言語モデルは時系列予測に役立つのか? (NeurIPS2024)


今回はAre Language Models Actually Useful for Time Series Forecasting?という論文に触れます.
はじめに
LLMの社会実装が徐々に進んでいて, 最初は言語だけだったのがマルチモーダルになっています. 例えばBLIPのように最初は少しの文章だけだったのが今は画像を見て長い文章を生成するなど非常に高性能になりつつあります. その流れもあって, LLMを時系列データに使う動きも見られます. 個人的な考えとしてはTransformerが有効かどうかですら結論が出ていないのにどうなんだという感じはします (例えばTransformer系の論文では多くの場合, Transformer familyの中で性能が出たということしか主張していません).
今回扱う論文のタイトルは"Are Language Models Actually Useful for Time Series Forecasting?"で, 非常に"Are Transformers Effective for Time Series Forecasting?"を意識しているように見えます (もちろんこの論文も引用されていました).
ちなみにこの論文については以下の時系列予測にTransformerを使うのは有効か?というまとめが非常に参考になります.
関連リンク
本記事中の図表は全て論文"Are Language Models Actually Useful for Time Series Forecasting?"からの引用です.
主張
著者らの主張は非常にシンプルです.
popular methods for adapting language models for time series forecasting perform the same or worse than basic ablations, yet require orders of magnitude more compute.
すなわち, 「LLMを時系列予測に転用した場合, 計算量は増えるし従来手法より性能改善は大してないか悪化している」というものです.
しかし, 決してLLMが不要と言っているわけではありません. むしろLLMの活用は時系列推論や社会的理解 (social understanding, social science)に目を向けるべきとしています.
本論文の主な貢献は以下の3つです.
- 時系列データをLLMに入力して予測する手法に対する3つのシンプルなablation手法の提案. 13のデータセットに対して3手法をablationし, LLMが時系列予測を改善しないことを発見.
- LLMの事前学習の影響を調査するために予測前にその重みを再初期化した結果, 予測性能には影響がないことを確認. 入力時系列をシャッフルしても, LLMがテキストから時系列に系列モデリング能力を成功裏に転移する証拠がなく, few-shotも同様.
- PatchingとAttentionをEncoderとして使用する非常にシンプルなモデルがLLMと同等のパフォーマンスを達成できることを確認. LLMの利点と時系列予測との間に大きなギャップが存在することを示唆しており, 未だ未解決.
以降では実験設定を確認したのちに実験結果を見ていきます.
実験設定
GPT4TS (OneFitsAll), LLaTA, Time-LLMの3手法を用いて実験します. これらは2023年12月から2024年5月までに登場したモデルで, 一定以上の人気があるとされています (GitHubのstarsが合計で1245と論文には書かれています).

ablationを行う手法としてここでは3つが提案されています.
- w/o LLM: LLMを取り除きます. すなわち時系列データをencoderに通したらそのままprojection networkに渡します.
- LLM2Attn: LLMをランダムに初期化した1つのMultihead-attention layerにします.
- LLM2Trsf: AttentionではなくTransformerにします.
図示すると以下のとおりです. ここで, projection networkは変えません.
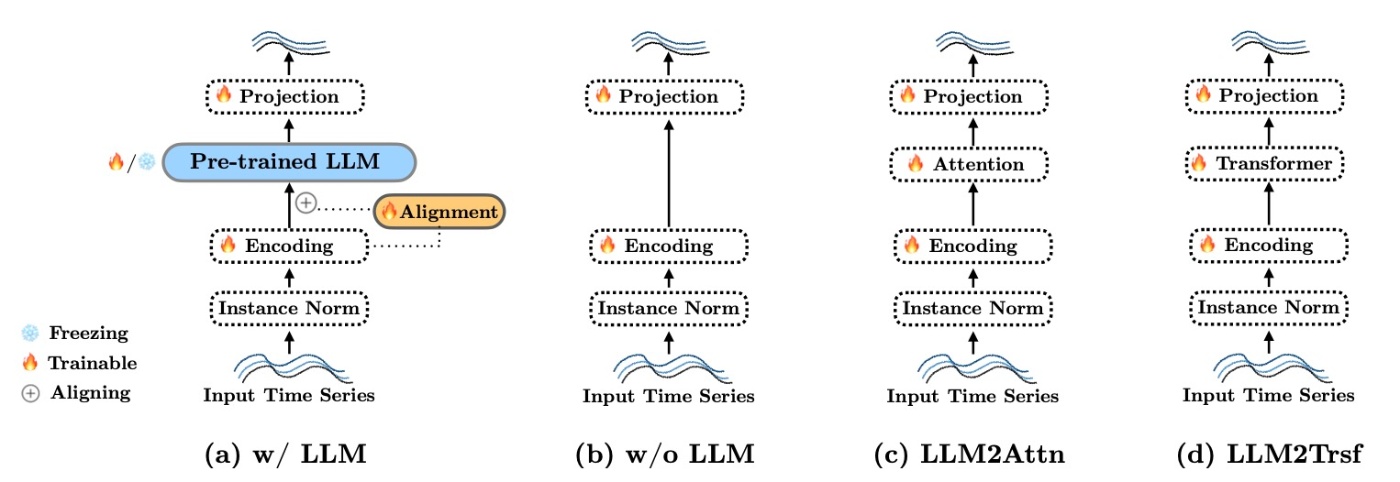
13のデータセットで実験します. 内訳はETTh1, ETTh2, ETTm1, EETm2, Illness, Weather, Traffic, Electricity, Exchange Rate, Covid Death, Taxi(30min), NN5(Daily), FRED-MDです.
評価指標はMAEとMSEです.
結果
結果を確認する前に, どのような問題意識を持って結果を見るかをチェックします. 著者らは全部で6つの観点から結果を分析します.
- 事前学習された言語モデルは予測性能に貢献するか?
- LLMベースの手法は計算コストに見合う価値があるか?
- 言語モデルの事前学習は予測タスクのパフォーマンスに役立つか?
- LLMは時系列の順序依存性を表現するか?
- LLMはfew-shot learningに役立つか?
- パフォーマンスの源はどこにあるか?
順番に見ていきます.
事前学習された言語モデルは予測性能に貢献するか?
結論を述べると, 「まだ役に立っているとは言えない」 です.
まず, 定量的な結果を確認します.
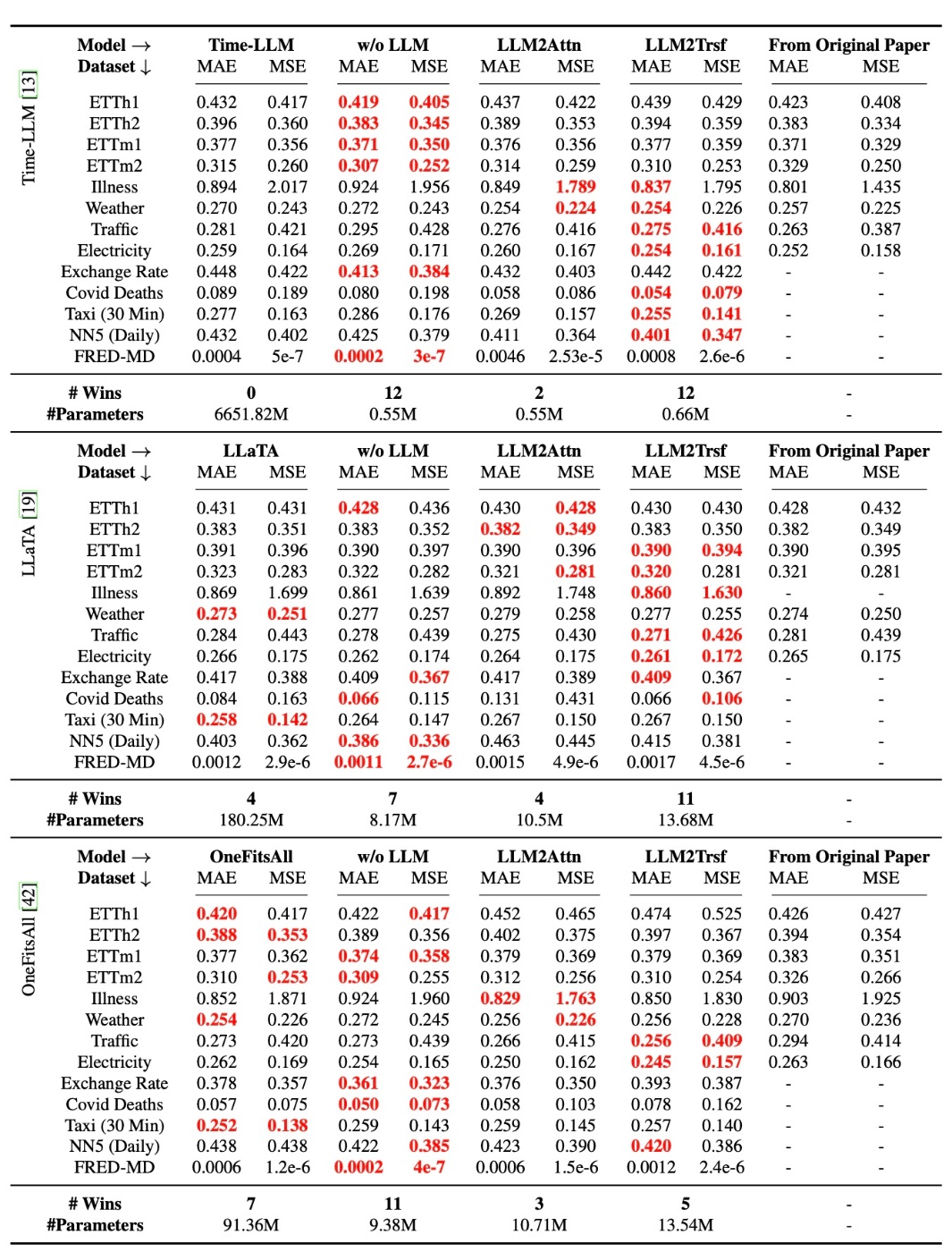
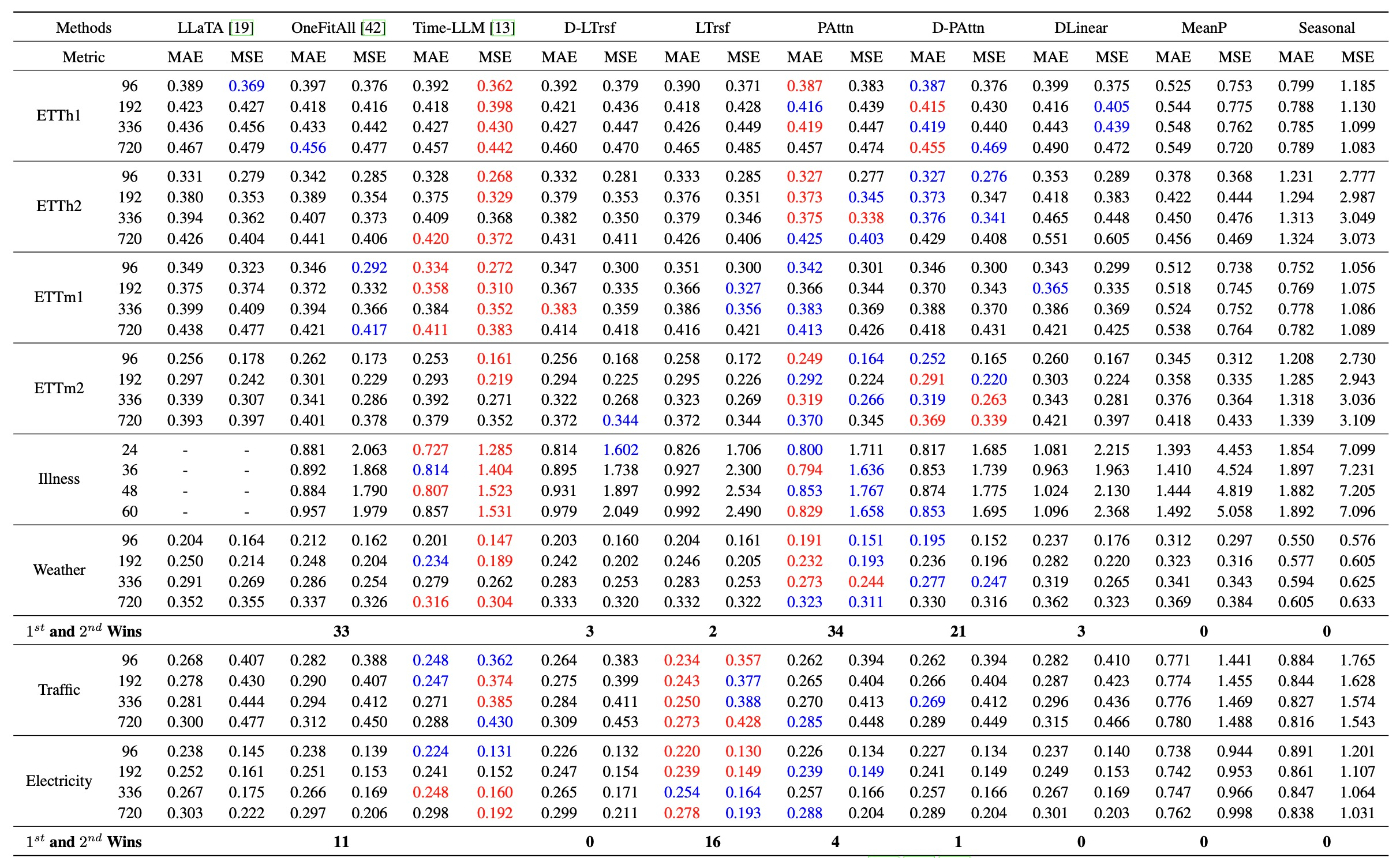
この表から分かるように, best performaceである赤色は多くのケースでwith LLMではない場合になっています. これは評価指標がMAEでもMSEでも同様の傾向ですので全体的な傾向といえます. また, Original Paperとwith LLMのスコアが同等であることから, 著者らの実験に不備があったとは考えにくいです.
各タスクに対して95% bootstrapped confidence intervalsをプロットしたのが以下の図になります.

例えば先ほどの表では, ETTh1ではOneFitsAllがablationよりよい性能を示していますが, 上図左上では他のablationとの重なりが確認できます.
これらの結果から著者らは「LLMが時系列予測において効果的であると結論づけるのは難しい」としています.
LLMベースの手法は計算コストに見合う価値があるか?
結論を述べると 「ない」 です.
今回の実験で用いたLLMは数億から数十億のパラメータを有する場合があります. LLMがfrozenであっても推論には多くのコストを要求することは周知の事実と言えるので, 計算負荷が気になります.
Time-LLMを例に考えます. この手法は6642M (6.6B)パラメータを持ち, 例えばWeather datasetでは学習に3000分かかります. GPUは80GBのNVIDIA A100が使われています. これと比較すると, ablationの手法では0.245Mパラメータで学習には2分程度の時間しかかかりません. 実際にEETh1とWeatherでの結果を表に示します.
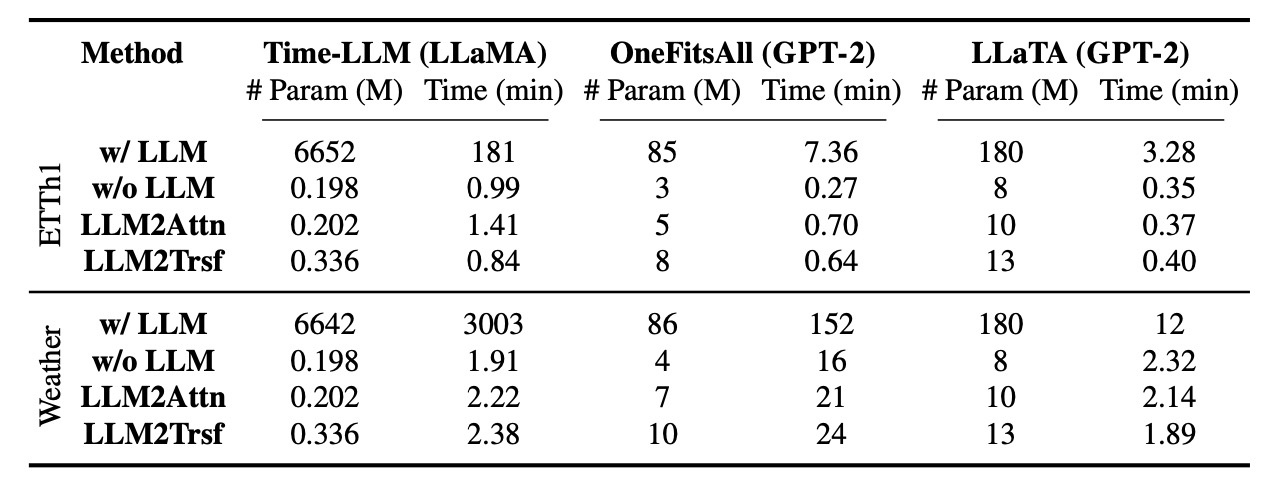
当然, 言語モデルが大きくなるほど学習に必要な時間は長くなっています. さらに, GPT-2という軽量なモデルでもablationのほうが高速に訓練が完了します.
推論でも同様のことが言えます. 以下の図は推論にかかる時間と精度をプロットしたものです.
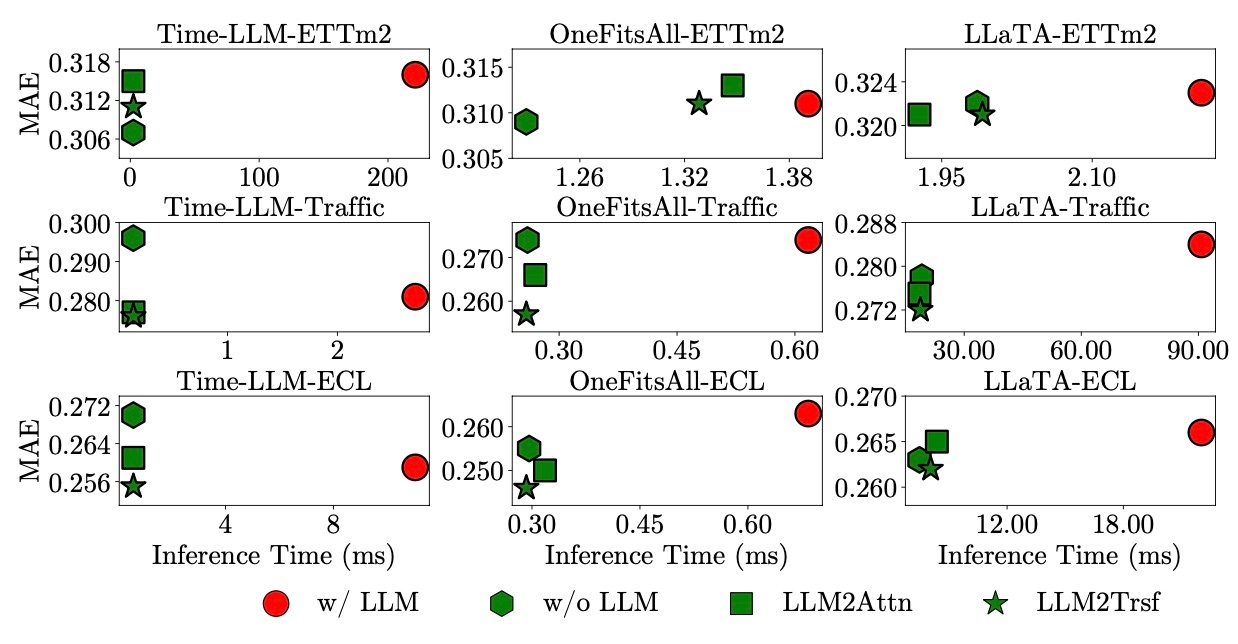
LLMを用いている赤色の点は基本的にグラフの右側に位置しており, 重要なのは赤色の左下にもプロットがあるということです. これはLLMを用いるより推論時間が短く, さらに精度もいい場合があることを意味しており, 現状の工夫ではLLMを用いるメリットがないことを示しています.
結論として, 「時系列予測タスクにおけるLLMの計算負荷は対応するパフォーマンスの向上には繋がらない」ということになります.
言語モデルの事前学習は予測タスクのパフォーマンスに役立つか?
LLMを導入する動機づけとして, 我々はLLMに備わっている能力をうまく使いたいというものがあると思います. 果たして既存手法はそれができているのか?ということをここでは確認します. 結論から言えば 「役立っていない」 です.
LLaTAのLLM (GPT-2)を時系列データでpretraining, fine-tuningする様々な組み合わせで実験します.
- Pretraining + Fine-Tuning (Pre+FT): これはLLaTAそのものです. 事前学習は言語で行うので学習済みモデルを時系列データでfine-tuningします. LLaTAの場合, LLMは固定してLoRAでfine-tuningします.
- Random Initialization + Fine-Tuning (woPre+FT): 言語情報から得られた知識が時系列予測に役立つのかを調べます. LLMをランダムに初期化してスクラッチで訓練します.
- Pretraining (Pre+woFT): fine-tuningの効果の有無を確認します. 言語モデルの素の能力で予測します.
- Random Initialization (woPre+woFT): ベースラインとして用います.
結果を見てみます.
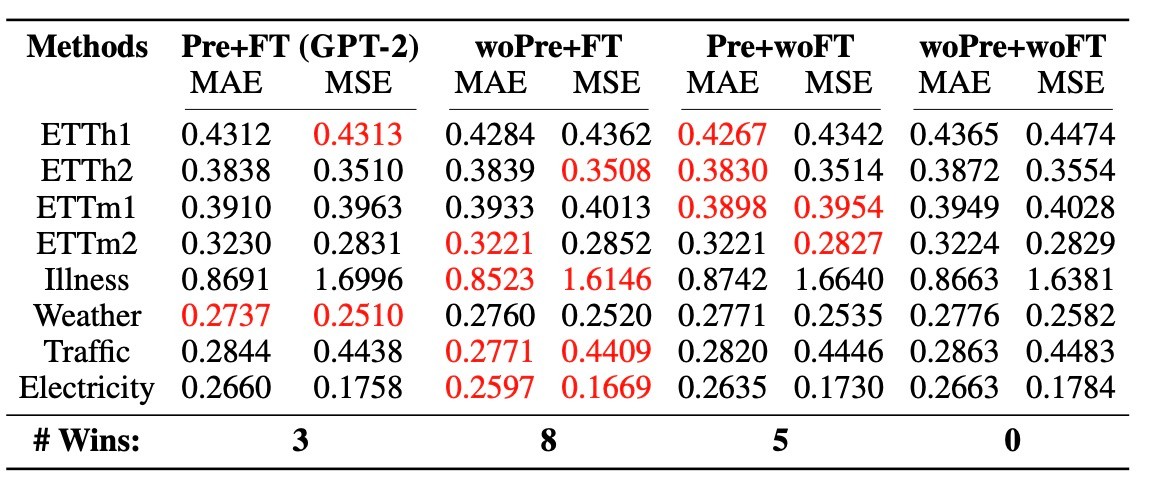
ここからも分かるように, 最も性能がいいものはwoPre+FTでした. この場合, LLMの言語知識は用いられていないので, 言語での事前学習の効果が限定的であることが窺えます. Pre+woFTとwoPre+woFTの結果を加えると, 言語知識がfine-tuningの段階で意味のある貢献を大してしていないことが示唆されます.
結論として, 「事前学習からの言語知識は時系列予測に対して非常に限られた意味しか持たない」ということになります.
LLMは時系列の順序依存性を表現するか?
これも結論を先に述べると 「表現しない」 です.
多くのLLMを用いた時系列予測では, 系列のタイムステップの位置を理解するためにPE (positional encoding)をfine-tuningします. 位置表現が優れたモデルであれば入力系列をシャッフルすると大幅に性能が低下することが期待できます. ここでは3種類のシャッフルを使って実験します.
- sf-all: 系列全体をランダムにシャッフルする
- sf-half: 系列の前半部分をランダムにシャッフルする
- ex-half: 系列の前半と後半を入れ替える
sf-allとex-halfは"Are Transformers Effective for Time Series Forecasting?"でも行われている実験です.
結果をみてみます.
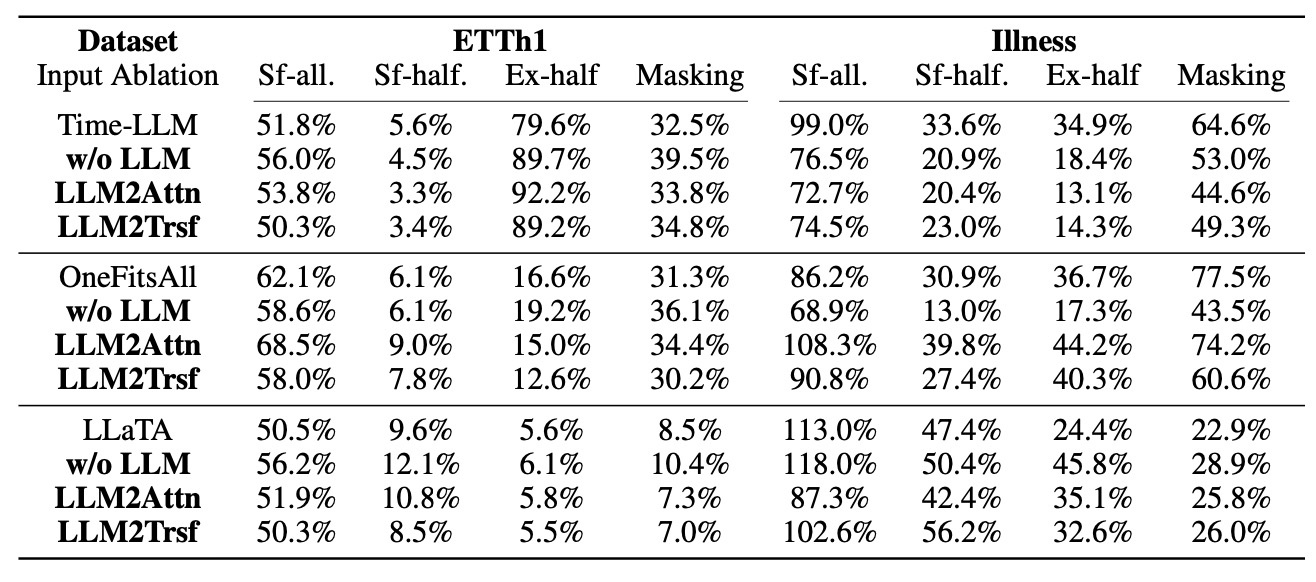
LLMとablation手法とを比較すると, 概ね同じ傾向が確認できます. これは, LLMが入力のシャッフルに対して堅牢であることを意味します. すなわち, LLMが時系列の順序依存性を表現するための能力を獲得していないことが示唆されます.
LLMはfew-shot learningに役立つか?
全て同じパターンなので結論が見えてしまっている気がしますが, これも先に結論を述べると 「役に立たない」 です.
これまでの結果から, 事前学習で重みの中にエンコードされた知識が役に立たないことは分かりましたが, few-shot learningの設定で性能向上に寄与する可能性は検証されていません. ここではそれを検証します. 各データセットの10%を用いて学習させます.
Time-LLMでの結果をみます.
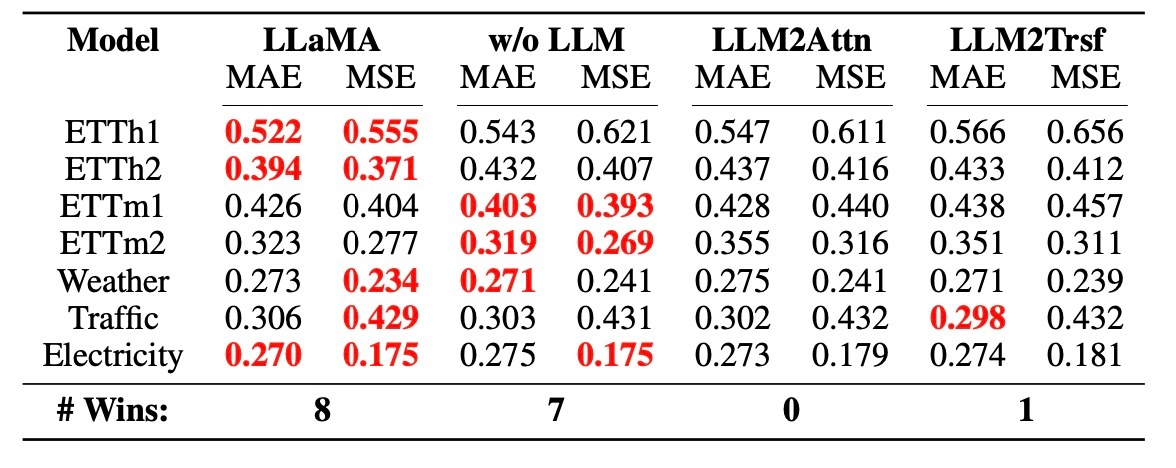
この表からLLMの有無ではfew-shot learningにおける性能は変わらないことが示されます. これはLLMの大きさによる可能性があるため, GPT-2を用いたLLaTAでも同様の実験を行います.
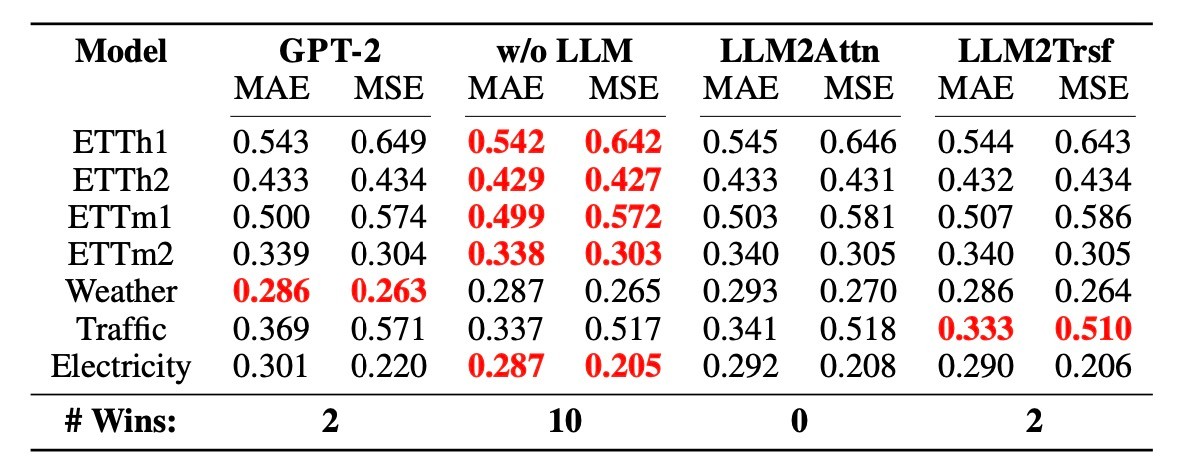
すると, LLaTAではLLMがないほうが優位であるという結果になりました. 個人的にはこの結果から, LLMの大きさによる性能の向上がfew-shot learningにおいて何かしらの影響を与えているように見えますが, そこに対する言及はありませんでした.
パフォーマンスの源はどこにあるか?
ここではLLMを用いた時系列モデルで使用されるPEを評価します. 結論を述べると, 「Patchingと1つのAttentionが最良」 です.
まず, これまでの実験からw/o LLM, LLM2Attn, LLM2Trsfのablationは性能を低下させないことを確認しました. これらは単純な手法ですが, なぜ機能するのかを探求します. LLM+時系列で使われるPatchingやPEなどを選び, 実験します.
小規模なデータセット (タイムスタンプが1M未満)では, PAttnという手法が他の手法より優れていて, かつLLM手法とも比較可能です. PAttnはPatchingとAttentionを組み合わせた以下のような構造で, 時系列にinstance normを適用してPatchingとprojectionを行い, 1層のattention layerを訓練するものです.
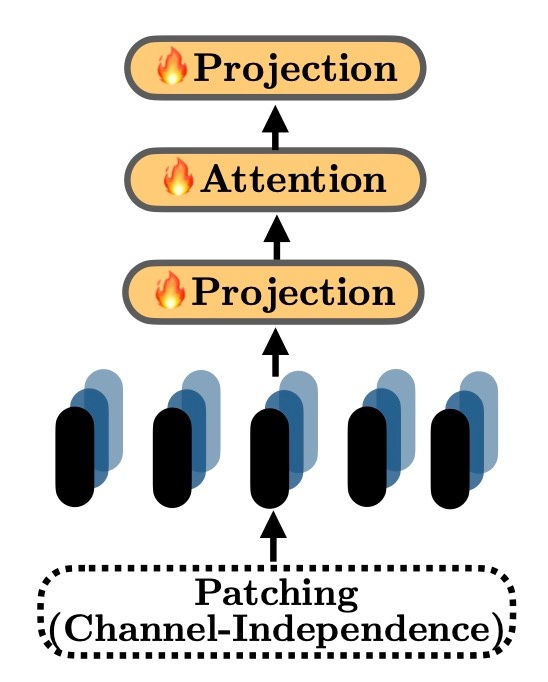
大規模なデータセット (Trafficは15M, Electricityは8Mです)では基本的なTransformerを持つモデルであるLTrsfが優れています. 上図のAttentionの部分がTransformerに置き換わったモデルです. これに対する考察などはありませんが, 違いを考えるとFFNなどが寄与しているのでしょうか.
全体として, Patchingは時系列エンコーディングにおいて重要な役割を担っていると言えます.
まとめ
- LLMを時系列予測に適用する既存の研究はコストパフォーマンスが悪い
- LLMが事前学習で獲得した知識もあまり活用できていない
- はるかにシンプルなモデルの方がいい. 大事なのはPatchingとAttention
Limitation
Appendixで著者らは2つのlimitationについて言及しています.
- LLMの時系列予測での評価をしただけで, LLMと時系列データの相性を確認するには他の下流タスクでの評価 (例えば時系列分類やQAタスク)も必要である.
- 評価が均一時系列に限定されている (タイムスタンプが一定間隔で記録されている). 例えば購買履歴のような時系列データは不均一なタイムスタンプを持っています. この点での評価も必要である.
思ったこと
- 最後のLTrsfが優れているのはHuggingFaceが以前出したYes, Transformers are Effective for Time Series Forecasting (+ Autoformer)と似ている話で, データ量の問題だと思います. 現実的にはデータ量がそこまであるのか不明なので多くのデータを必要とする現状の方針は微妙なのではと思います.
- 表データ同様, まだ深層学習で扱うことは難しそうです. 一方で時系列は基盤モデルが登場しているので単にLLMを使うことはナンセンスと考えることができますし, 個人的にもパラメータ数が大きいにも関わらずそれに見合った性能向上がないのでLLMを使うモチベーションがよくわからないというのが本音です.
- 今回はLLMが本当に必要なのかという趣旨の論文なので問題ないと思いますが, やはり時系列予測は決定木ベースのモデルや古典的モデルも比較対象に加えないとダメな気がします (深層学習のモデルだけで競ってもしょうがないです).
参考文献
- Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? Proceedings of the AAAI Conference on Artificial Intelligence, 37(9):11121–11128, Jun. 2023.
- Mingtian Tan, Mike A. Merrill, Vinayak Gupta, Tim Althoff, and Thomas Hartvigsen. Are language models actually useful for time series forecasting?, 2024.
- Yes, Transformers are Effective for Time Series Forecasting (+ Autoformer) (link: https://huggingface.co/blog/autoformer)
- 時系列予測にTransformerを使うのは有効か?(link: https://www.slideshare.net/ssuser369dbc/transformer-261229829)
Discussion