拡散モデルでの新しい概念の学習まとめ
Stable Diffusionが登場してから特定の概念を生成させる研究が多く登場しました. 最近はLoRAで学習させるようなものが主流な気がしますが, 初期に登場したTextual InversionやDreamboothといった研究は幅広くされています. ここでは, 5月の最新サーベイ論文A Survey on Personalized Content Synthesis with Diffusion Modelsを基にそれらの方向性を確認したいと思います.
図や表はことわりのない限り, このサーベイ論文からの引用となります. また, 論文リンクはできるだけarXivでないもの (ACMやPMLRやOpenReview)などを載せていますが, CVPR2024の論文はarXivになっています.
この論文では新規概念学習のことをPersonalized Content Synthesis (PCS)と呼んでおり, 以降でもPCSと表記します.
PCSは2022年の8月に初めて登場して, それほどしか経っていませんが, 150を超える論文が発表されており, 非常にホットな分野と言えます.
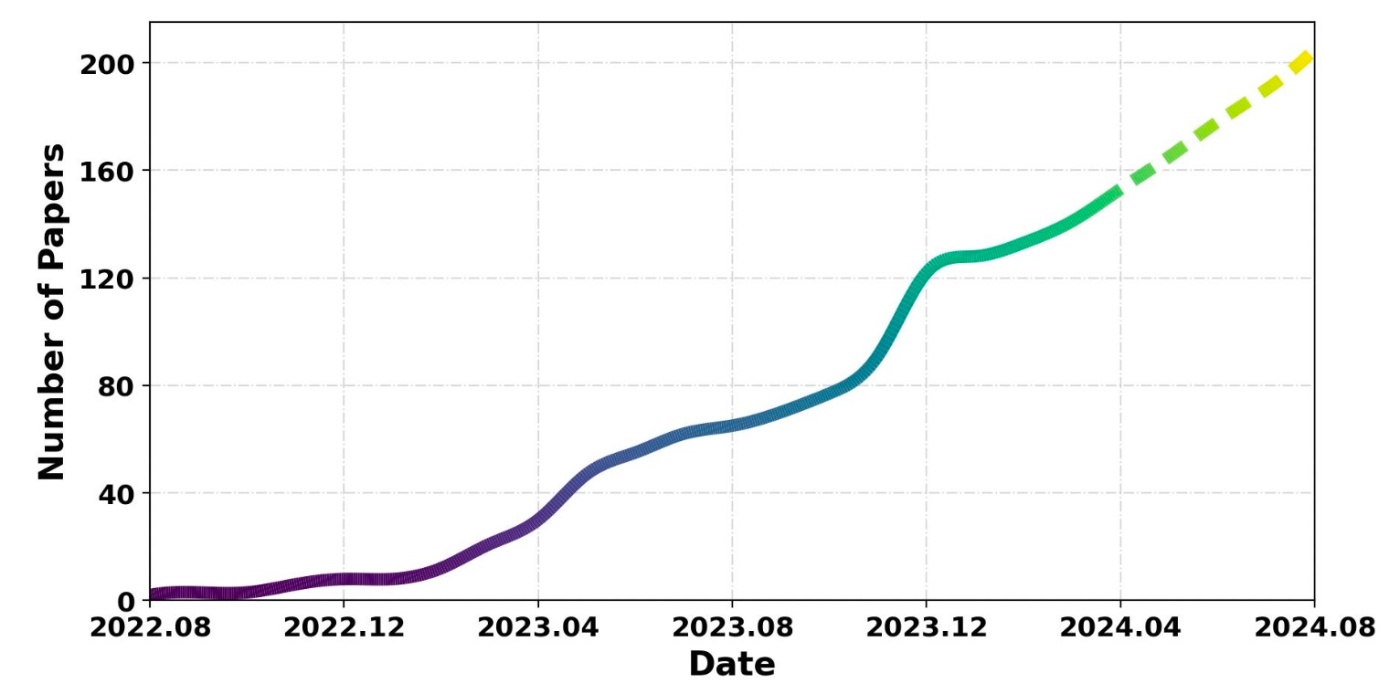
PCSの累計論文数の推移. 点線は著者らによる予測.
PCSとは?
PCSは数枚の画像を用いてその画像の概念を登場させる手法です. 具体的なもので言えば, 最初期に登場したTextual InversionやDreamBoothが有名です. 簡単に結果を確認すると, 以下のようなことが実現できます.

DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generationより引用
左の4枚の画像を入力として, fine-tuningなどを行うことで入力画像群に登場する犬を別のシナリオで登場させることができます. 何が嬉しいかというと, 自分の好きなものを登場させたりできます. また, 素人考えですがpersonalizedなモデルを作るときにデータセットの拡張としても利用できそうです.
PCSを実現する手法は先ほど確認した様に非常に多いのですが, 大きく2つに大別できます.
- Optimization-based method
- Learning-based method
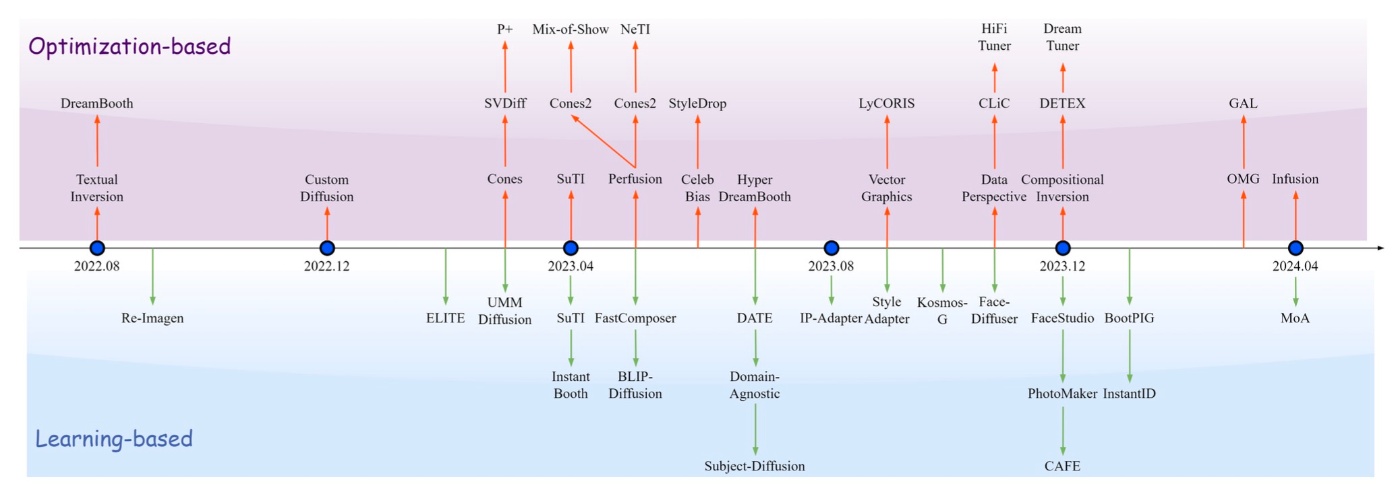
PCSの区分け. 著者らが作成.
まず, この2軸をメインとした分け方について見ていきます. なお, 拡散モデルの数理的仕組みなどは前提とし, notationも広く使われているものを採用します.
また, 用意する数枚の画像をSoI (subject of Interest)と呼びます.
まずはこの2つについて大まかにどのような手法なのかを確認します.
Optimization-based method
SoIをtext-to-imageのモデルに学ばせたいとき, textとimageのペアを用意する必要があります. imageの方はただ用意すればいいので問題ないですが, textに相当する情報はどのように用意するかが大事になります. これは主に3種類の方法に分けられます.
Learnable embedding
新しいトークンを用意して, それに対応する埋め込みを追加する手法です. 元々モデルが持っていないので疑似トークンと読んだりするようです. fine-tuningの際に重みを調整できる修飾子として機能し, 事前学習済みモデルの持つトークンには影響を与えません.
Plain text
SoIの明示的なテキストを利用します. 例えば, catやyellow catといったワードはSoI画像の猫を直接表しています. これを用いて概念を追加で学習しますが, その代わり他のcatが生成されにくくなるといったデメリットがあります.
Rare token
使用頻度の低いトークンを採用して学習済みモデルへの影響を最小限にする手法です. しかし, 使用頻度の低いトークンは有用な情報を提供できず, text embeddingは表現力に欠け, SoIを完全には再現できない可能性があります.
どの手法を利用するとしても, 結局はプロンプトが必要になります. 一般的にはTextual Inversionで見られるような, "Photo of
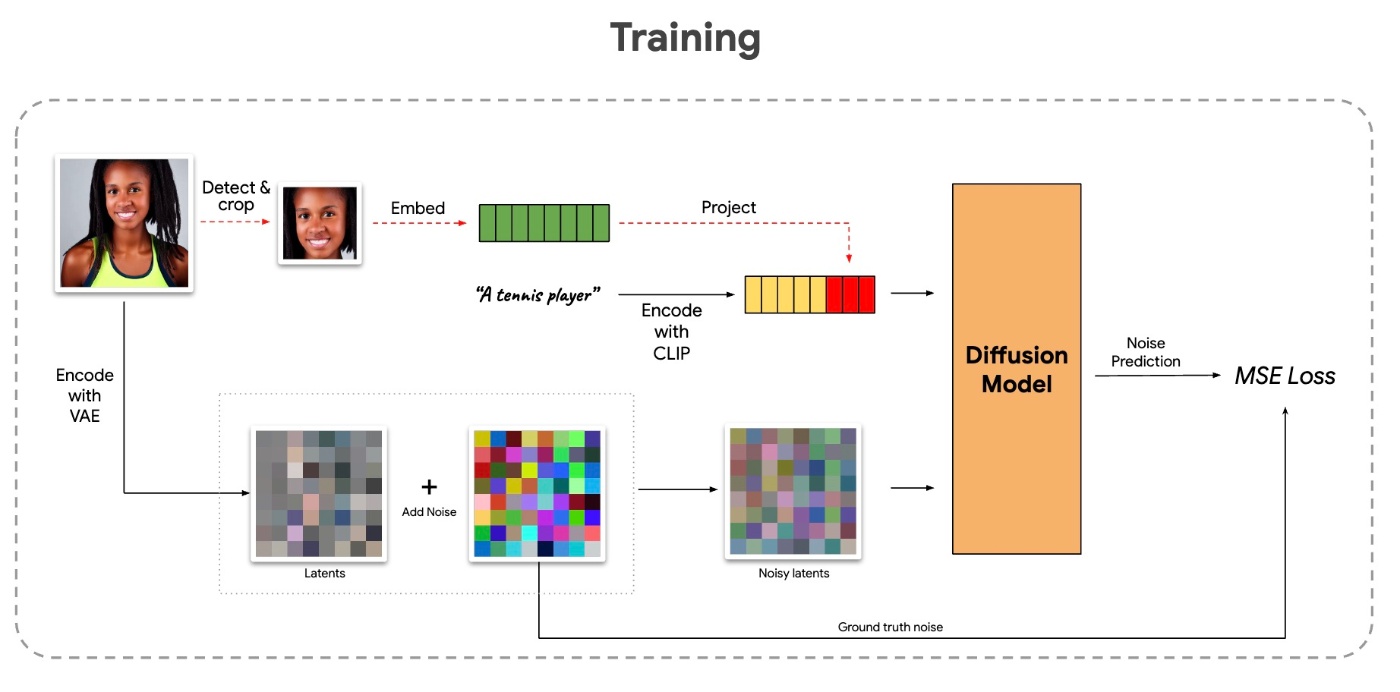
これらの手法は基本的には再構成誤差を小さくするように学習します. 図にすると下図のようになります.
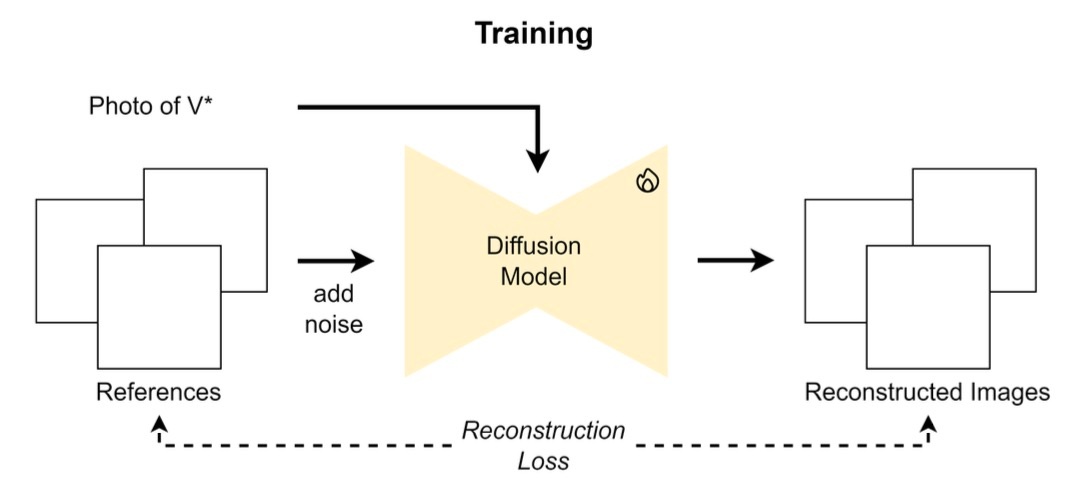
数式的には
です. 通常のdiffusion modelではノイズを予測しますが, ここでは完全にdenoiseされたデータを予測しているようです. この損失関数を用いて学習するのですが, どのパラメータを更新すればいいでしょうか. ベースとなっているStable Diffusionなどでは事前学習ではVAEとU-Netを学習します. 様々な方法が考えられますが, ここでは実例を交えて幾つかの例を紹介します.
-
トークンの埋め込み
これはTextual Inversionで採用されている手法で他には
P+ -
拡散モデル全体
これはDreamBoothで用いられている手法です.
-
全体ではなく特定のパラメータ
- Custom Diffusionではcross attentionのkeyとvalueの射影行列を更新しています.
- SVDiffでは新しい対角行列などを学習します.
- Perfusionではcross attentionのvalueの射影行列を更新します. また,keyとvalueの射影行列にはROMEに似た最適化を追加します.
-
Adapterを用意する
AdapterといえばLoRAが最も思い浮かぶものではないかと思います. LoRAを用いているものでは以下の3つの手法が挙げられます.
もちろん, LoRAを用いないAdapter-tuning手法もあり,
などが挙げられます. 例えばA Closer Look at Parameter-Efficient Tuning in Diffusion Modelsでは以下のようにAdapterを設置しています. LoRAと他のAdapter手法については少し古い論文ですがTowards a Unified View of Parameter-Efficient Transfer Learningなどが参考になると思います.
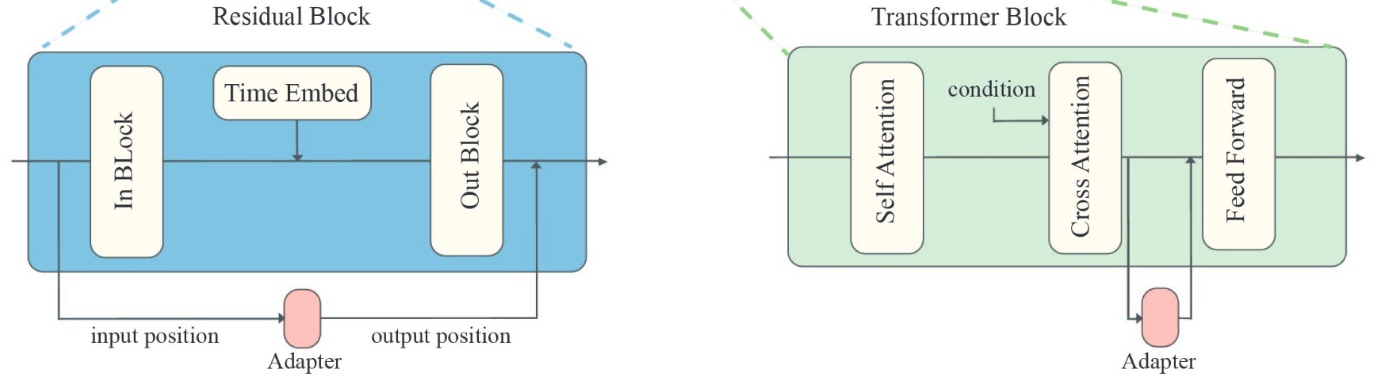
A Closer Look at Parameter-Efficient Tuning in Diffusion ModelsのFigure 3の一部を引用
基本的には多くのパラメータを更新した方が性能は良いようですが, その分時間がかかりますし, できたモデルの容量的な面でも問題があります.
Learning-based method
先ほどのクラス分けの画像を再掲します. この下の領域がLearning-based methodですが, こちらはあまり話題に上がることは少ないように思えます.
最近では, personalizedしやすいモデルを学習するという方法があります. 基本的には先ほどまでと同じで再構成誤差を基に学習をするのですが, いくつかの問題点があり, それを克服したものが論文という形で世の中に出てきます.
- Personalizedを容易に行うための効果的なアーキテクチャの設計
- 視覚的な忠実性を確保のためにSoIの情報をどのように保持するか
- 使用する訓練データの大きさ
それぞれについて見ていきます. ここでのアーキテクチャは学習の枠組みみたいなもので, 個々のモデル構造みたいなものを表しません.
アーキテクチャ
PCSのタスクでは画像とテキストを用いて学習ないしは最適化を行います. これは2つのモダリティのデータになっていて特徴の融合が必要となります. この方法に応じてLearning-based methodは2つに分けられます. placeholder-based architectureとreference-conditioned architectureです.
まず, placeholder-based architectureを確認します.
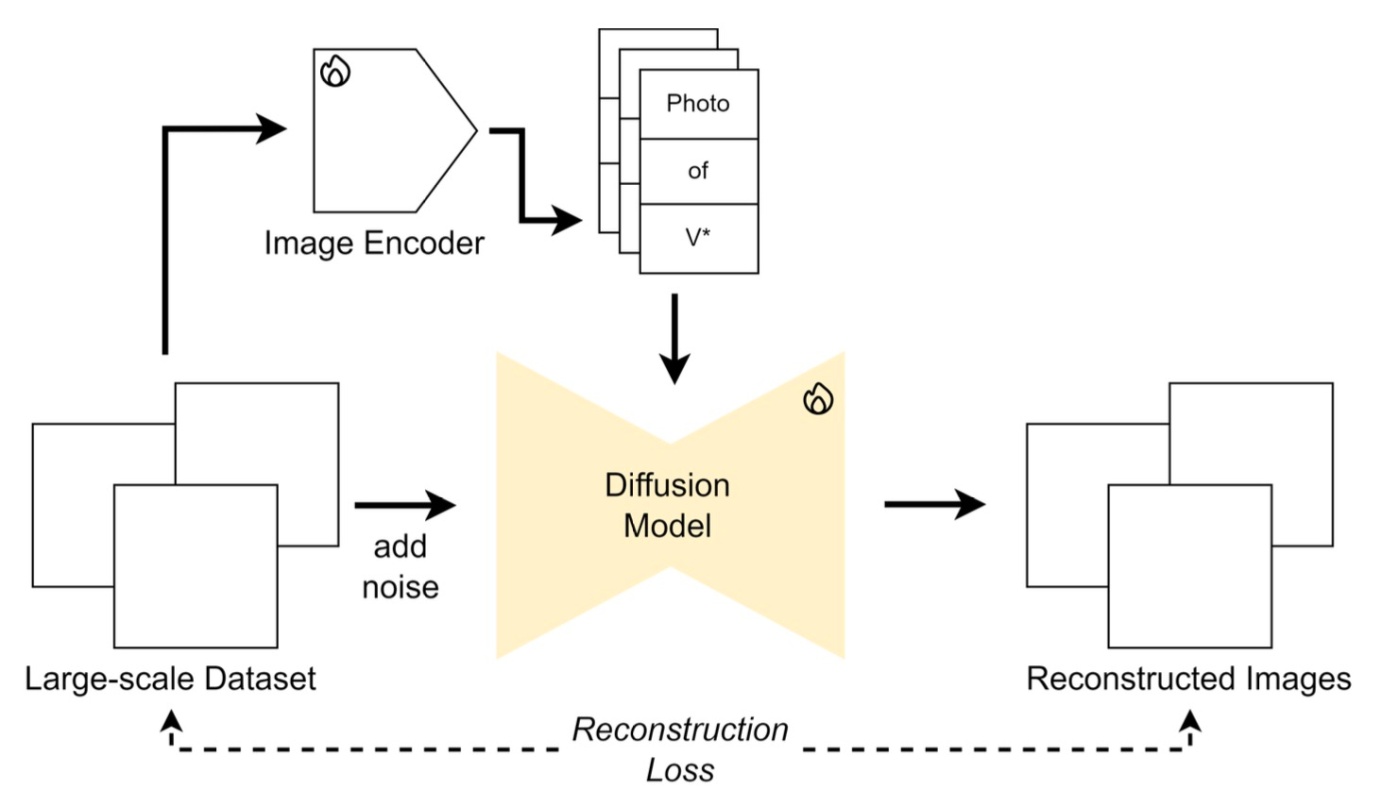
この手法では, SoIの視覚的特徴を表現するためにクラス名詞の前にplaceholderを挿入します. 簡単にいえば, textの代わりにImage Encoderから情報を取ってこようというものです.
次に, reference-conditioned architectureを確認します.
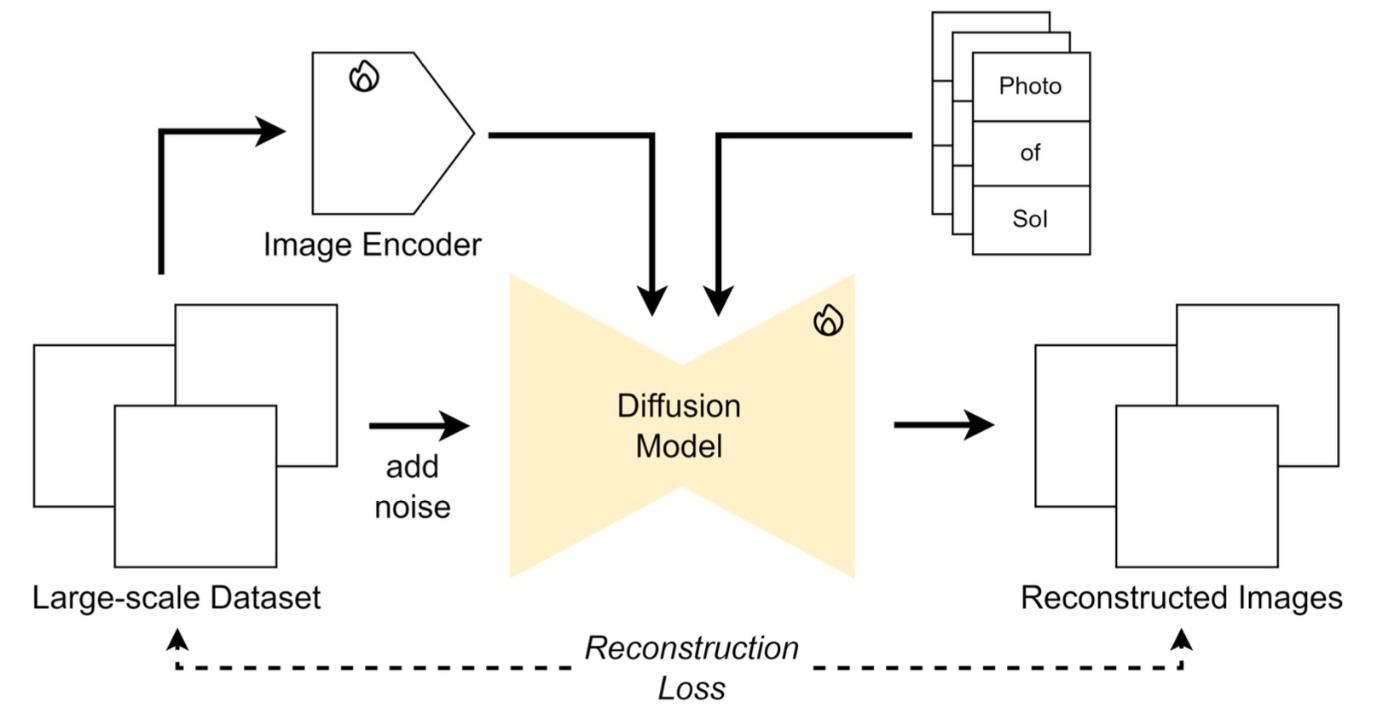
こちらではcross attentionの方を更新します. 大雑把にいえばtext以外の情報として画像の情報も条件として入力するというものです. 最も有名なものはIP-Adapterだと思います. これはcross attentionを複製してU-Netに与える手法です.
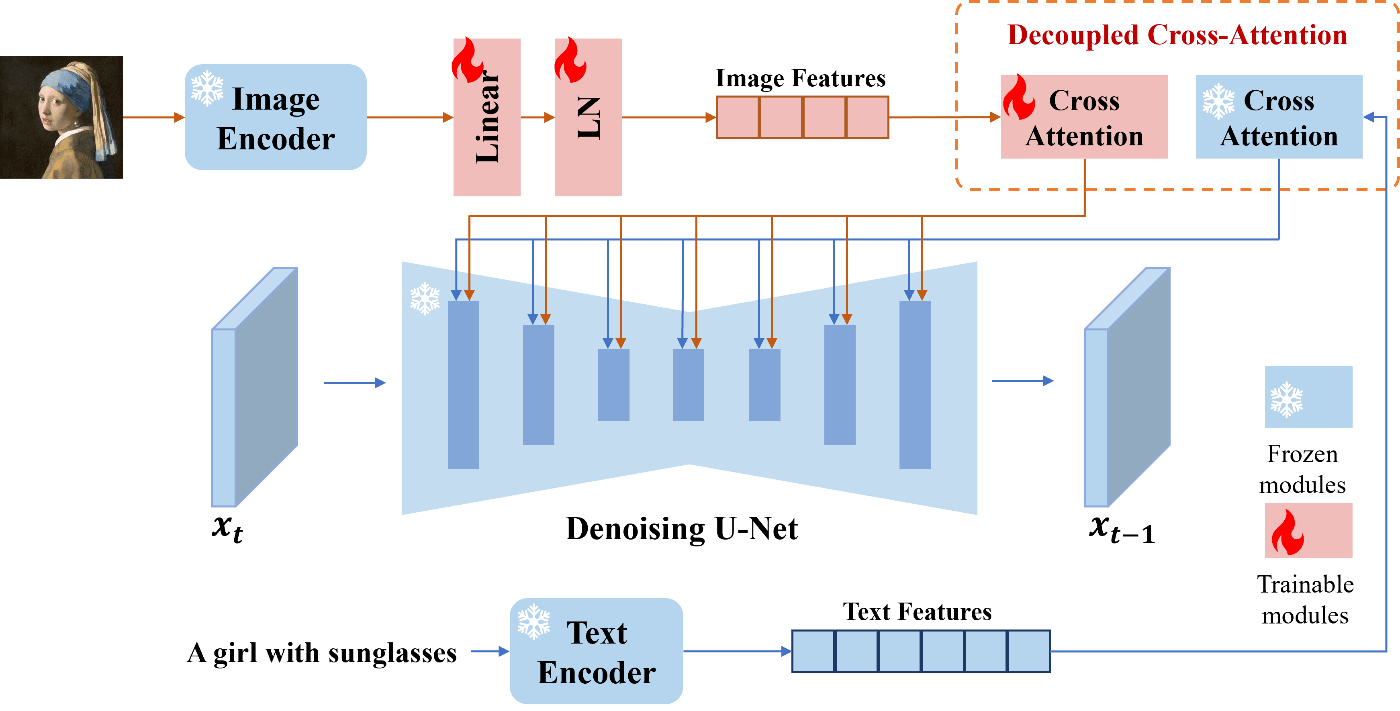
IP-Adapterのプロジェクトページより引用
あるいはSubject-Diffusionのように両方の手法を統合しているものもあります.
SoIの情報保持
先ほどImage Encoderで特徴を得るという話がありましたが, そのようなことは主にCLIPやBLIPを通して行われます. しかしながら, これらのモデルは局所的な情報抽出は得意ではなく, 例えば背景が同じになってしまうなどといった問題点があります. うまくSoIに対してのみ注目して欲しいので追加で学中を行ったり, 知識を補助的に追加したりしています.
例としていくつか研究事例を紹介します. segmentationやmaskを行うものが多いです.
- PerSAMでは, Personalized Segmentationを用いてうまく情報抽出を行なっています.
- HiFi Tunerでもsegmentationを行っていますが, DDIM Inversionと組み合わせています.
- Break-A-Sceneではこれまで紹介したものの融合のような学習の仕方で複数概念に対処しています.
他にはCLiCやObject-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding, Stellarといった手法があります.
segmentationなどをしない手法では, 顔のランドマーク情報を用いるPhotoMakerや, 複数の特徴を組み合わせるBlip-Diffusionなどがあります.
訓練データ
PCSが可能なモデル開発のための大規模なデータとして, 2種類に大別されます.
1つめはTriplet Dataです. Reference Image, Target Image, Target Captionから構成されるデータで, PCSの目的にぴったり合致します. しかしながら, この形式のデータを集めることは非常に難しいです. そのため, いくつかの戦略が提案されています.
- Data Augmentation: 前景のsegmentationや背景を入れ替えるなどして構築する手法で, Blip-Diffusionで用いられています.
- Synthetic Sample Generation: SuTIでは複数のOptimizing-based frameworkを使用して合成データを生成し, それを利用して訓練します.
- 認識可能なSoIの利用: 有名人の顔のような認識しやすいものを集める手法です. Inserting Anybody in Diffusion Models via Celeb Basisで用いられています.
2つめはDual Dataです. これは一般的なReference Image, Reference Captionから構成されるもので, 例えばLAIONやLAION-FACEといったものも含まれます. ただ, この種のデータはかなりpersonalizedの文脈では苦戦を強いられるようです.
タスクのカテゴライズ
ここまで読んでくださった方は薄々気付いているのではと思いますが, PCSでは一般のオブジェクトを生成するものや, 顔に限定したものなどがあります. 論文では10種類に区分けされているのでここでもその10種類を簡単に紹介したいと思います.
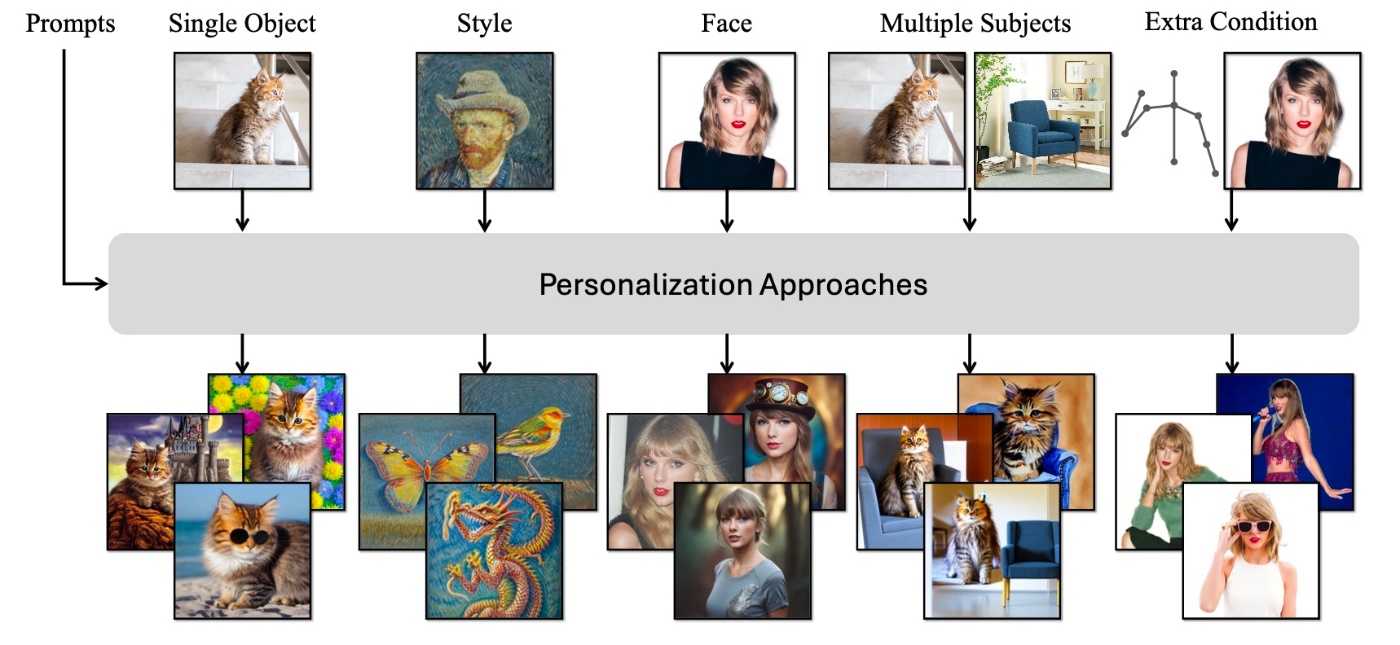
カテゴライズの一部. single objectやstyleといったものから追加条件を与えるものまである.
1. Personalized Object Generation
まずは最も単純な問題設定であるPersonalized Object Generationです. 主に1つの物体に焦点が当たっています. ベースとなる古典的手法 (古典的と言いつつ最近ですが, 論文のclassical methodを尊重してこの表現を使います)として, Textual Inversion, DreamBooth, ELITEが挙げられています. 以下の表のような比較が行われています.

この3手法を解説することはしませんが, 派生手法を紹介します.
Textual Inversionでは, 複雑な視覚的特徴を小さなパラメーターの集合に押し込めるため, 収束に時間がかかり, 視覚的忠実度が失われる可能性があるという欠点を抱えています. このような問題の分析は
Is This Loss Informative? Faster Text-to-Image Customization by Tracking Objective Dynamicsという論文で行われており, 非常に参考になります.
Textual Inversionを拡張する手法は多くあり, 代表的なものでも
などが挙げられます.
続いて, DreamBoothに移ります. DreamBoothでは全体をfine-tuningするためコストがかかる上に, モデル保存も大変です. このような問題への対処やDreamBoothの拡張は代表的なものでも
などがあります. 当然, 全体をfine-tuningするのが大変ならadapter-tuningをすればいいとなり, これまでに紹介したようなものが提案されています.
最後に, ELITEの話題に移ります. ELITEはlearning-basedな手法ですが, これの先行研究としてRe-Imagenがあります. これはRAG的アプローチを導入して訓練データにあまり存在しないものを生成するといった手法ですが, PCSではありません. ELITEと同様の研究として
- InstantBooth
- UMM-Diffusion
- SuTI
- Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
などがあります. あるいは, MLLM (Multimodal Large Language Models)を用いる手法としてBLIP-2を用いるBlip-Diffusionがあります.
他にもCustomization Assistant for Text-to-image GenerationやKosmos-Gが挙げられます.
最近ではOptimizing-based手法との組み合わせが研究されていて, HyperDreamBoothやDreamTunerなどがあります.
2. Personalized Style Generation
スタイルに関しても同種の研究が行われています. Personalized Style Generationとは, reference imageに含まれる美的要素を調整するものです. スタイルという概念は, 筆致, 素材の質感, 配色, 構造形式, 照明技法, 文化的影響などの, 幅広い芸術的要素を包含しているものですので, いわゆる絵柄に限らずPCSの研究が行われています.
個々の事例を細かく見ることはありませんが, 以下のような研究事例があります.
3. Personalized Face Generation
特に人間の顔に焦点を当てています. 自分では実用的な用途はあまり思いつきませんが (例えばある組織の人間かどうかを見分けるときにデータ拡張的に使うなどが考えられそうです), 顔画像データセットは大量に存在すること, ランドマーク検出や顔認識での学習済みモデルがそのまま使えるという利点があります.
例えば, Face0では顔の部分を検出して切り抜いてから埋め込みを学習する手法が取られています.
Face0: Instantaneously Conditioning a Text-to-Image Model on a Faceより引用.
他にも, W+AdapterはStyleGANの
4. Multiple Subject Composition
最初にsingle objectの話がありましたが, ここでは複数のobjectを登場させることを考えます. 学習ベースなら特に問題は起きませんが, 最適化ベースの場合, 個々のオブジェクトに最適化されたものをどのように融合するかという問題があります.
その方法の1つとして, 複数の最適化されたパラメータをうまく1つのパラメータに変換するというものがあります. 例えばCustom Diffusionではcross attentionの重みを更新しますし, Mix-of-ShowではLoRAを更新します.
他の手法としては, 連合モデルをつくることです. たとえば, SVDiffでは, Cut-Mix-Unmixというデータ拡張を行なって, 位置関係なども考慮して学習させます.
SVDiff: Compact Parameter Space for Diffusion Fine-Tuningより引用.
このような戦略はCustom DiffusionやInserting Anybody in Diffusion Models via Celeb Basisでも行われています.
5. High-level Semantic Personalization
これまではオブジェクトやスタイルといった, 視覚的にわかりやすいものに焦点が当たっていました. ここでは, より抽象度を高めたものについて考えます. 論文で紹介されているのはReVersion, Lego, ADIの3つです.
まず, ReVersionというものを紹介します. これは, Referenceから目的語の関係を反転させます. これでは何を言っているのかわからないので, ReVersionの論文の最初の図を見てみます.

ReVersion: Diffusion-Based Relation Inversion from Imagesより引用
中段の例を見てみると, referenceで与えられた画像はどれも握手をしています. この意味的な特徴を別の対象でも実現したいです. 実際にReVersionされた後の生成例では犬と猫が握手をするといったものが生成されていることがわかります. 学習ではトークン埋め込みを対照的損失で最適化します.
次に, Legoを紹介します. この手法では被写体の外見と関連する一般的な概念に着目しています. これも論文の図1をみるとわかりやすいです.

Lego: Learning to Disentangle and Invert Concepts Beyond Object Appearance in Text-to-Image Diffusion Modelsより引用
オブジェクトと, そのオブジェクトがどういった状態なのかを示すtext-imageのペアを用意します. すると, その状態のみを学習して反映できます. 例えば下段では, 猫と目を閉じた猫を用意することによって, 「目を閉じている」状態を学習することができ, 実際の生成例でも目を閉じることに成功しています. これはinversion lossとcontext lossを用いて学習しています.
最後に, ADIは「動作」を学習します. 先ほどのLegoなどと似ています. これも論文の図1を確認してみます.

Learning Disentangled Identifiers for Action-Customized Text-to-Image Generationより引用
祈ったり, 坐禅させたりといったことが可能です. 行動のみに注目するよう構成されたtripletを使って勾配不変性を抽出し, maskを行います.
6. Attack and Defense
さて, 今まではどのように概念を登場させるかということに着目していました. もちろん, それを防ぐ行為も研究対象になります. 敵対的攻撃などと他の分野では言われるように, 摂動などを加えて学習を妨害することが目標になります. 例えば, AntiDreamBoothも同様の手法を採用しています. 他には, Backdoored Textual Inversionでは, text-imageの無意味なペアを用意して, 訓練段階で組み込むことで妨害を行います.
7. Personalization on Extra Conditions
PCSではさらに追加条件を考える場合もあります. 例えば, PhotoSwapは, referenceの画像を数枚用意して, source imageのコンテンツをreferenceのものにしてしまうものです. 論文の図1を確認します.

PHOTOSWAP: Personalized Subject Swapping in Imagesより引用
この結果を見れば何をしているのかは一目瞭然だと思います. やっていることとしてはSwapping Autoencoderと似ている部分があります (どちらもAdobeが関わっています). また, MagiCaptureでは, 顔のカスタマイズに拡張しています.
他の応用としてはvisual try-onや, レイアウト調整, スケッチの変換, 視点制御, 姿勢修正などが挙げられます.
8. Personalized Video Generation
これまでは画像に限った話をしていましたが, 当然他のモダリティに拡張されます. この論文では動画と3Dを扱っていますが, まずは動画です.
動画における主な目的は3つです.
- 被写体
- 動き
- 被写体と外見の組み合わせ
先に結論を述べてしまうと, これらの目的に合わせて別々の戦略が行われているので, ロバストなPCSは現状ではできていません. 以降では個々の事例を少しだけ見てみます.
まず, 被写体についてです. この方針を実現する場合, 多くは画像をreferenceとして動画生成の拡散モデルを用います. しかし, 動画だからといって特別何かが変化するというわけではありません. 基本的な手法は画像の場合と同様です. 例えばCustomVideoではsegmentationを用いたデータ拡張やcross attentionの更新などを行なっていますし, VideoBoothやStyleCrafterでもattention機構の更新が行われます.
続いて, 動きについてです. 先ほどは画像をreferenceとしていましたが, 動きをPCSする場合にはその動作を含む短い動画になります. 一般的なアプローチは, 動画生成の拡散モデルをfine-tuningすることです. 有名なものにはTune-A-Videoがあります.
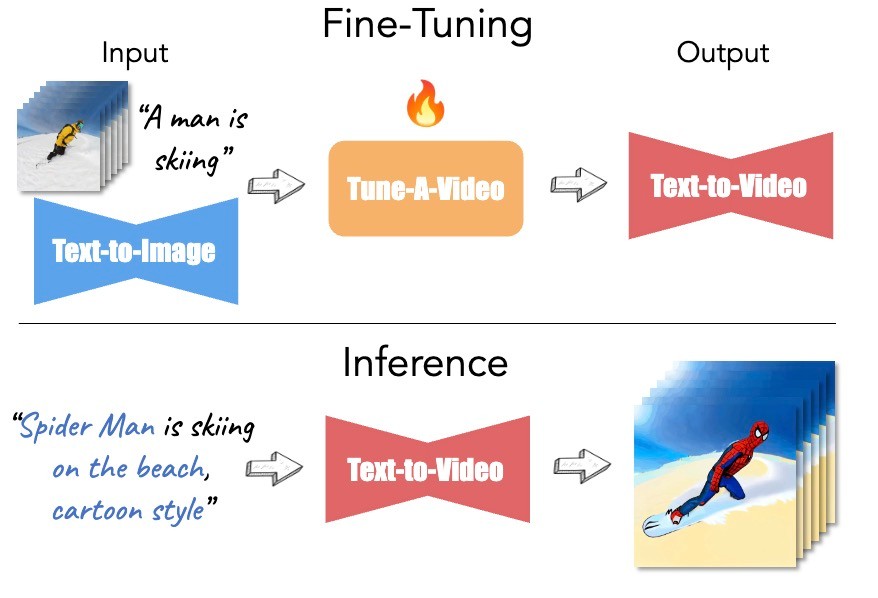
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generationより引用
これだけなら単純明快ですが, 実際にはreferenceになっている動画において, 動作と外観 (被写体など)は切り分けられる必要があります. SAVEでは外観の学習も加えることで分離を目指します.
SAVE: Protagonist Diversification with Structure Agnostic Video Editingより引用
他には, VMCでは学習時のプロンプトからあえて背景情報を消して学習を行なっています.
最後に, 両方を同時に達成することを考えます. 先ほど見たように, 2つの被写体と動作はかなり手法が異なっています. そのため, 両方を同時に達成するためには新しい手法が提案されます. MotionDirectorではspatial lossとtemporal lossを用いることで実現しています. ここではLoRAを用いてAdapter Tuningのように学習します.
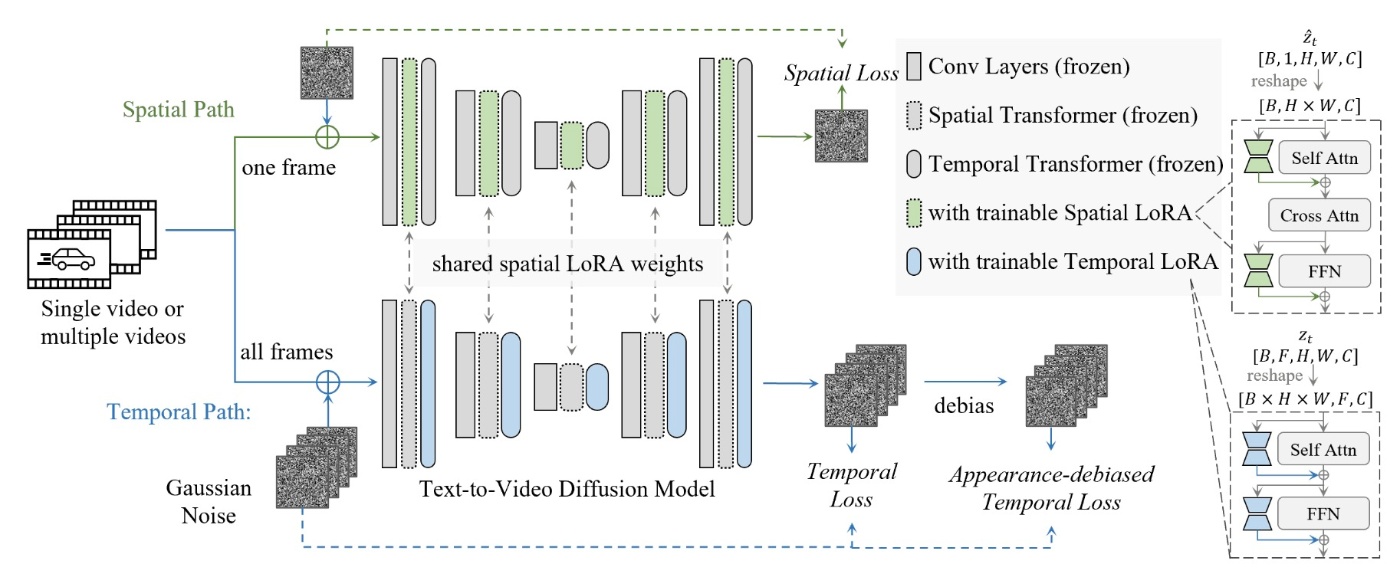
MotionDirector: Motion Customization of Text-to-Video Diffusion Modelsより引用
他にはDreamVideoではランダムに選択されたフレームから残差特徴を組み込むことで被写体を強調するようにしています.
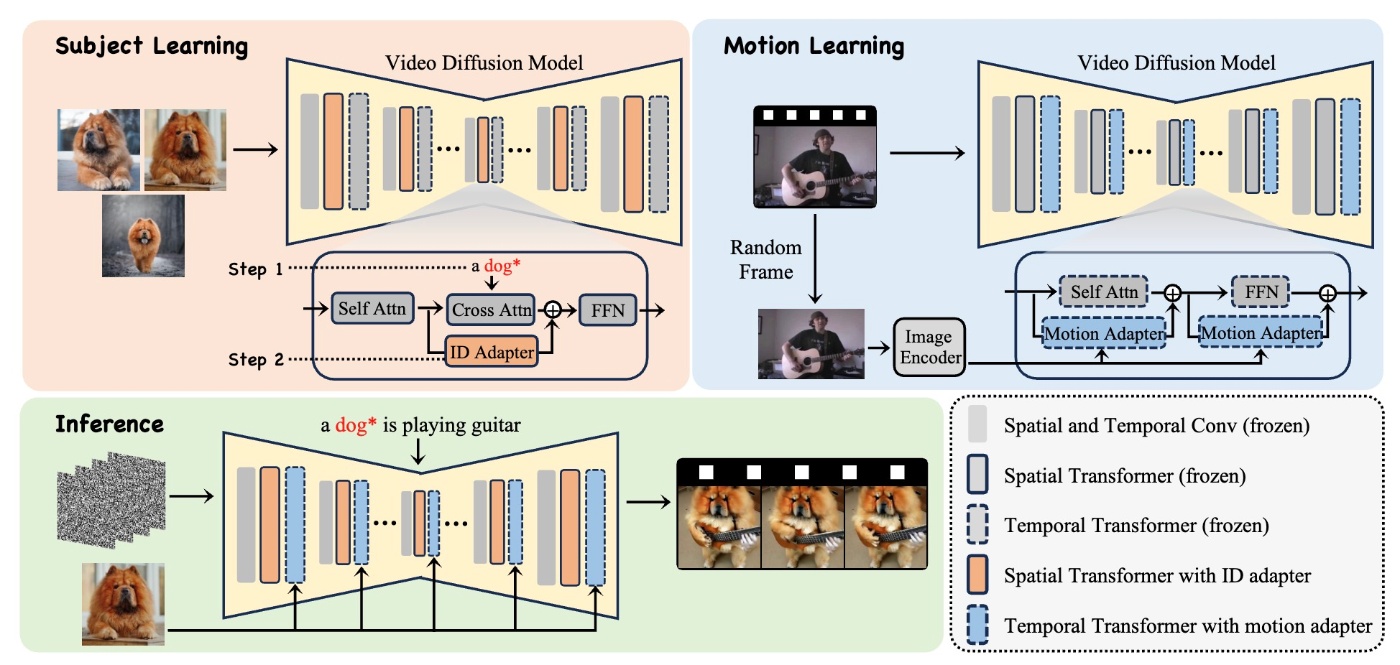
DreamVideo: Composing Your Dream Videos with Customized Subject and Motionより引用
9. Personalized 3D generation
3Dは画像生成モデルをfine-tuningするところから始まります. 主にNeRFについて取り上げますが, まず画像生成モデルをNeRFに対応させます. これはMagic3DやMVDreamなどがあります. その次にPersonalizeするのですが, DreamFusionがベースとなります. DreamFusionではScore Distillation Samplingで高速化した生成を目指します. これを改善する手法としていくつかのモデルが提案されています.
10. Others
これまで画像, 動画, 3Dと確認しましたが, 他にもPCSの研究が行われています. そのひとつがSVGです. Text-Guided Vector Graphics Customizationではimage-level lossとvector-level lossの2つを用いることで最適化を行なっています.
他には360°のパノラマ生成でもPCSが研究されており, MultiDiffusionがその代表例です.
何かしらのカテゴライズというよりは学習論的な話ですが, 継続学習を導入したContinual Diffusionがあり, 破滅的忘却を防いでいます. 主に, 各最適化のステップで重みの変化が最小になるようにlossを選択します
PCSのテクニック
ここまで数多くの手法を確認しましたが, その実現方法はさまざまでした. ここではその中から4つの手法を簡単にまとめます. 論文の中身には入らないので, 気になる人はそれぞれの論文を読むことをおすすめします.
Attentionの更新
まずは, 他のタスクでも多い手法としてattentionを更新するものがあります. しかし, この方法ではSoIのみに注意が向けられて, プロンプトの他の要素が反映されないといった課題があります. Mix-of-ShowやDreamTunerなどが特徴処理強化のためにメカニズムの改良を行なっています. 他にも, Layout-ControlやCones2, ViCoといった手法ではSoIのトークンの影響を制限する対策が採られています.
Maskを利用した手法
続いて, maskを用いてオブジェクトの位置と輪郭を示すという手法があります. 単純なアイデアとして, segmentationを用いる手法がこれまで見てきたように多くあります. segmentationの結果, 背景情報を捨てることができるので, オブジェクトへの集中が容易になります. 一方で, DETEXでは背景の再構成も行うことでより高精度な分離を実現しています. それ以外にもmaskで示されるレイアウトをcross attentionに条件付けすることでも実現されます.
他の手法では, AnyDoorがsegmentationした後の画像にHigh-pass filterを通したものを条件付けの一部として使っています.
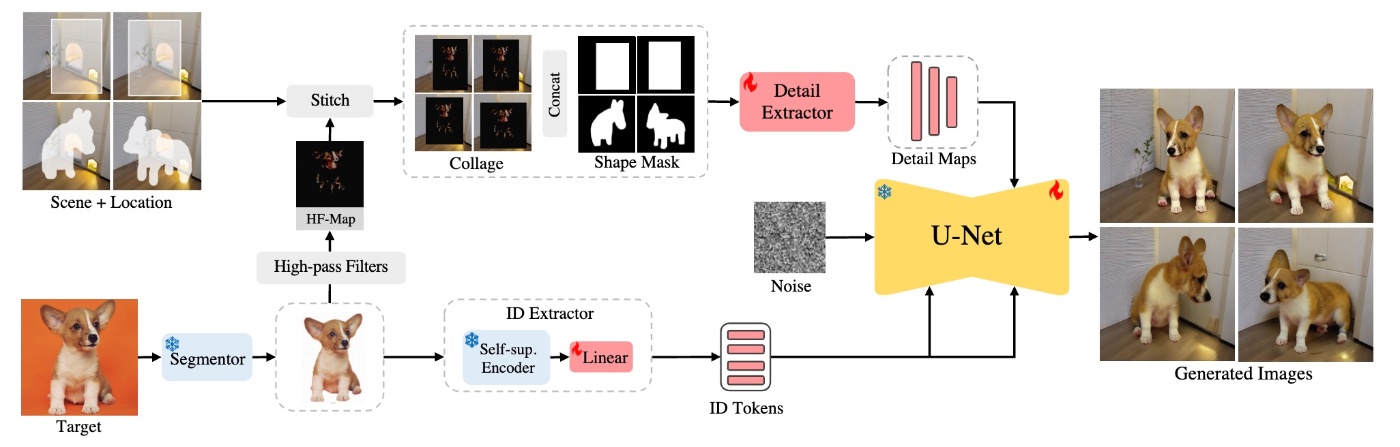
AnyDoor: Zero-shot Object-level Image Customizationより引用
DisenBoothでは, アイデンティティ埋め込みとそれに無関係な埋め込みのcosine類似度を最大化することでmaskを動的に生成しています.
他の主要な研究は以下のとおりです.
Data Augmentation
既存のPCSではreferenceとなる画像が限られているので多様な生成では課題があります. referenceを増やすことができれば手っ取り早いですが, 実際のデータを増やすことは困難ですので, データ拡張を行います. 例えばCOTIでは, ウェブ上から品質のよいデータを選択して徐々に訓練データを拡張します. 他にも度々登場しているSVDiff と似た方針の研究はsubject-diffusionやCustomVideo, VideoDreamerなど, 複数存在します.
Regularization
正則化は機械学習で例えば過学習を避けるためなど, 幅広く用いられている手法です. ここでは, SoIと同じカテゴリの画像で構成されたデータセットを追加で用意するなどが考えられます. そうすることによって, モデルは事前訓練で得た知識の保持を要求されます. これをベースとして, StyleBoostでは補助データセットを導入しています.
さらに, coached active learningに想起された手法もあります. Compositional InversionではSoIと意味的に関連するトークンの集合をanchorとして用いています. 他にも
- Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models
- Cones2
- Cross Initialization for Personalized Text-to-Image Generation
- Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
- Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding
などがあります.
以上は一般的な正則化手法ですが, 異なるアプローチもあります. DiffNatでは離散Wavelet変換を用いた損失関数を導入しています.
評価
これまでさまざまな工夫や手法を見てきましたが, 評価はどのように行うのでしょう. 評価を行う際には評価データセットと評価指標が必要ですので, それぞれ順番に確認します.
DreamBoothでは30のオブジェクトを含むデータセットが提案されています. 他にはDreamBench-v2はこれに220のプロンプトが追加されています. Custom Diffusionでは複数概念生成に向けた評価データを作成しています. 後続研究のCustom-101は対象を広げています. Stellarでは人間を対象にした少し大きめのデータになっています. 大きめとはいっても400人に対して20000プロンプトです.
評価指標は何を用いればいいでしょうか. PCSではSoIの忠実性を保ちつつ, 入力テキストとの一致度も重視しなければなりません. そのため, 2つの観点から指標が設計されます. まず, テキストとの一致度はCLIP Scoreが一般的です. それに加えてFIDやISで視覚的類似性を確認します.
これらはあくまで一般的に広く使われる指標ですが, PCSに特化した評価方法も提案されています. Navigating Text-To-Image Customizationでは, PCSモデルを忠実度, 制御可能性, 多様性, ベースモデルの維持度, 生成品質に基づいて評価する方法を提案しています.
まとめ
本記事ではPCSの区分けから具体的な手法に至るまで, かなり幅広く扱いました. サーベイ論文のconclusionにも
All covered personalization papers are summarized in Tab. II, Tab. III, Tab. IV, and Tab. V.
と書かれており, このサーベイに登場したもので全てと考えられます. 本記事ではそのすべての論文を登場させることはできていませんが, 気になった人はサーベイ論文の17ページから20ページの表2-5にすべての手法が区分けされているので確認してみてください (量が多くなるのでここでは扱いませんでした). 画像生成分野はかなり精度が向上ていて, 今後はより細かいところがテーマになってなるのかなと感じていますが, 動画などはベースのモデルの性能がまだ発展途上なのでアーキテクチャなどの変化に伴って多様な研究が見込めると思います. 例えば, 状態空間モデルと拡散モデルを用いた動画生成も研究されています. これは画像生成でも同じですが, 画像生成モデルは既にcross-attentionを用いたものが沢山公開されているのでLLM同様置き換わりには至るには時間がかかるか, そもそも置き換わらないのではと思います.
参考文献
普段は論文のスタイルで書いていますが, 量が多いのでタイトルとリンク, 著者 (1st)と会議 (あるいはarXiv)を示します. この記事で紹介している論文は, サーベイ論文で引用されている論文の4割ほどです.
CVPR2024採択論文は, 以下のサイトから確認できます. 論文タイトルの一部で検索して採択されているかを確認していますが, 抜けがあるかもしれません.
- An image is worth one word: Personalizing text-to-image generation using textual inversion [Gal et al., ICLR2023]
- Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation [Ruiz et al., CVPR2023]
- A Data Perspective on Enhanced Identity Preservation for Diffusion Personalization [He et al., arXiv]
- Improving Image Generation with Better Captions [Betker et al. OpenAI]
- P+: Extended Textual Conditioning in Text-to-Image Generation [Voynov et al., arXiv]
- Multi-Concept Customization of Text-to-Image Diffusion [Kumari et al., CVPR2023]
- SVDiff: Compact Parameter Space for Diffusion Fine-Tuning [Han et al., ICCV2023]
- Key-Locked Rank One Editing for Text-to-Image Personalization [Tewel et al., SIGGRAPH2023]
- Locating and Editing Factual Associations in GPT [Meng et al., NeurIPS2022]
- Mix-of-Show: Decentralized Low-Rank Adaptation for Multi-Concept Customization of Diffusion Models [Gu et al., NeurIPS2023]
- HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models [Ruiz et al., CVPR2024]
- OMG: Occlusion-friendly Personalized Multi-concept Generation in Diffusion Models [Kong et al., arXiv]
- StyleDrop: Text-to-Image Synthesis of Any Style [Sohn et al., NeurIPS2023]
- A Closer Look at Parameter-Efficient Tuning in Diffusion Models [Xiang et al., arXiv]
- IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models [Ye et al., arXiv]
- Subject-Diffusion:Open Domain Personalized Text-to-Image Generation without Test-time Fine-tuning [Ma et al., arXiv]
- Personalize Segment Anything Model with One Shot [Zhang et al., ICLR2024]
- HiFi Tuner: High-Fidelity Subject-Driven Fine-Tuning for Diffusion Models [Wang et al., arXiv]
- Break-A-Scene: Extracting Multiple Concepts from a Single Image [Avrahami et al., SIGGRAPH ASIA2023]
- CLiC: Concept Learning in Context [Safaee et al., CVPR2024]
- Object-Driven One-Shot Fine-tuning of Text-to-Image Diffusion with Prototypical Embedding [Lu et al., arXiv]
- PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding [Li et al., CVPR2024]
- BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing[Li et al., NeurIPS2023]
- Subject-driven Text-to-Image Generation via Apprenticeship Learning [Chen et al., NeurIPS2023]
- Inserting Anybody in Diffusion Models via Celeb Basis [Yuan et al., NeurIPS2023]
- ELITE: Encoding Visual Concepts into Textual Embeddings for Customized Text-to-Image Generation [Wei et al., ICCV2023]
- Is This Loss Informative? Faster Text-to-Image Customization by Tracking Objective Dynamics [Voronov et al., NeurIPS2023]
- A Neural Space-Time Representation for Text-to-Image Personalization [Alaluf et al., ACM Transactions on Graphics]
- ProSpect: Prompt Spectrum for Attribute-Aware Personalization of Diffusion Models [Zhang et al., ACM Transactions on Graphics]
- An Image is Worth Multiple Words: Multi-attribute Inversion for Constrained Text-to-Image Synthesis [Agarwal et al., arXiv]
- DreamArtist: Towards Controllable One-Shot Text-to-Image Generation via Positive-Negative Prompt-Tuning [Dong et al., arXiv]
- InstructBooth: Instruction-following Personalized Text-to-Image Generation [Chae et al., arXiv]
- Gradient-Free Textual Inversion [Fei et al., MM23]
- COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models [Xiao et al., ICML2023]
- Re-Imagen: Retrieval-Augmented Text-to-Image Generator [Chen et al., ICLR2023]
- InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning [Shi et al., arXiv]
- Unified Multi-Modal Latent Diffusion for Joint Subject and Text Conditional Image Generation [Ma et al., arXiv]
- Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models [Arar et al., SIGGRAPH ASIA2023]
- Customization Assistant for Text-to-image Generation [Zhou et al., CVPR2024]
- Kosmos-G: Generating Images in Context with Multimodal Large Language Models [Pan et al., ICLR2024]
- DreamTuner: Single Image is Enough for Subject-Driven Generation [Hua et al., arXiv]
- Generative Active Learning for Image Synthesis Personalization [Zhang et al., arXiv]
- Style Aligned Image Generation via Shared Attention [hertz et al., CVPR2024]
- StyleAdapter: A Single-Pass LoRA-Free Model for Stylized Image Generation [Eang et al., arXiv]
- Face0: Instantaneously Conditioning a Text-to-Image Model on a Face [Valevski et al., SIGGRAPH ASIA 2023]
- When StyleGAN Meets Stable Diffusion: a 𝒲+ Adapter for Personalized Image Generation [Li et al., CVPR2024]
- InstantID: Zero-shot Identity-Preserving Generation in Seconds [Wang et al., arXiv]
- ReVersion: Diffusion-Based Relation Inversion from Images [Huang et al., arXiv]
- Lego: Learning to Disentangle and Invert Concepts Beyond Object Appearance in Text-to-Image Diffusion Models [Motamed et al., arXiv]
- Learning Disentangled Identifiers for Action-Customized Text-to-Image Generation [Huang et al., CVPR2024]
- Anti-DreamBooth: Protecting Users from Personalized Text-to-image Synthesis [Le et al., ICCV2023]
- Backdoored Textual Inversion for Concept Censorship [Wu et al., arXiv]
- PHOTOSWAP: Personalized Subject Swapping in Images [Gu et al., NeurIPS2023]
- Swapping Autoencoder for Deep Image Manipulation [Park et al., NeurIPS2020]
- MagiCapture: High-Resolution Multi-Concept Portrait Customization [Hyung et al., AAAI2024]
- CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects [Wang et al., arXiv]
- VideoBooth: Diffusion-based Video Generation with Image Prompts [Jiang et al., CVPR2024]
- StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter [Liu et al., arXiv]
- Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation [Wu et al., ICCV2023]
- SAVE: Protagonist Diversification with Structure Agnostic Video Editing [Song et al., arXiv]
- VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models [Jeong et al., CVPR2024]
- MotionDirector: Motion Customization of Text-to-Video Diffusion Models [Zhao et al., arXiv]
- DreamVideo: Composing Your Dream Videos with Customized Subject and Motion [Wu et al., CVPR2024]
- Magic3D: High-Resolution Text-to-3D Content Creation [Lin et al., CVPR2023]
- MVDream: Multi-view Diffusion for 3D Generation [Shi et al, arXiv]
- DreamFusion: Text-to-3D using 2D Diffusion [Poole et al., ICLR2023]
- DreamBooth3D: Subject-Driven Text-to-3D Generation [Raj et al., ICCV2023]
- Chasing Consistency in Text-to-3D Generation from a Single Image [Ouyang et al., arXiv]
- TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion [yeh et al., CVPR2024]
- Text-Guided Vector Graphics Customization [Zhang et al., SIGGRAPH ASIA2023]
- Customizing 360-Degree Panoramas Through Text-to-Image Diffusion Models [Wang et al., WACV2024]
- Continual Diffusion: Continual Customization of Text-to-Image Diffusion with C-LoRA [Smith et al., TMLR]
- Training-Free Layout Control With Cross-Attention Guidance [Chen et al., WACV2024]
- Customizable Image Synthesis with Multiple Subjects [Liu et al., NeurIPS2023]
- ViCo: Plug-and-play Visual Condition for Personalized Text-to-image Generation [hao et al., arXiv]
- Decoupled Textual Embeddings for Customized Image Generation [Cai et al., AAAI2024]
- AnyDoor: Zero-shot Object-level Image Customization [Chen et al., CVPR2024]
- DisenBooth: Identity-Preserving Disentangled Tuning for Subject-Driven Text-to-Image Generation [Chen et al., ICLR2024]
- Generate Anything Anywhere in Any Scene [Li et al., arXiv]
- High fidelity Person-centric Subject-to-Image Synthesis [Wang et al., CVPR2024]
- Controllable Textual Inversion for Personalized Text-to-Image Generation [Yang et al., arXiv]
- StyleBoost: A Study of Personalizing Text-to-Image Generation in Any Style using DreamBooth [Park et al., ICTC2024]
- Compositional Inversion for Stable Diffusion Models [Zhang et al., AAAI2024]
- Encoder-based Domain Tuning for Fast Personalization of Text-to-Image Models [Gal et al., ACM Transactions on Graphics]
- Cross Initialization for Personalized Text-to-Image Generation [pang et al., CVPR2024]
- DIFFNAT: Improving Diffusion Image Quality Using Natural Image Statistics [Roy et al., arXiv]
- Stellar: Systematic Evaluation of Human-Centric Personalized Text-to-Image Methods [Achlioptas et al., arXiv]
- Navigating Text-To-Image Customization: From LyCORIS Fine-Tuning to Model Evaluation [Yeh et al., ICLR2024]
- A Style-Based Generator Architecture for Generative Adversarial Networks [Karras et al., CVPR2019]
- Adding Conditional Control to Text-to-Image Diffusion Models [Zhang et al., ICCV2023]
- SSM Meets Video Diffusion Models: Efficient Video Generation with Structured State Spaces [Oshima et al., ICLR2024 Workshop PML4LRS]
- Diffusion Models Without Attention [Yan et al., NeurIPS2023 Workshop on Diffusion Models]
- Towards a Unified View of Parameter-Efficient Transfer Learning [He et al., ICLR2022]
- A Survey on Personalized Content Synthesis with Diffusion Models [Zhang et al., arXiv]
Discussion