_text += f"[{start_formatted} --> {end_formatted}] {text}\n"
# テーブル表示
st.table(table_data)
# タイムスタンプ付きテキストのダウンロードボタン
st.download_button(
label="タイムスタンプ付きテキストをダウンロード",
data=timestamp_text,
file_name=f"{os.path.splitext(uploaded_file.name)[0]}_transcript_timestamps.txt",
mime="text/plain"
)
except Exception as e:
st.error(f"エラーが発生しました: {str(e)}")
finally:
# 一時ファイルの削除
if os.path.exists(temp_filename):
os.unlink(temp_filename)
else:
# ファイルがアップロードされていない場合の表示
st.info("👆 音声ファイルをアップロードしてください")
# サンプル説明
with st.expander("使い方"):
st.markdown("""
1. サイドバーでモデルサイズと言語を選択
2. 音声ファイルをアップロード
3. 「文字起こし開始」ボタンをクリック
4. 結果を確認し、必要に応じてダウンロード
**モデルサイズについて:**
- tiny: 最小・最速(低精度)
- base: バランス型(推奨)
- small: 中程度の精度
- medium: 高精度
- large: 最高精度(処理時間が長い)
""")
if __name__ == "__main__":
main()
アプリケーションの実行
コマンドライン版の実行
python transcribe.py --file path/to/audio/file.mp3 --model base --language ja
Webインターフェース版の実行
重要: Streamlitを実行する前に、必ず仮想環境を有効化してください。
# 仮想環境の有効化
source venv/bin/activate # Macの場合
venv\Scripts\activate # Windowsの場合
# Streamlitアプリの起動
streamlit run app.py
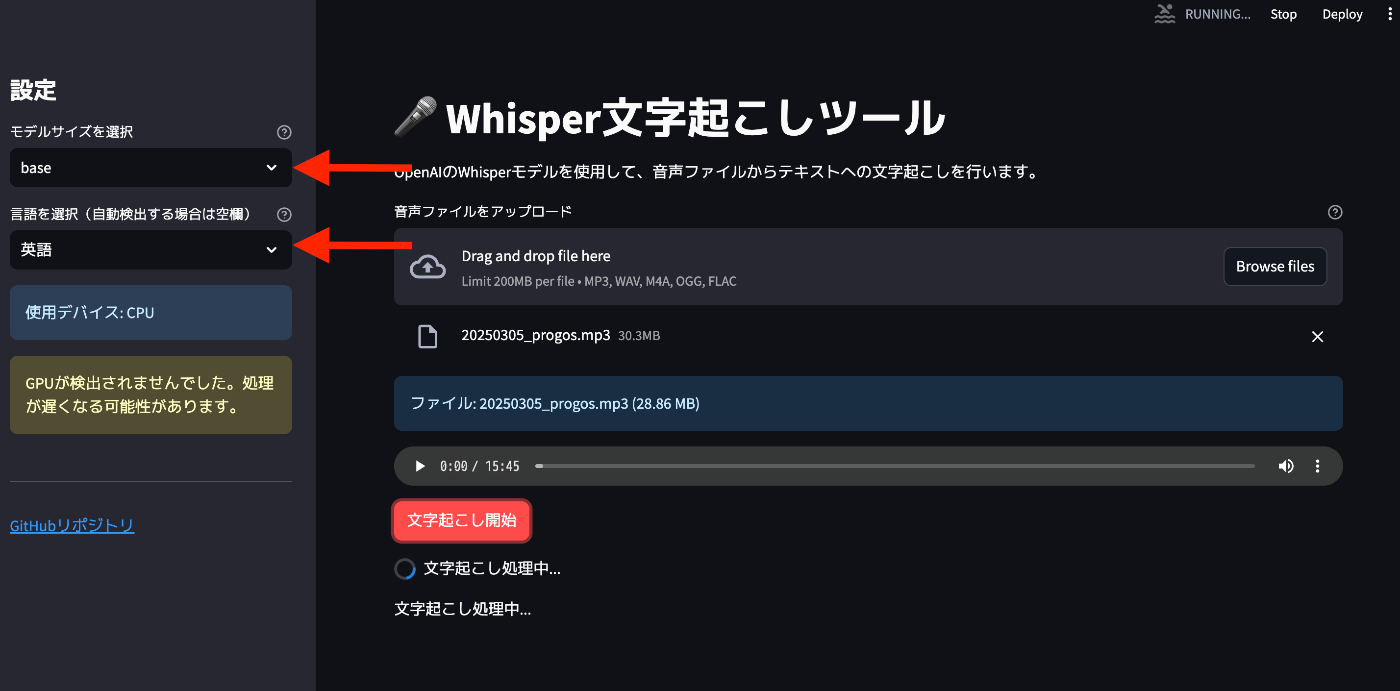
こちらはstreamlitで実際に起動したwhisperの画面です。
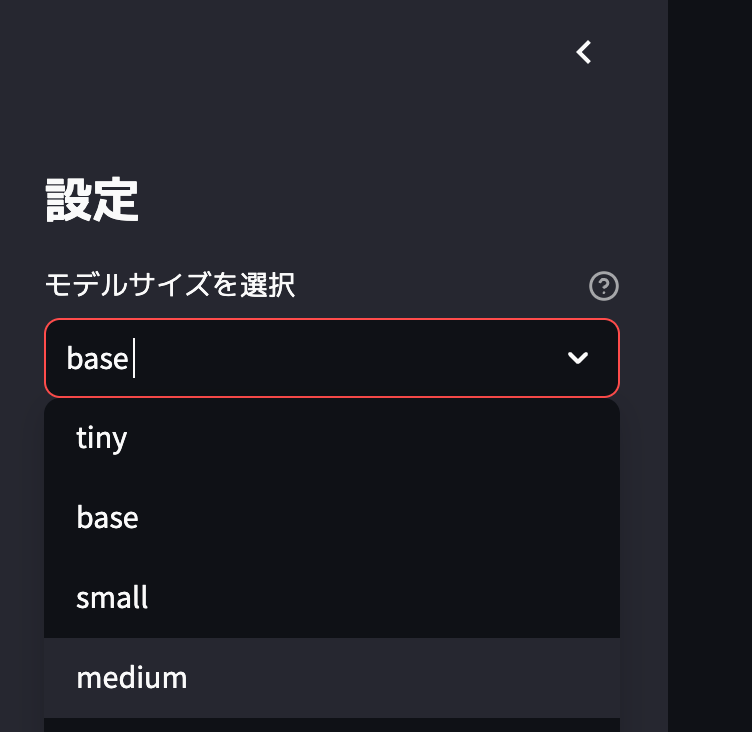
モデルサイズは
- tiny
- base
- small
- medium
の4種類から選択することができます。
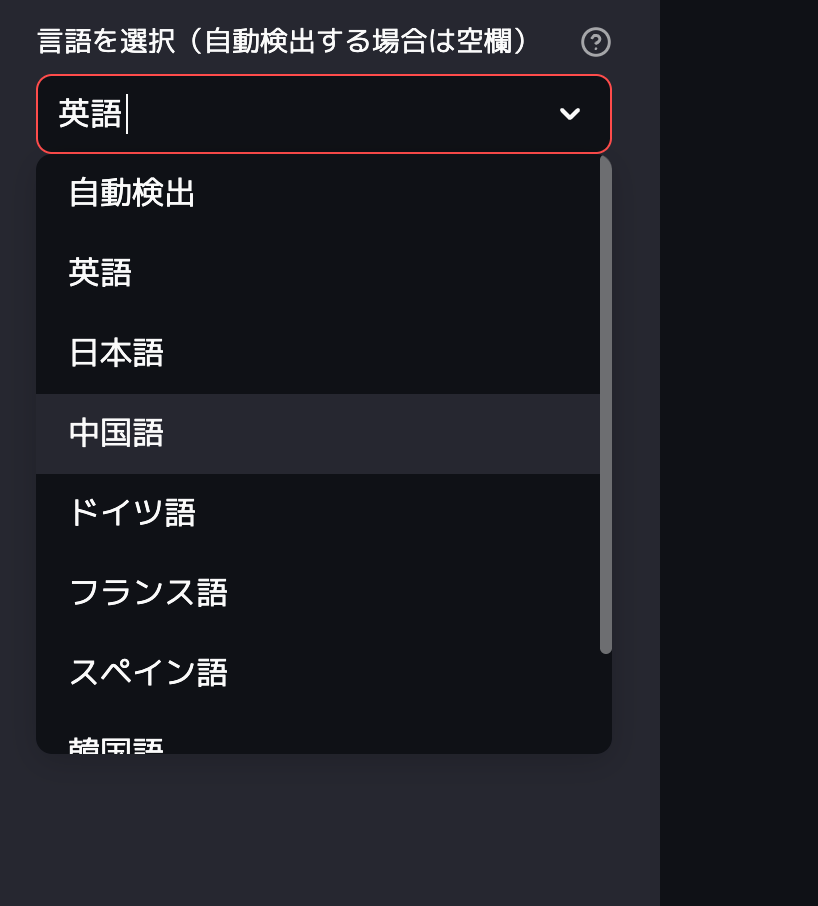
さらに言語選択も自動検出もあれば、英語、日本語、中国語、ドイツ語、フランス語、スペイン語、韓国語等たくさん言語を文字起こしすることが可能です。
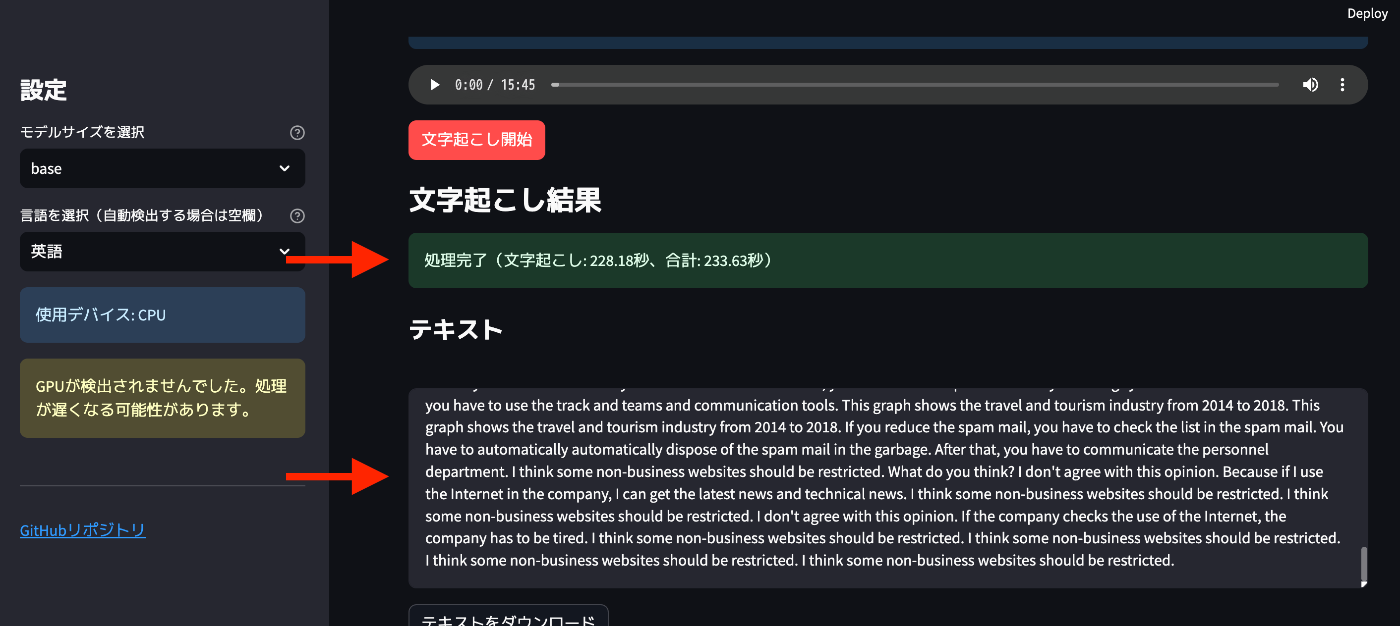
このようにブラウザ上で挙げると、28MBのファイルで大体4分程度で処理が完了します(GPTを積んでいないmacPCなので処理に多少時間がかかります。が無料なのでいいです!)
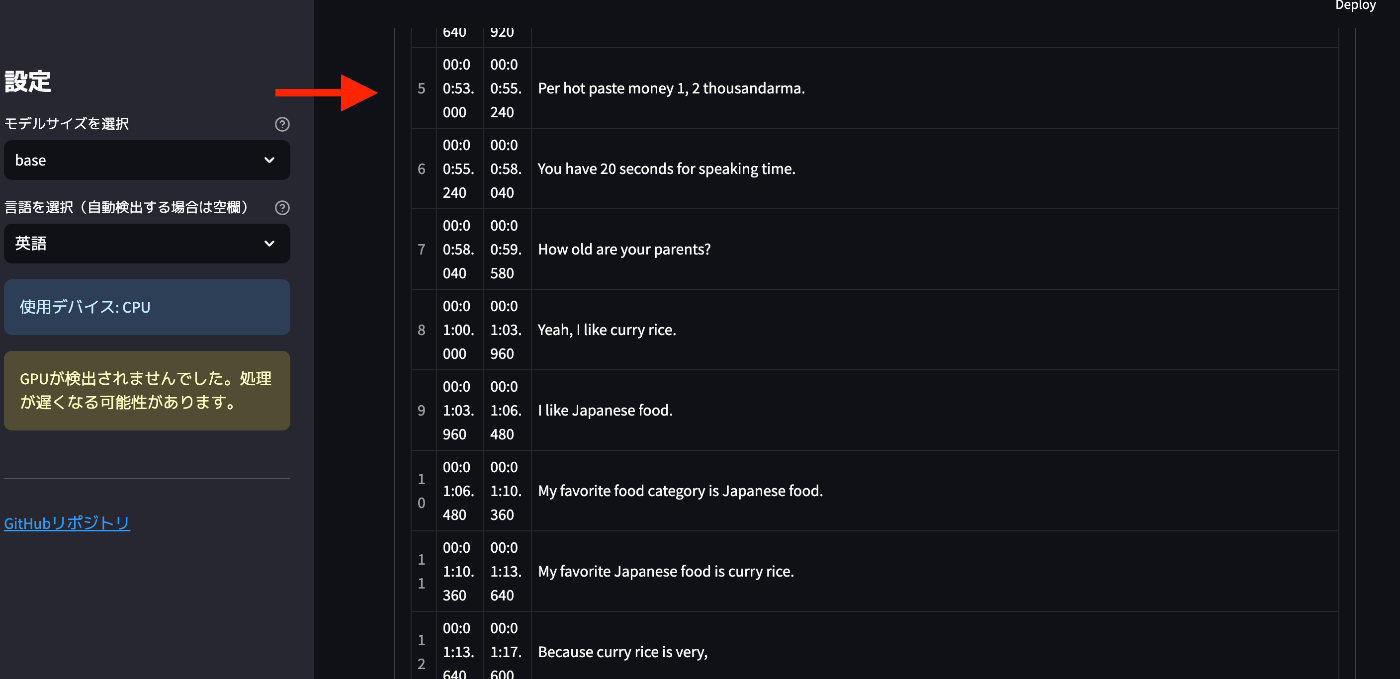
このように時間ごとに会話を分けて出力することも可能なので、超絶有能です…!
トラブルシューティング
「command not found: streamlit」エラー
このエラーは、Streamlitがインストールされていないか、仮想環境が有効化されていない場合に発生します。以下の手順で解決できます:
- 仮想環境が有効化されているか確認(プロンプトに
(venv)が表示されているか) - 有効化されていない場合は、以下のコマンドで有効化:
source venv/bin/activate # Macの場合 - Streamlitが正しくインストールされているか確認:
pip list | grep streamlit - インストールされていない場合は、再インストール:
pip install streamlit
NumPy関連のエラー
A module that was compiled using NumPy 1.x cannot be run in NumPy 2.1.3 as it may crash.
このエラーは、NumPy 2.x系とTorch/Whisperの互換性問題によるものです。解決策:
pip install numpy==1.26.4
まとめ:ローカルWhisperの強み
1. 完全無料で使える
- OpenAIのWhisperモデルは完全に無料で公開されています
- APIキーや課金は一切不要
- 使用量に制限なし
2. プライバシーが確保される
- 音声データがローカルで処理されるため、外部サーバーに送信されない
- 機密情報を含む会議やインタビューの文字起こしも安心
- インターネット接続不要で動作
3. 高い認識精度
- 多言語に対応(日本語の認識精度も高い)
- 様々なモデルサイズから選択可能
- 背景ノイズにも比較的強い
4. カスタマイズ可能
- オープンソースなので、必要に応じてカスタマイズ可能
- 特定の専門用語や固有名詞の認識を改善するためのファインチューニングも可能
- 自分のニーズに合わせたUIの構築が可能
5. 商用利用も可能
- MITライセンスで提供されているため、商用利用も可能
- 自社サービスへの組み込みも自由
おわりに
OpenAI Whisperを使ったローカル文字起こしツールは、クラウドサービスに頼ることなく、高品質な文字起こしを無料で実現できる素晴らしい選択肢です。特にプライバシーを重視する場面や、大量の音声データを処理する必要がある場合に最適です。
この記事で紹介したコードをベースに、ぜひ自分のニーズに合わせたカスタマイズを試してみてください。GPUを搭載したマシンであれば、さらに高速な処理も可能です。
文字起こし作業の効率化に、ぜひWhisperの力をお役立てください!
最後に
私は2つのプラットフォームで生成AIに関する発信を行なっております。
生成AIサービスの考察を見たい方へ
生成AIサービスの動向やや具体的な内容は、noteで詳しく解説しています。
noteプロフィール: @mizupee
日々の生成AI分析を追いたい方へ
毎日1つの生成AIサービスを分析するTwitter投稿「#100DaysofAI」もぜひフォローください。簡潔なポイント分析とアイデア共有を継続中です。
Twitter: @mizupee
Discussion
記事の内容で実行したところWhisper文字起こしツールを起動すると、
FFmpeg をインストールしてください。というエラーが発生してツールが使用できませんでした。
原因:Windows 環境では
/dev/nullが使用できなかったので、NULで対応。上記部分を修正することで正常に実行することが出来ました。
ご参考までに。