Amazon OpenSearch Serverless(Preview)を学ぶ
2022/11/29 Amazon OpenSearch Serverless が Preview リリースされました。
従来のプロビジョニング型の OpenSearch Service と比べて以下の特徴を持っています。
- 必要なリソースを高速に AutoScaling できる
- 利用料金がオンデマンド(消費したリソースのみ)になる
- アーキテクチャの変更
- コンピュートとストレージの分離
- インデキシングとクエリのコンポーネントの分離
- ストレージに S3 を利用
公式ドキュメントを中心に動作確認しながら学習します。
TLDR
- 従来の OpenSearch Service と比較して
- メリット
- 負荷に応じて自動でスケール
- スケールが早い
- 利用分だけの支払い
- インデックス、クエリの性能がそれぞれ確保される
- ほとんどが自動化されているので設定、運用が楽
- デメリット
- CPU/メモリ単価が高いので安くなるとは限らない
- 運用コストの省力化含めて検討しても
- 性能面に不安を感じる
- リフレッシュ速度
- スループット
- 利用できる機能が少ない
- API の制限が多い
- OpenSearch 独自のプラグインは利用できない
- CPU/メモリ単価が高いので安くなるとは限らない
- メリット
構築手順
クラスタ(コレクション)作成手順は設定項目はそんなに変わっていない。
クラスタはコレクションという名前に変わった?クラスタ≒コレクションなのか?
- コレクションタイプ
- タイムシリーズ、もしくは検索
- この選択により何が変わるんだろう?
- 暗号化設定
- AWS が提供するキー、もしくは KMS で独自のキーを利用可能
- コレクション毎に指定可能
- ネットワーク設定
- Public、もしくは VPC
- VPC はノードのネットワークが VPC にあるのではなく、VPC Endoint 経由でのアクセス?
- プロビジョニング型も同じ?
- アクセスポリシー
- インデックスレベル?コレクションレベル?でのアクセスポリシーを指定可能
- 若干従来のポリシーの記法と異なる?
- SAML 連携認証
設定画面だけざっくり見比べてみたところ、以下ができなくなっている?
- バージョン指定
- 今は 2.3 だけだから?
- カスタムエンドポイント
- ドメイン指定、ACM 連携
- UltraWarm データノード
- Tiering の概念自体なくなる
- Serverless 自体が S3 使ってて UltraWarm みたいなもんだしな
- AutoTune の有効無効指定
- 基本有効なのかな
- 自動 Snapshot
- Cognito 連携
公式ドキュメント
- プロビジョニング型と比較して、自動でスケールする
- 使用頻度が低い、断続的、または予測不可能なワークロードに対して、シンプルでコスト効率が高い
- プロビジョニング型よりシンプル
- 多くが自動化され、設定要素が減り、考えることが減る
- バージョンアップも自動?
- 高コスト効率
- 消費したリソースに対してのみの費用
- ピークに備えた余剰リソースの費用が発生しない
- 高可用性
- 常に AZ レベル、ノードレベルで冗長性が担保される
- 自動スケール
- 高速なインデキシングスループット、クエリ応答時間を維持
Amazon OpenSearch Serverless とは?
- 現在は OpenSearch 2.3
- 主な 2つのユースケース
- ログ解析
- 全文検索
アーキテクチャ
- インジェストとクエリのインスタンスは別
- インデキシング負荷によってクエリが遅くなることはない
- データストレージは S3
- インジェストインスタンスはデータを受け取るとインデキシング処理をして、S3 にアップロード
- クエリインスタンスはクエリを受け取ると S3 からダウンロードして検索・集計処理する
- インスタンスでキャッシュしない
- (性能が著しく低下しないか?)
- データが S3 にあるのでクエリがスケールしても relocation の負荷が発生しない?
- Serverless の処理能力は OCU(OpenSearch Compute Unit) で管理
- 1OCU = 6GiB メモリ、対応する vCPU(vCPU 数は固定じゃない?)、180GiB の S3 データ容量
- 最小は 4OCU?インジェスト、クエリで 1OCU づつ。高可用性を確保するため、別の AZ にスタンバイノードを起動する。
- 設定画面だと 2OCUも選択できる
コレクションタイプ
- コレクションタイプで最適なデータ配置を可能にする
- コレクションタイプに検索とタイムシリーズを指定可能
- 検索を指定すると、すべてのデータがホットストレージに配置する
- タイムシリーズを選択すると、ホットストレージとウォームストレージを組み合わせてデータ配置する
価格体系
- 以下のコンポーネントに対して課金が発生する
- インジェスト、クエリの OCU
- $0.24/OCU per 1時間
- S3 のストレージ保持
- $0.24/1GiB per 1ヶ月
- インジェスト、クエリの OCU
- OpenSearch Dashboard は無料
- プロビジョニング型との単価比較
- Service:r6g.large(東京リージョン)だと 16GiB メモリで $0.202
- Serverless:2OCU だと 12GiBメモリで $0.48
- ちゃんと価格計算して採用しないと逆に高くなるケースも多そう
- ミニマムコスト
- OCU
- 0.24 * 24 * 30 * 4 = $691.2
- 高い。。
- 採用するとしても検証環境はプロビジョニング、本番環境は Serverless みたいになるのか
- S3 のストレージ料金
- 100GB の場合、$24
- OCU
制限
- 利用できない OpenSearch の API がある
- プロビジョニング型はすべて利用可
- 利用できない OpenSearch の Plugin がある
- プロビジョニングと別?
- プロビジョニング型から Serverless への自動的な移行はない
- _reindex で可能
- クロスアカウントでアクセスできない
- カスタムプラグインはサポートされない
- Snapshot が利用できない
- クロスリージョンサーチ、レプリケーションできない
- リフレッシュインターバルが 10〜30秒ぐらいになる場合もある
OpenSearch Service との比較
従来のプロビジョニング型を OpenSearch Service、Serverless を OpenSearch Serverless の呼び方で区別しているらしい
| 機能 | OpenSearch Service | OpenSearch Serverless |
|---|---|---|
| Domain と Collection | Domain は OpenSearch のクラスタ | Collection は特定のワークロードやユースケースを表すインデックスのグループ |
| ノードの種類やキャパシティ管理 | 要件を満たすインスタンスタイプやストレージ容量を計算 | 最小、最大だけ決めて自動でスケール |
| 課金 | 割り当てたインスタンス、EBS の料金 | 自動スケールで利用した OCU、S3 ストレージ容量 |
| 暗号化 | 有効/無効を選択 | 必ず有効 |
| アクセスポリシー | クラスタレベルで IAM ポリシー | コレクションレベルで独自のポリシー |
| サポートする OpenSearch API | すべての API を利用可 | 利用できない API あり |
| Dashboard ログイン | ユーザー名、パスワード | IAM アクセスキー/シークレット? |
| AWS API | 従来通り | Serverless は従来とは別の API |
| ネットワーク | OpenSearchとDashboard は同じエンドポイント | OpenSearchとDashboard は別エンドポイント Dashboard を利用しないことも選択可 |
| AWS 認証を利用した OpenSearch API リクエスト | Signature Version 4 で認証情報生成してヘッダにセット | 基本同じ。少し実装方法が変わる? |
| OpenSearch バージョン | 手動でアップグレード アップグレードが問題ないかはユーザーが Changelog などで確認 |
自動アップグレード Breaking Change があったらどうなる? |
| ソフトウェアアップデート | 手動でアップデート | 自動でアップデート |
| VPC アクセス | ノードを VPC 内に構築可能 | VPC エンドポイントを作成してアクセス |
| SAML 連携認証 | ドメイン単位で設定 | アカウントレベルの SAML providers とアクセスポリシーを連携して設定 |
利用可能リージョン(2022/11/30時点)
東京リージョンを含む 5リージョン
Get Started
最小設定だと以下の 3ステップで OpenSearch Serverless の Dashboard にログインできる。
- IAM ユーザー作成(フル権限を持つ IAM ユーザーがいれば不要な手順)
- コレクション作成
- Dashboard へのアクセス&ログイン
続いて以下の 2ステップでデータの登録や検索ができる。
- アクセスポリシー設定
- Dev Tools でデータ登録、検索
IAM ユーザー作成
Dashboard にログインするには IAM ユーザーのアクセスキーとシークレットキーが必要になる。
ログインするだけであれば Permission を持たない IAM ユーザーを作成して、アクセスキーとシークレットキーを払い出すだけでいい。
コレクション作成
簡単に試すだけなので Collection name を適当に入力し、Collection Type を Search、Access type を Public にして Create する。
Collection 作成までに数分かかるので Status が Active になるまで待つ。
Dashboard へのアクセス&ログイン
Endpoint の OpenSearch Dashboards URL の URL にブラウザからアクセスする。

ログイン画面に IAM ユーザーのアクセスキー、シークレットキーを入力してログインする。
説明書きにある通り、アクセスキー、シークレットキーはサーバーには送信されず、ローカルで署名を作成して、署名がサーバーに送信される。
アクセスポリシー設定
[
{
"Rules": [
{
"Resource": [
"index/COLLECTIONNAME/*"
],
"Permission": [
"aoss:CreateIndex",
"aoss:DeleteIndex",
"aoss:UpdateIndex",
"aoss:DescribeIndex",
"aoss:ReadDocument",
"aoss:WriteDocument"
],
"ResourceType": "index"
}
],
"Principal": [
"arn:aws:iam::XXXXXXXX:user/USERNAME"
]
}
]
Dev Tools でデータ登録、検索
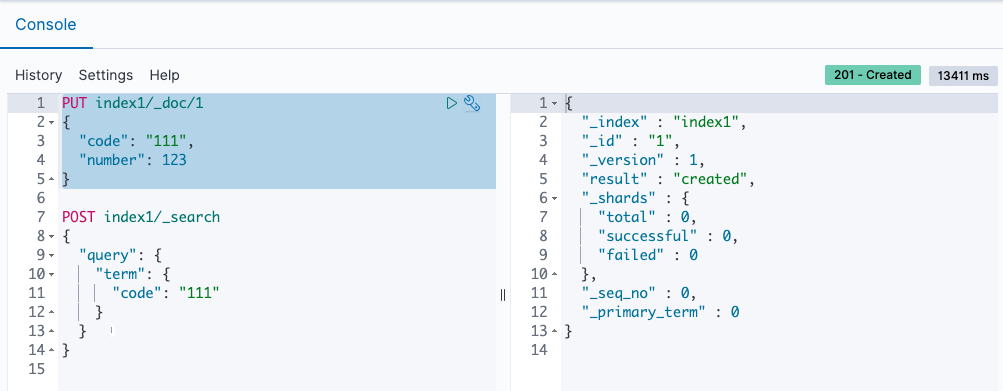
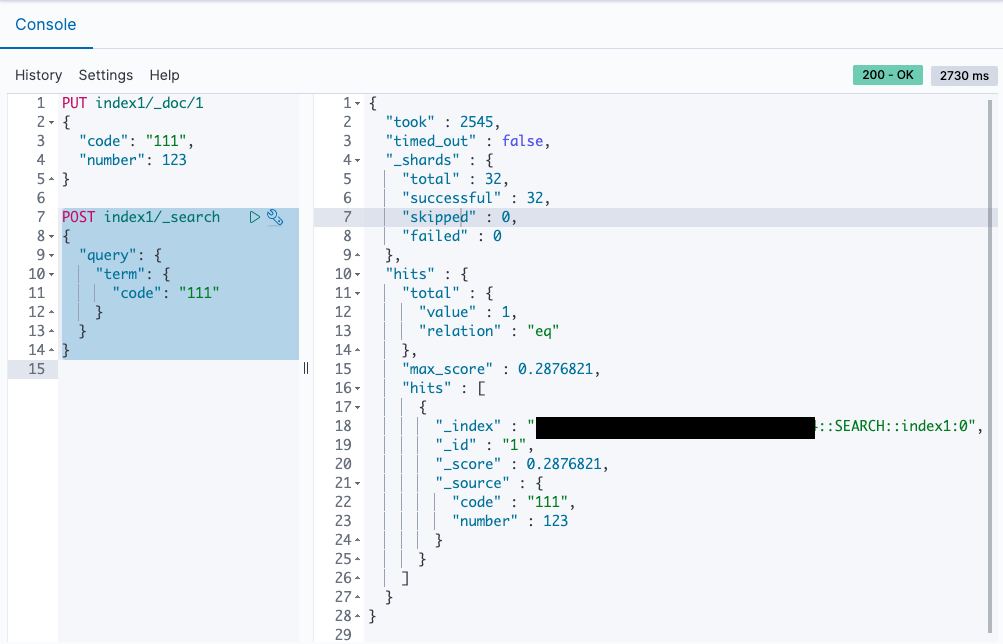
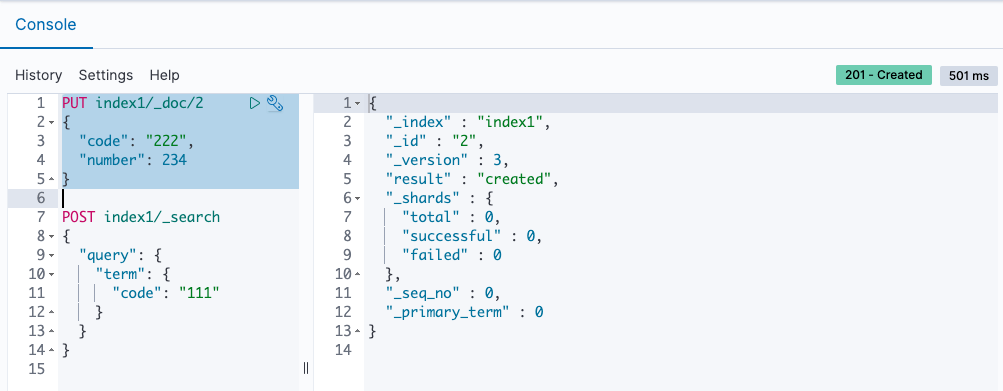
Dev Tools を開いて、データを登録、検索できます。
初回インデックスと初回検索が非常に遅いのと、2回目以降も遅い気がする。
アーキテクチャ的に仕方ない部分もありそうだけど、性能試験をちゃんとした方が良さそう。
登録から検索で返ってくるまでのラグは何回か手動で試してみたけどどんなに小さいデータでも 3秒〜10秒ぐらいはありそう。別途スクリプト組んで計測してみる。
- データ登録(初回)
- 検索(初回)
- データ登録(2回目)
- 検索(2回目)
キャパシティ制限
検索するデータは hot storage?と S3 に配置する。ほとんどは hot storage に配置する。
(一回目の検索で S3 から hot storage に持ってきたからレイテンシ高くなってたのかな)
インデキシング、クエリのキャパシティはそれぞれ必要に応じてスケールする。
OCU の最大値のみ指定可能。
コレクションレベルでの指定はできず、アカウントレベルのみ。
最大の OCU はインデキシング、クエリそれぞれで 20。
現在の OCU は CloudWatch のメトリクスに記録されるので、監視して調整するような運用も可能。
OpenSearch API の利用
OpenSearch API にアクセスするには AWS SigV4 による署名をリクエストヘッダに含める必要がある。
サービス名を aoss にするぐらいで従来とやり方変わっていなさそう。
Logstash や Fluentd を利用してインデキシングしている場合も対応済み。
OpenSearch Service Domain のように Basic 認証(独自のユーザー名・パスワード)によるアクセスはできなくなった。
サポートする OpenSearch API とプラグイン
サポートする OpenSearch API
- 基本的な読み書きの API はサポート
- Search Template を利用できない
- インデックスの Open / Close はできない
- Snapshot できない
- reindex できない
- Delete by query、Update by query できない
- Ingest Pipeline は利用できない
- クラスタ設定はない
サポートするプラグイン
- Kuromoji、ICU などの Analysis プラグインはサポートする
- OpenSearch のプラグインは利用できない
- SQL とか、k-NN とか、Index State Management とか
VPC アクセス
- 従来のように VPC 内にリソースを作成することはできず、VPC エンドポイント経由でのアクセスとなる
- VPC エンドポイントを作成してコレクションに紐付けるだけ
- 払い出されるエンドポイントが VPC エンドポイントになる
- インターネットからでも、VPC からでもアクセスできる
サービス制限
Indexes within search collections per account、Indexes within time series collections per account が気になる。
コレクションタイプ毎にインデックス最大数がある?
試しに Search タイプのコレクションに 20以上のインデックスを作成したみたけど作成できた。
性能試験してみた
比較対象
- OpenSearch Serverless
- Max 4 OCU(Indexing/Search ともに)
- 24GiB 4vCPU?
- OpenSearch Service Domain
- OpenSearch 2.3
- r6g.large(16GiB 2vCPU)
- 1台
計測ケース
- インデキシング
- データは EC で扱う商品データみたいなもの 10,000件
- 日本語検索を想定したインデックス設定
- bulk で 50件づつ 4並列で 5分間登録し続ける
- クエリ
- インデキシングで登録した 10,000件のテストデータを持つインデックスに対して
- Max 200ユーザー、Hatch Rate 4 でキーワード検索を 5分間投げ続ける
計測するもの
- スループット
- レイテンシー
- エラーレート
- CPU 使用率
- OpenSearch Serverless は取得できない
計測結果
- OpenSearch Service 2.3 と比較して、インデキシングレートが 50%低く、クエリレートは 85%低い
- とにかくレイテンシーが高い
※ あくまでも一つのケースでの試験なので OpenSearch Serverless のユースケースに向いていないだった可能性があります。
インデキシング
| 項目 | Serverless | Service |
|---|---|---|
| スループット(rps) | 3.7 | 7.3 |
| 平均レイテンシ(ms) | 1,077 | 545 |
| 最小レイテンシ(ms) | 536 | 106 |
| 最大レイテンシ(ms) | 2,513 | 2,485 |
| エラーレート(%) | 0 | 0 |
| CPU使用率(%) | - | 97 |
検索
| 項目 | Serverless | Service |
|---|---|---|
| スループット(rps) | 24.6 | 164.8 |
| 平均レイテンシ(ms) | 7,391 | 1,112 |
| 最小レイテンシ(ms) | 204 | 12 |
| 最大レイテンシ(ms) | 13,834 | 2,847 |
| 95tileレイテンシ(ms) | 11,000 | 1,300 |
| エラーレート(%) | 0.01 | 0 |
| CPU使用率(%) | - | 99 |