Motion Matchingによるキャラクター操作
最近のゲームエンジンではステートマシンやブレンドツリーを組むことによって、アニメーションクリップを組み合わせてリアルタイムでキャラクターを動かしますが、高品質なアニメーションを作るには専門的な技術も必要です。
そこで、アニメーションクリップを用意するだけ(?)で、手間をかけずにリアルタイムでキャラクターを動かすMotion Matchingという手法を紹介します。
1. Motion Matchingとは?
Motion Matching(MM)は予め用意されたアニメーションデータを切り貼りすることで、リアルタイムでアニメーションを作成する手法です。似たような手法としてMotion Graphsが存在しますが、Motion Matchingは事前にグラフ構造を組むのではなく、全アニメーションデータ(アニメーションデータベース)に対して探索をかける点が異なります。Motion Matchingはユーザーの入力に対応できるなど、リアルタイム性を意識したアプローチになっていますが、全探索が必要なためbrute-forceな方式です。
MM自体は次世代のアニメーション技術として2015年頃に発表されました。
現在previewではありますが、UnityのKinematicaとしても似たような機能があります?(試したことがないので詳細は不明です)
2. Method
ここからはDaniel Holden氏のLearned Motion Matching(LMM)[1]を参考に、MMのアルゴリズムについて見ていきます。LMM自体は深層学習を用いた手法となっており、従来のMMとは異なります。しかし、論文中でMotion Matchingの構造が述べられていたり、GitHubにてvanilla MMの実装も公開されているため、こちらを参考にします。
2.1 基本構造
MMの基本的な流れは図のようになっております。マッチングを行わない場合は通常のアニメーションパイプラインと同様に、次フレームのアニメーションを描画します。
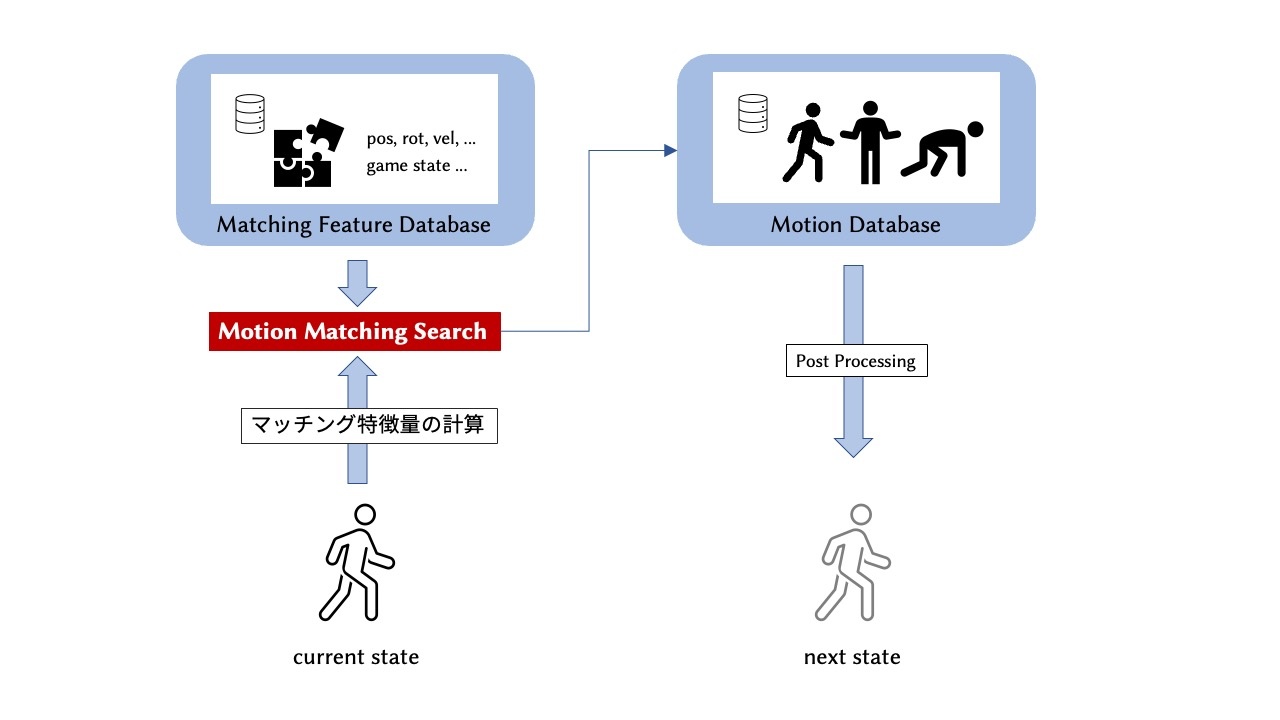
2.2 Matching Algorithm
MMでは現在再生中のアニメーションよりも適したアニメーションが存在するか判定を行います。毎フレーム探索をかけると、モーションの切り替えによるジッターが顕著になり、計算コストが大きくなるため、Nフレームごとに探索をかけることが一般的です。この特徴マッチングによる探索はリアルタイムで行う必要があり、メモリ効率の良い方法が必要となります。
まず、特徴マッチングで使用する特徴量を決定する必要があります。ここでは使用する特徴量をマッチング特徴量 (Matching Features) と呼びます。最も簡単な特徴量は関節位置や関節回転です。これらの特徴では純粋なポーズの比較を行うことが出来ます。しかしモーションは動的な要素を含むため、純粋なポーズの比較のみでは視覚的に不連続なモーションとなってしまいます。またゲームなどのインタラクティブ操作に対応するためには、ユーザーのゲームパッド入力なども考慮する必要があります。Holden氏の実装では、左右の足の位置、20フレーム先・40フレーム先などの将来の軌道、速度などをmatching featuresとして使用しています。将来の軌道はゲームパッド入力と対応付けることで、インタラクティブ操作を可能にします。これは一例で、何を特徴に使用するかは目的に応じて変化します(この部分はエンジニアリングが必要です)。
特徴マッチングでは現在再生中のアニメーションからマッチング特徴量 (query)を計算し、それをアニメーションデータベースと比較します。このときアニメーションデータベース全体でもマッチング特徴量を計算していると時間がかかるため、事前にアニメーションデータベースのマッチング特徴量をまとめたマッチングデータベースを用意することが多いです。
2.3 探索効率化
MMでは全フレームに対して探索をかけるため、アニメーションデータベースの大きさに比例して計算コストが膨大になります。ゲームなどではレンダリングなどの処理も必要になるため、できるだけMMによる計算量を減らすことが望ましいです。
Holden氏の実装では、データベース内に2つの大きさのAABB(axis-aligned bounding-box) を設けることで、計算量削減を行っています。
その他にもKD-Tree を用いるなど、マッチング高速化に使用されるアルゴリズムなどが採用されることが多いです。
2.4 ノイズ除去
MMによってアニメーションの切り替えが発生する場合、不連続であるためジッター (ノイズ)が生じることが多いです。ステートマシンなどと同様に、切り替え前と切り替え後のアニメーションのブレンドを行うことで、ノイズ除去を行うことが出来ます。また、足の接地の修正などはFootIKが用いられます。
3. 実装
インタラクティブ操作はまだできませんが、Python上でマッチング部分の実装を行い、事前に定義された経路上を動くことができるMotion Matchingの実装を行いました。database.pyにてデータベースのクラスを定義し、mm.pyではMotion Matchingのアルゴリズムを定義しています。本実装ではScipyのkd-treeを用いたものが最も早く動作しました。今回、ノイズ除去は実装していません。
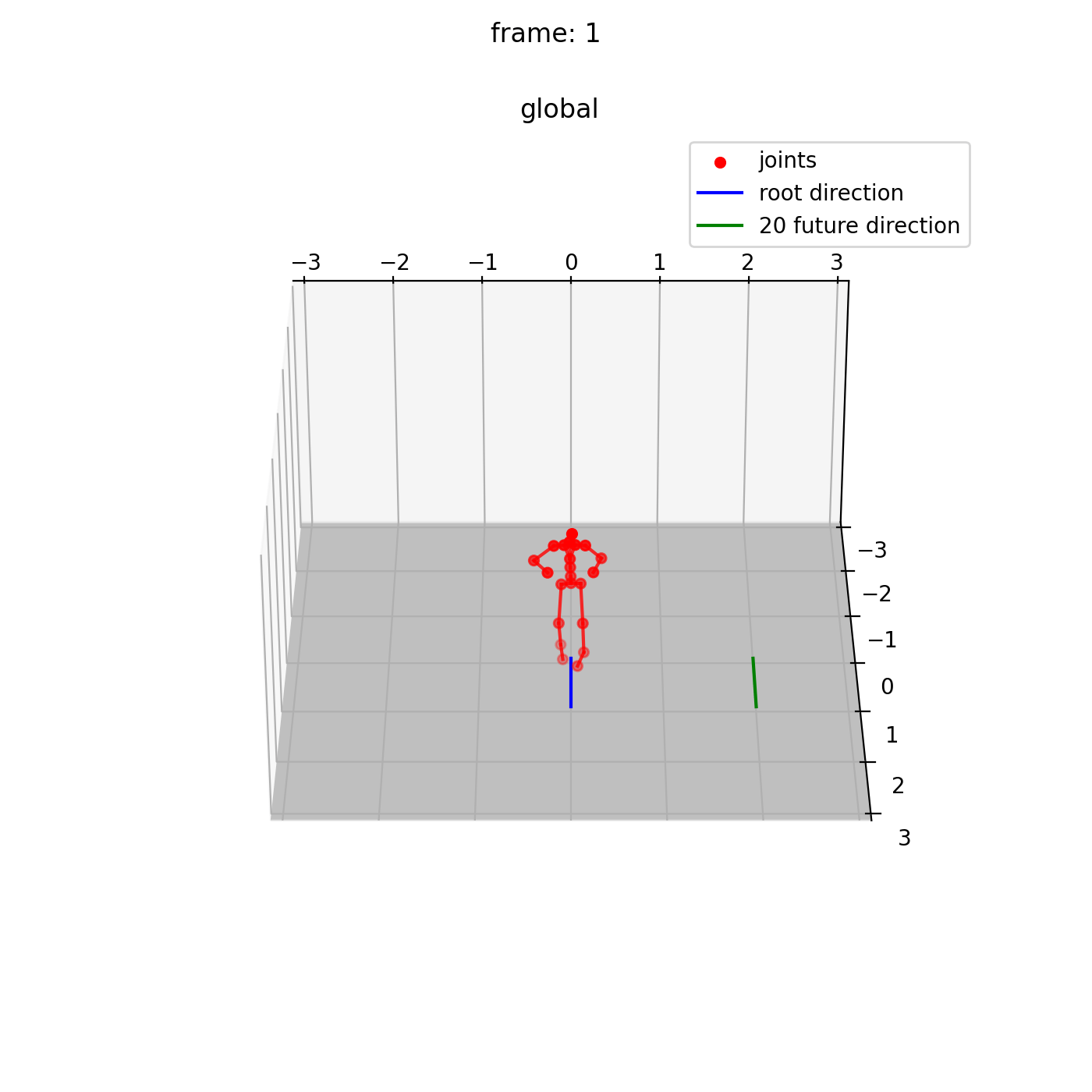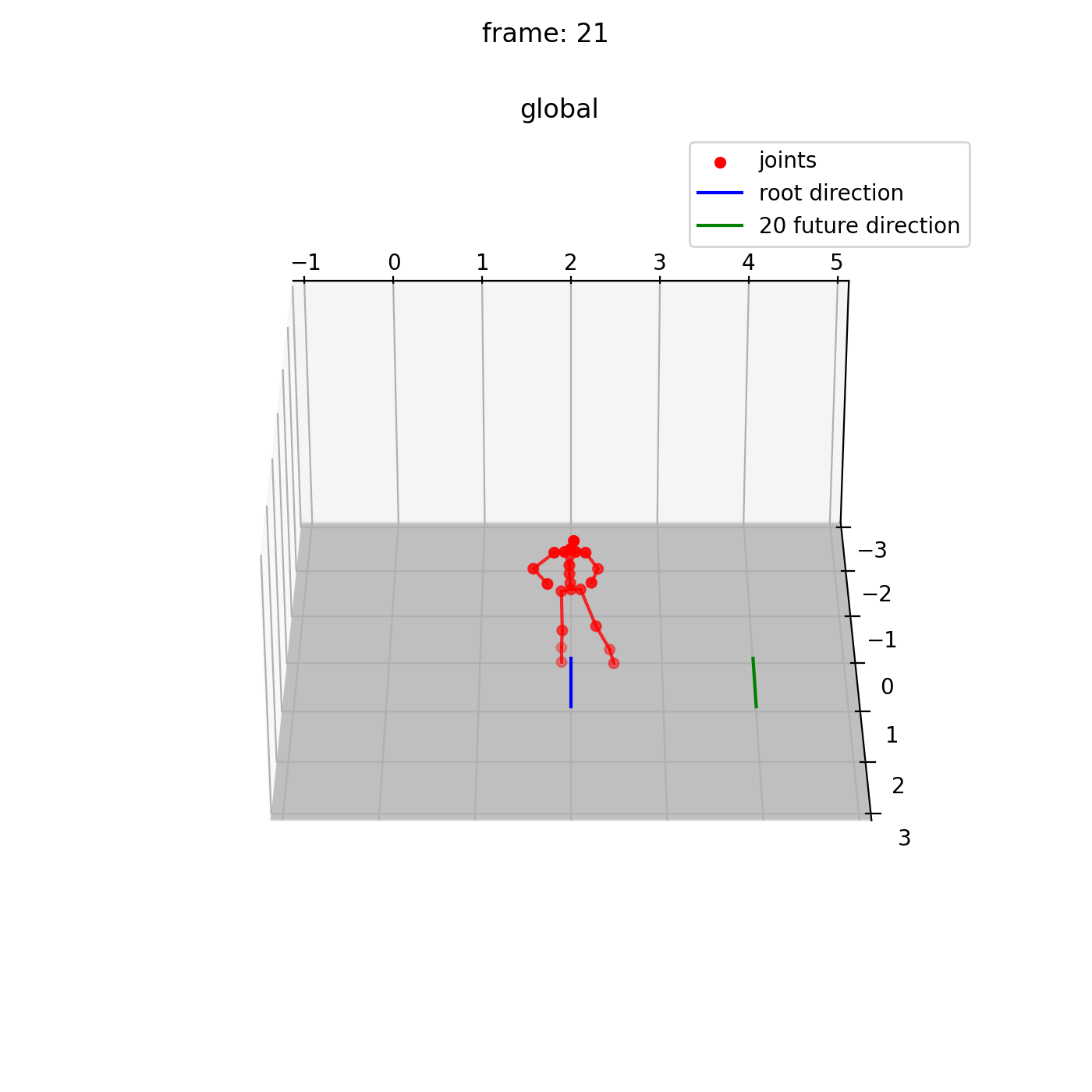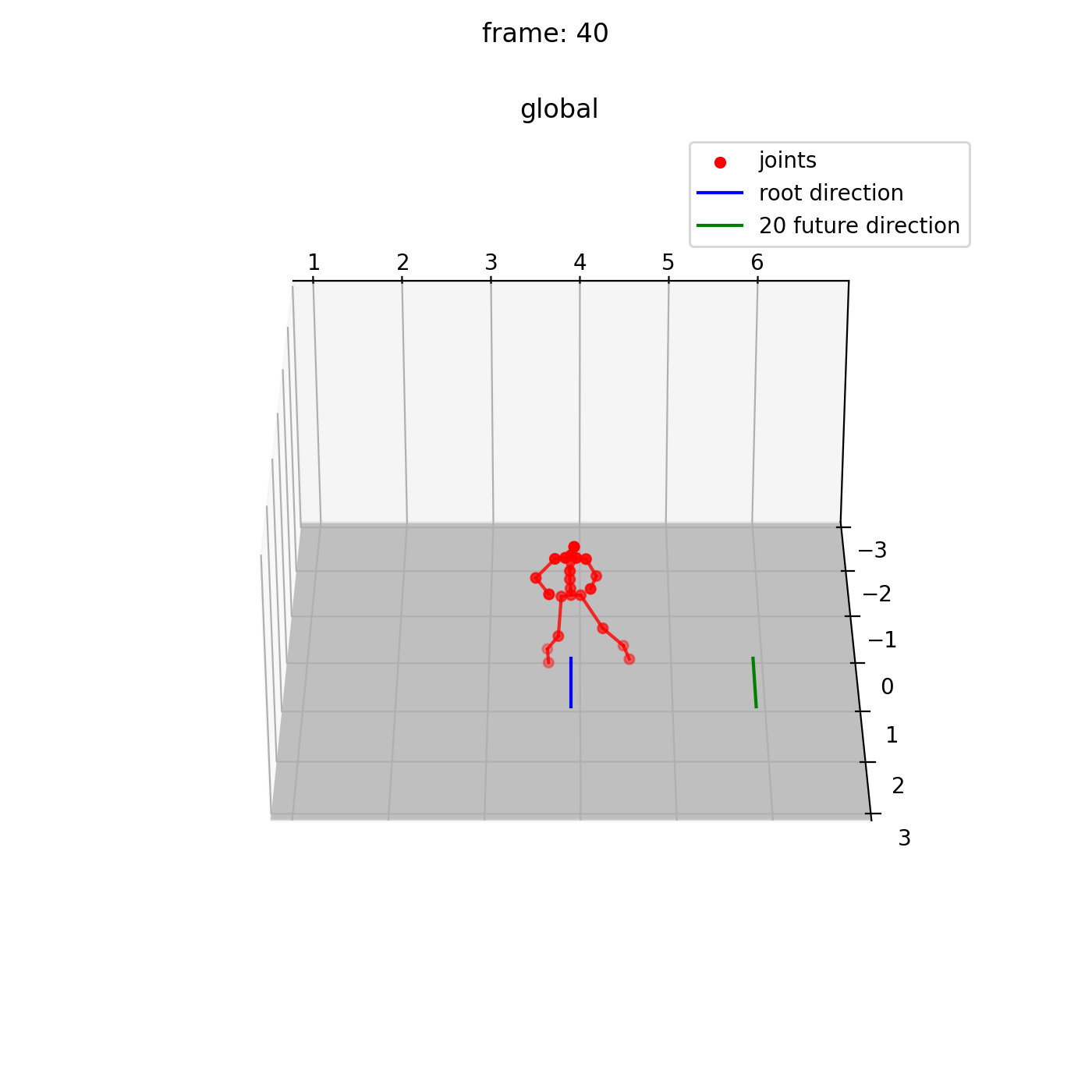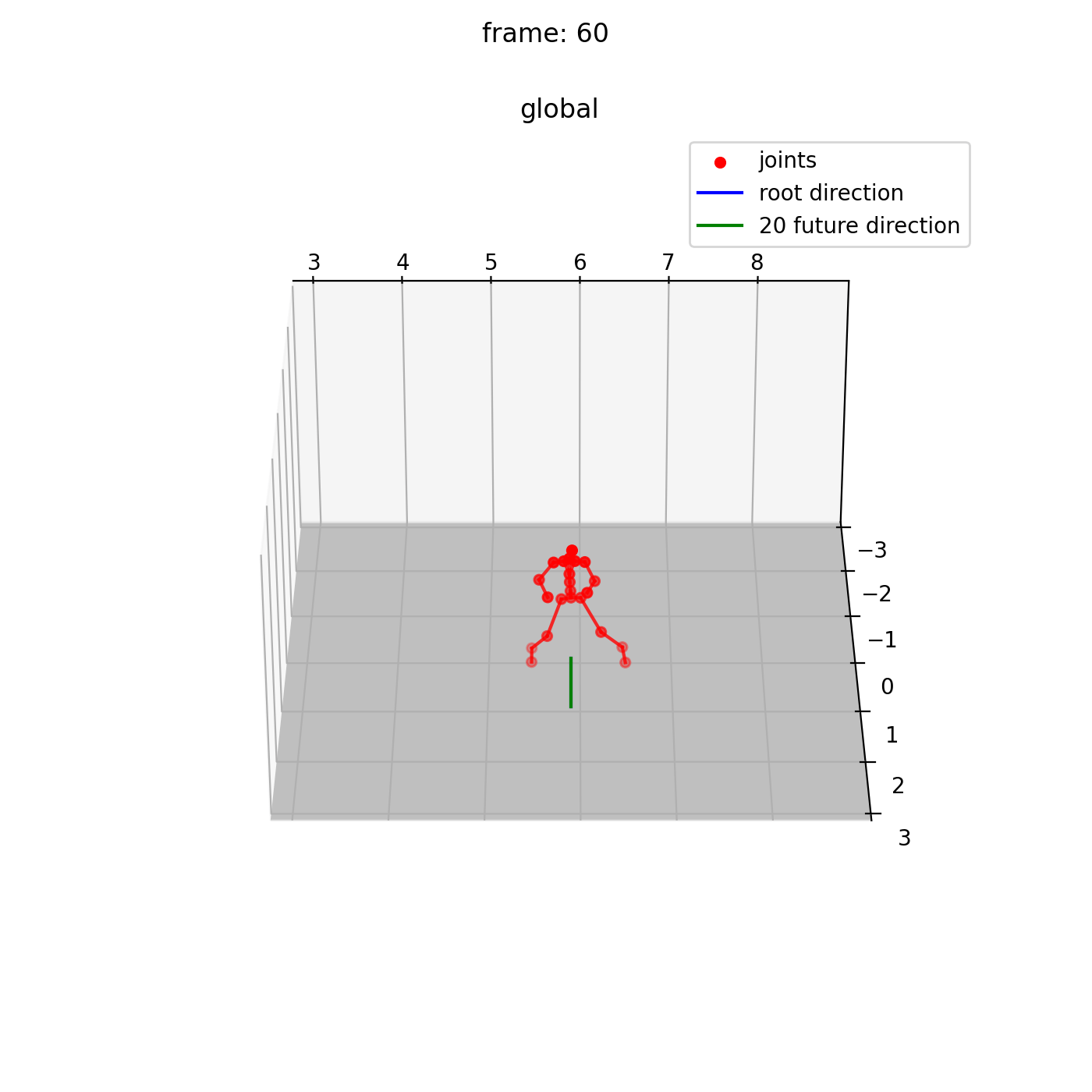
本実装によって合成された 1.前方に走るアニメーション、 2.サイドステップを行うアニメーション の例を示します。
1.前方に走るアニメーション

2.サイドステップを行うアニメーション
4. まとめ
ここまでMotion Matchingの簡単な紹介と、そのメモリ効率を良くするためにNeural Networksを用いたLearned Motion Matchingの説明を行いました。
Motion Matchingは従来のアニメーションシステムに搭載されているステートマシンのように複雑な構造を組む必要がなく、複数のアニメーションクリップからインタラクティブな操作が可能なアニメーションを生成します。
今回の例では平地のlocomotionタスクといった簡単な例を扱いましたが、実際のゲームであれば環境やモーションの種類(ジャンプする、壁を登る)なども考慮する必要があります。これらに適用するためには、対応する大量のアニメーションクリップと注意深く設計されたMatching Featuresなどが必要です。また、接触を伴う場合はInverse Kinematicsも必要となります。
最近ではアニメーションクリップを使用しないProcedural Animationも流行っているため、今後その動向などを調べていきたいと思います。
5. おまけ
LMMについて
Motion Matchingは数フレーム置きに特徴マッチングを行い、適したフレームの再生を行うので、データベース上全てのアニメーションデータと特徴ベクトルが常にメモリ上に存在する問題があります。数個のアニメーションデータであればそれほどメモリを必要としませんが、AAAタイトルなど高品質の作品では、何GBものメモリが必要になる場合も存在します。しかしながらゲームでアニメーションに割けるリソースはあまり多くありません。
そこでNeural Networksを用いることで、メモリ削減を行うLMMが提案されました。
Learned Motion Matching(LMM)
これはSIGGRAPH2020で発表された、当時UBIに所属していたDaniel Holden氏が書かれた論文です。ソースコードも存在するため、実際に試すことも可能です。
この手法では、3つのネットワークによって従来のMMからアニメーションデータベースを排除しています。
以下ではこのネットワーク構造を簡潔に説明します。
Decompressor
DecompressorではCombined Features(Matching Features + Additional Features)から完全なアニメーション(Full Pose)を生成します。
従来のMMでは、Matching Featuresをクエリとしてデータベースへアクセスし、そこからFull Poseを引っ張っていましたが、Decompressorを用いることでデータベースへのアクセスを排除できます。しかし、従来のMatching FeaturesだけではFull poseの復元が困難なため、Additional Features(追加情報)を加えることで復元を可能にします。
このネットワークはCompressor(Encoder)とDecompressor(Decoder)を用いたAutoEncoderの構造で学習されます。Additional FeaturesはCompressorによって、Full Poseから抽出される追加特徴量になります。学習の際にはCompressorとDecompressorが同時に学習され、Matching Featuresだけでは復元に不足している特徴がAdditional Featuresとして学習されるイメージです。
Stepper
Stepperは前フレームのCombined Featuresから、次フレームのCombined Featuresを生成します。
従来のMMでは、毎フレームデータベースにアクセスして次のフレームを取得していたため、それを排除します。このネットワークは、かなりデータセットに依存していると思われます。
正直この部分は毎フレームアクセスするのではなく、一度に5フレームくらい予測したほうが効率がいい気がします。
Projector
Projectorは上の2つと異なり、Nフレームごと(もしくは入力が著しく変化したとき)に使用されるネットワークで、従来のMMにおけるマッチング部分を担当しています。
これはランタイム上アニメーションの特徴(query)から、次フレームのCombined Featuresを生成します。これによってMatching featuresデータベースが不必要となります。
ProjectorとDecompressorを組み合わせるとqueryから直接Full Poseを得ることができますが、従来のMMのような構造を取るために、このような構造をとっていると思われます。
QueryとMatching Featuresの要素は同じため、Additional Featuresのみを生成してもCombined Featuresを作れそうですが、ProjectorはCombined Features全体を生成します。これはquery部分も一部編集されるイメージでしょうか。
Stepperではランタイム上の情報は見ずに次の特徴を生成していますが、Projectorはユーザー入力などのランタイム情報(ゲームパッド入力など)を受け取って、次の特徴を生成します。なのでStepperは今のアニメーションをそのまま続けるイメージで、Projectorはアニメーションの切り替えを行うイメージです。
総評
これらのネットワークはある意味、ネットワークをデータベースにオーバーフィットさせることで、正確なアニメーションの再現を可能にしている印象があります。そのため、データベースに存在しないアニメーションをつくることは難しいと思われます。これは生成モデルの強みを一部減らしているように思われますが、Motion Matchingの目的では相応しい方法だと思います。
少ない特徴量でFull poseアニメーションを表現する研究では、最近出てきたDeep Phaseなどが印象的です。実際にHolden氏もDeep Phaseの特徴量をLMMに組み込もうとしています。実装を見てみると、Matching Featuresにおける足の速度(3次元×2)、ルートの速度(3次元)がPhase Features(16次元)に変わっています。
6.参考文献
-
Learned Motion Matching, Holden et al., SIGGRAPH2020
https://dl.acm.org/doi/abs/10.1145/3386569.3392440 ↩︎
Discussion