Stable Diffusionからの概念消去⑩:R.A.C.E (論文)
R.A.C.E.: Robust Adversarial Concept Erasure for Secure Text-to-Image Diffusion Model (ECCV2024)
引き続き, ECCV2024での概念消去の論文を見ていきます. とは言いつつECCV2024はまだaccepted papersのタイトルを確認できないので見つけたものから順番に, という感じです.
図表はことわりのない限りこの論文からの引用です.
書籍情報
Changhoon Kim, Kyle Min, and Yezhou Yang. R.a.c.e.: Robust adversarial concept erasure for secure text-to-image diffusion model, 2024.
関連リンク
TL;DR
貢献は著者らが論文内でまとめてくれていますので, それをそのまま日本語にします.
- 敵対的学習の枠組みを初めて取り入れ, prompt-basedな攻撃手法によって概念消去を達成した. なお, 追加モジュールはない.
- 提案手法であるRACEは計算効率の良い敵対的攻撃手法を実装しているので概念消去に組み込める
- RACEは、white/black-boxな攻撃に基づくpromptに対するT2Iモデルの頑健性を大幅に向上させた
準備
簡単にベース技術を示します. まず, Stable Diffusionです. これは主にimage autoencoderとU-Netの2つから構成されていています. image autoencoderはencoder
で学習を行います.
続いて, ESDです. ESDは以下の損失関数によって特定の概念を削除します.
ここで, 追加のデータセットは必要ない点が特徴です.
このような概念消去に対して, red tamingというものがあります. これは, 消去された概念を復活させようというものです. これを達成するには敵対的なprompt
Adversarial Training on Concept Erased Diffusion Models
では, どのように統合すればいいのでしょう.
モチベーション
T2Iの拡散モデルは,
で学習を行いますが, 実はこの損失関数は分類タスクにも用いることができます. この分類能力はモデルの予測
特に, 事前分布がprompt
ここから, 拡散モデルを用いた画像分類では次の式を計算することで画像
ここで, 単一のタイムステップ
Single-Timestep Adversarial Attacks on Erased T2I Models
先ほどの観点から, SDの損失関数を分類機構として再構築します. Textual Inversionを, 画像
ここで, Textual Inversionは全てのタイムステップにわたる最適化が必要なので計算量は大きいです. そのため, 課題は「敵対的text embeddingは単一のタイムステップで特定できるのか?」となります.
概念消去の目的は, 消去された概念の画像
Adversarial Training for T2I Concept Erasure
さて, 単一のタイムステップでの敵対的攻撃が可能であることがわかりましたが, これが概念消去において頑健性を向上させるのかは不明です. ここでは, 「敵対的攻撃は概念消去メカニズムの耐性を向上させることができるのか?」について調査します.
RACEでは既存手法とは異なり, 対象概念のembeddingだけでなく隣接概念のembeddingも消去することを目指します. これは隣接概念によって意図せず消した概念が復活することを防ぐためです. 敵対的攻撃をESDに組み込みます.
本来なら実験を行って確認するところですが, それは実験セクションに譲ります.
ここで, アルゴリズムの全体像を確認します. 二重のfor-loopになっていますが, 内側が敵対的の部分です.

実験
実験設定
基本的には既存研究と同様の評価を行います.
RACEをESDに組み込んで評価を行います. 先ほどのアルゴリズムにおいて
頑健性をテストするために, white/black box approachで敵対的攻撃を行います. 初期評価ではI2P Red Taming Promptを用います. Black-boxのシナリオではCLIPを用いて敵対的promptを生成するPEZという手法を使用します. White-boxのシナリオではSDの勾配を用いてpromptを生成するP4DやUnlearnDiffを用います.
評価指標ですが, ASRを用います. 特に, 基盤モデルではなくドメイン固有のものを用います. 例えばstyleではImageNetで訓練され, WikiArtでfine-tuningされたViT-base, NudityはNudeNet, objectはImageNetで訓練されたResNet-50を使用します. ASRは
で計算します. ここで,
結果
定性評価を行うのですが, ここではNudityの評価は省略しますので, 結果の方は論文を参照ください.

White-box手法であるUnlearnDiffと比較すると, RACEの方がより優れた敵対的手法と言えそうな結果になっています. ここで重要なのは, RACEの方法論的な利点がprompt生成のために外部の画像やpromptに依存しない点で, 既存手法とは一線を画している点です.
続いて, 定量評価を行います. RACEはASRを最大で30%ほど低下させることに成功しています.
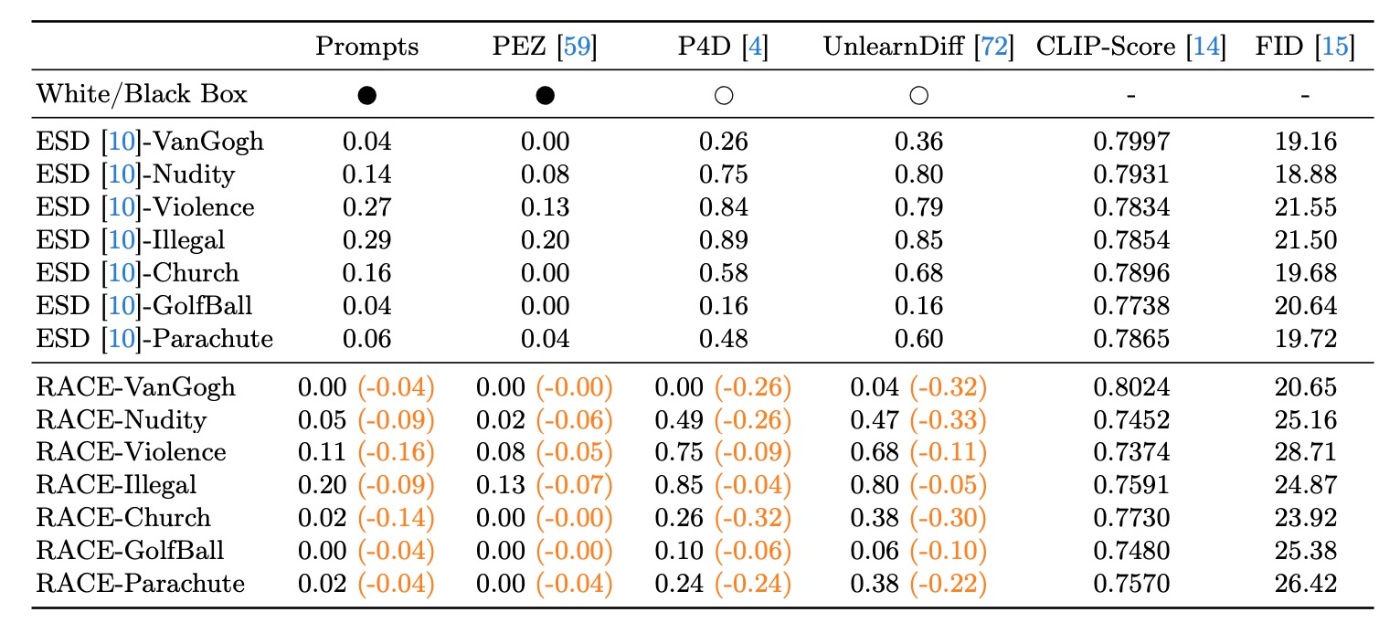
上表からもわかるように, NudityでもASRを30%以上低下させていることがわかります. どのようにしてASRが改善しているかを明らかにするために消去対象のカテゴリや要素を分析します. NudeNetを用いてI2PからNudity promptsに対してoriginal SD, ESD, UnlearnDiff, RACEが生成したものを列挙します.

ESDはかなりの消去に成功していますが, UnlearnDiff攻撃によって再生成が可能になっていることがわかります. これとは対照的にRACEはUnlearnDiff攻撃に対しても頑健性を維持しています.
ただし, 表のFIDの部分から分かるように, 頑健性と引き換えに生成品質が悪化していることがわかります. いわゆるトレードオフです. その原因については考察がされていますが, あくまで考察レベルなのでここでは取り上げません. なお, 後述する工夫によってトレードオフの解消を試みます.
Disentanglement
概念消去ではいくつか達成すべき事項がありますが, そのひとつに他の概念への影響が軽微であることが挙げられます. 生成例を見てみます. たしかに, 定性的には他の概念への影響はあまりなさそうです.

定量評価も行います. 5000のpromptを作成して画像生成を行います. 前述したResNet-50を使用しtop-1 accuracyを測定します.

RACEはESDと比較して消去能力が向上していることがわかります. しかしながら, 他の概念の維持能力は低下しているようです. これについて著者らはRACEが対象概念の
Discussion
先ほど頑健性と品質がトレードオフになるという話をしました. これに対して著者らは以下の式のように損失関数に正則化項を加えて実験を行いました.
ここで,

ESDと比較して頑健性を維持しつつ品質を改善していて, トレードオフの部分的解消に成功していると述べていますが, 少し微妙な結果に思えます.
この結果に出てくるRACE+keywordsですが, 対象概念が同義語で現れることを考慮したものです. 例えばNudityの場合, nude, nsfw, bareなどがあります. この手法は確かに頑健性を向上させますが, 却ってトレードオフを強めています.
思ったこと
- 敵対的学習をうまく組み込むのは新しくていいと思いました. 既存手法だと時間がかかりますが, 特定のタイムステップだけでうまくいくのも非常に魅力的です.
- 結果は微妙な気がします. 特に, 学習を行うことが前提なのでclosed-formで更新するような手法には使えない気がします
- 論文とは関係ないですが, ESDの公式実装の上に実装されているので論文の実装の仕方がかなり古いことが気になりました. ESDはdiffusersの実装も公開されているのでそっちをベースにした方が研究的にはやりやすいと思います.
参考文献
- Changhoon Kim, Kyle Min, and Yezhou Yang. R.a.c.e.: Robust adversarial concept erasure for secure text-to-image diffusion model, 2024.
Discussion