Locating and Editing Factual Associations in GPT
今回はROMEの論文を細かく見ていきます. arXivの方を見ると, 第5版まで出ていますので, ここでは第5版を扱います. ことわりのない限り, 図表は全て元論文からの引用とします.
関連リンク
書籍情報
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 17359–17372. Curran Associates, Inc., 2022.
はじめに
言語モデルはどこにその知識を格納しているのでしょう?この論文ではその点を扱います. 言語モデルは世界についての事実を推論することができます. 例えば, “The Space Needle is located in the city of,”と与えられたら, 正しい答えである"Seattle"を推論することが期待されますし, 実際にそうであると思われます. これは自己回帰のGPTだけでなくmasked BERTなどでも見られる現象です. ここではGPT-likeの自己回帰モデルに的を絞ってそのような知識がどこに蓄積されているのかを調査します. masked modelsでは研究が行われていますが, GPTのようなモデルはunidirectionalであるという点で異なります.
2つのアプローチを用いてこの目標を達成します. ひとつめはhidden state activationsのcasual effectsを追跡することです. これにはcausal mediation analysisを用います. これによって, あるsubjectに関する知識の想起を仲介するモジュールを特定することができます. 実験ではlast subject tokenを処理する際に, 中間層のFFN (feed-forward MLPs) が決定的な役割を果たしていることがわかります.
ふたつめはひとつめで得られた結果が正しいことを確認するためのテストとして, Rank-One Model Editing method (ROME)を提案します. これはFFNの挙動を決定するパラメータを代替する手法です. ROMEが標準的なzero-shotベンチマークで他のモデル編集手法と似たような効果を発揮することを確認することで, 事実がそこに蓄積されていることを保証します.
更なるROMEの評価として, より難しいケースを考えます. そのために反実仮想挿入データセット (dataset of counterfactual assertions)を導入します.
以降では, 大規模な学習済み自己回帰TransformerモデルをLLMと称します.
Interventions on Activations for Tracing Information Flow
LLMのパラメータのどこに事実があるのかを見つけるために, 著者らは個々の事実の推論時に最も強い因果効果を持つ特定の隠れ層を分析・特定することから始めました. 個々の事実をタプル
語彙
そこで,
です. 各MLP層には2層からなるニューラルネットワークがあります. それらは
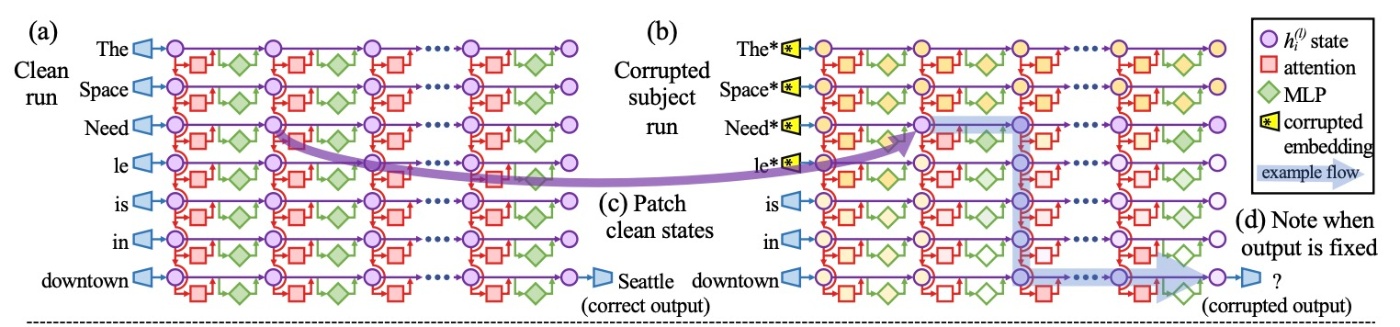
Causal Tracing of Factual Associations
上図の状態のgridはcausal graphを形成しています. このグラフは左側の入力から右下の出力までの様々なpathを持っています.
先行研究によると, これは因果媒介分析の自然な場合です. 各状態の事実の推論に対する寄与を計算するために, 全ての
- clean run: 事実の推論
- corrupted run: 推論が傷つけられたもの
- corrupted-with-restoration run: 1つの状態を回復した場合の推論能力のテスト
より詳しく見ていきます.
clean runでは, factual prompt
corrupted runでは, ネットワーク
corrupted-with-restoration runでは, corrupted runと同じように
以上が3つの実験です. 以降ではその実験においてどのように結果を評価するかを見ます.
まず,
Causal Tracing Results
ここではCausal Tracingの結果を確認します. 媒介させるものをさまざまに変化させながら, 1000を超えるfactual statementに対してAIEを計算します. 1.5BのモデルであるGPT2-XLを用いた結果が以下のようになっています. ATEは18.6%で, 効果の大部分がlast subject tokenにおいて, 強く因果的な個別状態 (レイヤー15でAIE=8.7%) によって媒介されていることに注意が必要です. 推論直前のlate siteに強い因果状態が存在することはあまり驚きはありませんが, last subject tokenのearly siteにこれが出現することは新しい発見です.
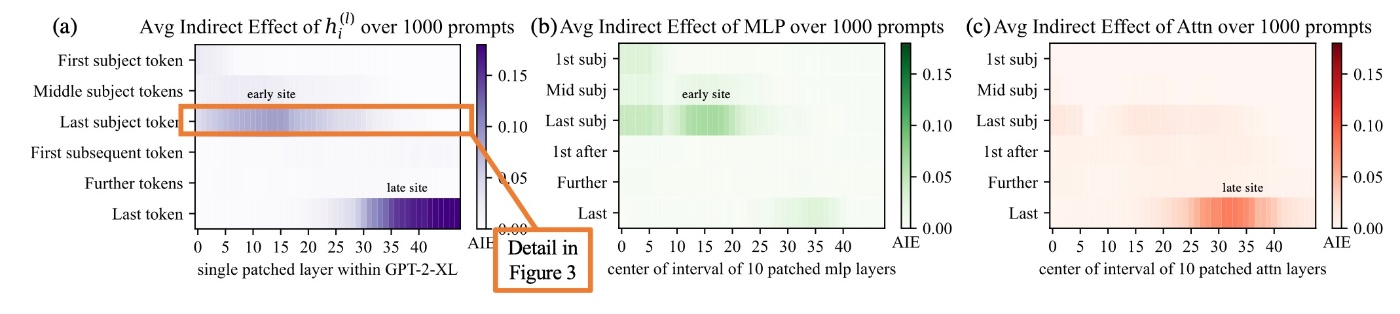
MLPとattentionの寄与の因果効果を分解すると, 上図 (b, c) と下図 (f, g) からearly siteの決定的な役割が示唆されます. last subject tokenでのMLPのAIEは6.6%ですが, attentionは1.6%です. attentionはlast tokenでより重要であることがわかります.
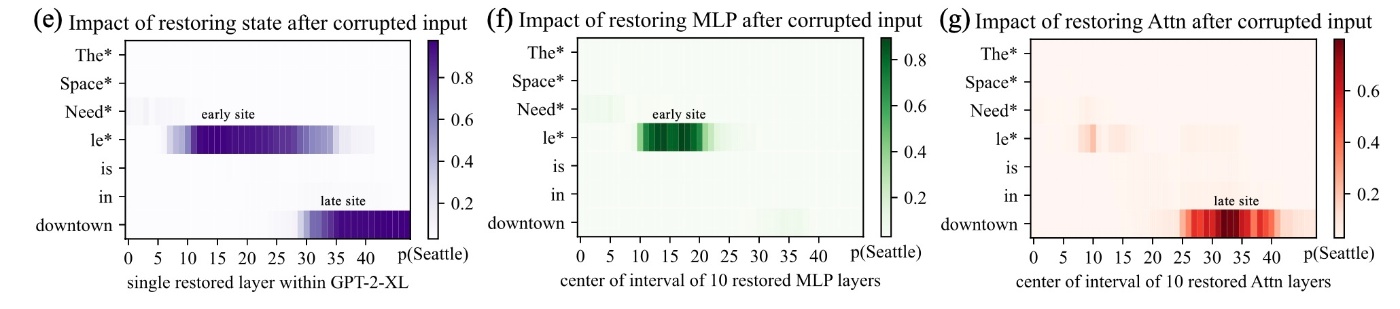
最後に, early siteにおけるMLPの特別な役割を明確にするために, IEを修正したcausal graphを用いて分析します.
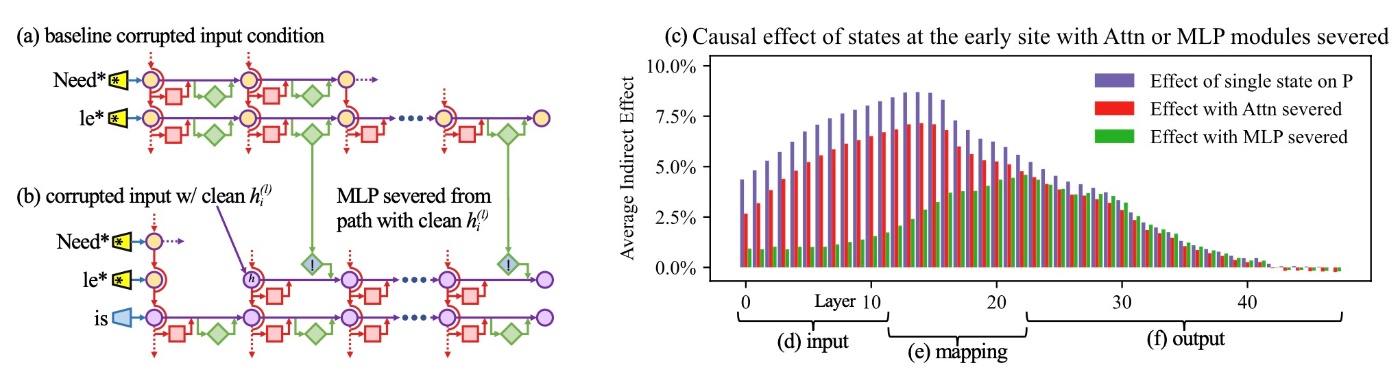
上図には (a)-(f) までラベルが付与されていますので, 順番に見ていきます.
まず, 各MLPモジュールの寄与をcorrupted runによって集めます (a). 次に, 因果効果を測定する際にMLPの効果を分離するために, トークン
さて, 修正されたグラフoriginalのグラフのAIEを比較します (c). まず最初の層ですが, その後のMLPの活動なしでは自身の因果効果を失っています (d). それとは対照的に, 後ろの層になると状態の効果はMLPの活動に影響されにくくなっています. attentionを切り離すとこのような変化は見られません (f). この結果は事実の想起において中間層のMLPが必要不可欠であることを示しています (e).
このことから著者らは局所化されたMLPのkey-value mappingがsubjectに関する事実を想起させると仮説を立てました.
The Localized Factual Association Hypothesis
著者らはcausal tracingの結果に基づいて, 事実の関連付けを蓄積するための特定のメカニズムを提唱しています. 具体的には, 中間層のMLPモジュールがsubjectをエンコードする入力を受け取り, そのsubjectに関する記憶された特性を想起させる出力を生成します. 中間層のMLPは蓄積された情報を出力し, 集められた情報が後ろの層のattentionによってlast subject tokenにコピーされるというものです.
この仮説は, 知識の関連付けについて3つの次元に沿って, 特定の位置に局所化します.
- MLPモジュール
- 特定の中間層
- last subject tokenの処理時
この仮説は先行研究と一致するものです.
(先行研究では「MLP層が知識を保存する」という考えや, 「self attentionが情報をコピーする役割を果たす」という考えです.)
さらに, 「Transformer層の順序を変更しても挙動にはほとんど影響がない」という先行研究の発見に基づいて, 著者らはこの仮説が完全なものであることを提案しています. つまり, 中間層の個々の層の選択や配置には特別な役割がないということで, どの事実も中間層のMLPのいずれかに等しく保村されていると推測できます. この仮説を検証するために特定の中間層のMLPモジュール
Interventions on Weights for Understanding Factual Association Storage
MLPが事実の関連付けの想起の役割を担っていそうなことはすでに確認した通りです. では, 事実はどのように重みに保存されているのでしょう. 先行研究では, FFNの2つあるMLPがkey-valueメモリとして機能していることがわかっています. 最初の層である
この仮説の検証のために, Rank-One Model Editing (ROME) を用いて事実の関連付けを修正するという介入を行います. 現在のタプル
Rank-One Model Editing: Viewing the Transformer MLP as an Associative Memory
ここでは,
ここで,
ここで, ROMEの概要図を示します.
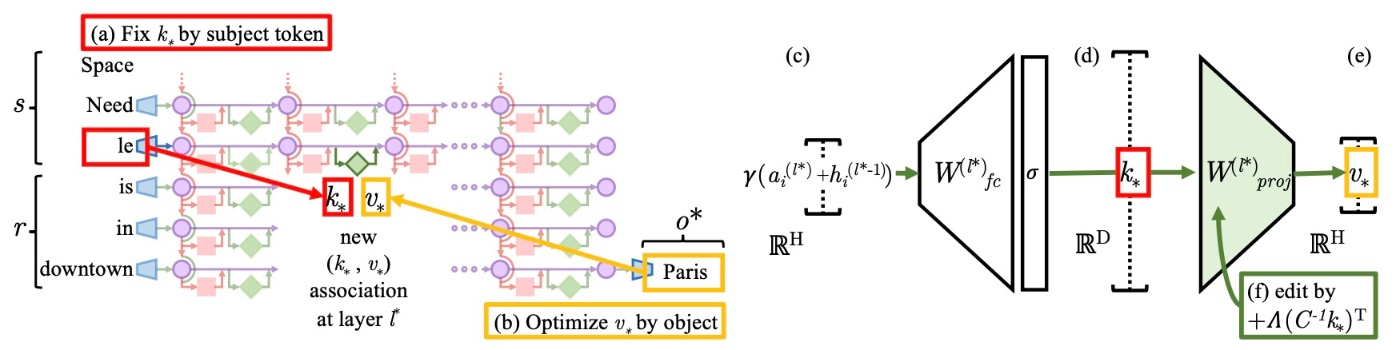
ROMEは残り3ステップから構成されます. 順番に見ていきます.
Step 1: subjectを選択するための
MLPの入力がfinal subject tokenで果たす決定的な役割に基づいて, last tokenでのsubjectを表す入力をlookup key
Step 2: 事実想起のための
次に, 新しい関係
です. 最初の項はベクトル
Step 3: 事実の挿入
完全な事実
を適用してMLPの重み
Evaluating ROME: Zero-Shot Relation Extraction (zsRE)
ROMEの性能を確認します. 比較対象は直接最適化を行うものか新しいネットワークを導入するものです. 具体的には
- Fine-Tuning (FT): 1つの層に対してAdamをearly stoppingありで用い,
-\log\mathbb{P}[o^*\mid x] - Constrained Fine-Tuning (FT+L): FTに加えてパラメータ空間の
L_{\infty} - Knowledge Editor (KE)とMENDはどちらもhypernetworksを用いる手法です
まずは, Zero-Shot Relation Extraction (zeRE) で実験を行います. 10000件のレコードを用います. 各レコードには1つのfactual statement, その言い換え, おっよび無関係な事実が含まれています. 評価指標はEfficacy, Paraphrase, Specificityです. EfficacyとParaphraseはそれぞれfactual statementとその言い換えにおける編集後のモデルの精度
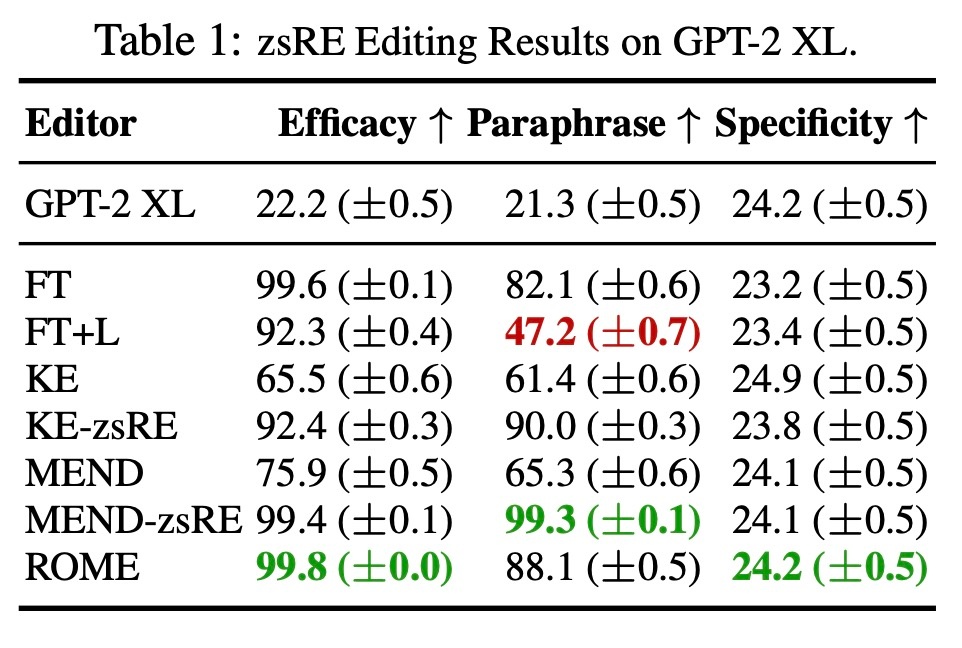
ROMEは他の手法と比較しても遜色ない結果を得ることができています. これは手法の複雑さを加味すると優位に立てそうな結果だと著者らは述べています. 特に, ROMEがモデルに再現されるような関連付けの挿入は難しくないことがわかります. 言い換えに対する頑健性は高いですが, zsRE分布に特化して訓練しているKE-zsREやMEND-zsREには及びません. また, zsREにおけるSpecificityはモデルの無関係な事実への影響度合いを敏感に測定することができていない指標であることがわかります. これは, promptは多数の可能な事実なサンプリングされているからです. 直感的に, ある知識を編集すると最も影響が及ぶのはそれに関連した知識です. そのため, 正しく影響を測るには関連する近隣のsubjectで行う必要があると著者らは考えています.
Evaluating ROME: Our CounterFact Dataset
先ほど見た評価指標は, ROMEをある程度評価できるもので, 評価のスタートとしては妥当ですが, 事実に関する意味のある変更に対する深い修正と, 表面的な言葉の変更を区別するための詳細な洞察は提供されないです.
著者らは特に, 重要な変更の有効性を測定したいです. 先行研究では, 標準的なモデル編集ベンチマークが, モデルが以前に高得点をつけた提案のみを測定するので, 難易度を過小評価していることを指摘しています. そのため, 著者らはより難易度の高い誤った事実
また, 著者らは生成されたテキストの意味的一貫性も測定したいと考えています. そのため, sで始まるテキストを生成し, 対象の属性
これまで述べた指標の測定を簡単に行うため, CounterFactという, 言語モデルにおける反事実的な編集を評価するための挑戦的な評価データセットを導入します. このデータセットは全部で21919件のレコードがあり, さまざまなsubject, relation, および言語的なバリエーションが豊富にあります. CounterFactの目標は, 新しい事実の堅牢な保存と, ターゲットワードの表面的な再現を区別することです. 以下の表はその構成の概要を示しています.

Confirming the Importance of Decisive States Identified by Causal Tracing
Causal Tracingを用いた実験では, 決定的な隠れ状態が特定されました. これらの状態を出力するMLPモジュールに事実の関連が実際に保存されていることを確認するために, 様々な層やトークンをターゲットとしてROMEを適用した際の効果を調べます.
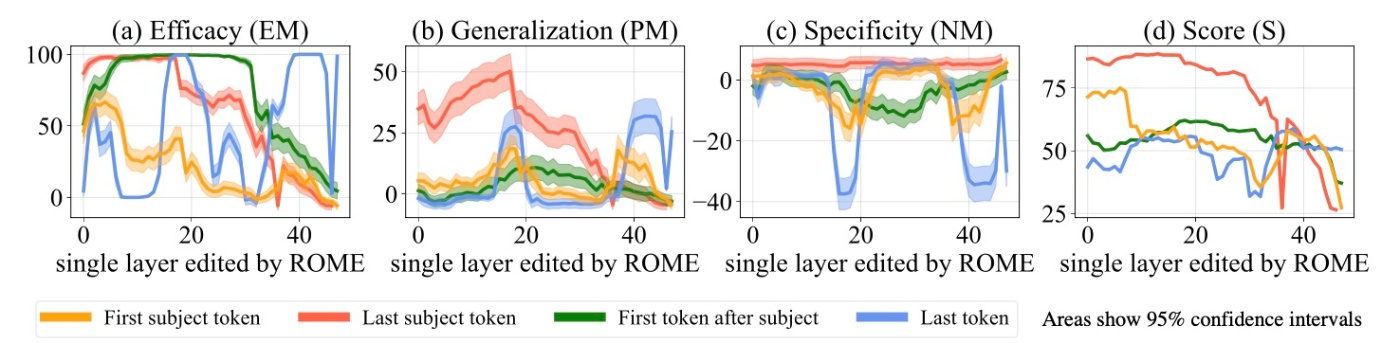
この図は一般化 (a, b, d)と特異性 (c)の両方を評価する4指標をプロットしたものです. 因果効果との強い相関が確認でき, 書き換えはlast subject tokenで最も成功し, 特異性と一般化の両方が中間層でピークに達しています. より前のトークンや後のトークンをターゲットとすると, 一般化や特異性が低下することもわかります. さらに, 編集が最も一般化されるのはCausal Tracingで特定された初期サイトの中間レイヤーに対応しており, 18番目の層です. これらの結果は事実の関連がどこに保存されているのかだけでなく, どのように保存されているのかについても正確に理解していることを示唆しています.
以下の表では, GPT2-XL (1.5B) とGPT-J (6B)における定量的結果を示します. この実験では, 以前の実験で用いたベースラインに加えて, ニューロンの解釈可能性に基づく方法であるKnowledge Neurons (KN) とも比較を行います. KNは, まず勾配に基づく寄与によって知識に関連するニューロンを選択し, その後対応する行のMLPの重みをスケーリングされた埋め込みベクトルを追加して修正します.
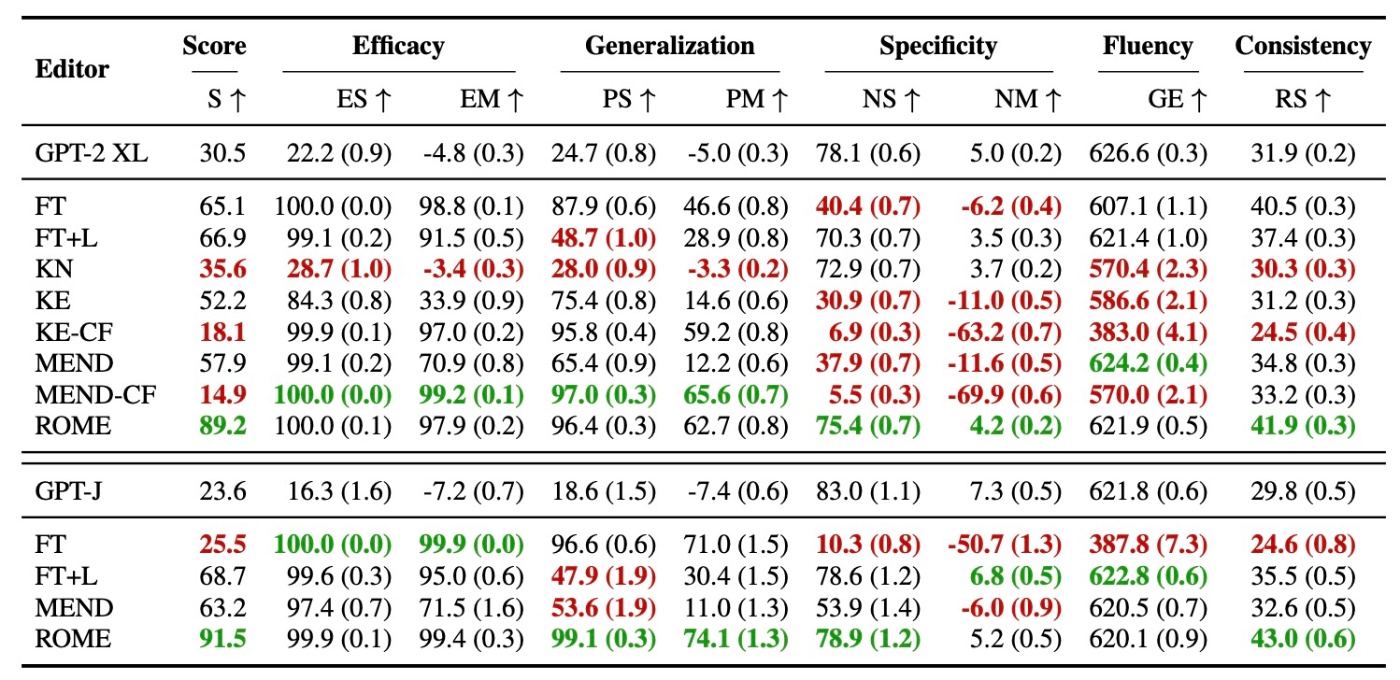
結果を見ると, ROME以外の全ての方法が以下のいずれか, または両方の問題を示すことがわかります.
- 反事実的な文にoverfittingし, 一般化に失敗する
- underfittingしてしまい, 無関係なsubjectにたいしても同じ新しい出力を予測する
例えばFTは高い一般化を達成しますが, 近隣のentitiyに対して誤りを起こします (2に該当). 逆に, FT+Lは1に該当します. KEやMENDは両方に当てはまり, 高い効果があるにも関わらず一般化や一貫性などが劣っているために再生が示唆されます. KNは効果的な編集を行うことすらできません. ROMEは今回の比較の中では一般化と特異性の両方において高い性能を示します.
Comparing Generation Results
生成結果をひとつだけ確認してみます. この例では, "Pierre Curie’s area of work is medicine" という反事実的な編集をGPT2-XLに行ったものです (実際にはPierre Curieは物理学者です).

一般化の観点から見てみます. すると, FTとROMEは言い換えに対しても対応できていて, 異なる言い回しでも物理学者ではなく医学者としてPierre Curieを説明しています. 一方で, FT+L, KE, MENDは一般化に失敗しており, 言い回しによっては医学または物理学のどちらかを交互に使っています. (c, d, e1またはc1, e, d1). KEは流暢さに問題があり (d), medicineを繰り返し生成しています.
特異性の観点から見ます. FT, KE, MENDは特異性に問題があり, 無関係な人物の職業も変更しています. 例えば編集前はRobert Millikanを天文学者として生成していたGPT2-XLが編集後はFT+Lでは生物学者 (b1), KEとMENDでは医学者 (d2, e2)と生成しています. これに対してROMEでは特異性を保持しており, 天文学者として生成しています.
おわりに
この論文では1.5BのGPT2-XLを用いています. 今から見ると非常に小規模なモデルですが, これより大きい規模のモデルが当時は非公開だったことが大きいです. この論文がarXivに投稿されたのが2022年2月で, 176BのオープンアクセスなモデルであるBLOOMがarXivに投稿されたのは同年11月ですので, まだ大規模化は進んでいないときと考えられます. 最近ではモデルの規模が大きくなると性能が突然上がるようなこと (創発性)が言われてたりします[1]. このことを踏まえると, より大きいモデルでも同じ傾向なのかを確認したくなります. 例えば以下の記事では6Bのモデルを用いて類似の結果を得ることができています. 軽く調べただけなので6B程度ですが, おそらく13Bなどでも同様なのではと思います.
また, ROMEはその分析手法を見て分かるように, SVO形式を前提としています. 当然ですが, SVO以外で終わる形式の文章も存在します. そのような形式に対する研究では軽く調べた感じだと日本語論文で
などがあります.
参考文献
- Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in gpt. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 17359–17372. Curran Associates, Inc., 2022.
-
これは評価指標によるものだと主張する論文もあります ↩︎
Discussion