Mamba内部の知識とその編集(COLM2024)


Locating and Editing Factual Associations in Mamba (COLM2024)
COLM (Conference on Language Modeling)という新設の会議があります.
新設なので今年が最初 (第1回)なのですが, そこに採択された論文について見てみます.
タイトルは"Locating and Editing Factual Associations in Mamba"です. これはNeurIPS2020に採択された"Locating and Editing Factual Associations in GPT"を意識したものでしょう.
関連リンク
はじめに
論文の内容に入る前に, タイトルの元ネタとなっている"Locating and Editing Factual Associations in GPT"ではどのようなことをしているのかを軽く確認します. ここでは非常に簡単に述べるので詳しくは論文の方を参照していただければと思います.
タイトルにあるように言語モデルとしてGPTを用いて, 事実に関する事柄 (いわゆる知識)がモデル内部でどのように結びつき, 想起されているかを調べ, その編集方法について提案したのがこの論文です. 因果推論を用いて, 特定の知識に関連する部分を特定します. それを表したのが下の図です.

Locating and Editing Factual Associations in GPTより引用
この結果から, 真ん中あたりのMLP (FFN)に知識が蓄積されていそうだということが[1], 最後の方のself attentionでその知識がトークンにコピーされていそうだ, ということがわかりました. それでMLPを編集しようという (ROME)のがこの論文での提案手法です.
日本語では言語処理学会 (NLP2024)の『言語構造に制約されない大規模言語モデルの知識編集』という論文が詳細な説明をわかりやすくしています.
ROMEの論文ではGPT2-XLを対象としていますが, 多くの場合他のモデルに拡張できます. 日本語記事だと以下のようなものがあります
以上のことから, 非常に大雑把に言うと, GPT2だけではなく, さらに大きなTransformer decoder言語モデルにもこの話が当てはまることがわかります. ではMambaではどうなのかというのがこの論文での話です.
Mamba
MambaとTransformerではアーキテクチャが大きく異なります. Mambaは同じくCOLM2024に採択されている, Transformerを代替しうると注目されている状態空間モデル (State Space Model, 以降SSM)の発展系です.
Transformerは推論時に系列長の2乗に比例する計算量 (すなわち
Transformerの計算量が大きいならTransformerをやめればいいのですが, 性能が非常に悪化します. 特に, Transformer以前のRNNなどは性能が悪い上に勾配消失などの問題を抱えています (LSTMやGRUで解消されます). さらに, 逐次処理であるために並列処理ができないという非常に大きな欠点を抱えています (この欠点を解消したのがTransformerで, Attention Is All You NeedのIntroの最終段落に成果として書かれるほどです).
Transformerのいいところをそのままに推論時の計算量を削減したのがSSMになります. 詳しくはそれぞれの論文を参照してほしいのですが, LSSL, S4, H3, HyenaのようなSSMベースのモデルはSSMの計算の畳み込みの部分の高速化にフーリエ変換を用いています. これをよりsoftとhardの面から最適化したものがMambaです (H3などでもFlashConvのような最適化が使われていますがそれとは別です).
アーキテクチャとしてはH3とGated MLPの組み合わせのような構造をしています.

Mamba: Linear-Time Sequence Modeling with Selective State Spacesより引用
この論文では, 以下のような構造を使用します. notationもこの図に従います.

なお, Mambaに関しては以下の記事などが参考になります.
Locating Key States for Factual Recall
では, 論文の内容に入っていきます.
まず, 言語モデルが知っている事実
この正しい事実予測に対する各状態の寄与を推定するために, 3つの異なる実行にわたってモデルの活性化を収集します.
- clean run
- corrupted run
- patched run
clean run (G)
clean runでは, 単にプロンプトを入力します. 例えば,
corrupted run (G^*)
patched run (G^*[\leftarrow h_i^{(\ell)}])

分析結果
さて,
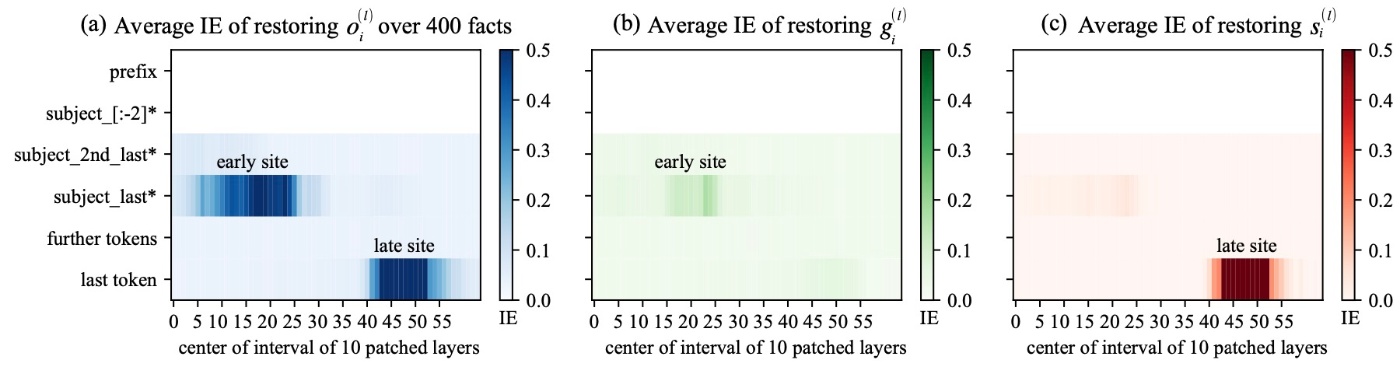
以下の図では, Relations Datasetの400の事実について,

last tokenについて, late siteで高いIEが確認できます. これはそこでcleanな
他の変数についても見てみます.
自己回帰のTransformerとこの結果を比較するために, 同じ規模のTransformer言語モデル (Pythia-2.8b)でも実験を行いました.

これと比較すると, MambaとTransformerで異なる点が浮かび上がります. それは, TransformerはMLPの出力がearly siteに効果を持ち, late siteでは効果がないです (図b, 同じ部分は色の変化がありますが, TransformerのMLPのように支配的ではないということだと思います). しかし, Mambaはそれに対応する結果が得られません. ここから, 「Mambaのどのパラメーターが事実の想起を媒介するのか?」という疑問が生じます.
その疑問を解消するために, ROMEの論文でやっていることと同じことをMambaでも再現します. すなわち, 因果グラフから特定の経路を切断し, その影響を観察することで経路特有の効果を探ります. ここでは, 事実の想起の際に
まず,
次に,
図にすると以下のようになります.

Relations Datasetから400件をランダムサンプリングした結果を示します.

紫色のバーと緑色、赤色、青色のバーとのギャップを見ることでグラフを読み取ります. 大きいギャップはそれぞれ
後ろの層でもやはり
Editing Facts With ROME
ここではROMEをMambaに適用することを考え, 事実の編集ができるかどうかを確かめます. ROMEは任意の線形変換を連想記憶として考えることができ, keyの集合
入力はプロンプト
ROMEは層
Mambaには3つの射影行列があります. Conv+SSM経路である
編集性能を測るために, CounterFact datasetを用います. 20Kの
-
Efficacy (ES): effective とは, 編集ののちに言語モデルが
p(o^*)>p(o) -
Generalization (PS): 編集が成功した場合,
(s, r) (s, r, o\rightarrow o^*) x_p\sim \mathcal{P}_r(s) p(o)>p(o^*) -
Specifity (NS): 編集は特定の
\mathcal{P}_r(s) o^* s_n p(o_n)>p(o^*)
結果を確認します.

この結果を見ると, 初期層から中間層にかけてをROMEで編集を行うと高いスコア (S)が得られています. これはTransformerの言語モデルでの観察結果と同じです. しかし, 編集の性能は場所によることが確認できます. 例えば,
では, MambaにROMEを適用する際に正しい場所はどこでしょう? 間接効果の図を再掲します.
この図では,
一方, 先ほどの結果では中間層のgatingは (ES)と(PS)が急激に低下します. これはいくつかの層で
このことから著者らは
Linearity of Relation Embeddin (LRE)
activation patchingによって, 言語モデルのどの部分に事実が位置しているかを特定することができます. 我々はプロンプト
Transformerの言語モデルでは, subject entityの表現
この事実は以下の論文によるものです.
次に, last subject tokenの位置で, attention moduleはenrichedな
ここで
で
著者らはこれを用いてMambaの事実関係のデコードの複雑さを探求します.

赤い線はrandom choiceです. 結果を詳しくみます. 26ある事実のうち, 10件の事実のみが線形LREで50%以上を達成できています. 比較のためにPythia-2.8bでも同じ実験をしたところ, 11件でした. MambaよPyhtiaの両方でLREはユニークな回答の数が大きい関係に対しては良好な忠実度を達成できないことがわかります. この結果はLLaMAでの先行研究の結果と一致し, Transformer言語モデルと同様に, Mambaにおける事実知識もrelationごとに異なる方法で表現されている可能性があることを示唆しています.
Attention Knock-out in Mamba?
attention moduleはTransformer言語モデル内の異なるトークン位置間の情報の流れを媒介しています. Attention "Knock-out"実験では, 特定のエッジ (
実際には, 非線形な操作であるConv+Selective-SSMによって, 完全に情報を取り除くことは困難です. しかし, Conv+SSMの操作で
Relations datasetsから6つの事実関係にわたって700の事実をランダムに取ってきます. これらのデータに対して特定のレイヤー
です. さて, 結果を見てみます.
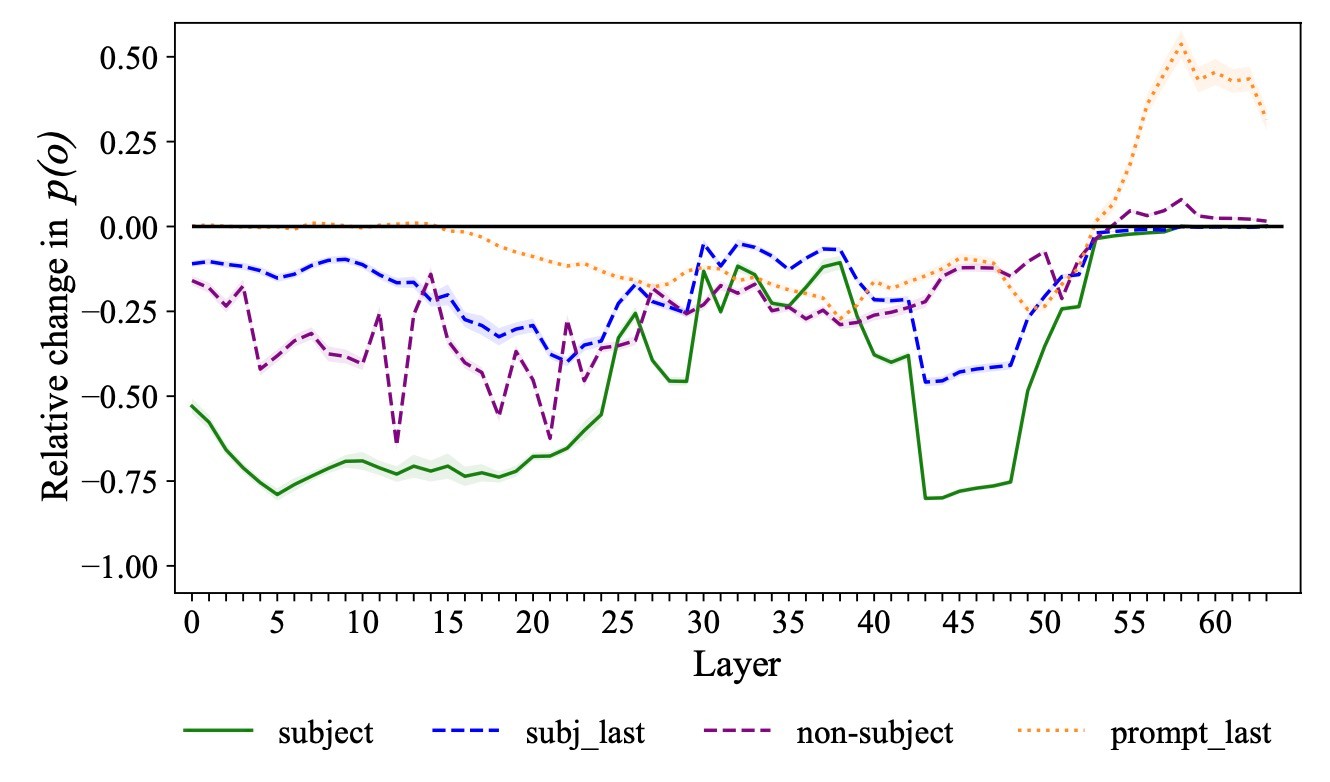
著者らはここから3つの結論を導いています.
Mambaは初期~中間層で関係特有の情報を将来のトークンに伝播する
紫色の線をみます. ここから, 初期~中間層でnon-subjectの情報の流れをブロックすることで
やや後半の層では事実想起に重要な役割を果たしている
subject情報の流れである緑色の線を見ると, 2つの谷があることがわかります.
- 最初の谷は初期層にありますが, これはMambaが初期初期層で全ての主語トークンから情報を集約して複数のトークンからなるsubject entity
s - しかし, 43~48層に見られる谷は, Mambaがその層でConv+SSM経路を利用してsubjectから後続のトークンへ重要な情報を伝播していることが示唆されます. これは以前の結果と一致しており, その層の
s_i
last subject tokenの除去だけでは不完全
last subject token情報をブロックした際の結果である青い線を見ます. 初期層では後続の層が損失を補うことがわかります. しかし, 20層あたりで谷があり, Mambaがその時点までに完全なsubject entityを認識して関連する連想 (enrichment)を想起することが示唆されます. 特に, enrichmentに重要な役割を果たしていると仮定している
まとめ
- ROMEがMambaに適用できるかの検討
- 全体としてMambaとTransformerでは同じような考察ができる
- 著者らは自己回帰型の言語モデリングというタスクが事実想起パターンを誘発するのではと考えている
参考文献
- Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 17359–17372. Curran Associates, Inc., 2022.
- Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024.
- Arnab Sen Sharma, David Atkinson, and David Bau. Locating and editing factual associations in mamba. In First Conference on Language Modeling, 2024.
-
もう少し正しくいうと, 因果推論でわかることは「事実の想起において何かしらの大きな関与をしていると予想される.」ということです. ↩︎
-
詳細は, Are Transformers Effective for Time Series Forecasting?などを参照してください ↩︎
Discussion