こんにちは、株式会社FP16で結構コードを書いている二宮です。
最近Webスクレイピングのコードを色々な方法で書いているので、そこで得た知見をここに残しておこうと思います。
ほぼ毎日なにかのWebスクレイピングコードを書いています。
Webスクレイピング手段
Webスクレイピングには色々な方法があります。
私が最近主に使っているのはこの5つの手段です。
- cheerioでHTMLを解析
- Playwrightなどで要素指定でデータを取得する
- APIを見つけて叩く(バックエンドとの通信を再現してデータを取得)
- LLMでサイト構造を解析してデータを取得する
- Next.jsからのレスポンスに含まれているデータを解析して取得する
これが令和のWebスクレイピングのベストプラクティスだと思っています。
これらの方法を、目標に合わせて使い分けています。
使い分け方
CheerioでHTML解析
JavaScriptを使った遅延読み込みなどがなく、完成したHTMLが返ってくるサイトをスクレイピングする場合はCheerioが最適です。
これはなんとCloudflare Workerで動くので、大量にスクレイピングする場合もサーバー代が0円で住んだりします。
Playwright
JavaScriptでのデータ読み込みなどがある場合はPlaywrightを使ってスクレイピングする必要があります。
一般的なブログ形式のウェブサイトや、テンプレートで型が決まっていて複数の商品データなどを取得したい場合、かつ情報の取得がフロントからAPIで行われていない場合
Seleniumなど色々ブラウザを操作するツールはありますが、今からやるならPlaywrightをおすすめします。
APIを叩く
フロントからAPI経由でデータの取得が行われていた場合は間違いなくこれが一番です。
要素指定などではないので、取得に失敗する確率が圧倒的に減ります。
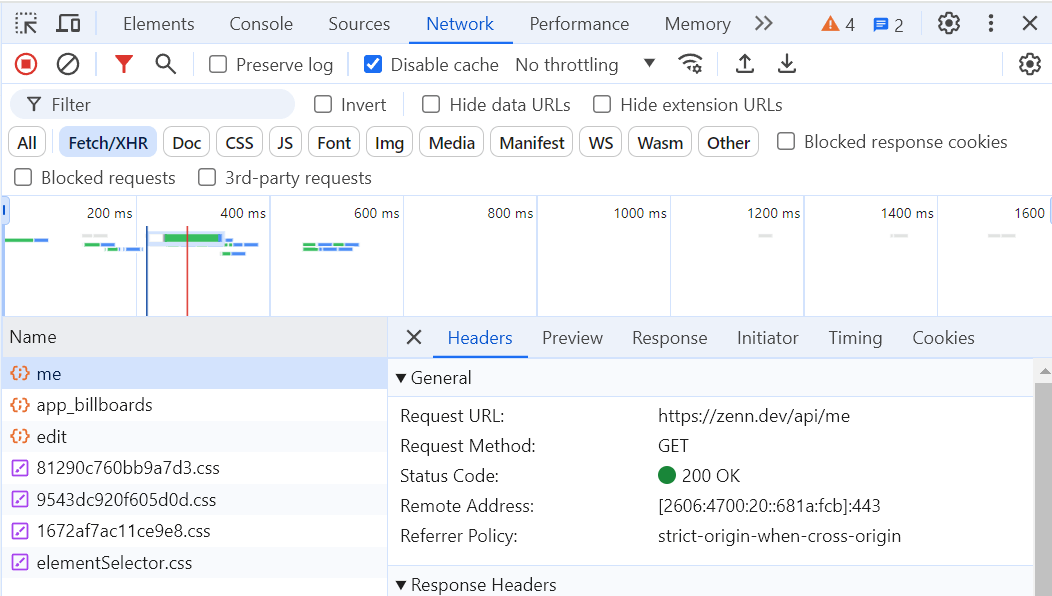
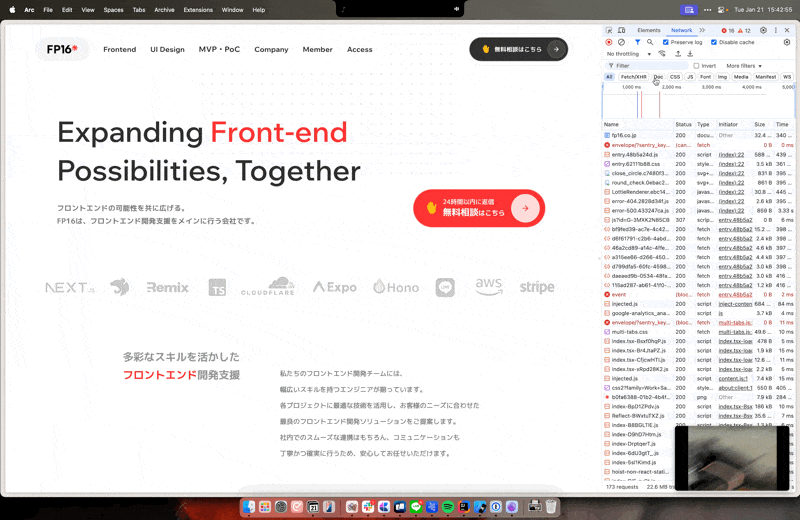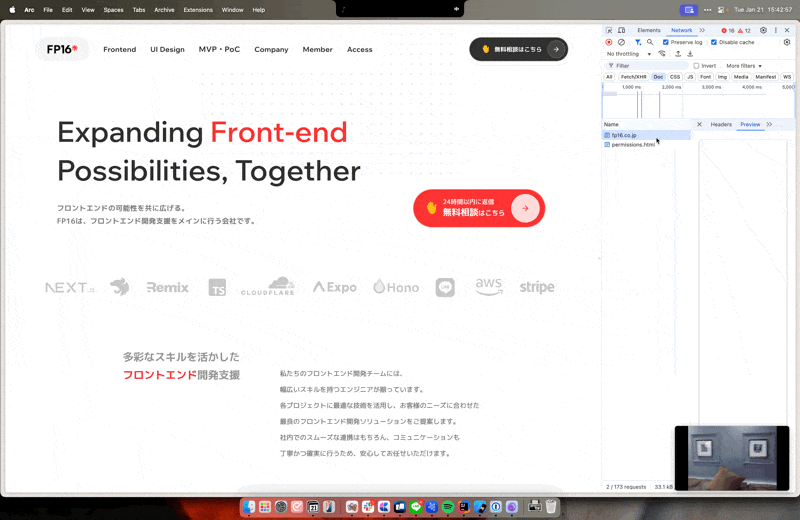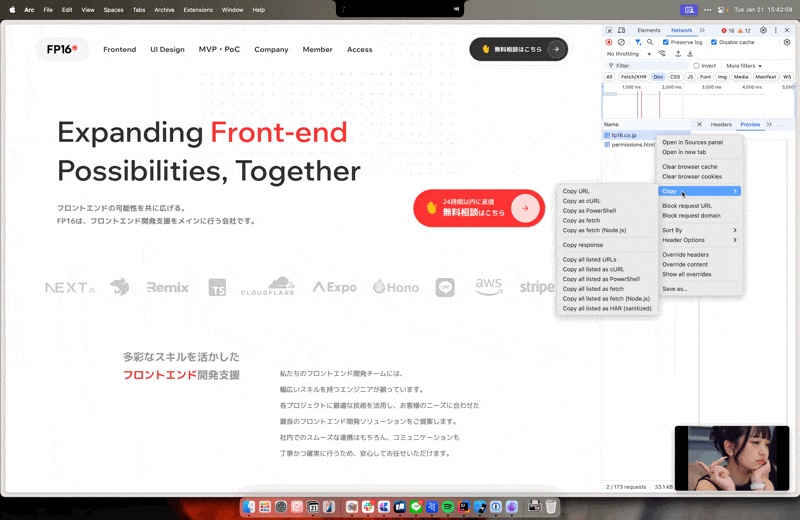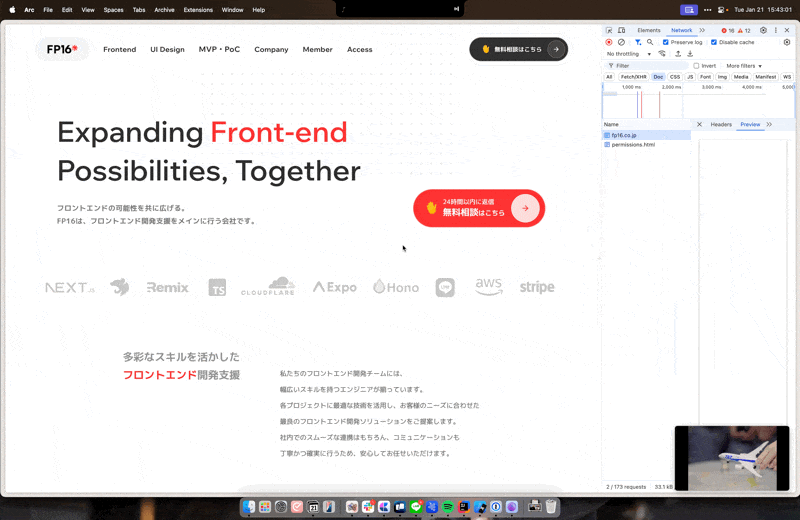
Chromeでウェブサイトを開き、Networkタブから通信情報を確認します。
RESTやGraphQLでの通信の場合にこの方法を使っています。
そして取得する数などのプロパティを調整してデータを取得します。
LLMでサイト構造を解析
クロール対象となるウェブサイトが多く、構造も複雑な場合にLLMでサイト構造解析を行っています。
これはCheerioやPlaywrightとLangChainを組み合わせて使います。
静的なHTMLが返ってくる場合はCheerioでデータを<main>タグなどに絞りLLMに渡します。
動的な場合はPlaywrightでアクセスし、生成後のHTMLを<main>タグなどに絞ってLLMに渡します。
FP16では社内にGPUサーバーを設置し、Ollamaでモデルをホスティングしています。
Next.jsからのレスポンスデータを解析
Next.jsで作られているサイトが増えていますが、サーバーサイドでデータを取得していて、フロントには表示していない場合などもあります。(未ログイン時)
その場合はNext.jsがレスポンスに含むself.__next_f.pushを解析すると取得できる場合があります。
例えばこのように解析します。
const dom = new JSDOM(html);
const scripts = dom.window.document.querySelectorAll("script");
function getTransactionDate(scripts) {
let transactionDate = null;
for (let i = 0; i < scripts.length; i++) {
const script = scripts[i];
const text = script.textContent;
if (text?.includes("self.__next_f.push")) {
const jsonLikeString = text.match(
/self\.__next_f\.push\(\[1,"(.*?)"\]\)/,
);
if (jsonLikeString?.[1]) {
const jsonString = `{"data": "${jsonLikeString[1]}"}`.replace(
/\n/g,
"\\n",
);
try {
const json = JSON.parse(jsonString);
const dataString = json.data;
const dateMatch = dataString.match(
/"dateLastSold":"(\d{4}-\d{2}-\d{2})"/,
);
if (dateMatch?.[1]) {
transactionDate = dateMatch[1];
break;
}
} catch (e) {
console.error("Failed to parse JSON string", e);
}
}
}
}
return transactionDate;
}
プロキシで制限を回避
Bunをランタイムとして使っている場合は簡単にfetchにプロキシをつけてIPブロックを回避することが可能です。
私はWebShareというプロキシ販売サイトで日本IPのプロキシを購入して使用しています。(100IPで2~3ドルです)
Bunでのプロキシはこんな感じで行います。
const response = await fetch(url, {
proxy: PROXY_URL,
})
また、サービス次第ではヘッダー情報を監視してブロックしてくることがあります。
その時は以下のような流れで実際にリクエストで使われてるヘッダーをコピーしてヘッダー情報としてfetchに追加しましょう。
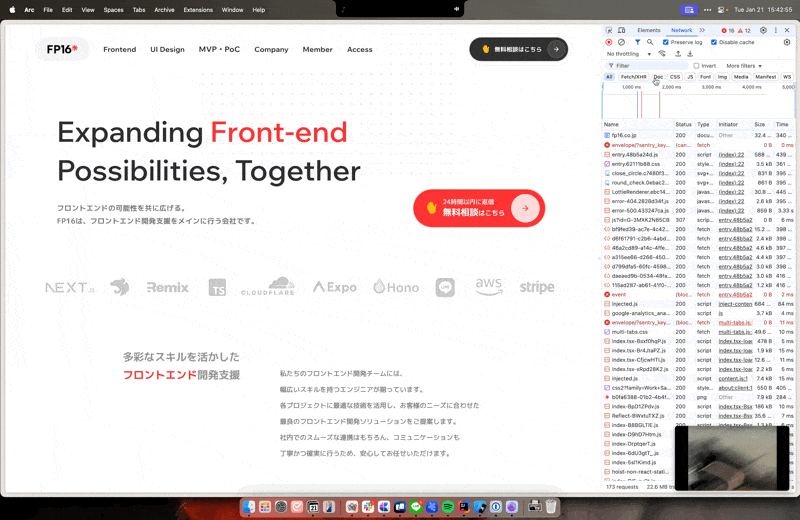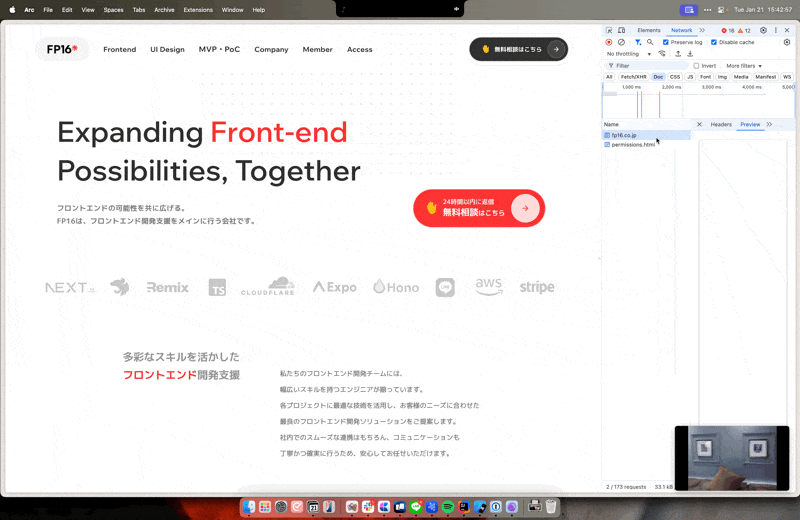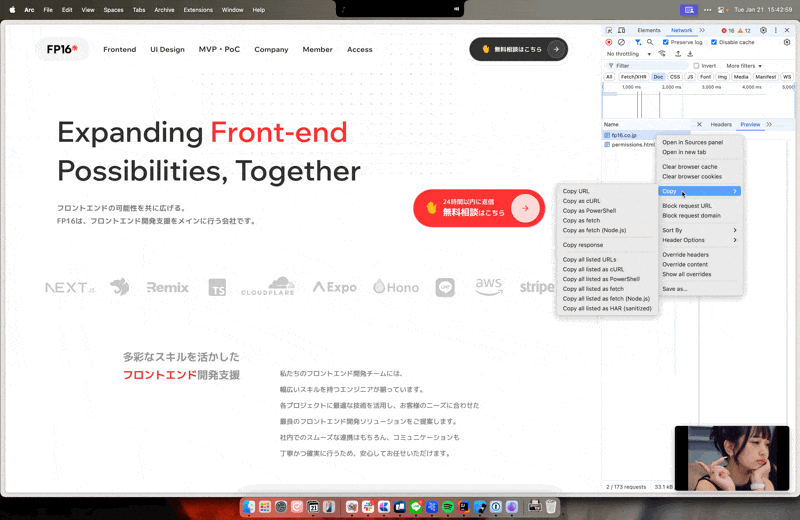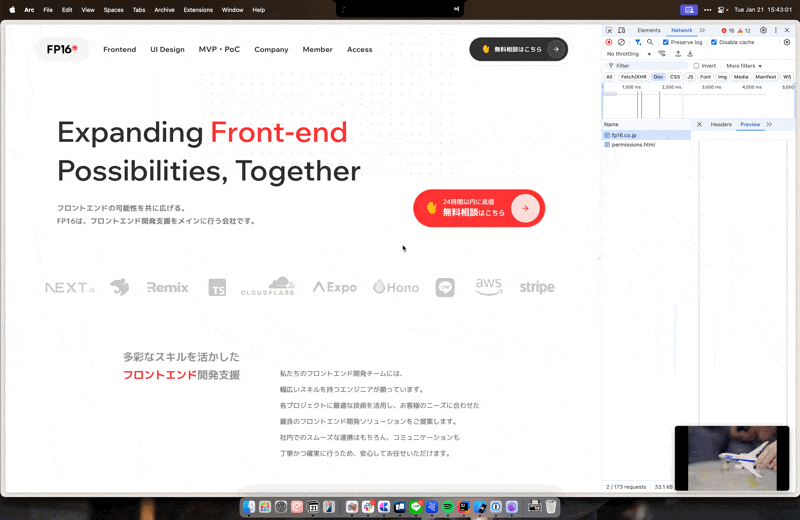
こんなのがコピーされるので
fetch("https://fp16.co.jp/", {
"headers": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "en-US,en;q=0.9,ja;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=0, i",
"sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"macOS\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"cookie": "mw-wp-form-token=35c90b9ab55df8dace2e4b0b8569d70ca63a7e88c257689928ff093235e6d6a9; wordpress_test_cookie=WP%20Cookie%20check; wp-settings-time-1=1720073296; wp-settings-1=libraryContent%3Dbrowse; _ga=GA1.1.318755459.1720075152; _clck=oxmx5q%7C2%7Cfow%7C0%7C1647; _ga_3MXK2N85CB=GS1.1.1725426858.26.1.1725428565.60.0.1258496670"
},
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET"
});
こんな感じのリクエストにしたらOKです
const response = await fetch(url, {
proxy: PROXY_URL,
"headers": {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "en-US,en;q=0.9,ja;q=0.8",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=0, i",
"sec-ch-ua": "\"Not A(Brand\";v=\"8\", \"Chromium\";v=\"132\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"macOS\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"cookie": "mw-wp-form-token=35c90b9ab55df8dace2e4b0b8569d70ca63a7e88c257689928ff093235e6d6a9; wordpress_test_cookie=WP%20Cookie%20check; wp-settings-time-1=1720073296; wp-settings-1=libraryContent%3Dbrowse; _ga=GA1.1.318755459.1720075152; _clck=oxmx5q%7C2%7Cfow%7C0%7C1647; _ga_3MXK2N85CB=GS1.1.1725426858.26.1.1725428565.60.0.1258496670"
},
"referrerPolicy": "strict-origin-when-cross-origin",
"body": null,
"method": "GET"
})
こんなサービスもあるよ
Automa
Chrome拡張型のブラウザ自動操作・データ取得アプリです。
完全にシステムに組み込む必要がなく、簡単にデータ取得を行いたい場合はAutomaで十分かもしれません。
Firecrawl
LLMにRAGとかで最新のデータを渡すためにスクレイピングしたいならこれを使うのが最近は多い。
セルフホスティングも可能!
おしまい
最後まで読んでいただきありがとうございました!
今後各方法の実際の実装方法の記事を書けたらいいなと思っています。
たくさんいいねもらえると嬉しいです!

Discussion