概要
ベクトル検索データベースを利用するにあたり、 PostgreSQL + pgvector は有力な選択肢の1つに挙げられると思います。
pgvectorがサポートするインデックスアルゴリズムは一般的で信頼性の高いものですが、近似最近傍探索アルゴリズムは近年でも新しい手法の提案が頻繁に行われている分野であり、そういった新手法をPostgreSQL向けに実装した野心的な拡張機能も存在します。
本稿は、新しいベクトル検索用拡張のひとつである VectorChord の紹介と、簡単な性能検証を試みるものです。
PostgreSQLのベクトル検索拡張
PostgreSQL でベクトル検索を利用する場合、特に理由がなければpgvectorを採用することになるかと思います。
pgvectorはHNSWとIVFFlatの2種類のインデックスアルゴリズムをサポートしています。HNSWはほとんどのベクトルデータベースで標準採用されている最も一般的といえるアルゴリズムで、IVFFlatも多くの製品でサポートされています。
初期のpgvectorは性能に問題があったため、 より高機能なベクトル検索機能を提供する拡張が複数出現しました(pgvecto.rs や pg_embedding など)。これらはpgvectorと同じアルゴリズムを提供していましたが、近年はpgvector自体の機能が充実してきたこともあり、相互互換を目指した拡張はほとんどが開発を中断ないし終了しています。
結果として、2025年5月時点でHNSWを使ってとりあえずベクトル検索をしよう、となった場合はpgvectorがほぼ一強状態となっています。
一方でHNSWは億単位の巨大なデータセットには不向きであり、IVFFlatも実用に足る精度と速度の両立が難しいとされているため、ビッグデータに対するベクトル検索には依然として課題があります。そのためpgvectorの相互互換を目指すのではなく、新しいアルゴリズムの実装によってpgvectorの欠点を補完する というのが拡張機能開発の潮流となっています。
VectorChordの特徴
前項でも触れましたが、VectorChord は pgvecto.rs の開発元であった TensorChord が新しく開発している PostgreSQL 向けの拡張機能です。
VectorChordはpgvectorのフォーマットを利用しつつ、新しいインデックスを提供するライブラリです。ベクトル型のインターフェイスをpgvectorに依存しているため、VectorChordを利用する際はpgvectorのインストールも必要です。
現在は型としてvector型とhalfvec型、比較方法としてコサイン距離、ユークリッド距離(L2)、内積が実装されており、一般的な用途に必要な機能は一通り揃っていそうです。
VectorChord の一番の特徴は、IVFと RaBitQ というビット量子化手法を組み合わせたアルゴリズムを実装している点です。アルゴリズムの詳しい説明は省きますが、データベース視点でHNSWと比べると、比較的高い精度を保ちつつインデックスサイズの軽量化と構築の高速化が実現されている、ということになります[1]。
個人的に触ってみた感触ですが、インデックスの並列構築やハイブリッド検索対応など実用上必要になるだろう機能も充実しており、商用環境での使用も検討できる水準だと感じました。
実測
VectorChordの公式ブログには、各ベクトルデータベースに対して独自に実施したベンチマークの結果が記載されています。
ブログではLAION-5Mというデータセットでのベンチマークを比較しています[2]。このベンチマークの結果の解釈としては、VectorChordはRecallが99%を超えるような非常に高精度の検索が難しい一方、97%~99%程度の精度帯では他のデータベースでは実現できない水準の速度を出せる、ということになりそうです。
本当にこのような圧倒的な性能差が生まれるものか、というのは気になりますね。そのため他のデータセットを使って実際にベンチマークを試してみることにしました[3]。
今回は ann_benchmarks にVectorChordのベンチマークを加え、pgvectorとVectorChordのベンチマーク結果を比較しています。
ann_benchmarksはベクトルDB間というよりはアルゴリズム間の性能比較が目的のベンチマークであり、扱っているデータセットはメモリに乗りきる比較的小さめのものになります。そのため、VectorChordの真価である省容量化の恩恵は測れていません(将来的にはこれも検証したいと思っています)。
計測について
計測は以下の条件で行いました。
c6a.xlarge
ubuntu: 22.04
postgresql: 16.8
pgvector: 0.8.0
vchord: 0.3.0
pgvector, VectorChordともにインデックス構築、検索時のパラメータによって検索速度と精度が大きく変動します。以下に本計測での設定を記載します(あくまで傾向の比較が目的であり、現実的に設定すべきパラメータと乖離している可能性があります)。
pgvector
構築時パラメータ
m: 16
ef_construction: 200
検索時パラメータ
ef_search: 10, 20, 40, 80, 120, 200, 400, 800 (計8パターン)
vchord
構築時パラメータ
lists: 1000
検索時パラメータ
(probes, epsilon): (10, 0.5), (10, 1.0), (40, 0.5), (40, 1.0), (40, 1.9), (80, 1.0), (80, 1.9) (計7パターン)
ann_benchmarksではそのままでもさまざまなデータセットでベンチマークが実行できますが、今回はGloVeとGISTの2種類に対して実施しました。GloVeは100次元×約100万件、GISTは960次元×100万件のデータセットとなります。
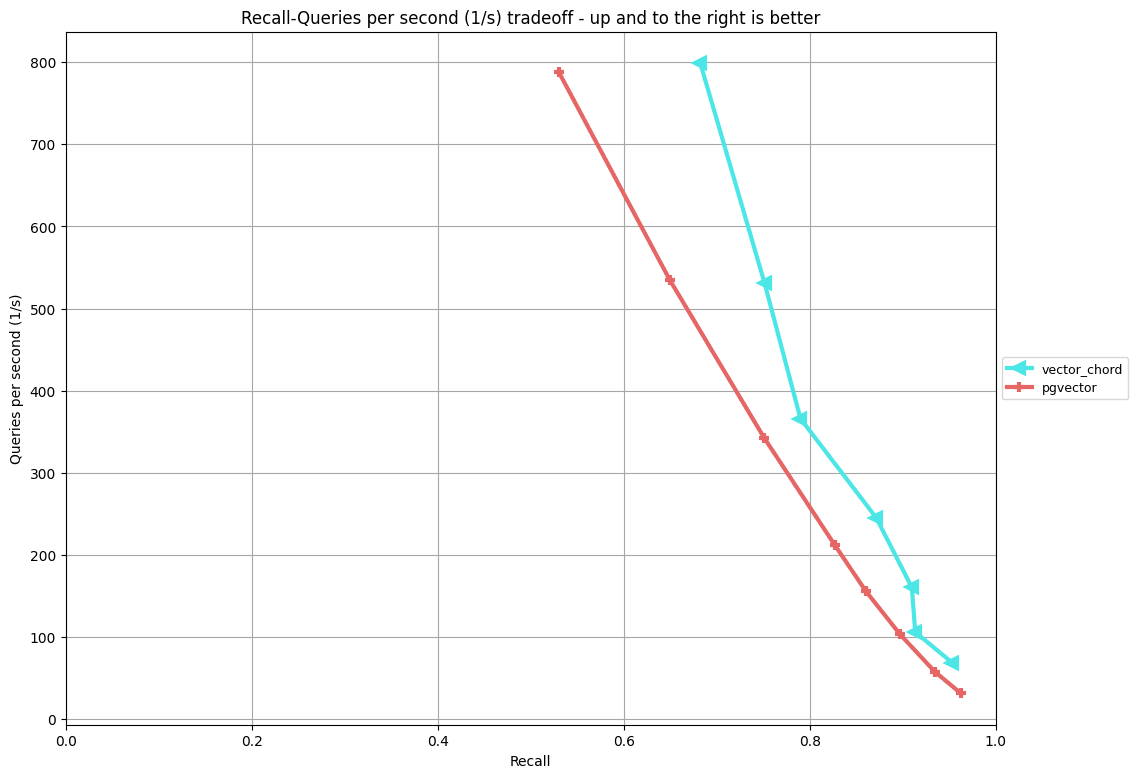
GLoVe-100-angular
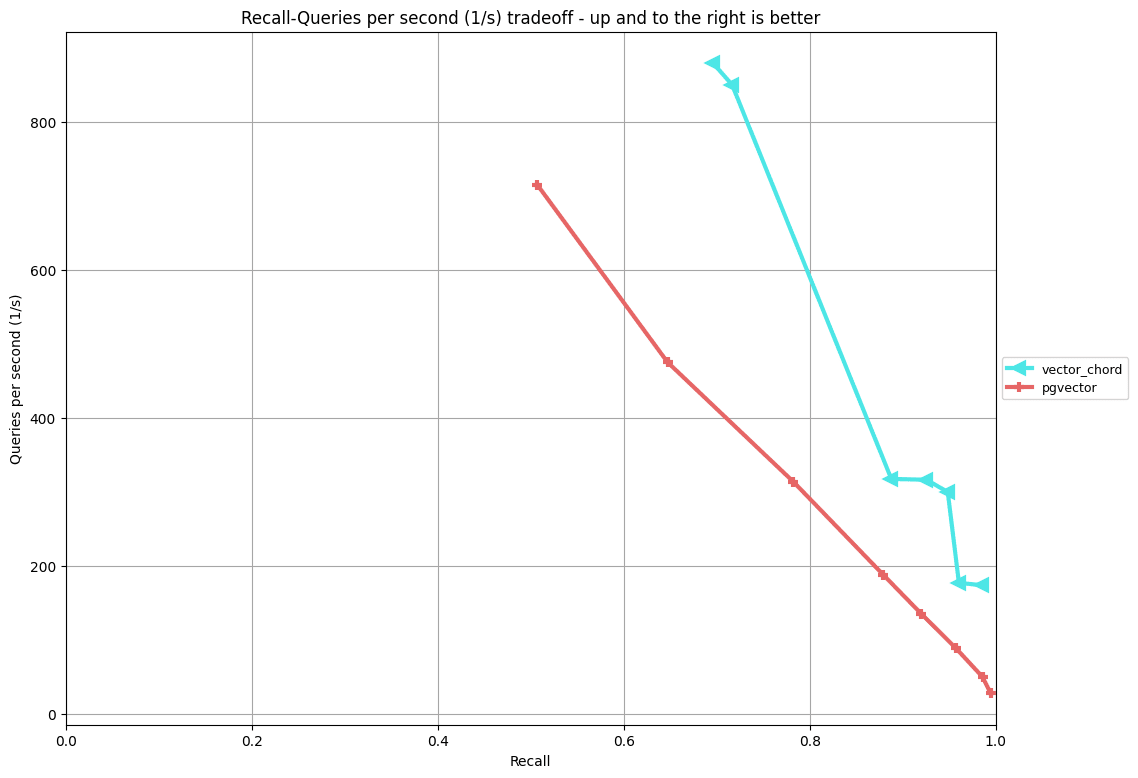
GIST-900-euclidean
グラフの横軸がRecall(精度)、縦軸がQPS(速度)となります(両者はトレードオフ)。折れ線が右上にあるほど性能が高いといえます。
VectorChord側はオンライン検索時のパラメータが2種類あるため歪な折れ線になっていますが、いずれの比較においても、VectorChordがpgvectorの性能を上回るという結果となりました。また、GloVeに比べるとGISTの方がより性能差が出る、という結果も確認できました[4]。
ブログにはGISTの性能はpgvectorの2倍という記述もありますが、状況によってこの主張もあながち間違ってはいないのかもしれません。
またオンライン計測とは別ですが、インデックス構築速度、サイズに関してもVectorChordが優れていました[5]。
まとめ
VectorChordはまだ出たばかりの拡張にもかかわらず、既に実用面、パフォーマンス面ともにかなり完成度が高い印象を受けました。
pgrxを用いたRustによる実装という点でも、拡張実装においてボトルネックになりがちなPostgreSQL特有の煩雑な部分をライブラリに任せ、コアの実装をRustで記述しつつC言語の拡張と遜色ないパフォーマンスを発揮しているため学ぶべき部分が多そうです。
冒頭でも触れましたが、ベクトル検索は現在も進歩が続いている分野です。拡張機能という形で新技術を誰でも追加実装できる点でPostgreSQLは非常に優れたプラットフォームであり、今後もより高機能なデータベースとして第一線で活躍し続ける可能性を改めて感じました。
この記事を書いた人
吉田 侑弥
2020年新卒入社
TODO: IVFFlatのベンチマーク
告知
フォルシアはzenn記事投稿コンテスト「TypeScriptでやってみた挑戦・学び・工夫」のスポンサーを務めています。
また6/20(金)には、フォルシアの技術ブログを語るLT会、Shinjuku.md #1を開催予定です!

今後も様々な技術記事を投稿していきますので、ぜひ気軽に遊びに来てください!
-
https://blog.vectorchord.ai/vectorchord-store-400k-vectors-for-1-in-postgresql#heading-vectorchords-solution-disk-friendly-ivfrabitq ↩︎
-
LAIONは50億件を超える巨大なデータセットですが、5Mとある通りこのベンチマークではその中の500万件を用いているようです。 ↩︎
-
開発者が実施したベンチマークはプロダクトの優位性を示す材料に過ぎないので、利用者は世のベンチマークを鵜呑みにするのではなく、中立な視点での検討、場合によっては追試をすべきだと思います。切に。 ↩︎
-
GISTはGloVeとくらべて8倍程度大きいデータセットなので、データサイズが大きい時ほどVectorChordが有利という直感にそぐう結果ではあります。ただこの結果だけではデータサイズのみが性能差に起因したのかを判断できないので、理由を明らかにしたければさらに追試が必要です。。 ↩︎
-
ログを取り忘れてしまいましたが、インデックスサイズはHNSWの約半分で、構築速度は何倍も高速でした。pgvectorもインデックスの並列構築をサポートしていますが、それでもやはりHNSWの構築にはかなりの時間が必要です。 ↩︎

Discussion