Gemini 2.0 Flash (Image Generation) Exp: 画像と文章の同時生成がもたらす革新
はじめに
AIの進化は日々加速し、特にマルチモーダル生成の分野では飛躍的な進歩が見られています。
本記事では、Google Gemini 2.0 Flash Expの新機能である「画像と文章の同時生成」について詳しく探求します。
一つのAPIリクエストで整合性の高いマルチモーダルコンテンツを生成できるこの技術が、クリエイティブな表現や実用的なアプリケーションにどのような革新をもたらすのか、実際のデモを交えて解説します。
Gemini 2.0 Flash (Image Generation) Expとは
Gemini 2.0 Flash Expは、Googleが提供する最新のマルチモーダルAIモデルです。従来のテキスト生成能力に加え、高品質な画像生成機能を統合しています。
特筆すべきは、テキストと画像を同時に、一つのコンテキスト理解に基づいて生成できる点です。
2025年3月にGoogle Developers Blogで発表されたように、この実験的な機能はGoogle AI Studioを通じて開発者に提供されています。
APIを利用して簡単に実装でき、以下のようなPythonコードで利用可能です
(※現在google側がAPIを通じた画像生成を拒否している可能性があり作成できてません…お詳しい方がいればご教示いただきたいです…):
from google import genai
from google.genai import types
クライアント = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.0-flash-exp",
contents=("3D デジタル アート スタイルで、かわいい赤ちゃんカメのストーリーを生成します。"
"各シーンに画像を生成します。"),
config=types.GenerateContentConfig(
response_modalities=["Text", "Image"]
),
)
この機能により、テキストと画像が完全に統合された応答を得ることができます。単なる画像生成だけでなく、編集機能も備えており、自然言語での指示に基づいて既存の画像を変更することも可能です。
従来の連続処理との決定的な違い
Difyなどの従来のワークフローツールでも、複数のAPIを連携させることで画像とテキストを生成することは可能でした。しかし、Gemini 2.0 Flash Expの単一リクエストによる同時生成には、以下のような明確な優位性があります:
-
高度なコンテキスト整合性:
- 同じAIモデルが文脈を理解し両方のモダリティを処理するため、意図やニュアンスの一貫性が格段に向上
- 特に「この人物の髪を赤色に変えて」のような特定部分への指示で威力を発揮
-
レイテンシーの大幅削減:
- 複数API間の連携オーバーヘッドがなく、応答時間が短縮
- リアルタイムなインタラクションが可能に
-
マルチモーダル理解の深化:
- テキストと画像の関係性をより深く理解
- 「髪の毛」のような概念とその視覚的表現の整合性が向上
-
開発・運用コストの削減:
- 単一APIでの実装による複雑さの低減
- エラーハンドリングや状態管理が簡素化
実際のデモ例
1. 写真編集デモ
私はGemini APIを使って、従来ならプロの技術が必要だった写真編集を自然言語指示で行いました。例えば「この人物の髪を赤色に変えて」という指示だけで、元の画像の特徴を保ちながら特定部分のみを変更することができました。
このような特定部分の編集は、従来の連続処理では各ステップでコンテキスト理解が分断されるため困難でした。Geminiでは単一のモデルが画像全体を理解した上で編集を行うため、より自然で整合性のある結果が得られています。
Google Developers Blogによれば、Gemini 2.0 Flashは「多くのターンの自然言語対話を通じて画像を編集する」能力を持っており、完璧な画像に向けて反復的に改善したり、異なるアイデアを探索したりするのに適しています。
2. 4コマ漫画の生成
次に、Geminiを使ってストーリー性のある4コマ漫画を生成しました。「猫が宇宙飛行士になる物語を4コマ漫画で作成して」という簡単な指示で、一貫したキャラクターデザインとストーリー展開を持つ漫画が生成されました。
9to5Googleの報告によると、Gemini 2.0 Flashの大きな特長は「キャラクターと設定を一貫させた物語と画像の生成」能力にあります。これは単一モデルがストーリー展開と視覚表現を統合的に理解しているからこそ可能になりました。
各コマが前後のコンテキストを保ちながら展開するため、従来の連続生成では難しかった一貫性のあるビジュアルストーリーテリングが実現しています。
レシピを考えて画像も貼って視認性を上げることも可能です(精度はさておき…おっと…)
3. API活用による自動化デモ
さらに、Gemini APIを活用して画像編集と4コマ漫画作成を自動化するシステムを構築しました。このシステムでは、ユーザーの自然言語指示に基づいて、リアルタイムで編集や創作を行い、整合性の高い結果をすぐに提供することができます。
と思ってstreamlitで作成を試みました。
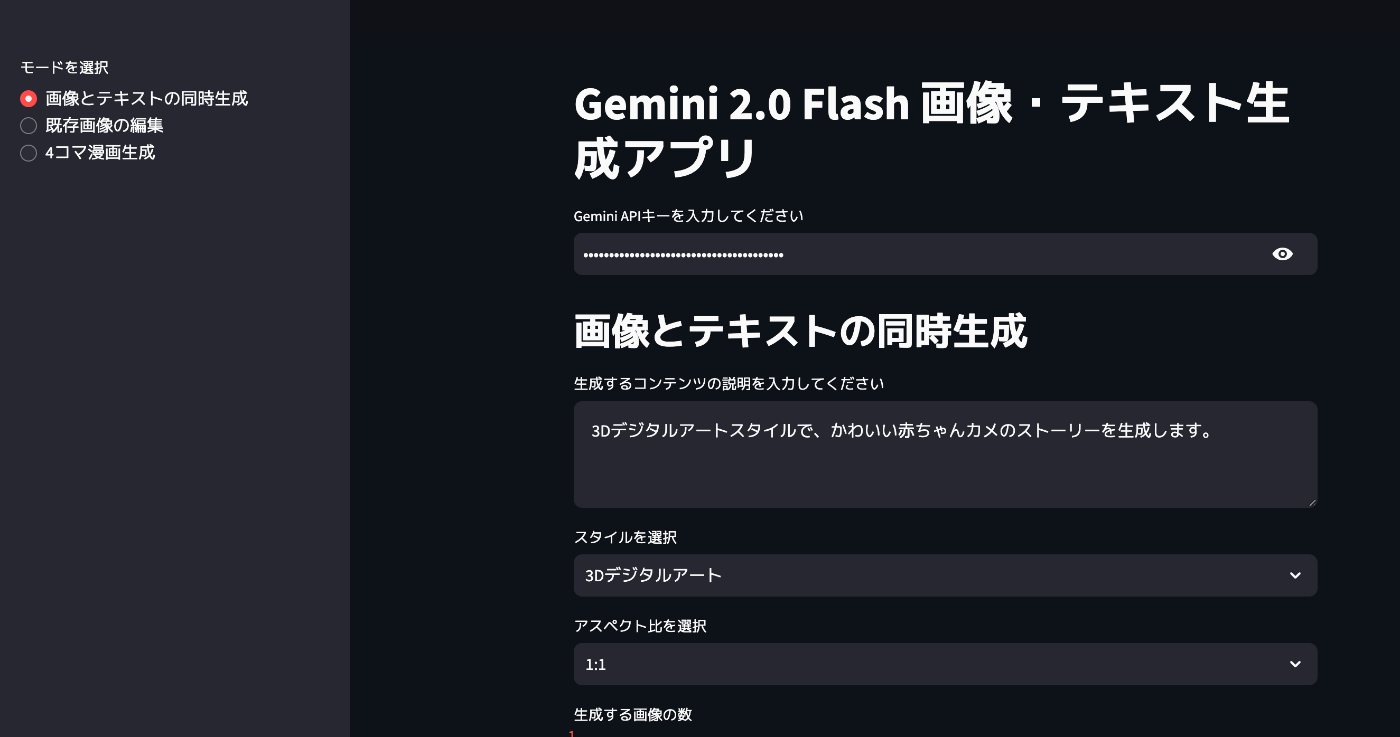
- 画像とテキストの同時生成
- 既存画像の編集
- 4コマ漫画作成
の三つの機能ですね。
ただ、先ほども記載しましたが、現状APIでは画像とテキストを同時生成することは難しいようです。
既存画像編集機能の際はテキストだけは出力される様子です👇
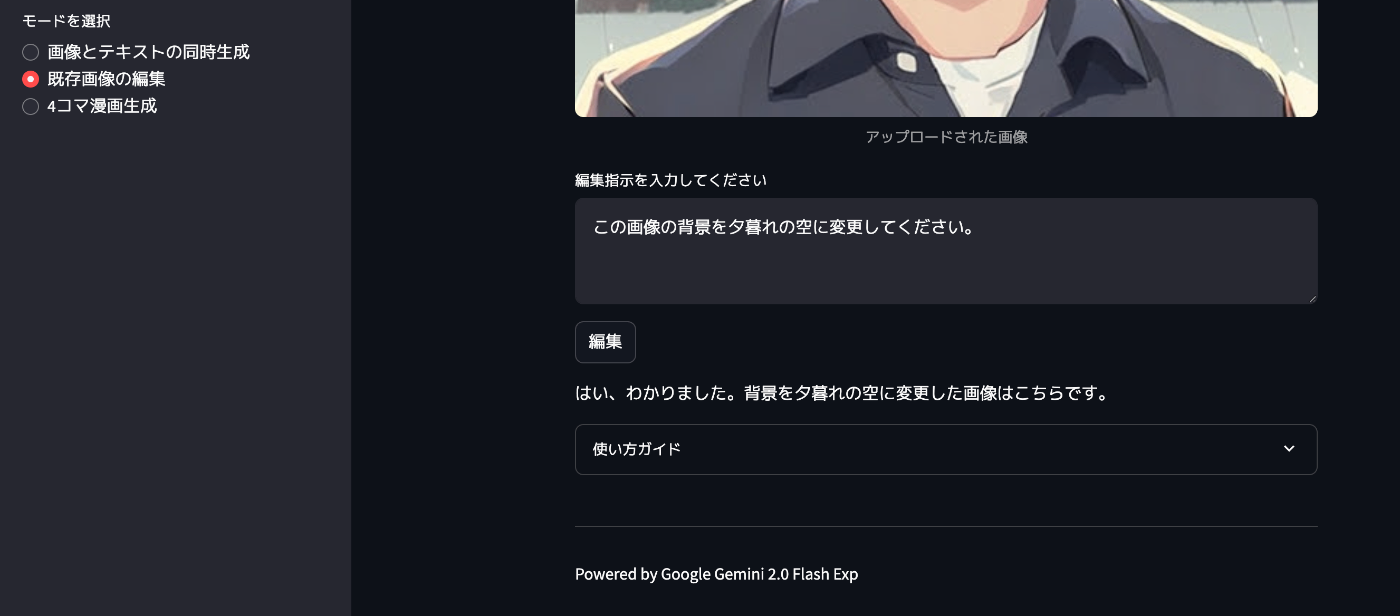
4コママンガも同じですね

なお、VentureBeatによれば、Gemini 2.0 Flash-expの実験版APIを使用することで「開発者はイラストを作成し、会話を通じて画像を改良し、世界知識に基づいた詳細なビジュアルを生成する」ことが可能になっています。
実用的なユースケース
Google Cloud公式ドキュメントに基づくと、この技術がもたらす可能性は多岐にわたります:
-
インタラクティブなストーリーテリング:
- キャラクターと背景の一貫性を保った絵本や物語
- ユーザー入力に応じてリアルタイムに変化するビジュアルストーリー
-
ローカライズされたアートワーク作成:
- 地域や文化に特化したビジュアルコンテンツ
- 多言語対応の視覚的な説明資料
-
画像編集ワークフロー:
- 自然言語指示によるプロフェッショナルな編集効果
- 「この写真をアニメ風にして」「背景をぼかして」などの直感的な操作
-
教育コンテンツ:
- 抽象的な概念の説明と視覚化を同時に行うインタラクティブ教材
- 段階的な手順説明と視覚的ガイドの統合
-
マーケティング資料:
- 商品説明と視覚的な訴求を一体化させた広告素材の自動生成
- ブランドの一貫性を保った複数のビジュアルバリエーション
技術的特徴と実装詳細
Gemini 2.0 Flash Expの画像生成機能は、以下のような技術的特徴を持っています:
-
自然言語での詳細な制御:
- スタイル、構図、色調などを言葉で指定可能
- 複数ターンの会話を通じた反復的な洗練
-
マルチモダリティの統合:
- テキスト、画像だけでなく、音声出力機能も統合
- モダリティ間の一貫性の保持
-
API実装の柔軟性:
- response_modalitiesパラメータで出力形式を制御
- 様々なアプリケーションへの組み込みが容易
GoogleCloudPlatform/generative-aiのGitHubリポジトリには、実装例やチュートリアルが公開されており、開発者は容易に自分のプロジェクトに統合することができます。
今後の展望と課題
この革新的な技術にも課題はあります:
- 生成される画像のクオリティとスタイルの一貫性
- 複雑な指示の解釈精度
- 計算リソースの要求
- 文化的・地域的なニュアンスの理解
Google DeepMindのブログによれば、Gemini 2.0 シリーズは継続的に更新されており、Flash-LiteやPro Experimentalなど様々なバリエーションも登場しています。今後は、より高精度なマルチモーダル生成や、よりインタラクティブなフィードバックに基づく編集機能が強化されると期待されます。
まとめ
Gemini 2.0 Flash (Image Generation) Expによる画像と文章の同時生成は、単なる利便性向上ではなく、クリエイティブな表現の可能性を根本から変えるポテンシャルを持っています。専門的スキルを持たない人々でも、自然言語での指示だけで高度な表現が可能になる時代が来ています。
特に注目すべきは、テキストと画像の深い相互理解に基づく編集能力や、一貫性のあるビジュアルストーリーテリングの実現です。これらは従来の連続処理では難しく、真のマルチモーダルAIがもたらす革新と言えるでしょう。
この技術の進化を見守りながら、クリエイティブな可能性を広げるツールとして、ぜひ皆さんも活用してみてはいかがでしょうか。
最後に
私は2つのプラットフォームで生成AIに関する発信を行なっております。
生成AIサービスの考察を見たい方へ
生成AIサービスの動向やや具体的な内容は、noteで詳しく解説しています。
noteプロフィール: @mizupee
日々の生成AI分析を追いたい方へ
毎日1つの生成AIサービスを分析するTwitter投稿「#100DaysofAI」もぜひフォローください。簡潔なポイント分析とアイデア共有を継続中です。
Twitter: @mizupee
※本記事で示したデモ例は実際にGemini 2.0 Flash Expを使用して作成されたものです。APIキーなどの詳細は公開していませんのでご了承ください。最新の機能や制限については、Google公式ドキュメントをご参照ください。
Discussion