QVQ-Max公式ブログ日本語まとめ



QVQ-Max: 証拠とともに考えるAI
本記事は以下の公式ブログを参考にしています。
はじめに
昨年12月、私たちは試験的モデルとして「QVQ-72B-Preview」をリリースしましたが、多くの課題がありました。そして本日、視覚的推論モデル「QVQ-Max」の正式な初版をリリースします。このモデルは、画像や動画の内容を“理解”するだけでなく、それらの情報を解析・推論して解決策を提示することができます。
数学の問題から日常的な質問、プログラムコードからアートの創作に至るまで、QVQ-Maxは驚異的な性能を示しました。これはまだ初期バージョンに過ぎませんが、そのポテンシャルは非常に魅力的です。
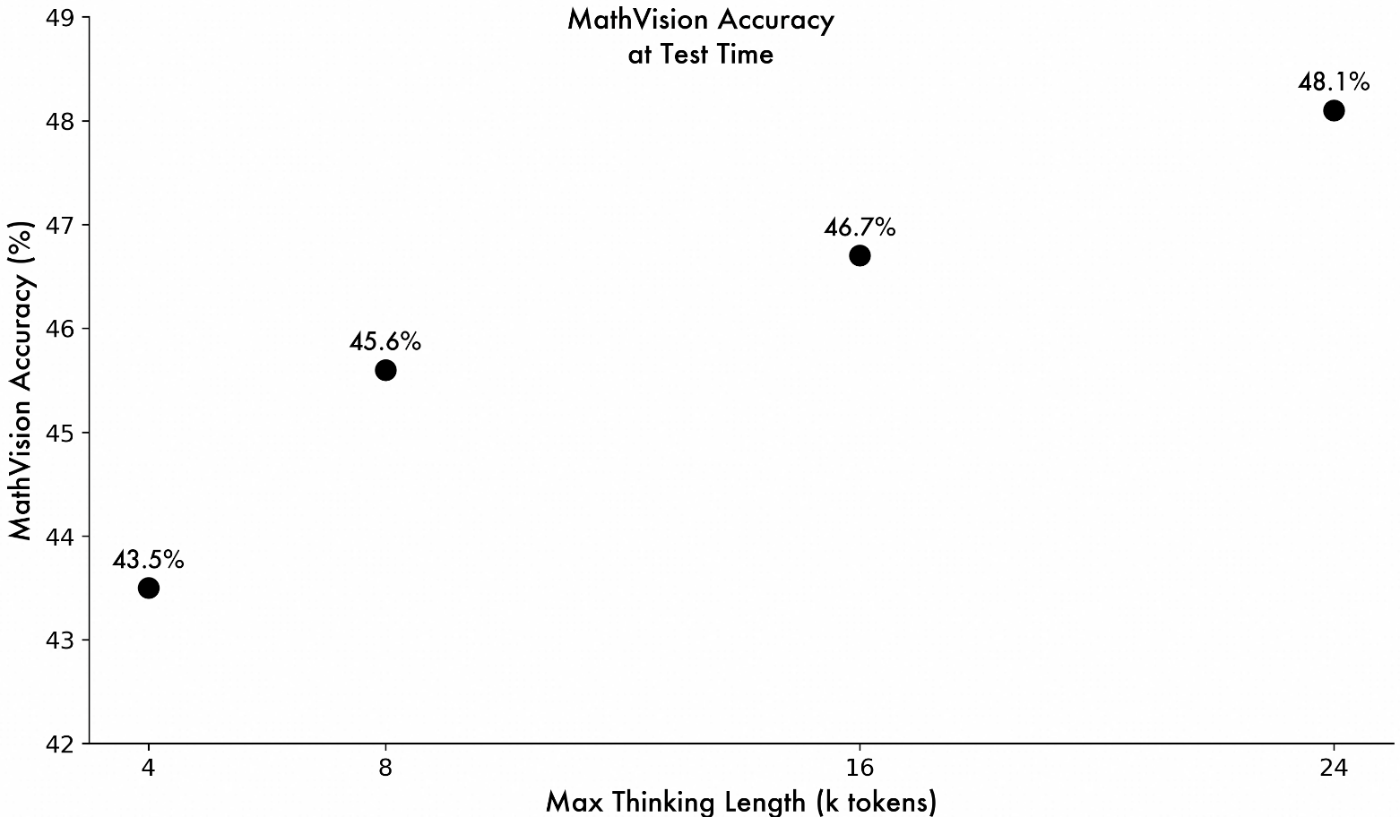
MathVisionでの性能
MathVisionは、難易度の高いマルチモーダルな数学問題を集めたベンチマークであり、複雑な数学問題を解くAIモデルの能力を評価します。下図に示されるように、モデルの思考プロセスの最大長を調整することで、MathVisionでの正答率が継続的に向上することが確認され、QVQ-Maxの可能性の高さが伺えます。
QVQ-Maxの設計思想
このセクションでは、QVQ-Maxの設計思想、その能力、そして私たちの生活にどのように役立つかについて解説します。
なぜ視覚的推論が必要なのか?
従来のAIモデルは、質問応答、文章生成、コード生成など、主にテキスト入力に依存していました。しかし現実世界では、多くの情報が言葉ではなく、画像、図表、動画などで表現されています。
画像には色、形、空間的関係などの豊かな情報が含まれ、これらは直感的であると同時に、テキストよりもはるかに複雑です。
例えば、建築図面が妥当かどうかを判断するには、テキストによる説明だけでは不十分かもしれません。しかし、実際の図面を視覚的に見て、専門知識を使って分析できれば、そのタスクは格段に容易になります。
このように、視覚的推論はAIが単に「見る」だけでなく、「理解し、考える」ことを可能にします。
私たちがQVQ-Maxに込めた目標はシンプルです:鋭い観察力と素早い思考力を持つアシスタントを作ること。それにより、ユーザーが直面するさまざまな実用的課題を解決できるようにしました。
コア機能:観察から推論へ
QVQ-Maxの能力は、以下の3つの領域に分類できます:
1. 精密な観察力:細部まで把握
QVQ-Maxは、複雑な図表から日常のスナップ写真まで、画像を正確に解析する力を持っています。画像中の主要な要素を特定し、物体やテキストラベル、小さな見落としがちなポイントまでも抽出できます。
2. 深い推論力:「見る」だけでなく「考える」
画像の内容を認識するだけでなく、それに基づいた解析や背景知識との統合を通じて結論を導き出せます。例えば、幾何学の問題では図を参照しながら答えを導き出し、動画では次に起こり得ることを予測することもできます。
3. 柔軟な応用力:課題解決から創造まで
分析・推論にとどまらず、イラストの設計支援、短編動画スクリプトの生成、RPG風のコンテンツ創作などにも応用可能です。ラフなスケッチをアップロードすれば、完成度の高い作品に仕上げてくれるかもしれません。普通の写真をアップすれば、批評家や占い師のように振る舞うこともできます。
デモケース
QVQ-Maxは、学習、仕事、日常生活など、あらゆる場面で活用できます。
- ビジネスツール:データ分析や情報整理、さらにはコード作成まで支援します。
- 学習アシスタント:特に図を伴う数学や物理の問題解決に強く、複雑な概念も直感的に解説します。
- 生活サポート:クローゼットの写真をもとに服のコーディネートを提案したり、レシピ画像から料理の手順をガイドしてくれます。
今後の展望:次のステップへ
現在のQVQ-Maxは初期バージョンに過ぎず、今後さらなる改善を予定しています。特に以下の点に注力していきます:
- より正確な観察:グラウンディング技術により、視覚情報の認識精度を高めます。
- ビジュアルエージェント化:スマートフォンやPCの操作、ゲームプレイなど、より複雑なマルチステップタスクへの対応力を強化します。
- 高度な対話機能:テキストにとどまらず、ツール連携や画像生成など、多様なモダリティとの連携でユーザー体験を豊かにします。
QVQ-Maxは、視覚と知性を兼ね備えた“視覚的推論モデル”です。画像の内容を認識するだけでなく、それをもとに分析・推論・創作までこなします。まだ成長過程にあるとはいえ、既に大きな可能性を見せており、今後の進化によって現実の課題解決を支援する真のビジュアルエージェントとなることを目指しています。
Discussion