これは何
バッチ監視と一口に言っても、単に「失敗を検知する」だけでは不十分なことがある。
本記事では、FOLIOのバッチを運用する中で得られた知見をもとに、「何をどのように監視すべきか」 を3つの観点から整理する。
JJUG CCC 2025 Fall の Lightning Talk で話をしたことを紹介する。
バッチシステムとは
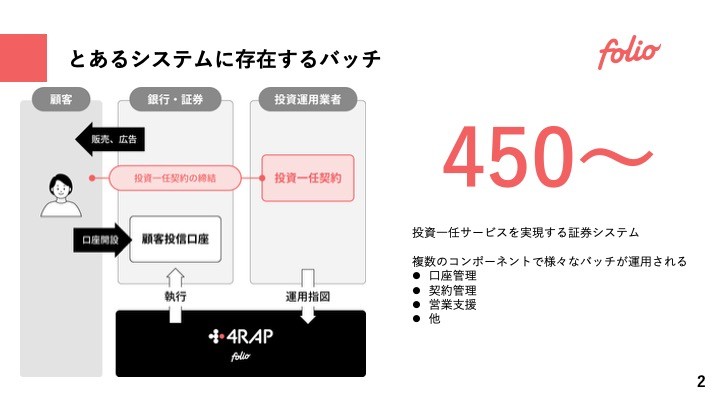
株式会社FOLIOの4RAPというサービスでは、現時点において450を超えるバッチが存在している。日次で動くものもあれば、月次で動くようなものもあり、各コンポーネント毎に必要な処理が定期的に実施されている。
バッチ監視はどのようなことをしていますか?
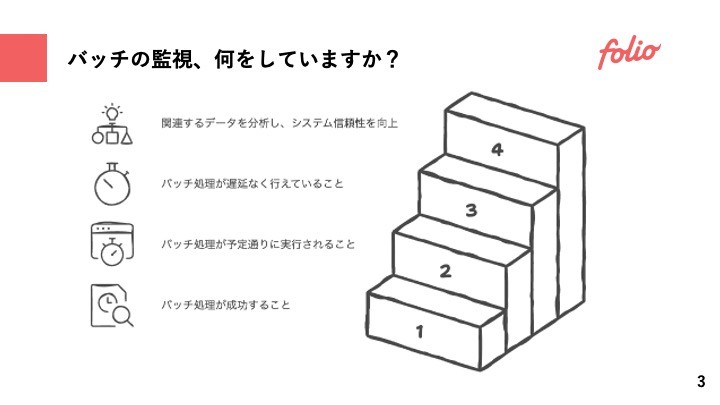
どんなサービスにもバッチ処理はつきものかと思う。ジョブスケジューラをもとに発火するものがあれば、イベントをもとに発火するものもある。
これらのバッチの監視は何をしたら良いのだろうか?
ここでは基本的な例を順取り上げつつ、トピックごとにここまで考慮出来ると良いということを個別に説明したい。
1. バッチの「成功」を確認する
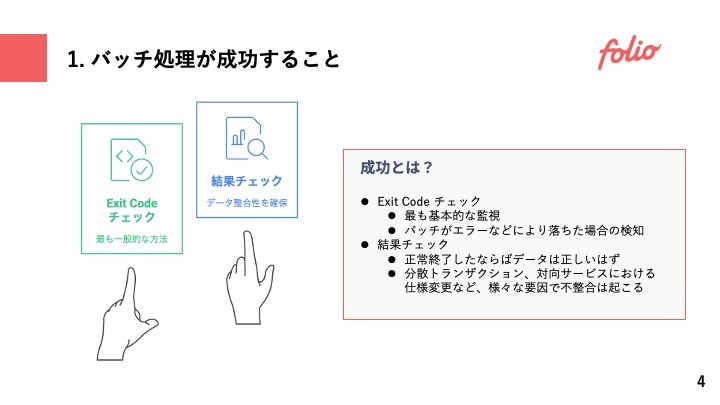
最もよくやられている監視として、バッチがエラーを出して落ちた場合の監視というものがあげられる。通常は失敗時にはExit Codeが1になるようにして処理を落として、バッチ基盤の仕組みを使いアラートまであげるのではないかと思う。
ここで注意したいのは何をもってバッチの「成功」とみなすか。
バッチが正常終了したことをもって結果整合性が取れているのがもちろん最も望ましい。一方で、そのバッチで分散トランザクションをしていたり、意図せず障害対応によりデータが書き換えられていたり...様々な要因で意図しないデータ不整合は起こり得る。サービスをまたいだ整合性の検知などは、必要に応じて別途リコンサイルなどのフローを設けることも検討が必要になる。
2. バッチの「実行開始」を検知する
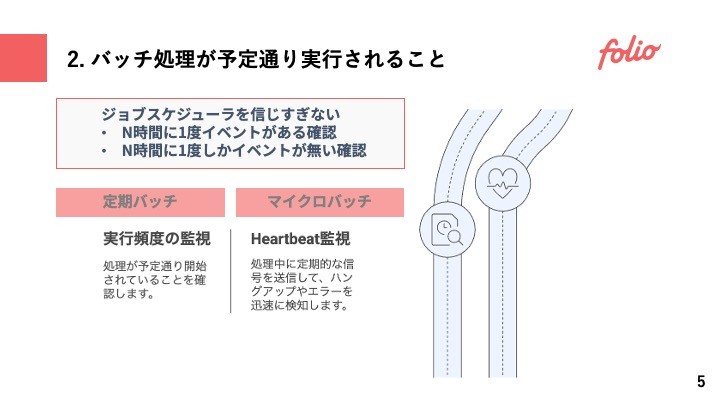
次に確認したいのは、そもそもバッチが起動されているのか?ということ。cron syntaxで24時間設定をしたので、あとはバッチ基盤にのっていれば必ず動くでしょうという勘違いはある。バッチ基盤にはバッチ基盤なりのSLOが存在しており、大手のSaaSを使っていたとしても何かしらハードウェア障害などで意図せず処理がスキップされてしまう、k8のCronJobでもdeadline次第ではqueueingされたものが処理されないことはある。
24時間に1度動くようなバッチについては24時間+αに1度イベントが届いているかを確認したいし、マイクロバッチのようなシステムではハートビートが定期的に届いているかを確認したい。
3. バッチの「遅延」を検知する
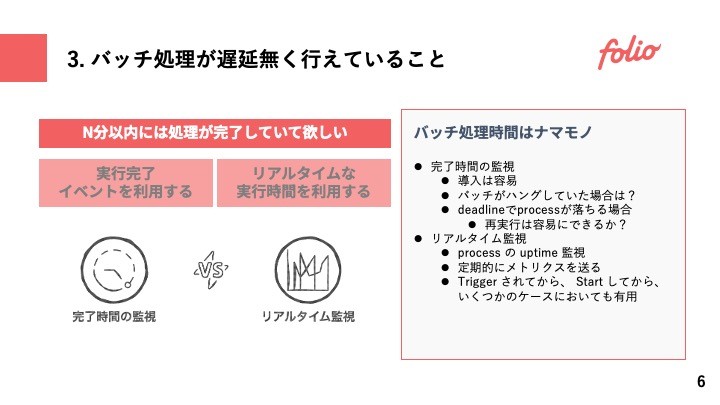
ここで言う「遅延」とは、実行時間のことを指す。毎日12時に動き始めるバッチが13時までに終わって欲しい場合には、バッファを設けて閾値40分などで監視をしたい。
様々なバッチ基盤においては、バッチ処理が完了した際にイベントやメトリクスを送出していると思う。最も簡単な監視方法はそのイベントやメトリクスを見て、40分を超えていたら警告を鳴らすこと。
一方この方法でもデメリットが存在しており、仮に処理に60分を超えてしまった場合には、検知自体が60分を超えた時刻になってしまう問題がある。この問題の解決案として例としてk8s Jobなら activeDeadlineSeconds のような設定をすることも考えられるが、deadlineを超えた際にprocessを終了させてしまうような処理には注意が必要だ。仮に再実行をしたとしても、再実行性が考慮されていない場合に、また再実行の際にdeadlineによりprocessが落とされてしまうこともある。
処理時間の監視は、終了イベントではなく uptime のような実行中に定期的に送られるメトリクスで監視をすることが望ましい。それによりジョブが終了していなくても閾値を超えた際の検知が出来るし、仮に超えたとしても処理を止めるかは人が判断することが出来る。
再掲: バッチ監視はどのようなことをしていますか?
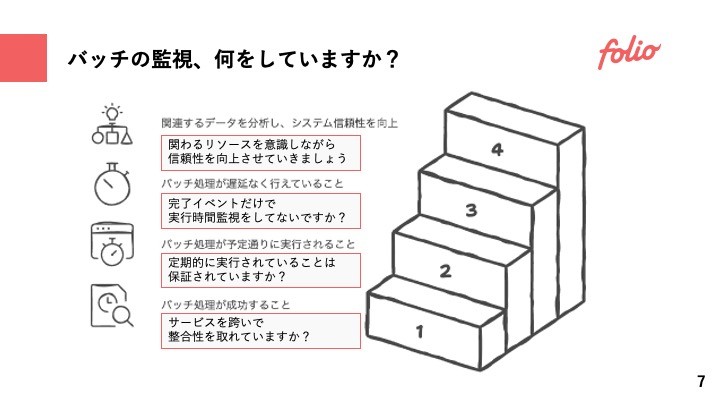
これ以外にもcpuやmemoryのようなリソース監視や、外部middlewareの監視など、バッチ処理に関わる監視は信頼性を向上させるためにも必要になってくる。
締め
たかがバッチ監視、されどバッチ監視。
監視設計の粒度が、バッチの信頼性と運用負荷を大きく左右します。
明日の朝を安心して迎えられるように、もう一度自分たちの監視を見直してみませんか?

Discussion