はじめに
2022/07から株式会社FOLIOで働いている田口と申します。
私が所属しているチームは、4RAP というプロダクト(金融機関の「投資一任サービス」を実現する SaaS 型プラットフォーム)において、金融機関とのデータのやり取りを行うインターフェイス部分の開発・運用を担当しています。
転職して驚いたことの一つとして弊チームにおいては、業務の中心に設計書が存在するということです。
そうあるべきではあるものの、メンテが行き届いておらず設計書を信用できなくなっている会社が多いのではないかと思うのですが、弊チームは本当に設計書が業務の中央にしっかりと鎮座しています。
設計書を中心とした業務について
弊チームでは、
- バッチや API を実装する際は、設計書と表現をなるべく一致させることが一つの価値観になっている。
- そのくらい、実装前の時点で設計書が完成されている状態になっているし、改修時もまずは設計書から修正して実装を行うなどの工夫がされている。
- 障害対応時は、該当のログ・DB・設計書の三点を参照して調査を進め、これらで説明がつかなかった場合、最後に設計書と実装で不整合な状態になっているかの確認をする為にコードを見に行く。
と言ったことが行われています。
設計書と実装が乖離したり「結局コード見ないと仕様がわからないよね」「コードが仕様書」という世間でよく見る状態は、弊チームでは起きていませんしそれが起こらないように細心の注意が払われています。
また、チーム管轄のすべてのバッチ・API に対して設計書が書かれており(設計書をもとに実装されており)2025年現在、その数は400を超えるとのことです。
設計書とロギングについて
「実装の詳細や依存した内容は書くべきではない」という考え方を持って設計書は作られており、当然実装の詳細であるロギングに関しては設計書には登場しません。
どのようなログを出力するべきか、と言った指標としてエンジニアで定めているコーディングガイドラインの一つとしてロギングに関する項目が存在すると言った形になっています。
基本的には設計書と実装は完全に一致していて、設計書とコードを突き合わせたときに素早くマッピングできる状態になっているのですが、ロギングの事情(または、ログ出力を副作用とした扱う Scala + Cats Effect を使用している性質上)で、設計書と実装の表現として若干の差異が発生する場合があります。
本稿ではその差異が発生する場合の簡単な例を紹介したいと思います。
ものすごく簡単な設計書の例(雰囲気)と実装を考える
下の画像は、設計書を一つも書いたことのない私が書いた、それっぽい雰囲気だけ持っているごくごく簡単なバッチの設計書のようなものです。こんなに簡単なバッチは実際にはないですが、こんな雰囲気で設計されている、というのは伝わるかなと思っています。
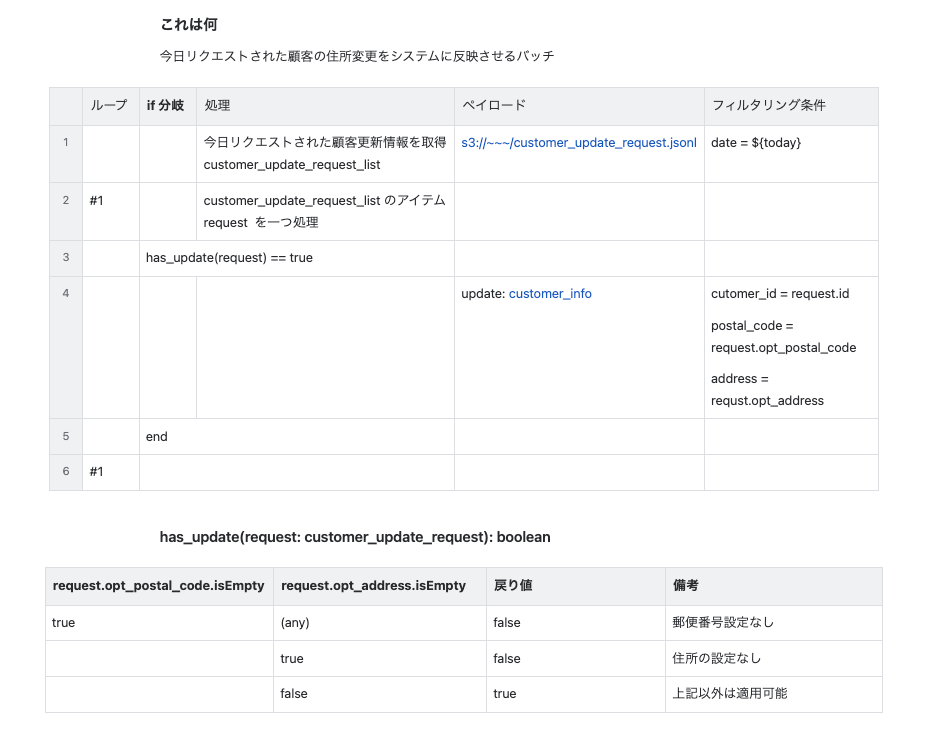
- S3 から本日分の指定されたjsonlファイルを取得して、顧客更新情報リストとして持つ
- 顧客更新情報リストをループする
- 顧客更新情報に対して更新が必要かどうか判断して、必要な場合更新を行う
ということが設計書としては書かれています。
設計書には書かれていない部分
現在、弊チームで採用しているプログラミング言語は Scala を使っており Cats(Cats Effect) という関数型ライブラリを中心に Doobie, Crice, FS2, Refined といったライブラリを主に使っています。設計書を実装する場合は、FS2.stream を使って chunk 毎に処理を行ったりするわけですが、そういう部分は設計書には書かれていません。「実装の詳細や依存した内容は書くべきではない」からですね。
同様にロギングも設計書に書くものではないですが、運用目線でどういうログがあったら嬉しいか考えると、
- S3ファイル全体の件数
- データベースが更新された件数
- 更新されなかった件数・理由
などが出力されていると、ログを見ただけでどういう処理がされたか分かりやすく調査もしやすくなりそうですね。
このような話は、コーディングガイドラインにて策定されているのですが、今回のような設計書の場合それを見落としやすい事情が隠れています。
has_update(request: customer_update_request): boolean
というように、設計上定義されている関数が戻り値、boolean を要求しているので素朴に実装するとログ出力を忘れてしまう、と言ったことが稀によくあります。順を追って説明します。
設計書を実装してみる
設計書のループ処理の内側をCustomerUpdateServiceとして実装することを考えてみましょう。
まずはテーブルのレコードを表現するクラスを作ってみます。
import CustomerInfo.{Address, CustomerId, PostalCode}
case class CustomerInfo(id: CustomerId, postalCode: PostalCode, address: Address)
object CustomerInfo {
case class CustomerId(value: Int)
case class PostalCode(value: String)
case class Address(value: String)
}
簡単のため Refined の定義などは省きますがこんな感じだとします。
import CustomerInfo.{Address, CustomerId, PostalCode}
case class CustomerUpdateRequest(id: CustomerId, postalCode: Option[PostalCode], address: Option[Address])
S3 の jsonl ファイルの一行はこのように定義できるでしょうか。
class CustomerInfoWriter {
def write(customerInfo: CustomerInfo): Unit = println(s"Writing customer info. $customerInfo")
}
更新するための writer はこのように。実際には Scala + Cats Effect の場合戻り値はIO[Unit]などになると思いますが、取り急ぎは Unit で定義します。
さて、設計書に一致する形で、CustomerUpdateServiceを実装してみましょう。
class CustomerUpdateService(val writer: CustomerInfoWriter) {
def run(request: CustomerUpdateRequest): Unit = {
if(hasUpdate(request)) {
writer.write(CustomerInfo(request.id, request.maybePostalCode.get, request.maybeAddress.get))
}
}
private def hasUpdate(request: CustomerUpdateRequest): Boolean =
request.maybeAddress.isDefined && request.maybePostalCode.isDefined
}
設計書通りに実装できているかと思います。
が、Option::getは運用する中で None が混じるような改修が起こることも考えると、Scala を採用しているプロジェクトではあまり使わないと思います。
Scala の Option::get を使わない形でリファクタリング
Option::getを使わないような形で実装し直してみましょう。
class CustomerUpdateService(val writer: CustomerInfoWriter) {
def run(request: CustomerUpdateRequest): Unit = {
customerInfoIfShouldUpdate(request) match {
case Some(customerInfo) => // has_update = true
writer.write(customerInfo)
case None => ()
}
}
private def customerInfoIfShouldUpdate(request: CustomerUpdateRequest): Option[CustomerInfo] = {
for {
// 郵便番号・住所がどちらも設定されている場合、更新対象として扱う。
postalCode <- request.maybePostalCode
address <- request.maybeAddress
} yield CustomerInfo(request.id, postalCode, address)
}
}
hasUpdate という関数から customerInfoIfShouldUpdate という関数を使用する形に変更しました。それにより、設計書で示されている関数と差異が出てしまいました。Option::getを使わない実装上の都合により差異が起きてしまいました。
「設計書で表現されている has_update と同等の判定が行われているのはここだよ」と示してあげるなどすると、設計書とコードのマッピングがしやすい状態を保つことができると思います。
さて、当初の目的であるロギングについて考えていきましょう。
ロギングを考慮した実装に変更
まずは、customerInfoIfShouldUpdate のインターフェイスを変えずに素朴にログを出すことを考えてみましょう。slf4j を使ってみるとして
private val logger = LoggerFactory.getLogger("CustomerUpdateService")
private def customerInfoIfShouldUpdate(request: CustomerUpdateRequest): Option[CustomerInfo] = {
val maybeCustomerInfo = for {
// 郵便番号・住所がどちらも設定されている場合、更新対象として扱う。
postalCode <- request.maybePostalCode
address <- request.maybeAddress
} yield CustomerInfo(request.id, postalCode, address)
if (maybeCustomerInfo.isEmpty) {
if (request.maybePostalCode.isEmpty) {
logger.info(s"郵便番号の指定がなかったため処理をスキップしました。 $request")
} else if (request.maybeAddress.isEmpty) {
logger.info(s"住所の指定がなかったため処理をスキップしました。 $request")
} else ()
} else ()
maybeCustomerInfo
}
ログの考慮を入れたことで、なんとグジャっとしたコードになってしまったことでしょうか。
こんなコード嫌。。。私の力量不足でもっとスッキリ同じコード書ける可能性はあると思いますが、もう少し改善していきたいですよね。
Either を返すように修正
副作用をまとめる観点からも、run 関数でログ出力はする・customerInfoIfShouldUpdate 関数の戻り値は Either にするという変更を行ってみましょう。
まずは、フィルタリングされた理由(updateされなかった理由)を表すクラスをつくります。
object CustomerUpdateService {
sealed trait FilterReason {
val id: CustomerId
def value: String
def message: String
}
object FilterReason {
case class PostalCodeNotSet(override val id: CustomerId) extends FilterReason {
override val value = "郵便番号設定なし"
override def message: String = s"顧客ID: $id, 理由: $value"
}
case class AddressNotSet(override val id: CustomerId) extends FilterReason {
override val value = "住所の設定なし"
override def message: String = s"顧客ID: $id, 理由: $value"
}
}
}
CustomerUpdateService を FilterReason を使った処理に変更してみましょう。
import CustomerInfo.CustomerId
import CustomerUpdateService.FilterReason
import CustomerUpdateService.FilterReason.*
import org.slf4j.LoggerFactory
class CustomerUpdateService(val writer: CustomerInfoWriter) {
private val logger = LoggerFactory.getLogger("CustomerUpdateService")
def run(request: CustomerUpdateRequest): Unit = {
filterReasonOrCustomerInfo(request) match {
case Right(customerInfo) => // has_update = true
writer.write(customerInfo)
case Left(filterReason) =>
logger.info(filterReason.message)
}
}
private def filterReasonOrCustomerInfo(request: CustomerUpdateRequest): Either[FilterReason, CustomerInfo] = {
for {
// 郵便番号・住所がどちらも設定されている場合、更新対象として扱う。
postalCode <- request.maybePostalCode.toRight(PostalCodeNotSet(request.id))
address <- request.maybeAddress.toRight(AddressNotSet(request.id))
} yield CustomerInfo(request.id, postalCode, address)
}
}
処理の分岐がなくなってスッキリするとともに、副作用が run にまとめられました。
先ほどの処理との違いとして Either を使ってしまったせいで、郵便番号と住所ともに存在しない場合に「住所の設定なし」のログが出なくなってしまいました。
複数のログを出せるように変更する
Scala + Cats を使っている場合、Cats に定義されているデータ構造である Validated, NonEmptyList そしてValidated[NonEmptyList, A]のエイリアスである ValidatedNel を使うと、複数のログを出せるように簡単にコードを変更できるので、filterReasonOrCustomerInfo のインターフェイスは変えずに ValidatedNel を使った理由の累積可能なコードに変更してみましょう。
まずは、FilterReason に複数の FilterReason を持てるクラスを追加します。
object CustomerUpdateService {
sealed trait FilterReason {
val id: CustomerId
def value: String
def message: String
}
object FilterReason {
case class PostalCodeNotSet(override val id: CustomerId) extends FilterReason {
override val value = "郵便番号設定なし"
override def message: String = s"顧客ID: $id, 理由: $value"
}
case class AddressNotSet(override val id: CustomerId) extends FilterReason {
override val value = "住所の設定なし"
override def message: String = s"顧客ID: $id, 理由: $value"
}
case class FilterReasons(values: NonEmptyList[FilterReason]) extends FilterReason {
override val id: CustomerId = values.head.id
override val value: String = values.map(_.value).toList.mkString(", ")
override def message: String = s"顧客ID: $id, 理由: $value"
}
}
}
続いて filterReasonOrCustomerInfo を変更します。
private def filterReasonOrCustomerInfo(request: CustomerUpdateRequest): Either[FilterReason, CustomerInfo] = {
(
request.maybePostalCode.toValidNel[FilterReason](PostalCodeNotSet(request.id)),
request.maybeAddress.toValidNel[FilterReason](AddressNotSet(request.id))
)
.mapN((postalCode, address) => CustomerInfo(request.id, postalCode, address))
.leftMap(FilterReasons(_))
.toEither
}
こうすることで、複数のフィルタ理由があった場合でも複数の理由をログとして出力することができるようになりました。
Scala + Cats Effect を使っている場合
Cats Effect を使っている場合、副作用であるログ出力はコンテキストに包まれた結果として表現されます。その場合でも、今回のように副作用をなるべくまとめておくと run 関数の戻り値が変わるだけで表現することができます。
def run(request: CustomerUpdateRequest): IO[Unit] = {
filterReasonOrCustomerInfo(request) match {
case Right(customerInfo) => // has_update = true
writer.write(customerInfo)
case Left(filterReason) =>
logger.info(filterReason.message)
}
}
おわりに
弊チームにおける設計書の立ち位置と、設計書には現れないロギングの考え方の一端とコード例を紹介しました。
設計書を中心にした業務の中で、実装上どうしても乖離が発生する場合、コメントなどを工夫してそのコードが設計書ではこれと同義であると示してあげると(今回は// has_update = trueなど)、運用目線としてはいいかもしれないと思ってます。
そのほかには設計書の乖離を少なくするために、戻り値は全然 boolean じゃないけど、関数名を hasUpdate にするみたいなことも考えられるかもしれません。
色々ツッコミや工夫する余地がまだまだあると思いますが、FOLIO での実装の仕事の一部が雰囲気でも伝わったら幸いです。
この記事を読んで「もっと詳しく話が聞きたい」や「うちだとこういうことやっているよ」みたいに話していただける方がいらっしゃったら、私の X に DM などいただけると幸いです。
https://x.com/nozomitaguchi

Discussion