こんにちは。エンジニアの谷井です。
フォルシアでは、Spookと呼んでいる技術基盤を用いて、主に旅行業界やMRO業界に対して、膨大で複雑なデータを高速検索できるアプリケーションを提供しています。
今回はその高速検索のノウハウのうち、特にDBの扱いに関連する部分について、ベテランエンジニアへのインタビューを通してそのエッセンスをまとめてみました。
一般的なベストプラクティスだけでなく、検索性能を高めることに特化しためずらしいアプローチもあるので、ぜひご覧ください。
フォルシアにおける検索DBについて
まず前提としてフォルシアで扱うデータについて軽く説明します。
扱うデータの複雑さ
たとえば、旅行会社向けのアプリケーションであれば、宿泊素材の情報としては
- ホテルの情報「〇〇ホテル」(~約2万件)
- プランの情報「朝食付き・ロングステイ△△プラン」(0~1500件/施設)
- 客室の情報(~100件/施設)
- 在庫(~366日分)
^1 - 料金(~366日
^2 ^3 ^4
などを保持しています。(展開すると料金データとしては10~100億件ほどのオーダー)
「複雑」な点としては、
- 1つの客室が複数のプランとして販売されるため、在庫はプランをまたいで共有している。
- 日によって料金が異なる。(繁忙期は高いなどシーズナリティがある)
- 宿泊人数によって料金が異なる。(2名1室料金は1名1室料金×2ではない)
- 人員区分(大人/子供/幼児/シニアetc)によって料金が異なる。また「この年齢の子供は大人人数としてカウントする」というようなロジックがプランごとに存在する。
- 連泊によって料金が割り引かれるプランもある。
などが挙げられます。
検索の種類
こうした複雑なデータに対して、様々な軸での検索を行います。先ほどの旅行系アプリケーションの例であれば、
- 選択日程の販売可否判定(在庫検索)
- プランの販売期間内か(設定期間・販売停止・手じまい等)
- 各日の在庫が存在するか(
大人2名+5才の子供1名)
- 選択条件での料金検索
- 予算の上下限(
5000円以上・15000円以内) - 集約表示(同じ施設でも日ごと/プランごとに料金が異なるため、料金を集約して最小~最大の料金幅で表示)
- 日付未指定(カレンダー形式)での料金表示(
5/1:〇~〇円, 5/2:△~△円...) - 計算後の料金の安い順/高い順での並べ替え
- 予算の上下限(
- 条件で絞り込む検索(属性検索)
- 宿泊地のエリア(
関東/札幌市内) - 客室のこだわり条件(
ツイン/和室/バス・トイレ別/禁煙/ペットOK) - ホテルのこだわり条件(
駅徒歩5分/コテージ/露天風呂/口コミ90点以上) - プランのこだわり条件(
朝食つき/部屋食/レイトチェックアウト/現地払い)
- 宿泊地のエリア(
- 施設名やキーワードを指定しての検索(全文検索)
- 地図検索(表示領域内の緯度経度検索)
などが挙げられます。さらに、フォルシアではここに交通手段や現地素材を加えたパッケージやツアーの検索も扱っており、他の素材も加わると制御はより複雑になります。
このような「5月3日~5日で大人4名 / 札幌市内 / 駅徒歩5分以内 / 朝食付き / ツイン / 予算〇円以内」といった様々な条件での絞り込みを、エンドユーザーにとって快適なレベルで高速に行うために、フォルシアでは様々な技術的工夫がなされています。
データの更新方法・ライフサイクル
DBの更新も少し特殊です。
1日数回のバッチ処理によって、顧客の基幹システムから連携される全件データを取り込み、検索DBを全件再構築しまるごと洗い替えています。
-
INSERTやUPDATEではなく、DROP TABLE→CREATE TABLE - 連携された時点のデータを、検索に特化したテーブル構造に変換している。
- RDBMSとしてPostgreSQLを採用。

インフラ構成別のバッチ処理の流れ
(補足) データ鮮度の問題と対応について
一方、全件更新には時間がかかってしまう(データ量次第では、更新処理が6時間を超えることもある)ため、データ鮮度は課題になります。たとえば在庫や料金の鮮度は、予約を確定させるタイミングになって在庫切れで予約できない、料金が変わってしまう、といったUXの問題に直結します。
そこで、フォルシアでは2種類の方法で差分更新(変更があった内容のみをオンラインのDBに適用する)を実現しています。
- レプリケーション方式:バッチサーバーに更新をあてていくことで各オンラインのDBに反映される仕組み。
- message queue方式:特定のサーバーで動いている常駐プロセスが更新ファイルを集めてきて、データを整形して各オンラインのDBに配り、それぞれのDBでそのファイルを当てていく仕組み。
これらの差分更新は顧客の基幹DB(ないしはそのレプリケーション先)の更新頻度を上限として、早いケースでは3分間隔で更新されます。
その他、アプリ側の構成の詳細については以下の記事で紹介しています。
以上のようなデータの複雑さやライフサイクルを前提に、高速検索に特化したDB設計をしています。
検索が爆速になるデータベース設計
さて、ここからは具体的な工夫について紹介します。

ノウハウ1: 検索専用テーブルを分離する
フォルシアではマスタテーブルとは別に、検索に特化したテーブル(以降"サーチテーブル"と呼びます)を作成します。サーチテーブルには検索時に参照する情報のみを集約して極力不要なデータは載せないようにすることで、共有バッファに効率よくキャッシュされやすくなります。
たとえば、ホテルを検索するためのテーブルであれば、サーチテーブルにはホテルやエリアの通し番号(後述)やキーワード検索用文言、こだわり条件、並び順などを載せます。
一方で、電話番号、住所文字列、施設からの案内、画像URLなど表示用の情報はマスターテーブルに分離しています。
また、販売期間外等で検索結果に表示され得ないレコードはサーチテーブル作成時に除外します。
このように作ったテーブルに対して、検索時には以下の流れでオンラインクエリを実行します。
- まずサブクエリ内などでサーチテーブル上で絞り込みをかけ件数を絞る(WHEREとLIMIT)
- 絞り込んだ後のデータに対して、indexの貼られたマスタテーブルを結合する(JOIN)
最終的に「条件に合致するホテルについて、表示に必要な情報をマスタテーブルから取得する」という点は同じですが、あらかじめ絞り込むことで巨大なテーブルをメモリに載せる必要がなくなり、大幅にパフォーマンスを向上させることができます。
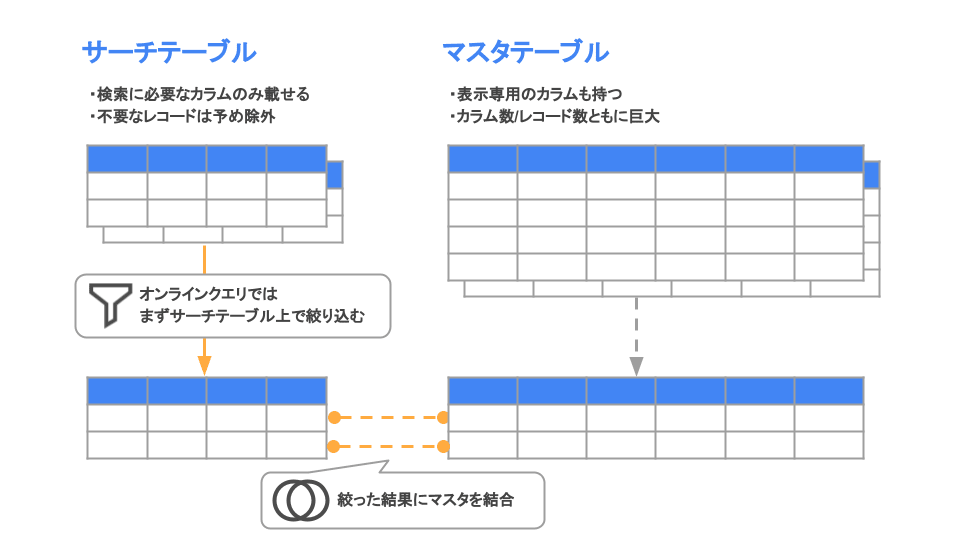
テーブルの分離とオンラインクエリの流れ
また、あらかじめ条件に合致する件数を先回りで検索するファセットカウントなどにおいてはサーチテーブルのみの走査で完結することもあり、高速化に大きく寄与します。
ノウハウ2: あえての「非正規化」
DB設計の一般的な考え方として、テーブルを適切に分割し、DBの冗長化を排除して効率的に情報を保持する"正規化"がよく挙げられます。一方、フォルシアではあえて正規化しないことがあります。
- オンラインでのテーブルの結合回数を減らすために、あえて重複した情報を複数のテーブルに保持する
- サーチテーブルのレコード数を削減するために、あえてデータを配列で保持する
PostgreSQLは行指向のDBであり行をカウントするのは苦手なため、特に集計処理などでは配列を使ってレコード数を削減した方がパフォーマンス面で有利になることがあります。
当然そのままではPostgreSQLでは扱いづらいので、(後述の)ユーザー定義関数を使うことで、配列のまま高速走査できるようにしています。
もっとも、やみくもに結合回数だけを減らしてもテーブルが肥大化してしまうため、
- テーブルのレコード数とのバランス(行数が多いテーブルはカラム数を増やしすぎない)
- そのカラムがどの粒度の情報で、どの検索に必要となるのか
なども考慮する必要がありますし、時には顧客から連携されてくるデータが(特別な意図なく)正規化されていないケースもあるため、業界に対する理解や実際のデータ構造とじっくり向き合うことが重要です。
ノウハウ3: 軽量なデータ型/独自のデータ型の利用
サーチテーブルでは、極力軽量なデータ型を用います。
たとえば、サーチテーブルの情報のうちIDやエリアなどには、あらかじめ採番して通し番号で表した状態で保持します。以下のようなイメージです。
マスターテーブル(抜粋)
| ホテルコード(text) | ホテル名称(text) | 地方(text) | 都道府県(text) | 地区(text) |
|---|---|---|---|---|
| a130354 | 新宿フォルシアホテル | 関東 | 東京都 | 新宿 |
サーチテーブル(抜粋)
| ホテルインデックス(smallint) | エリアインデックス(smallint) |
|---|---|
| 139 | 1305 |
また、組み込み型よりさらに小さく・効率よく情報を持つために、社内ではforcia typesと呼んでいる独自のデータ型を定義しています。(参考:PostgreSQL 14.5文書 ユーザ定義の型)
たとえば、旅行業界向けのアプリケーションでは、日ごと/人数ごとの在庫や料金のデータを効率的に保持できるデータ型を自前で実装しています。
一方、専門商社の業界の場合は、日ごとの料金差異はありませんが、企業制御(利用企業毎に料金を出し分ける等)が必要で、そのために料金グループを保持できるような型を作っています。
各業界ごとに顧客のデータ特性や検索時の処理に合わせた型を考案することで、データを集約してレコード数を削減したり、1レコードのデータサイズを縮小したりしています。
詳細な実装まではご紹介できませんが、これらの独自型には顧客のドメインやデータ構造への理解に基づくフォルシアの工夫が詰まっています。
ノウハウ4: ユーザー定義関数の活用
同様に、フォルシアでは独自のユーザー定義関数も駆使してパフォーマンスの改善を図っています。
PostgreSQLには豊富な組み込み関数が用意されていますが、ユーザーが自分で関数を定義して拡張することもできます。
その際、SQLはもちろん他の手続き型言語を使うことができるのですが、C言語を使うことも可能で、特にフォルシアでは処理速度が求められる部分で大いに活用しています。
たとえば、拡張のイメージは以下のような形です。
/* C言語で関数を実装 */
# include "postgres.h"
PG_FUNCTION_INFO_V1(plus_one);
Datum plus_one(PG_FUNCTION_ARGS);
Datum plus_one(PG_FUNCTION_ARGS){
int32 input = PG_GETARG_INT32(0);
PG_RETURN_INT32(input + 1);
}
これをコンパイルしてplus_one.soファイルを生成し、PostgreSQL側で関数を登録すると、クエリ内で実行可能になります。
CREATE or REPLACE FUNCTION plus_one(int4)
RETURN int4 AS 'plus_one.so', 'plus_one'
LANGUAGE C IMMUTABLE STRICT;
-- SQLで実行可能
SELECT plus_one(1);
plus_one
------------
2
特に先述の独自データ型や配列の扱いなどにおいては、組み込み関数やSQLでの拡張関数に比べて各段に処理速度が向上するほか、関数呼び出しのオーバーヘッドも削減することができます。
独自型やユーザー定義関数の活用によるクエリ実行速度の変化については、以下の記事の最後で軽く触れています。
ノウハウ5: カラムテトリス
テーブル作成時に記述順を工夫することで、扱う情報量はそのままに格納効率を上げられることがあります。
PostgreSQLには"アラインメント"という境界がデータ型ごとに決められており、その境界をまたいで配置することができません(int4では4バイト、int2では2バイト、booleanでは1バイトなど)。
たとえば、X(int4), Y(int2), Z(int4)という順序で配置すると、X,Yを続けて配置した後、続けてZを置きたいところですが、Zは4の倍数位置から開始する必要があるため、自動的に2バイト分パディングされてから配置されることになります。
一方、X, Z, Yの順に配置するとパディングは発生しません。

パディングされて2バイト分がデッドスペースとなってしまう(図のpの領域)
PostgreSQLではテーブル定義時の記述順がそのまま物理的な配置にリンクするため、カラム名を書く順番の違いでこのような差が生まれます。
行数が少なければさして問題になりませんが、レコード数が億単位になるような巨大な連携データ(お客さんから連携される生データなど)をローディングする際は、パディングを減らすだけで何GBも削減できることさえあります。
このように、CREATE TABLEする際にアラインメントに応じて隙間なく敷き詰めることを俗に"カラムテトリス"とも言うようです。ユーモアのある呼び方ですよね。
ノウハウ6: 事前計算
オンラインで行う計算が少なくなるよう、特に頻繁に実行される計算はDB作成時にあらかじめ用意しておくことも有効です。
よくある例としては、型のキャストが挙げられます。一見些細に思えるようなキャストも思いのほか処理時間を要することがあるので、オンラインクエリで発生させないよう注意します。
特に、気付かないうちに暗黙のキャストが発生してしまうケースはよくあるため、テーブル作成時点でカラムの型と関数の引数の型をしっかり合わせる等、普段から暗黙のキャストをさせない癖をつける必要があります。
他にも、ソートキーや結合キーが複数ある場合に、採番し直したソート用のカラムを作っておくこともあります。
宿泊施設の並び替えなどは多い時で4つ5つのソートキーが指定されることもありますが、仮にこのうち2つが前に並んでいればそれを統合して1つのキーとすることで、テーブルも小さくなりオンラインでの計算も速くなります。
これらはノウハウ1での「テーブルサイズ削減」とのトレードオフにもなるため、データサイズやクエリの実行頻度に鑑みて、どこまで事前計算するか慎重に検討します。
ノウハウ7: インデックス作成の工夫
これは一般にもよく言われていることですが、適切なインデックスを作成することで特定行の抽出を高速化できます。
一方で、当然インデックス自体もサイズを持つため、作りすぎるとメモリをひっ迫してしまい、本来メモリに載せておきたいサーチテーブルが追い出されてしまいます。データの偏りや分布を見て、本当に有効な絞り込みのカラムに対して付与することが必要です。
「99%が0で1%が1」というようなデータであれば、1%の方にだけインデックスを付けること(部分インデックス)も有効です。
また、具体的にインデックスを作成するカラムの見極め方として、サービスイン後にPostgreSQLの統計テーブルpg_stat_all_tablesを見てseq scanの回数を確認する方法もあります。行数が多いテーブルをseq scanしているようであれば、インデックスが効きそうなテーブルを探して後から付与する、というのも慣用手段です。
(統計テーブルについては以下の記事でも触れているのでぜひご覧ください)
その他(2023/5/9追記)
「特定の理由でフォルシアでは積極的に採用していないが、一般的に考えられる手法」についても軽く触れておきます。
パーティショニングやシャーディング
特定の行や範囲にアクセスが集中する場合、絞り込み条件に応じたテーブルのパーティション分割によって、スキャン対象を絞り込むことができます。
また、データ同士の関連性が低い、アクセスパターンが分散しているような場合であれば、DB自体をシャードに分割することによって、負荷分散が可能です。Postgresでは、Citusなどのシャーディング拡張を利用することになります。
フォルシアの検索においては、以下のような理由で有効な分割ができず、ほぼ利用していません。
- 検索条件が多くほぼ常に複数カラムでの絞り込みになること
- 「日付を指定せず検索」「全国で検索」などの横断的な検索があること
- 「部屋割り・泊数を計算した料金順」でのソートがあること
マテリアライズドビュー
ノウハウ6: 事前計算の章では扱いませんでしたが、高頻度で実行されるクエリや複数クエリにまたがって利用される計算がある場合には、マテリアライズドビューを用いることも効果的です。
フォルシアでは以下の理由でマテリアライズドビューに頼ることはあまりありません。
- 全件更新によって検索用テーブルをこまめに作り直している
- 計算量が多く中間テーブルが必要になるため直接的にマテリアライズドビューにしづらい、更新コストが高い
- 検索条件が多くクエリのパターンが膨大
技術選定
フォルシアの検索アプリケーションにおいては、極めて複雑な商品構造に対応するにあたってRDBが適していること、参照が中心のため追記型アーキテクチャもほぼ問題にならないこと、拡張性が高いことなどからPostgreSQLを採用していますが、アプリケーションや機能の特性に応じた技術選定が重要です。
たとえば、集計処理が占める割合が高ければ列指向拡張やインメモリDBの活用、テキストデータの検索や解析がメインであればElasticsearchやSolrなどの全文検索エンジンの導入も選択肢に入るかと思います。
フォルシアでもアプリケーションによっては部分的に列指向のインメモリDB(Rust,Java)を実装していたりキーワード検索にElasticsearchを使用していたりするほか、参照性能に特化する必要がない検索領域以外のプロダクトでは一般的なDB構成になっています。
いずれの場合も、アプリケーションの要件や問題箇所を見据えて手段を吟味する必要があります。
銀の弾丸はない
さて、ここまで検索高速化のためにフォルシアで行っている具体的な手法の例をいくつか述べてきました。一方で、「これをやっていれば完璧」という万能薬はありません。
フォルシアのエンジニアは受け取った実際のデータ特性に合わせて、ボトルネックとなるような処理に対して様々な方法を駆使して、細かな改善を日々繰り返して高速化を実現しています。
時には思うように効果が出ないこともありますが、エンジニアとしてはこれこそチャレンジングな部分であり、気持ちよいほど改善ができたときはやりがいを強く感じる部分でもあります。
最後に
高速化に終わりはありません!フォルシアでも日々試行錯誤を続けています。
直近では、さらなる開発体験/パフォーマンス向上のため、先述のC関数による独自拡張をRustで書き換えていく取り組みも絶賛進行中です。
また、フォルシアでは、近年は検索以外のプロダクト(旅行業界の商品造成など)も手がけており、DBに求められる役割も、必要な知識も大きく広がっています。
まだまだ紹介したい内容はありますが、記事が長くなってしまうため今回はここまでとします。
あくなき探求心で高速化を追求したいという方、もっと詳しく話を聞いてみたいという方はぜひお気軽にご連絡ください!
この記事を書いた人
谷井 嶺太
2019年新卒入社 旅行プラットフォーム部エンジニア。
自社SaaSプロダクトの改善開発ユニットリーダーの傍ら、技術広報の企画・運営を担当。
最近ようやくホットクックを買いました。
フォルシアではフォルシアに興味をお持ちいただけた方に、社員との面談のご案内をしています。採用応募の方、まずはカジュアルにお話をしてみたいという方は、お気軽に下記よりご連絡ください。

Discussion