アリババクラウドのオープンソースLLM(Qwen)が2.0から2.5へバージョンアップ!!


本記事は以下の公式ブログを参考にしています。
はじめに
前回のQwen2.0リリースから約3ヶ月が経ち、2024年9月19日にQwen2.5が新たにリリースされました!今回のリリースでは、ベースLLMであるQwen2.5だけでなく、コーディング専用モデルであるQwen2.5-Coderと、数学専用モデルであるQwen2.5-Mathもリリースされました。すべてのモデルはデコーダーのみで構成されており、以下のような様々なサイズが利用可能です:
- Qwen2.5:0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B
- Qwen2.5-Coder:1.5B, 7B, 32B(準備中)
- Qwen2.5-Math:1.5B, 7B, 72B
ライセンス
Qwen2.5-3BとQwen2.5-72Bはそれぞれ、Qwen Research LicenseとQwen Licenseによって管理されていますが、それ以外のモデルはApache2.0ライセンスに基づいています。
特徴
トークン数
Qwen2.5は最新の大規模データセットで事前トレーニングされており、最大18兆のトークンを保有しています。
トークン長
Qwen2同様、Qwen2.5言語モデルは最大128Kのトークンをサポートし、最大8Kのトークンを生成することができます。
多言語対応
日本語、中国語、英語、フランス語、スペイン語、ポルトガル語、ドイツ語、イタリア語、ロシア語、朝鮮語、ベトナム語、タイ語、アラビア語など、29以上の言語に対応しています。
理解能力
Qwen2と比較すると、Qwen2.5は著しく多くの知識を獲得し(MMLU: 85+)、プログラミング(HumanEval 85+)や数学(MATH 80+)における性能が大幅に向上しています。また、長いテキスト生成(8,000トークン以上)、構造化データ(例えばテーブル)の理解、特にJSONなどの構造化出力を生成する能力においても顯著な改善を遂げています。
チャットボット機能
様々な形のシステムプロンプトに対応することができ、チャットボットとしてのロールプレイ実装や条件設定などの機能が強化されています。
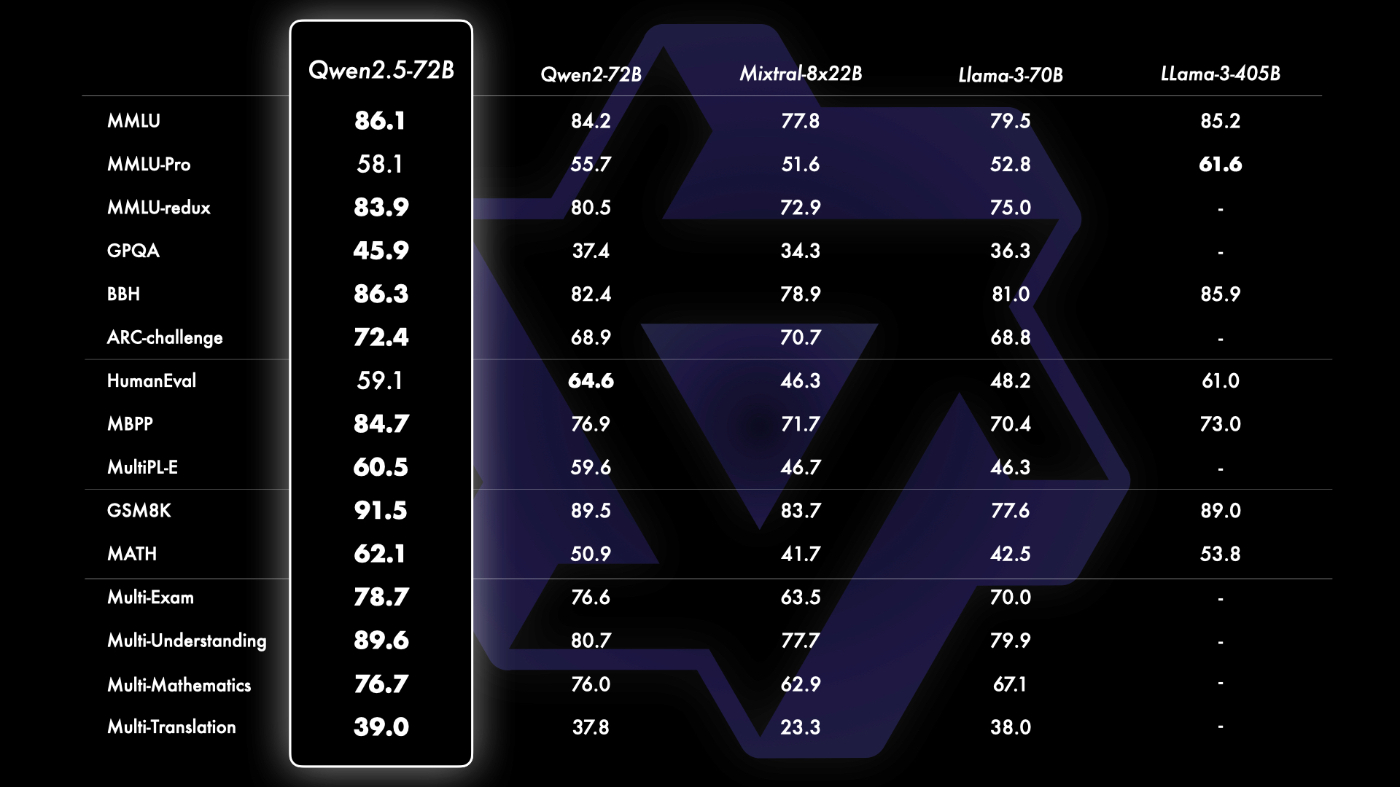
パフォーマンス
Instruction TuningされたLLMだけでなく、ベースLLMもLlama-3-405Bなどの大きなモデルに対して最上位の性能を達成していることを確認することができました。

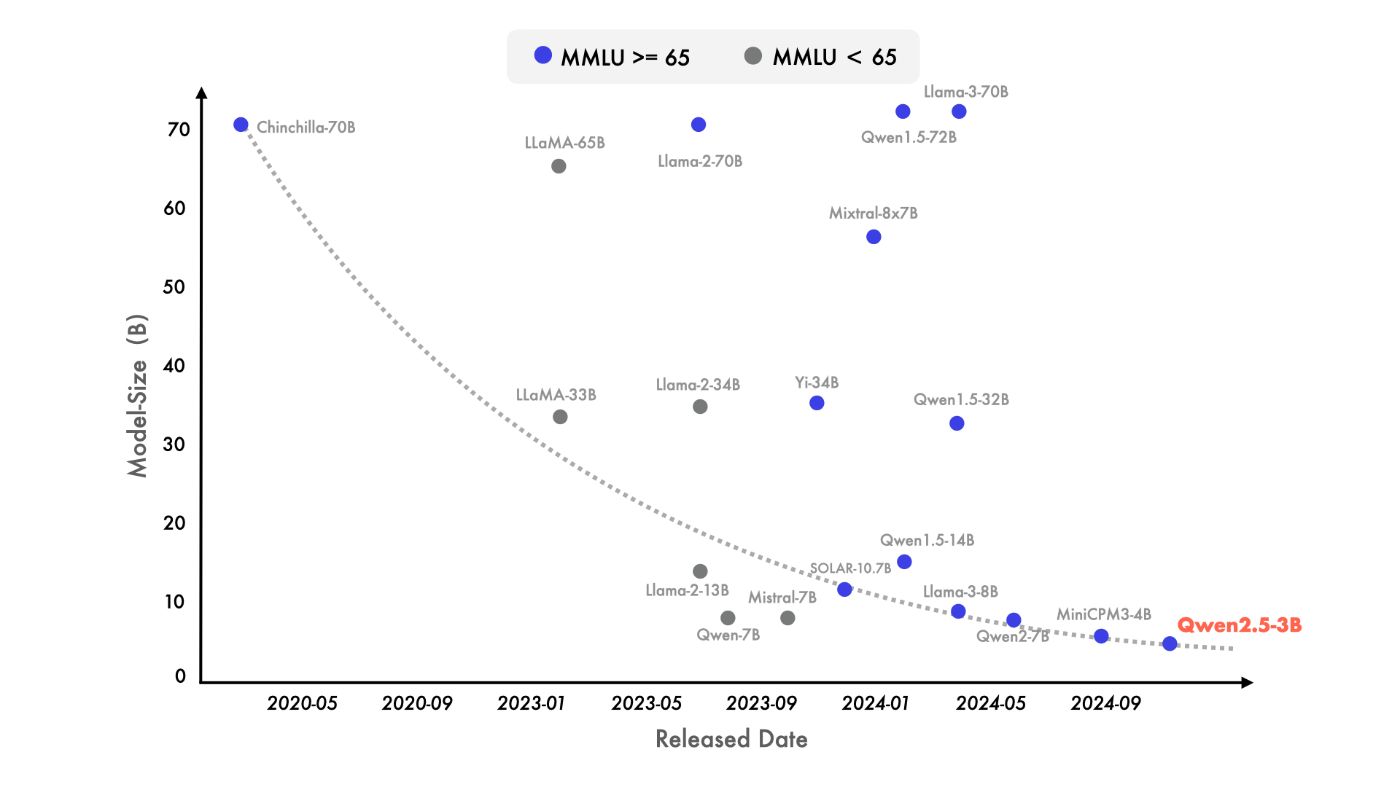
小規模言語モデル(SLM)
最近では、小型言語モデル(SLMs)への注目が高まっています。歴史的に見れば、SLMsは大規模言語モデル(LLMs)に追随していたものの、そのパフォーマンス格差は急速に縮小しています。驚くべきことに、わずか30億個のパラメーターを持つモデルでさえ、現在非常に競争力のある結果を出しています。以下の図は、MMLUでスコア65以上を達成する新しいモデルがますます小さくなり、言語モデルにおける知識密度の急増を浮き彫りにした重要な傾向を示しています。特にQwen2.5-3Bは、約30億個のパラメーターだけで卓越したパフォーマンスを達成し、その効率性と能力は他のSLMと比較しても際立っています。
使い方
最も簡単な使用方法は、Hugging Face Transformerを使用することです。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-7B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
ツール連携
Qwenは様々なオープンソースツールと連携されています。
- Hugging Face Transformers
- Finetuning: Peft, ChatLearn, Llama-Factory, Axolotl, Firefly, Swift, XTuner, Unsloth, Liger Kernel
- Quantization: AutoGPTQ, AutoAWQ, Neural Compressor
- Deployment: vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI, Xinference
- API Platforms: Together, Fireworks, OpenRouter, Sillicon Flow
- Local Run: MLX, Llama.cpp, Ollama, LM Studio, Jan
- Agent and RAG Frameworks: Dify, LlamaIndex, CrewAI
- Evaluation: LMSys, OpenCompass, Open LLM Leaderboard
- Model Training: Arcee AI, Sailor, Dolphin, Openbuddy
一緒にオープンソースAIコミュニティの研究開発を推進し、これまで以上に革新的なものにしていきましょう!
Discussion