自己相関副問い合わせ(自己相関サブクエリ)はどのような流れで処理を行なっているのか?
例)SELECT within SELECT Tutorial/ja - SQLZOO
SELECT continent, name, population FROM world x
WHERE population >= ALL
(SELECT population FROM world y
WHERE y.continent=x.continent
AND population>0)
相関サブクエリーの利用
相関サブクエリーの2重ループの様に機能する: 内側のサブクエリーは一度に1行ずつ外側のクエリーの関連するレコードにアクセスする。内と外で同じ名前のテーブルを区別するテクニックとして、外側のクエリーのテーブルと内側のサブクエリーのテーブルの名前を付け替える(訳注:この例では 外側の world を x とし、内側の world を y として、y.continent=x.continent で外側でアクセスしているx.continentの値と同じy.continentのレコードを内側のサブクエリーで処理する。)。
WHERE 節の2つのテーブルへの参照の解釈は、”関連する値が同じである”と考える。
ここの例は、“大陸が同じ各国の人口と比べてより大きいか等しいような人口を持つ国をworldから選ぶ”となる。
処理の流れを考察->違うらしい。
1. メインクエリ:worldテーブルにアクセスする。特定のcontinent(一番上のフィールドのcontinentになる?)にアクセスする。
2. サブクエリ:populationが0より大きい、かつメインクエリがアクセス中のcontinentのpopulationをworldテーブルから取得する
3. メインクエリ:サブクエリが取得したテーブル(アクセス中のcontinentのpopulation一覧テーブル)の中で最もpopulationが大きいフィールドの、continent, name, populationを取得。
4. メインクエリ:最初にアクセスしたのとは別のcontinentにアクセスする
5. 以降2~3を繰り返す。
処理の流れについて詳しい人に聞いて理解できた部分
これが実質的に何をしているかというと、
サブクエリのWHERE y.continent=x.continentの部分でinner join on continentを行っているイメージらしい
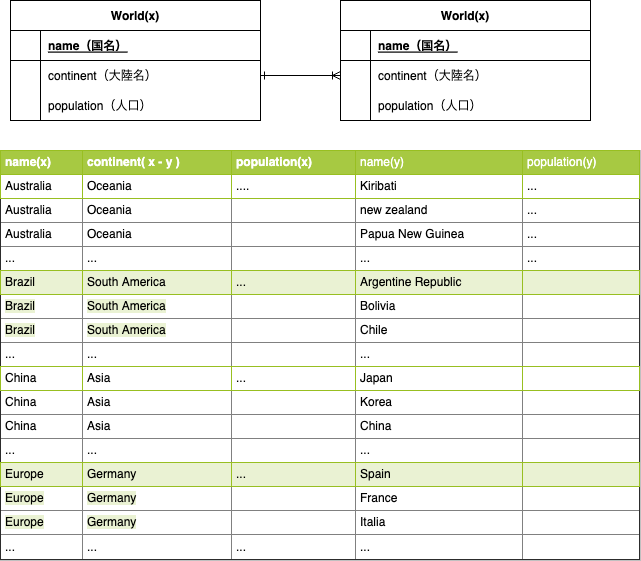
-
worldテーブル(x)とworldテーブル(y)をcontinentで結合する - すると、
world(x)テーブルの各レコードのcontinentと一致するworld(y)のカラム・レコードが結合される(下図のイメージ) -
ALL演算子により、結合されたworld(y)テーブルのpopulationカラムのどの値よりも大きなpopulationを持つworld(x)テーブルのレコードのみチョイスされる。