はじめに
第1旅行プラットフォーム部長の武田です。これまで検索アプリケーションの開発をメインに担当していましたが、最近は検索で利用する商品データを作成するサービスの開発をしています。
慣れ親しんだ検索アプリケーションとは異なりますが、そのノウハウを活かしつつ、新しいことに取り組んでいます。今回はそのサービス開発で利用している技術についてご紹介いたします。
フロントエンド
Next.js
フォルシアではアプリケーション開発で社内製のWebアプリケーションフレームワークを利用しています。現在は3代目までのWebアプリケーションフレームワークが存在します。3代目のフレームワークは内部でNext.jsを利用しています。そのためNext.jsを採用するのは自然な流れでした。
この社内製Webアプリケーションフレームワーク開発の話はこちらです。
なお、今回開発しているアプリケーションは検索アプリケーションではなく、主にデータを登録する管理画面系のアプリケーションとなっています。通常のSpookの開発とは大きく異なるアプリケーションのため社内製フレームワークは利用しませんでした。
個人的には今回のアプリケーションではSvelteの採用もありかと考えましたが、以下の理由から見送っています。
- Reactでの開発に慣れているエンジニアが多い
- アプリ開発の規模も大きく、Svelteでどこまでうまく対応できるか未知数
antd
デザインシステムとしてantdを採用しています。
- MUI(旧Material-UI)と比較して管理画面向けのコンポーネントが多い
- Form関連のコンポーネントも強力で、不要な再レンダリングが発生しないようになっている(React hook formも良い評判を良く聞きます)
- コンポーネントだけでなく、ガイドラインやデザインパターンについてのドキュメントも多く充実している
といった点で採用しました。
現状、Next.jsでantdを利用していると特定のコンポーネントを使用した際に以下のWarningが出ます。
Warning: useLayoutEffect does nothing on the server, because its effect cannot be encoded into the server renderer's output format. This will lead to a mismatch between the initial, non-hydrated UI and the intended UI. Toavoid this, useLayoutEffect should only be used in components that renderexclusively on the client. See https://reactjs.org/link/uselayouteffect-ssr for common fixes.
これはantdが内部的に利用しているrc(react-component)がSSR対応されておらず、useLayoutEffectフックを利用しているためです。
対応自体は進められており、近い将来解消すると思われます。
Storybook
今回の案件では、エンジニアがスタイリングを含めてコンポーネントを開発しており、Storybookを利用しています。
GitLab CIを利用して、mainブランチをpushしたタイミングでStorybookをbuild、生成したhtmlをS3+CloudFrontにアップし、常に最新のコンポーネントを全メンバーが確認できる状態にしています。
Storybookを用意することでエンジニア以外のプロジェクトメンバーもどのようなコンポーネントがあり、開発中のデザインがどうなっているか確認できるというメリットがあります。
現時点ではコンポーネントの設計等も頻繁に変わるような開発初期段階のため、Storybookを利用したテストは書いていませんが然るべきタイミングでスナップショットテストを含むコンポーネントのテストを実装していこうと考えています。
Apollo client
データフェッチのライブラリとしてApollo clientを採用しています。
GraphQLを利用しており、バックエンドで生成したGraphQLのschemaとGraphQL Code GeneratorのTypeScript React Apolloプラグインを利用して、hookを自動生成しています。
状態管理のライブラリとしてrecoilを使いたいと思っていますが、現時点ではGlobalな状態管理が必要になるケースがそこまでなく、Context APIやuseState hook等で十分な可能性があります。
このあたりは開発を進めていく中で検討できればと考えています。
バックエンド
NestJS
バックエンドのフレームワークとしてNestJSを採用しました。
- 協力会社のエンジニアさんはJavaでの開発に慣れたエンジニアが多い
- 社内のエンジニアはJavaScript, TypeScriptでの開発に慣れたエンジニアが多い
という状態でした。将来的には社内でメンテナンスしていくサービスになるため、開発言語をJavaにしてしまうと運用時に厳しくなる可能性が高いと考えました。
JavaのSpring Frameworkのような書き味のNestJSを採用することで双方が開発、運用しやすい形にできるのではと考え採用しました。
こちらはYahoo! JAPAN さんのこちらのTech Blogも参考にさせていただきました。
デコレータやDIを利用した開発は私含め社内のエンジニアも慣れておらず、若干の取っ付きにくさを感じましたが、慣れてくるとまさに関心の分離により、メインのロジックに集中できるように感じました。
また、協力会社のエンジニアさんからも書きやすいという声をいただき、採用して良かったと思いました。
NestJSはGraphQL Serverとして実装していて、デコレータをたくさん書く必要がありますがcli-pluginを導入することにより、記述量を大きく削減できました。
GraphQLについて
NestJSはGraphQL Serverとして実装しています。
今回のアプリケーションでは非常に多くの画面が存在し、それに伴いAPIの数も多くなることが見込まれました。
参照でGETのエンドポイント、データの追加でPOSTのエンドポイントを用意、データの更新ではPUT/PATCHといったエンドポイントを用意して...となると考えることも多く、特にRESTfulなAPIを設計する場合にエンドポイントの設計だけでも膨大な時間がかかってしまう可能性がありました。
GraphQLではデータ取得はquery、データを操作する際はmutation、あとはハンドラメソッド名を考えれば済むため、地味ではありますがエンドポイントについて考える時間はかなり短縮された感覚です。
GraphQLでは「フロントエンドでの取り回しは楽になるが、バックエンドの実装は複雑になる」といった話を何度か耳にしたことがあります。開発を進めてみてNestJSがよくできているのか、そこまで複雑になっている印象はありません。
現時点では、GraphQLのバックエンドの実装は通常のWeb APIとそこまで変わらないように感じました。
実際、REST APIで開発するか、GraphQLにするかは非常に悩んだポイントではありますが、チームメンバーの使ってみたさあります!という声やメルカリ Shops さんの記事も採用の後押しになりました。
コードファースト?スキーマファースト?
NestJSでGraphQL Serverを実装する際にコードファーストで進めるか、スキーマファーストで進めるか、という点がひとつ悩ましいポイントかと思います。
今回のプロジェクトではコードファーストのアプローチを取ることにしました。
理由は以下のとおりです。
- フロントエンドの開発をした人がそのままバックエンドのAPIも実装する形式になっている
- フォルシアではフロントエンドとバックエンドでエンジニアが分かれておらず、どちらも実装する
- そのためスキーマベースで認識を合わせる必要がない
- モノレポ構成となっており、フロントエンドとバックエンドのコードが同一リポジトリで管理されている
こちらは毎週実施している技術ディスカッションという社内MTGの場で相談したところ、上記のようなコメントをいただき、コードファーストで進めることにしました。
実際、コードファーストで進めてみて快適に開発できている印象です。
Prisma
ORMとしてPrismaを利用しています。
通常はPrisma schemaによるモデリングでデータベースの設計をしていくかと思いますが、フォルシアには独自のschema定義を用意してデータベースを構築する仕組みがあります。
データベースの構築は独自の仕組みを利用し、Prismaとの連携では prisma db pull(旧prisma introspect)コマンドを利用してprisma.schemaファイルを生成しています。
データベースからのデータの取得が型安全になり、TypeScriptで補完が効く点も非常に良い開発体験が得られています。
一方、私含めフォルシアのエンジニアはパフォーマンス面も考慮したSQLを書くことを得意としていますが、PrismaのようなORMで効率的にデータを取得するノウハウは少ないため、少しずつ知見を貯めていければと考えています。
Prismaは周辺ツールも強力で、初期開発時のサンプルデータの作成ではprisma studioを利用しています。
資金調達もしており、引き続き活発な開発が進められていくことが見込まれる点も採用を後押ししました。
schemaspy
今回の案件では外部サービスからデータベースにアクセスするケースもあるため、テーブル定義書を用意する必要がありました。
schema定義と別でテーブル定義書を作成するのではなく、構築したデータベースからschemaspyを利用して定義書を生成するようにしました。
また、テーブルやカラムの論理名を表示したいという要件がありました。
PostgreSQLではテーブルやカラムに対してコメントを付与する機能があるため、こちらを利用しました。
- コメントの1行目が論理名
- 2行目以降がテーブル、カラムのコメント本文
として、schemaspyをforkして機能を追加することで日本語の論理名も一緒に表示できるよう対応しました。
この機能を追加したもののソースコードはこちらに公開しています。
生成されるテーブル定義書は以下のようになります。
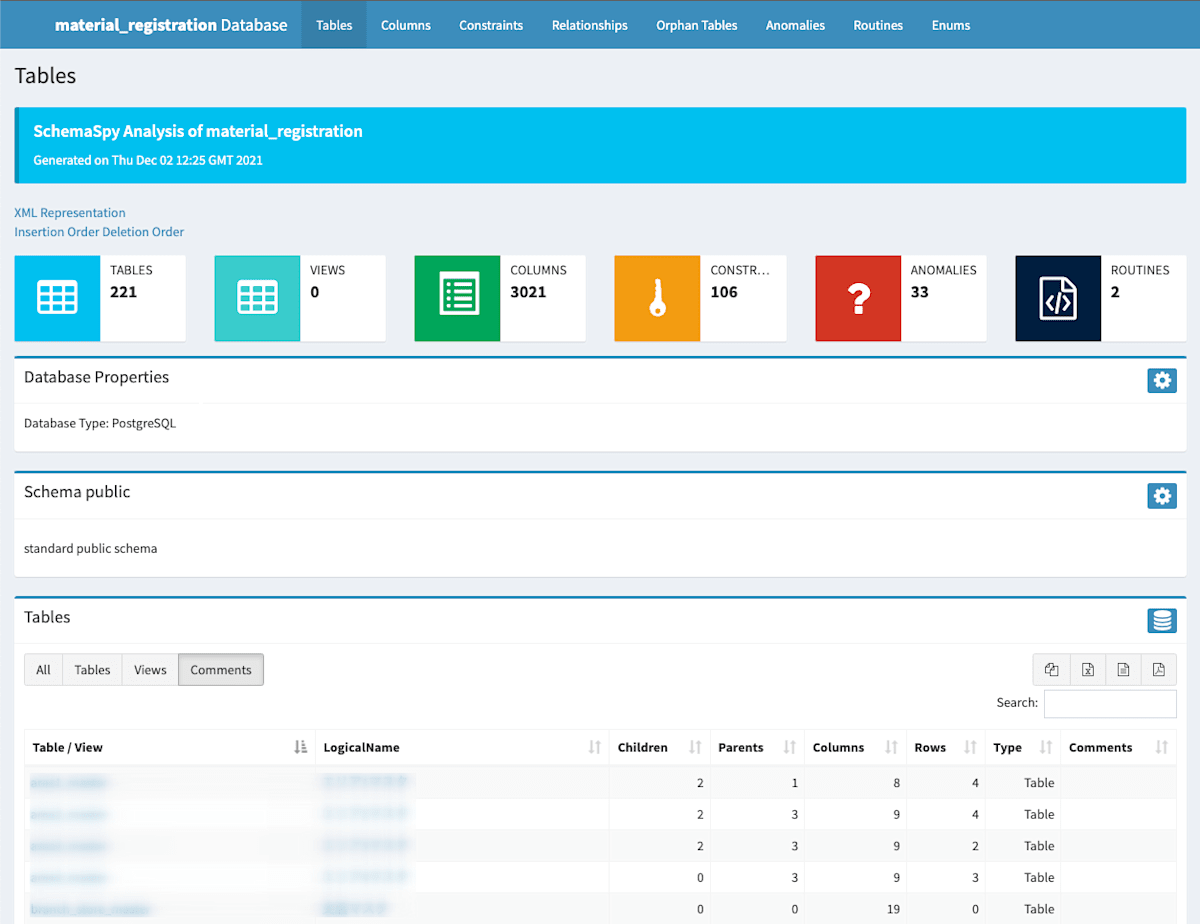
こちらもStorybookと同様にGitLab CIを利用してmainブランチにマージされたタイミングで最新のテーブル定義書がbuildされ、Web上で確認できるようにしています。
Dockerの利用について
開発環境ではDockerを利用して、各プロセスはすべてコンテナで動作するようになっています。
環境構築用のinit scriptも用意しており、手元の環境にDocker、Docker Composeをインストールしておけばすぐに開発に入れるようになっています。
また、バックエンドのNestJSで生成したGraphQLのschemaファイルは変更があったタイミングでフロントエンドのコンテナに同期されます。
これはchokidar-cliを動かすコンテナを別で用意して実現しています。
これによりフロントエンド側で参照していたフィールドを削除したケースなどは型エラーとして即時検知できます。
docker-compose up すれば自動生成ファイルの連携含めて、ホストマシン側では特に何のプロセスも動かさずに開発できるように、ということを意識しています。
バッチ処理まわり
- 外部サービスから連携データを取得し、取り込み
- 外部サービスへの連携データを生成
といったバッチ処理も存在します。こちらはSQLやshellコマンドなどを柔軟に実行する社内独自の仕組みを利用して実装しています。
実際に開発が進んできての印象
- デザインを含めてエンジニアが実装していますが、デザインの調整にかなりの実装時間を割いてしまっている
- デザインの経験があるエンジニアが少なく、慣れていないという点が大きいです
- GraphQL、何もわからない状態からスタートしていましたが実際には単なるインタフェースであり、Web APIと大きく変わらないと感じてからは仲良くなれてきた気がします
- GraphQLを取り巻くエコシステムがかなり発達しており、このあたりも開発体験を向上させているように感じました
- データベースのテーブル定義が変わったときのコードの変更量が多い...
- このあたりはなるべく少なくなるように、というのを意識してはいましたが...開発初期段階ではどうしてもテーブル定義に変更が入ることが多く、ここの追従をいかに楽にするかは今後の課題です
まとめ
フォルシアでは検索Webアプリケーションの開発で培ったノウハウを活かしつつ、新しい技術も取り入れながら検索以外のWebアプリケーション開発にも取り組み始めています。技術選定の際に今回の記事が少しでも参考になりましたら幸いです。
この記事を書いた人
武田 陽一郎
2012年新卒入社
先日娘の七五三がありました。娘が神社の方に「将来何になりたいの?」と言われ、祖父祖母の前で「孫になりたいです!」と答える姿に成長を感じました。

Discussion