NeuralNetwork on Scratch(基本部分)
NeuralNetwork on Scratch(基本部分)
NeuralNetwork on Scratch を基本部分だけにしたものも公開しています。
入力データの取り込み/作成部分や出力値の扱い方の部分などは自由に実装しましょう。
画面イメージ
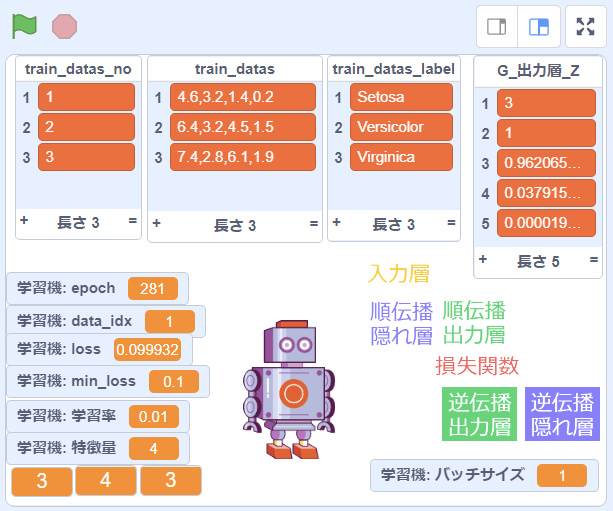
ニューラルネットワークの構成
上の画面の設定の場合、次のようなニューラルネットワークの構成になります。
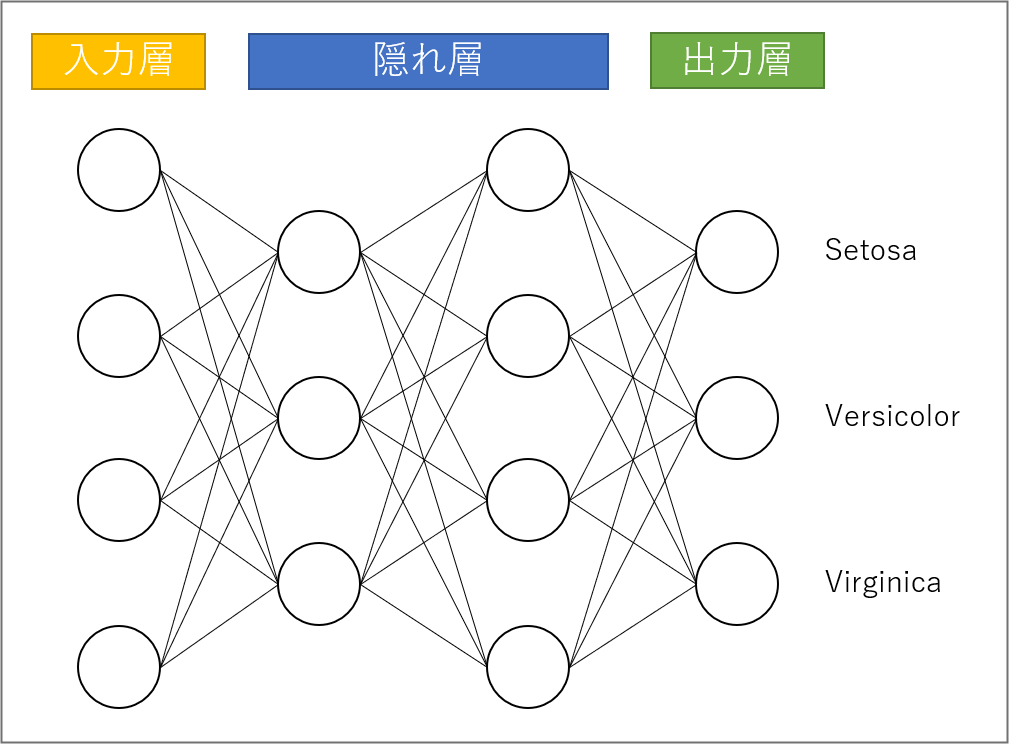
変数の説明
「初期化」定義ブロック
| 変数名 | 意味 | 説明/備考 |
|---|---|---|
| 特徴量 | 特徴量 | 特徴量の個数。データから自動取得。 |
| 隠れ層_1の数 | 隠れ層_1のユニット数 | 画面左下の一番左の「3」がこの数 |
| 隠れ層_nの数 | 隠れ層_nのユニット数 | 出力層の一つ手前の隠れ層。画面左下の真ん中の「4」がこの数 |
| G_出力層の数 | 出力層のユニット数 | 画面右下の一番左の「3」がこの数。ラベルのユニーク数から自動取得。 |
| G_隠れ層_活性化関数 | 隠れ層の活性化関数 | ReLU, LeakyReLU を実装済み |
| G_出力層_活性化関数 | 出力層の活性化関数 | Softmax のみ実装済み |
| loss | 損失値 | epochごとの損失値 |
| min_loss | 損失値の最小値 | 損失値がこの値を下回ると学習終了 |
| sum_loss | 損失値の合計 | バッチごとの損失値の合計。lossの計算に使用。 |
| G_学習率 | 学習率 | - |
| 学習率 | 学習率 | 表示用 |
| epoch | epoch数のカウンタ | - |
| data_idx | データインデックス | train_datas リストのインデックス。train_datas_no の値ではない。 |
| max_epoch | epoch数の最大値 | epoch数がこの値を上回ると学習停止 |
| バッチサイズ | バッチサイズ | 表示用 |
- 太字は設定可能な変数

「[テスト]を受け取ったとき」イベントブロック
| 変数名 | 意味 | 説明/備考 |
|---|---|---|
| G_バッチサイズ | バッチサイズ | テストの際は1を指定 |
| data_idx | データインデックス | train_datas リストのインデックス。テストに使いたいデータをインデックス番号で指定。train_datas_no の値ではない。 |
- 太字は設定可能な変数
リストの説明
| リスト名 | 意味 | 説明 |
|---|---|---|
| train_datas_no | 訓練データ(項番) | 単なる項番 |
| train_datas | 訓練データ(特徴量) | 特徴量をカンマ区切りで登録。1項目 = 1データ |
| train_datas_label | 訓練データ(ラベル) | 訓練データのラベル(教師データ) |
| G_出力層_Z | 出力値 | 出力層のユニットごとの出力値(確率) |
| loss_history | 損失値 | epochごとの損失値のログ |
リスト変数の値の見方
Scratchでは行列(2次元配列)を扱えないため、「NeuralNetwork on Scratch」ではリスト変数を使って疑似的に行列(2次元配列)を実現しています。下の図で 入力値リストが行列形式です。1つ目の要素が行、2つ目の要素が列、3つ目の要素以降が行列の要素を表しています。なお、train_datasは単なるリストです(行列形式ではありません)。
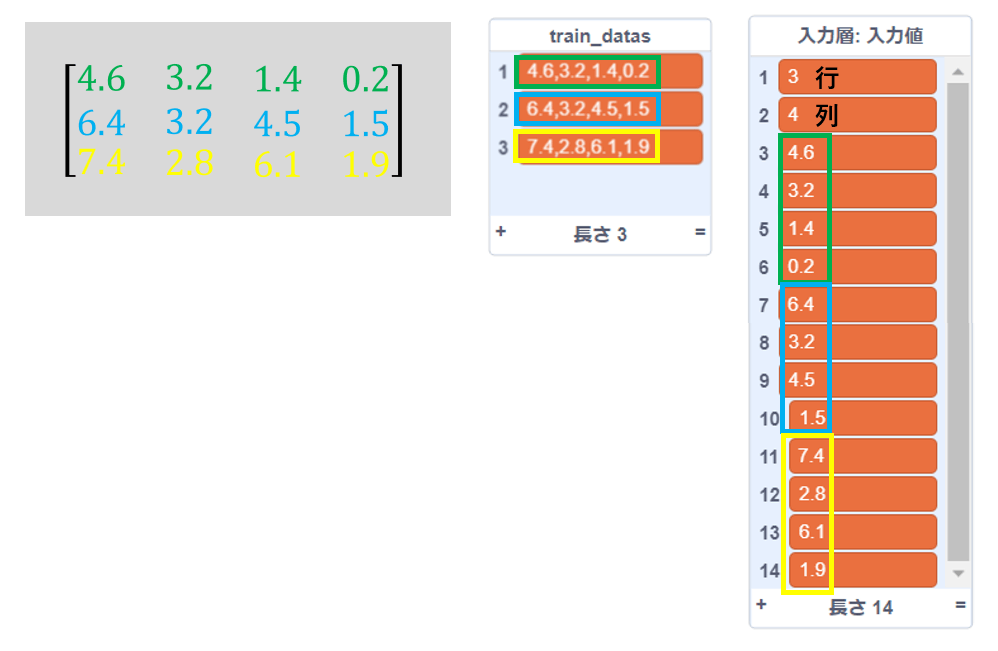
入力データの作成
入力データは1つのデータごとにカンマ区切りの状態で train_datas リストに登録します。その際、train_datas_no リストの項番、これは単なるデータの順番を表すものなので1から連番を振ればよいです。「データシャッフル」を使うとデータの順番が変わってしまうため、元の順番に戻したいときに利用しましょう。なお、data_idx 変数が train_datas リストのインデックス番号として処理されるので、train_datas リストの特定のデータを指定したい場合は、data_idx 変数を使います。
上の図で data_idx = 1 は、train_datas_no =「1」、train_datas =「4.6,3.2,1.4,0.2」、train_datas_label = 「Setosa」です。
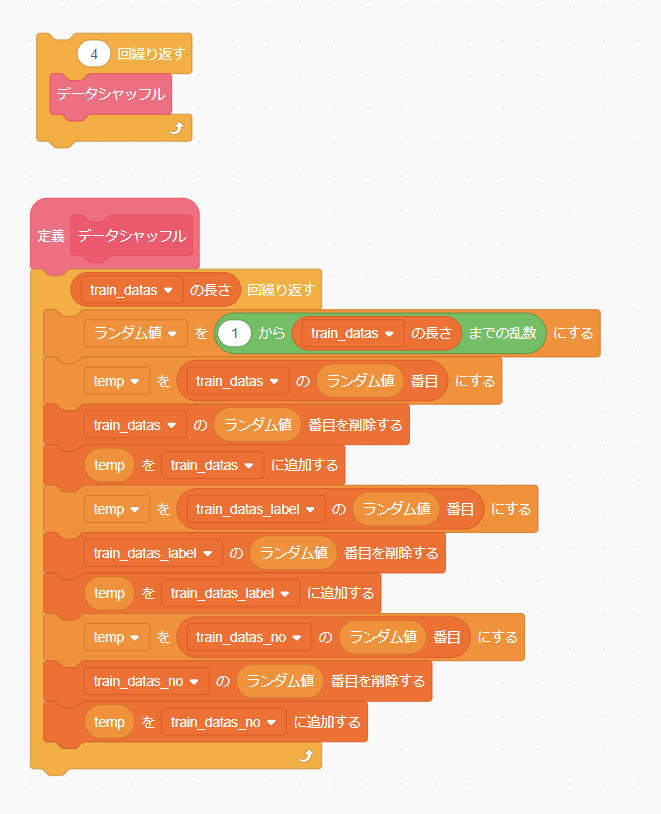
データシャッフル
必要に応じて「データシャッフル」を組み込みます。(組み込む場所は「[学習開始]を受け取ったとき」の「学習する」定義を呼び出す前あたりがよいでしょう。)「データシャッフル」が実行されると、訓練データの順番がランダムに入れ替えられます。シャッフルの回数は適当に決めましょう。
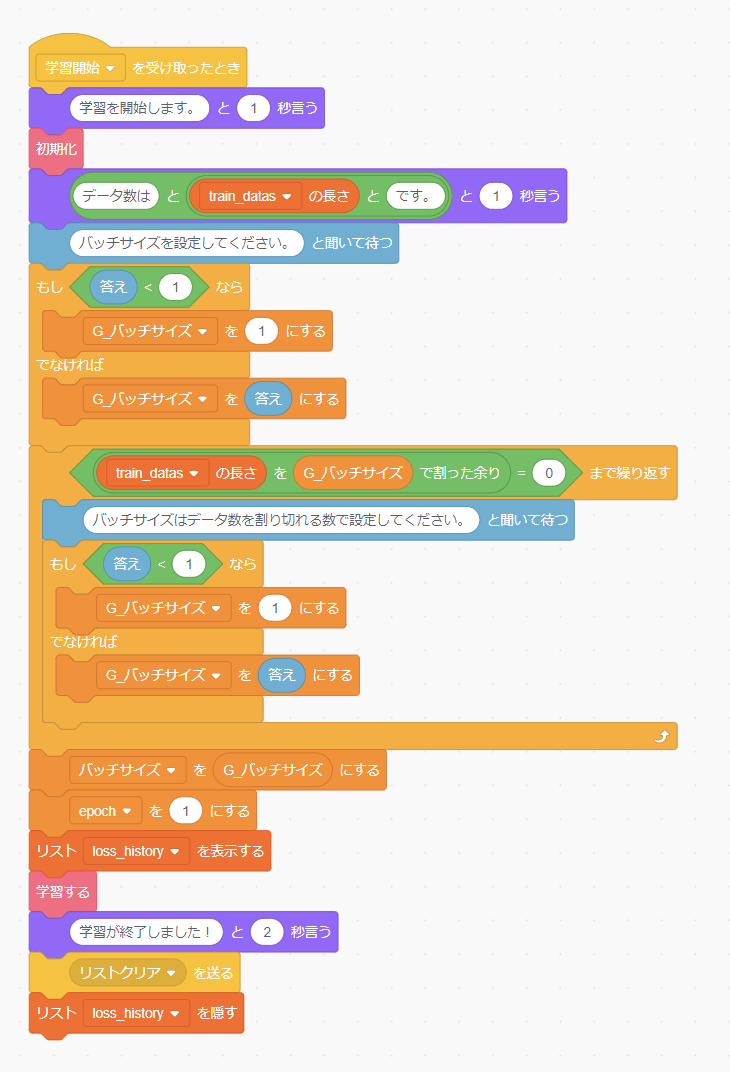
学習
「[学習開始]を受け取ったとき」 を実行すると、バッチサイズを聞かれます。何も入力しないとバッチサイズは1になり「オンライン学習」になります。バッチサイズをデータ数と同じにすると「バッチ学習」、それ以外だと「ミニバッチ学習」になります。なお、入力したバッチサイズでデータ数が割り切れない場合、再度の入力を促されます。学習が開始したら、終了するまで待ちましょう。loss_historyが表示されるので、loss(損失/誤差)が減少していくのを確認しましょう。(lossが減少しない場合は中断して学習をやり直してください。)
テスト
学習が終了したらテストしてみましょう。「[テスト]を受け取ったとき」 を実行すると data_idxで指定したインデックスのデータで推論をします。G_出力層_Zリストの最も大きい値の箇所がこのニューラルネットワークの推論結果となります。
出力結果の見方
以下の図で説明すると、G_出力層_Zリストの1番目と2番目の要素は行列(ベクトル)のサイズなのでここでは気にしなくてよいです。3番目~5番目の要素が出力層の各ユニットの出力値となります。ここでは、3番目の要素の値が最も大きいのでこのニューラルネットワークの推論結果としては、3番目のユニットであらわされているものになります。

どのユニットが何を表しているかはG_ラベルの種類リストを確認してください。今回であれば3番目の要素は「Setosa」、4番目は「Versicolor」、5番目は「Virginica」です。3番目の要素の値が最も大きいので、data_idx = 1 のデータは 「Setosa」 と推論したことになります。
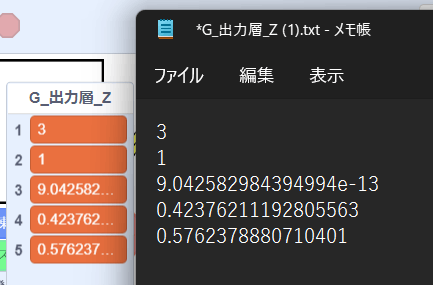
なお、出力結果が以下のような場合があります。G_出力層_Zの値だけを見ると3番目の要素の値が最大のように見えますが、実は指数表現されているため実際の値は非常に小さな値ですので注意してください。
最後に
入力データとしてカンマ区切りのデータが準備できれば、いろいろな分類問題を解くことができると思います。いろいろと工夫して遊んでみましょう。
【関連記事】
【Scratchプロジェクト】
NeuralNetwork_on_Scratch_2 (全部入り)
Base_NeuralNetwork_on_Scratch_2 (基本部分のみ)
Discussion