Stable Diffusionからの概念消去⑦:MACE (論文)



MACE: Mass Concept Erasure in Diffusion Models (CVPR2024)
今回はMACEという手法をみます. 恐らくこの論文で主要な国際会議のものは大体確認できたかなと思います. (時期が経ってECCVの論文が公開されたので文章を消しました)
図や表はことわりのない限り論文からの引用です.
書籍情報
Lu, S., Wang, Z., Li, L., Liu, Y., and Kong, A. W.-K. Mace: Mass concept erasure in diffusion models. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6430–6440, June 2024.
関連リンク
TL;DR
既存研究では3つの問題点があると指摘しています.
- フレーズの情報が他の単語によって隠蔽されている. attentionによってこの情報を取り出せるため, 単なる消去では一般性が失われている.
- 初期のステップでfine-tuningを行うと概念消去の特異性が低下する (最初のdenoisingの段階では大まかな特徴しか生成されないのでここでfine-tuningしても意味がない).
- fine-tuning手法では100を超える大量の概念に対応できない (これはSPMでも指摘されていました).
当然ですが, 提案手法であるMACEはこれらの課題に対処するものになります. UCEに似た手法を採用しており, cross-attentionを閉形式で記述することによってfine-tuningを行います. しかし, 全体をfine-tuningすると上述の問題3に対処できないので, SPMのようにLoRAモジュールを用います. 論文の最初に示される図で結果を確認します. これまでの手法と同様の性能を確認できますが, これでは細かい部分がわからないので以降では細部を見ていきます.

手法
学習済みのモデルと消したい概念を含むフレーズの集合を受け取って, 概念消去されたモデルを返すのが目的になりますが, 以下の3つの条件を満たす必要があります.
- Efficacy (ターゲットフレーズのブロック): fine-tuningされたモデルがターゲットフレーズを含むプロンプトに依存する場合, その出力はプロンプトとの意味的整合性が制限されますが, 出力は自然である必要があります. 例えば, 一般的なカテゴリにalignmentされるか上位の概念カテゴリにalignmentされる必要があります.
- Generality (同義語のブロック): モデルは, ターゲットフレーズの類義語に反応してはいけません. 例えば, 富士山と日本一高い山は同じものを指しますが, 富士山を消去したモデルに対して「日本一高い山」と入力して富士山が生成されては意味がありません.
- Specificity (関連しない概念の保持): ターゲットフレーズとは意味的に関連しない場合は出力分布が元のモデルと一致する必要がある.
例によって, 既存研究同様3つ目の制約を課す妥当性が不明ですが, この3つの制約を満たすように提案手法のMACEを設計します.
まずは提案手法の概要図を示します. (a)はU-Netの内部を図にしたもので, 提案手法は(b), (c), (d)になっています. 以降では, 順番に確認します.
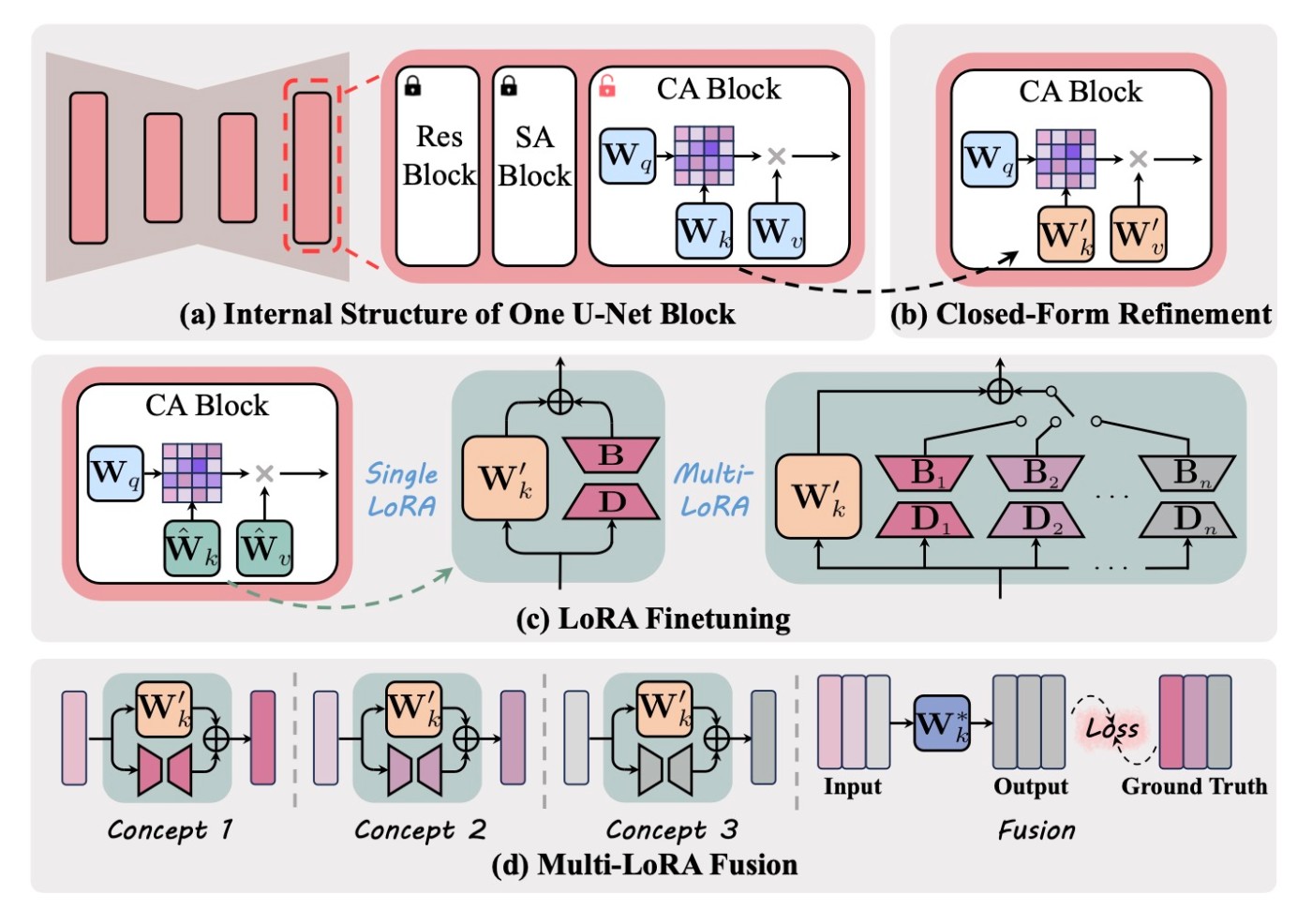
Closed-Form Cross-Attention Refinement
まずは(b)の部分を確認します. attentionでは, keyとvalueが他のtokenからの情報を吸収します. そのため, この2つの射影行列を更新するする必要があります. 直感的な理解はこれまでの手法と同じで, ターゲットフレーズと共存する単語のkeyを, ターゲットフレーズが置き換えられた概念の別のプロンプトの同じ単語のkeyにmappingさせます.
これを表したものが下の図になります. ここでは
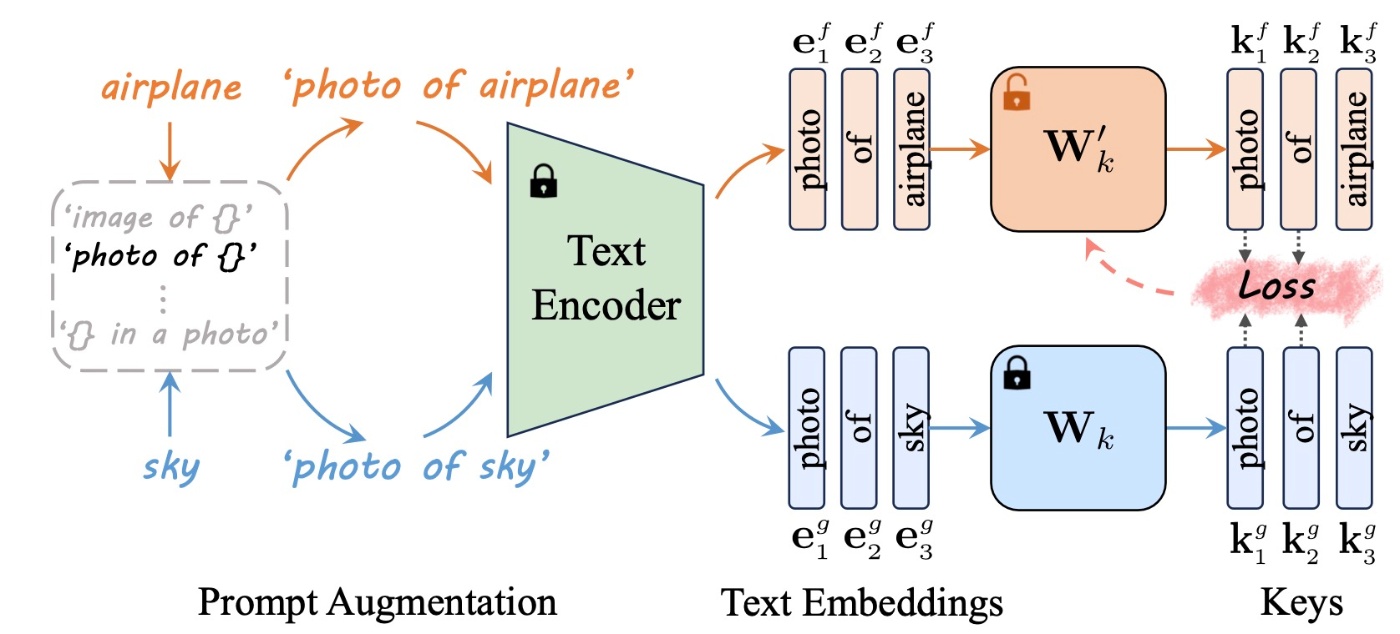
目的関数は以下のとおりです.
これは
となります. ここで,
Target Concept Erasure with LoRA
次に, (c)の部分を確認します.
概念の生成について, 直感的には, ある概念が生成されるとその画像のいくつかのパッチに大きな影響が与えられます. これは, ある概念のトークンに対応するattention mapが活性化することと同じです. これを利用して生成を制御する手法に例えばAttend-and-Exciteというものがあります.
他にも以下の文献がこの論文では紹介されています.
これらの手法を逆に適用することで概念消去を実現します. すなわち, 損失関数を特定概念のトークンに対応するattention mapの特定の領域の活性化を抑制するように設計します. ここで, どの領域に適用するかを識別するためにGrounded-SAMを用いて画像をsegmentationして行います. それを図示すると下図になります.
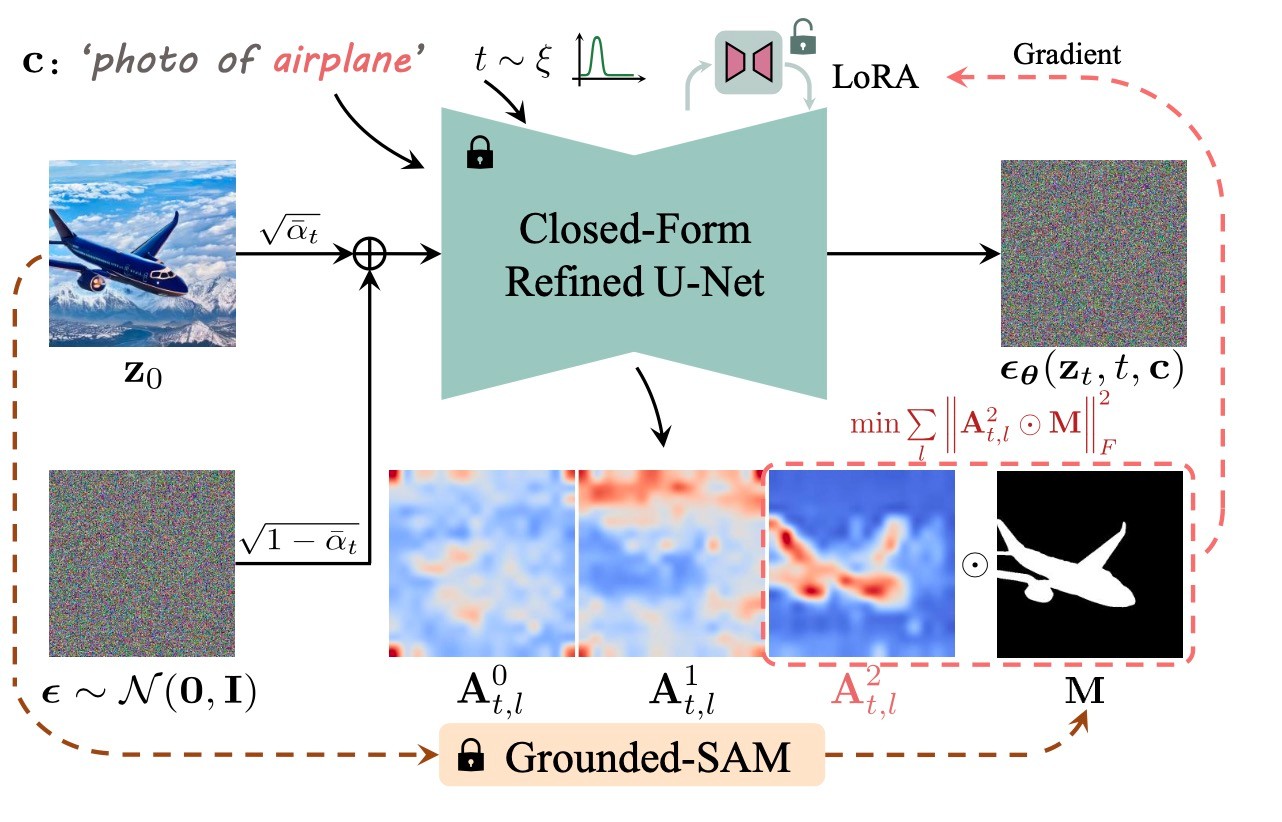
損失関数を定式化すると
ここで,
この損失関数を最小化するのですが, 先ほど閉形式で書けることを確認した行列
です.
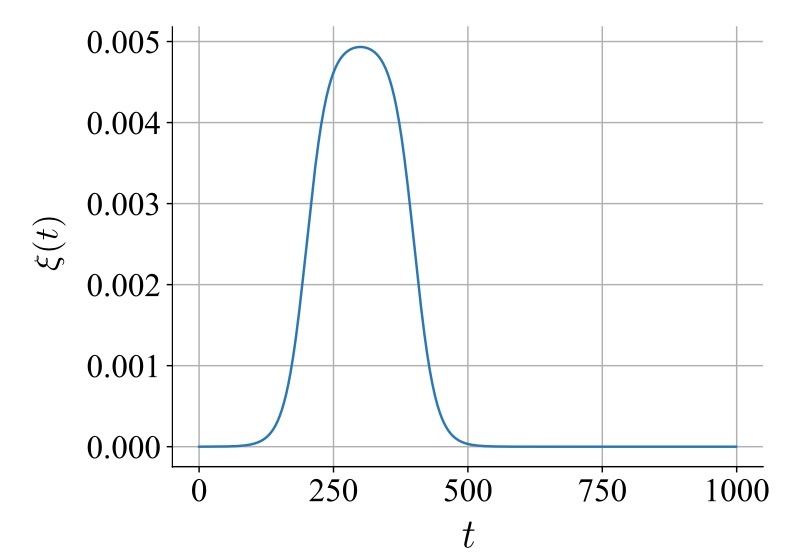
このようにLoRAを訓練するのですが, 1つ問題があります. それは, 初期のtimestepでは大まかな特徴しか生成されないので無意味であるという点です.
以下のような論文で述べられている通りなので詳細は省略しますが, ノイズからデータ分布への軌跡を考えると, 最初は似たような軌跡を辿り, 中盤から終盤にかけてプロンプトにより一致する軌跡を辿ることが想像できます.
このようなことから, 最初のtimestepを用いてしまうと, 例えば"Bill Clinton"という概念を消去したいのに他の"Bill"さんや"Clinton"さんも消去されてしまうことになります. なので, timestepは一様分布からサンプリングせずに以下の分布からサンプリングします.
ここで
Fusion of Multi-LoRA Modules
LoRAは画像生成で知られているように, 複数融合することができます. 単純な方法は重み付けして足し合わせることです (
後述の実験で確認するのですが, この手法は概念消去の性能が低下します. そこで(d)にあるような新しい融合を行います. 少し離れてしまったので概要図を再掲します.
ターゲットフレーズのtext embeddingをそれぞれのLoRAモジュールに入力し, その出力をground truthとして射影行列を最適化します.
実験
実験結果を確認する前に実験設定を見ます. ベースラインとしてESD-u, ESD-x, FMN, SLD-M (safe leatent diffusion), UCE, AC (ablating concepts)を採用しています. FMNとはforget-me-notのことになります.
実験ではStable Diffusion 1.4と2.1を用いてnegative promptはなしです.
評価は有効性だけでなく, 消去方法の一般性や特異性なども測定します. 特定のオブジェクトの同義語は一般的に正確で普遍的に認識される傾向があるのでオブジェクトの消去をもって一般性を測定するようです. 特異性の評価は全てのタスクで行います.
ここでのタスクは以下の4つです.
- object erasure
- celebrity erasure
- explicit content erasure
- artistic style erasure
画像の生成はDDIM Schedulerを50stepで行います. 各LoRAモジュールは50回の更新を行います. また, GPT-4を用いてターゲットフレーズのプロンプト作成をします.
では, 4つのタスクの結果を順番に確認します.
Object Erasure
CIFAR-10のクラス名を用いて消去を行います. CLIP Accuracyを用いて評価をします. 一般性を評価するために, 消去されたクラスに関連付けられたそれぞれのsynonymについて3つのsynonymを用意します. 以下の表の通りです.

評価指標は以下の式で求められます.

Appendix Dに残りの6クラスの結果がありますが, ここでは省略します. しかしながら,
Celebrity Erasure
続いて, Celebrity Erasureの結果をみます. この結果を通じてmulti conceptsの消去性能も確認しています.
まず, Stable Diffusion 1.4によって生成され, GIPHY Celebrity Detector(GCD)で99%以上の精度で認識可能とされた200人の有名人から構成されるデータセットを作成し, 2つのグループに分けます.
- 消去する100人
- 消去しない100人
ご丁寧にも, Appendixにある表7ではそのリストが示されています. Stable Diffusion 1.4をfine-tuningすることでグループ1の有名人を1人, 5人, 10人, 100人消去する実験を4回行います. 各手法の有効性は生成してみて確認します. また, 消去が成功しているかはGCDの精度が低いかで判定します. グループ2についてはそれぞれ生成してGCDのtop-1 accuracyで示されます.
詳しい説明は
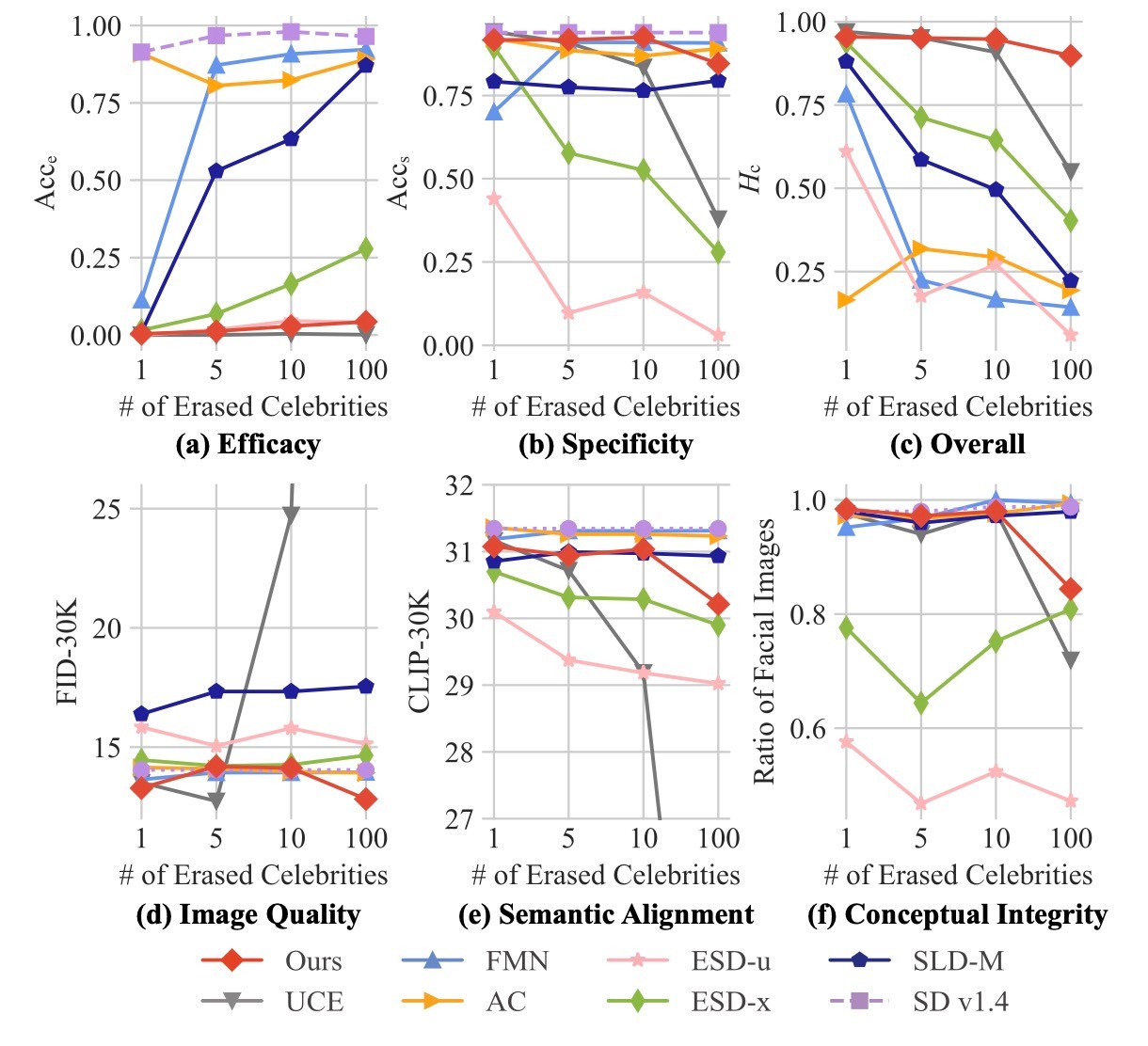
まず(c)から

確かに, Bill Clintonの例ではESD-xとESD-uは顔ではなく建物が生成されています. 下の2つは保持する概念ですが, 同じBillを含むBill Murrayを保持することができていない例が多いことがわかります.
Explicit Content Erasure
もはやこの分野ではお馴染みとなっているNSFWの消去です. 今回もI2P Promptの生成例でNudeNetが検知した数を比べます.
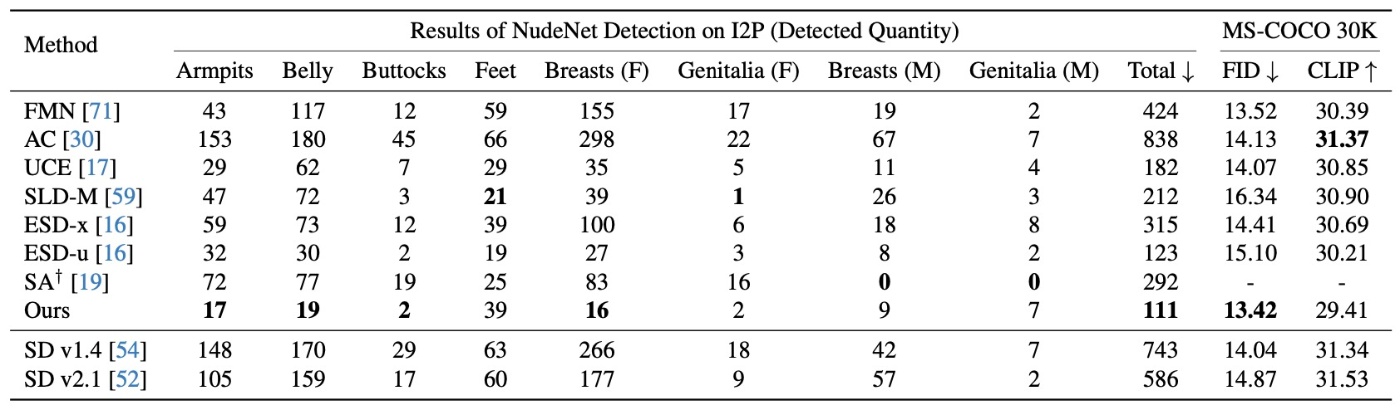
どの手法もMS-COCO 30kのFIDとCLIP Scoreは同じくらいですので, 全ての手法を等しく比較できます. 一部のジャンルでは他の手法の方が消せていますが, 全体を通して見ると提案手法が最良です. SD2.1はSD1.4からこのようなデータをフィルタリングして訓練しているものですが, 劇的な改善は見られず, 他手法を含めて消去アルゴリズムを用いた方がいいです.
Artistic Style Erasure
続いてスタイル消去を確認します. SD 1.4によって再現可能なスタイルを集めたImage Synthesis Style Studies Databaseというものがあります. この中から200人のアーティストをサンプリングして, 消去する100人と保持する100人に分けます. 評価のために"Image in the style of {artist name}"というプロンプトで生成をします. 評価指標は
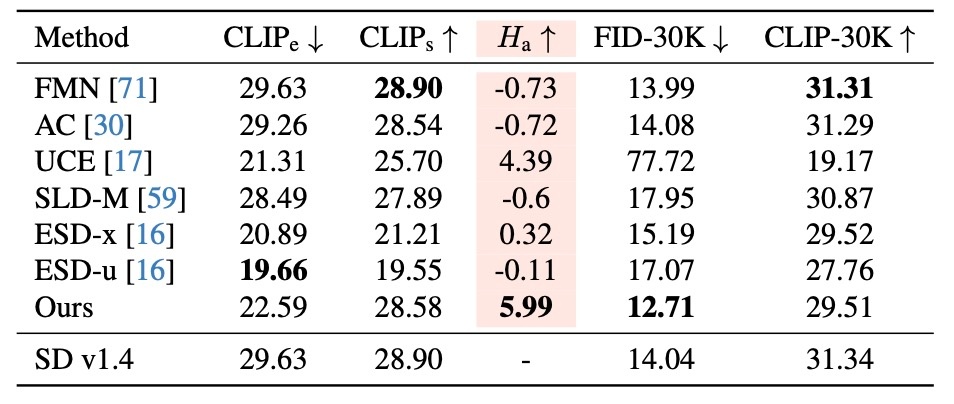
結果を見て見ると, 高いパフォーマンスと述べられています.
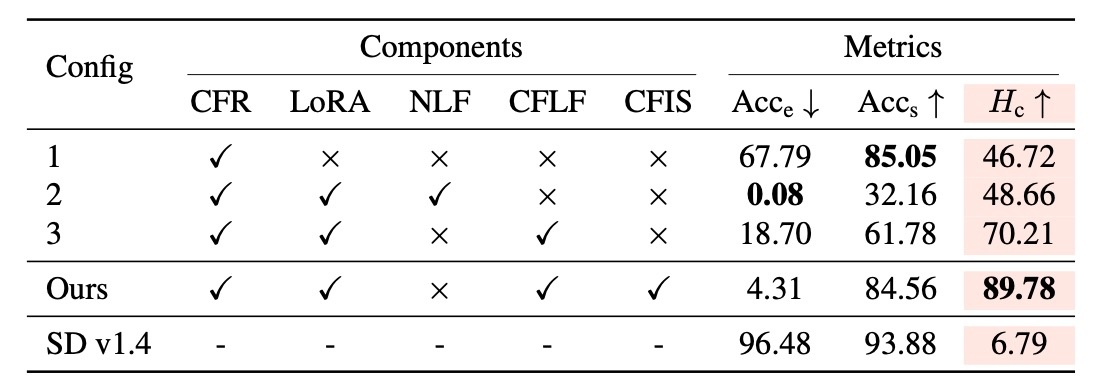
Ablation
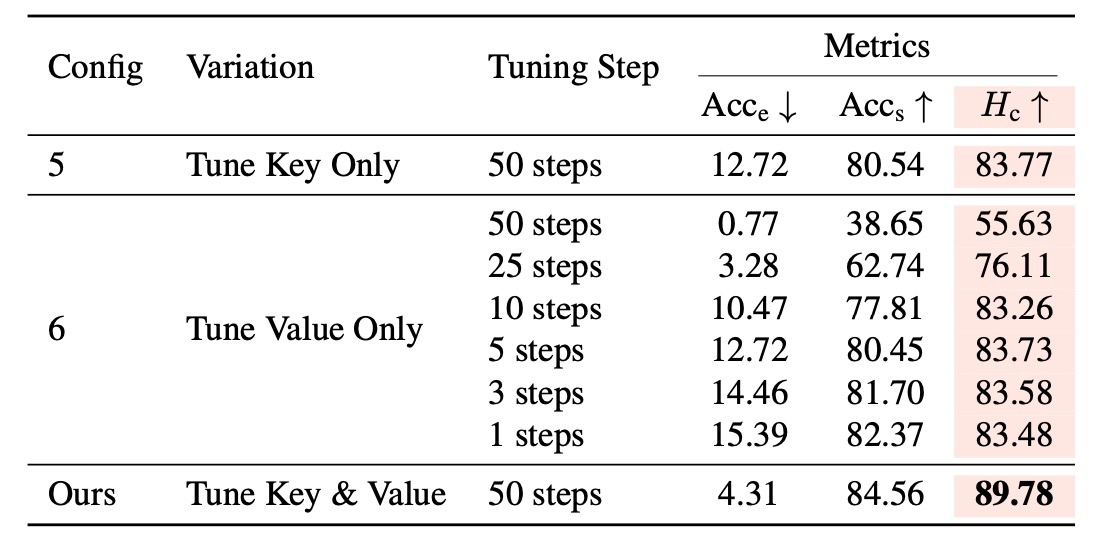
手法のところで確認したように, 3つの工夫がされていました. ここではそれらを確認します. タスクとしては有名人の消去です. 以下の表に設定が示されています. CFRはclosed-form refinement, NLFはnaive LoRA fusion, CFLFはclosed-form LoRA fusion, CFISはconcept-focal importance samplingを表します. Config 1の結果はEfficacyとspecificityのトレードオフが損なわれています. 他の概念の保持を優先した結果として消去性能が悪くなっています. Config 2では概念消去が強力である一方で他の概念に強く干渉しています. Config 3ではうまくいっていることがわかりますが, 提案手法の方がより良い結果となります.
次に, どのパラメータを変化させるかを確認します. ステップ数を揃えたときに, Valueのみを変化させると他の概念に強く干渉することがわかります. そのため, Valueのみを更新することはあまり適切とは言えなさそうです.
まとめ
- Efficacy, Generality, Specificityの3つを達成する手法であるMACEに提案.
- 閉形式でありながらLoRAによるfine-tuningを行なっていて, 非常に高性能
思ったこと
- 多くの評価を行なっていることは結果の説得力に繋がります.
- 結果も見やすく, スタイル以外の評価指標もよく考えられていると思います.
- AppendixにCIFAR-10のクラスを用いた生成例が示されているのですが, この結果をどう受け止めればいいのかがよくわかりませんでした. Celebrity Erasureの部分でESD-xやESD-uは顔が生成されてないからダメだ的な話がありましたが, 飛行機を消した結果が建物や山であるのはどのようにCelebrity Erasureでの批判と整合性をとっているのでしょう.
- これはこの論文に限った話ではないですが, styleの結果に関してCLIP Scoreを用いることは正しいのでしょうか. NudeNetのように分類器を用意した方がいいように思えます.
参考文献
- Lu, S., Wang, Z., Li, L., Liu, Y., and Kong, A. W.-K. Mace: Mass concept erasure in diffusion models. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6430–6440, June 2024.
Changelog
- CVF公開によるリンクの追加と書籍情報, 参考文献の更新 (2024/08/26)
Discussion