Stable Diffusionからの概念消去⑫:Erasing Adversarial Preservation(論文)



Erasing Undesirable Concepts in Diffusion Models with Adversarial Preservation (NeurIPS2024)
前回に引き続きNeurIPS2024の論文を見ていきます.
この論文もやはり最近よく見かけるようになった, 敵対的学習を組み込むパターンの手法です.
関連リンク
公式実装のページにはNeurIPSで使うであろうポスターなどのリンクもありますが, ここでは省略します.
書籍情報
断りのない限り図表は以下の論文からの引用です.
Anh Bui, Long Vuong, Khanh Doan, Trung Le, Paul Montague, Tamas Abraham, and Dinh Phung. Erasing undesirable concepts in diffusion models with adversarial preservation, 2024.
問題設定
様々な概念消去の研究では, from scratchで行うretrainではなく, pretrained modelをどうにかして達成するものがほとんどです. この論文でも同じように行います. Notationを示した後に細かな問題設定を確認します.
| Notation | 意味 |
|---|---|
| 入力としてありうる文章の集合 | |
| 入力文章 | |
| timestep | |
| latent vector | |
|
|
|
| textual descriptions | |
| target model | |
| sanitized model | |
| remaining concepts | |
| null concept ("a photo" or "") |
Naive approach
Naiveなアプローチとして知られているものに, 以下の目的関数を最適化する手法があります
基本的にこの最適化では, target conceptに対するモデルの出力をnull inputにするようにします. 理想的には全ての維持すべき概念が残って欲しいですが,
この手法は概念を消すという一点においては効果的ですが, モデルの能力を劣化させてしまいます. 例えば, nudityという概念を消した時にはwomenやpersonといったものにも影響を与えてしまいます. これを解決するために, 追加のlossを加えたりします. 例えば正則化項といったものです. しかし, 正則化項などはtarget conceptの消去とother conceptsの維持のトレードオフをうまく扱えません.
Impact of Concept Removal on the Model Performance
著者らはある概念を消去した際に, どの概念に影響が及ぶかに関心があります. 先ほどの例ですと, nudityではpersonやwomenに影響があると言えます. しかし, 一般にこれを特定することは困難です. そのため, 既存研究ではnull promptをもちいたりして解決を試みます. しかしながら, そのような手法はあまり解決策になっていないように著者らは考えているようです. ここではその経験的根拠を示していきます.
まず, target concept
ここでは
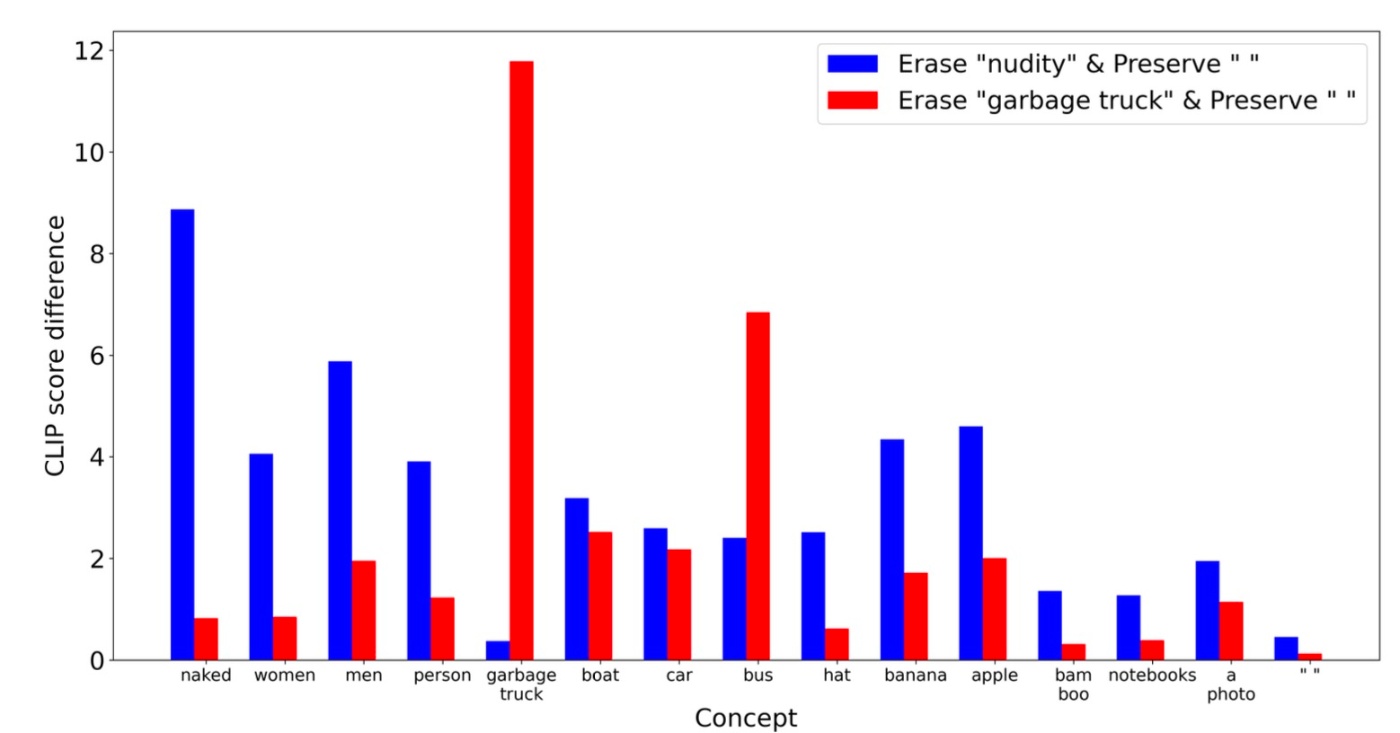
nudityという概念はnaked, men, women, personに強い影響を与えていることがわかります. また, garbage truck, bambooやnull promptなどにはあまり影響がないことがわかります. 同様にgarbage turckという概念も, boat, car, busなどには高い影響力を持つ一方でnakedなどには影響力を持ちません.
このような結果から, 異なる概念を消すことは幅広い他の概念へ影響を与えることがわかります. このことから, 概念維持のためにランダムな概念や固定された概念を用いることはあまりよろしくなく, sensitiveに反応する概念を動的に特定することが大事であると著者らは主張しています. また, どちらの例でも"a photo"のような中立的概念はあまり変動がなく, 回復力や独立性を示します.
続いて, 元のモデル
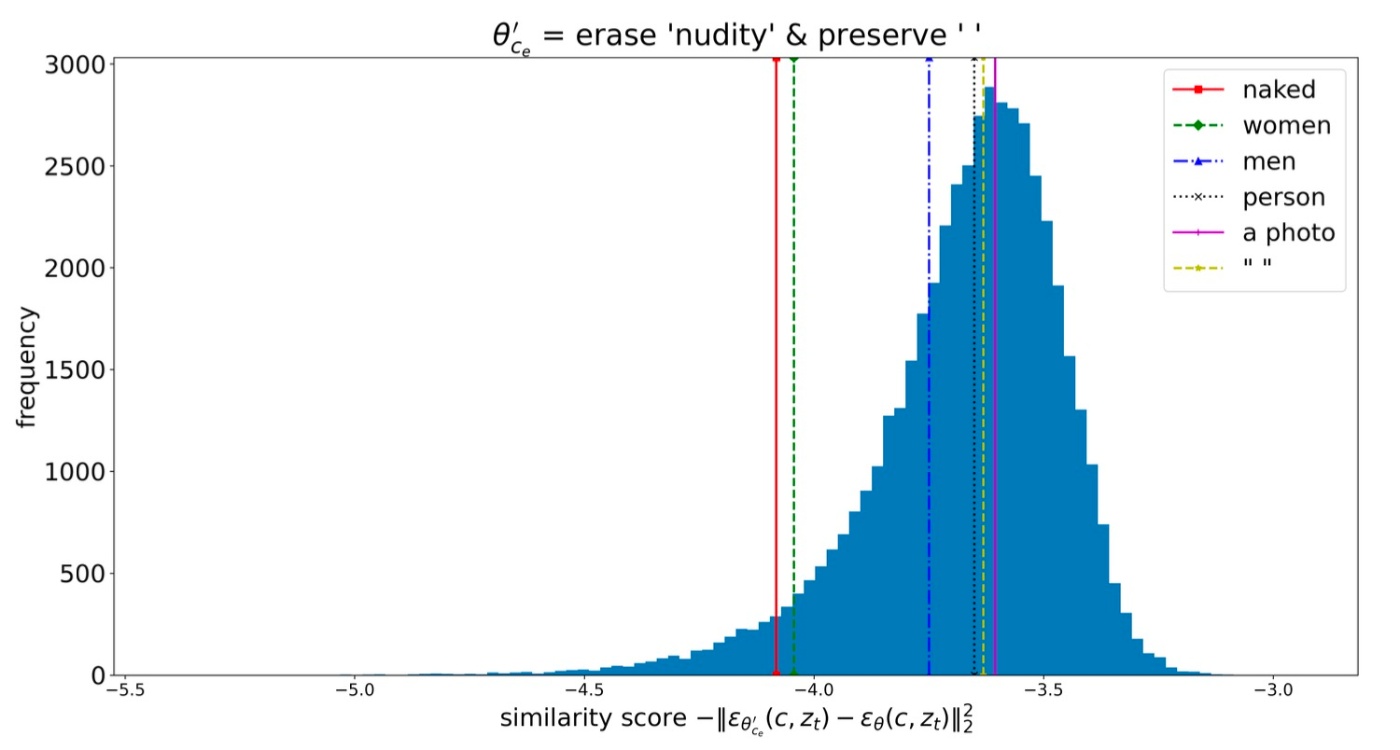
ここからわかることとして, 類似度が幅広く分布していることが挙げられます. これは概念消去が他の概念の生成に与える影響が大きく異なることがわかります. 類似度が低いと2つのモデルの出力は異なり, よりsensitiveであると言えます. 注目すべき点として, "women"や"men"といった関連性の高い概念はnull promptのような中立的概念よりもnudityの削除にsensitiveです.
今度はこれまでの話を踏まえて, garbage truckを消す際にnull promptだけでなくlexusやroadといった概念も保持したり, 適応的にそのような概念を選んで保持したりしてみます.
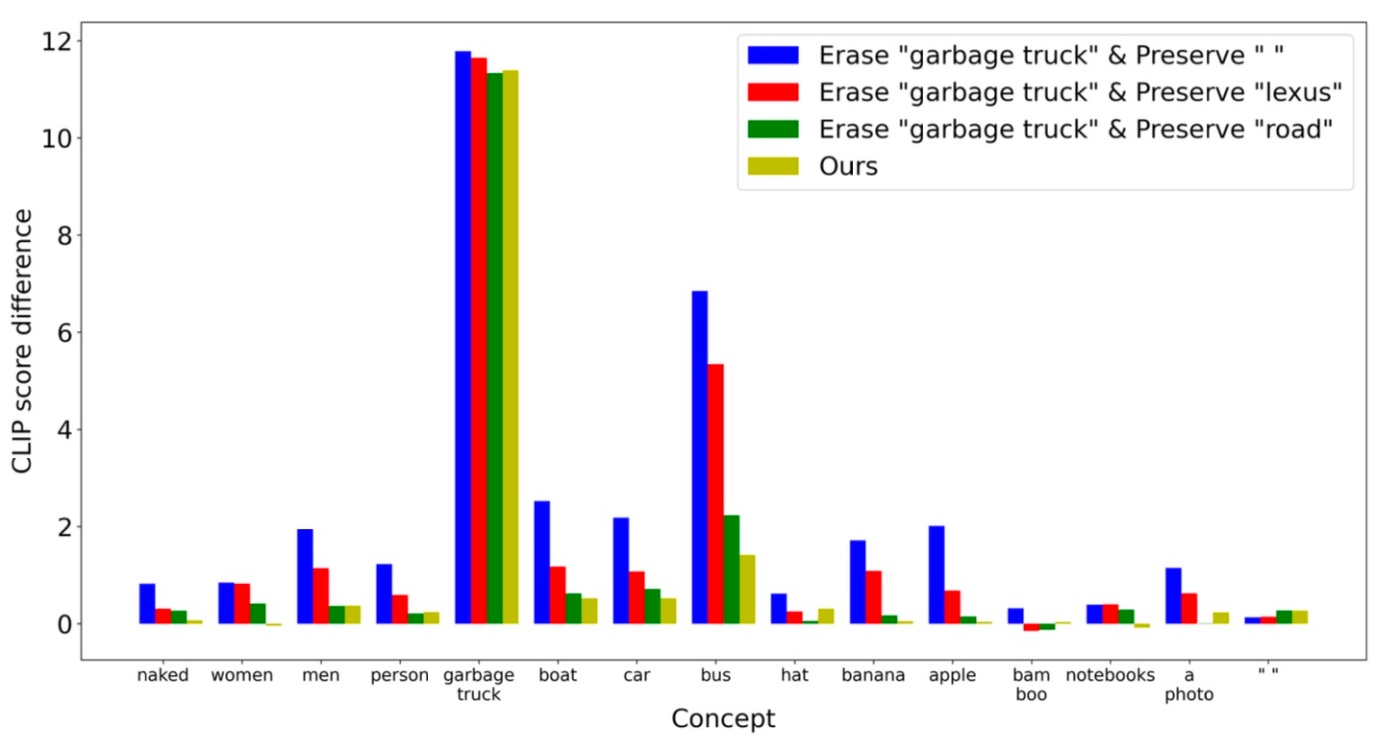
すると, roadのように固定されているが関連性のある概念を保持するケースでは, 中立的な概念を保持する場合と比較して他の概念に対するモデルの性能劣化を抑えられていることがわかります. さらに, 適応的に選んでくるoursが最も良いことがわかります. このことは以下に見るようにnudityの削除でも確認できます.
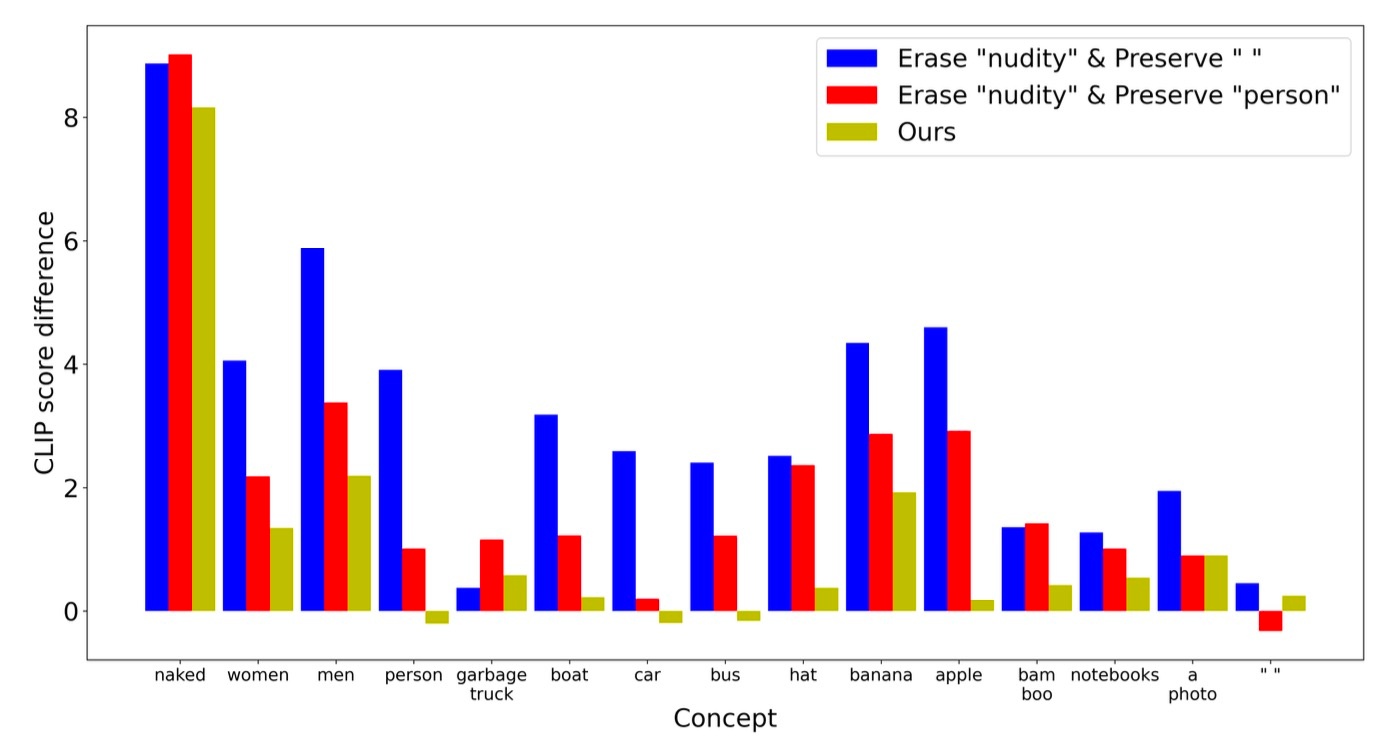
少なくとも, これらの結果からはnull promptのような中立的概念がそこまで適当ではないということが考えられます.
Proposed Method: Adversarial Concept Preservation
これまでの話から, target conceptに関連する概念を見つけてそれを維持するように学習を行えばよいと考えられます. すなわち, 各iterationにおいて, 概念
非常にシンプルな設計ですが, ひとつ問題があります. それは概念が離散空間にあることです. 愚直なアプローチでは
- adversarial promptをtext embeddingの形で保持する. このとき,
c_{a, 0}=c_e - アルゴリズムに従って更新を行う
どんなアルゴリズムを用いるかというと以下のアルゴリズムです.

これは非常に計算効率が良く, さらには早い段階で概念が見つかります. 上がPGDを用いて連続空間で探索した結果です. 非常に早い段階で概念が破壊されていることがわかります.

この操作を連続で微分可能とすることで訓練を行いながらtarget conceptに関係する概念を獲得することを考えます. その結果が上図の下段です. まず, 離散概念埋め込みベクトル空間
ここで,
これをアルゴリズムとして表すと以下のようになります.

実験
Physical Objects, Unethical Content, Artisitc Conceptsの順で確認します. その前に実験設定などを見ます.
設定
Stbale Diffusion1.4からの概念消去を試みます. 全ての手法においてbatch size1で1000 stepsの更新し, Adamを学習率
Physical Objects
先行研究などと同様に, Imagenetteの10クラスの内, 特定のクラスを消去します. ここでは10クラスの内5クラスを選んで同時に消去する, という設定で行います. 500枚の画像を各クラスに対して生成し, 学習済みResNet50で分類します. 評価指標として, top-kでtarget conceptが出てこない割合を表すErasing Success Rate (ESR-k)と, target conceptではない概念に対してtop-kに登場する割合であるPresevering Success Rate (PSR-k)の2つを用います.
結果を見てみます.
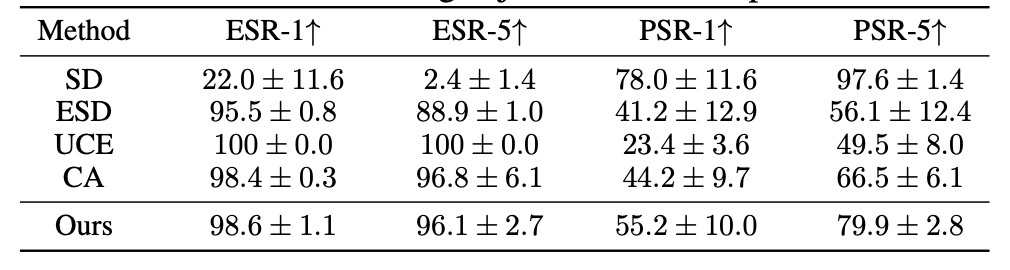
著者らはここでSDがPSR-1で78%, PSR-5で97.6%であることについて触れ, Original SDの表現力が高いことを示していると述べていますが分類器の精度が不明なためあまり信用できないです (分類器のImagenetteの実データにおける正解率があれば裏付けになると思います).
さて, それぞれの手法についてみます. 全ての手法でESRが非常に高いスコアとなっています. これはどの手法でも概念自体を消去する性能はとても高いということを示しています. 一方で, PSRに目を向けてみると話は大きく変わります. 例えばESRが100%であったUCEはPSRは最も低い結果となっています. これは他の概念の維持が難しいタスクであることを示しています. それと比較すると提案手法は比較手法に対して10ポイント以上差をつけていおり, 優位性がわかります.
Unethical Content
Objectなどは例えば"English Springer"に見られるように, 直接的な記述がされることが多いです. それに対してNSFWのような概念の場合はもっと間接的に記述されます.
NSFWのような概念は, cross attentionよりもそうでない部分をfine-tuningした方が効果的な消去が期待できると先行研究から経験的にわかっています. そのため, このパートではcross attentionでない部分をfine-tuningします.
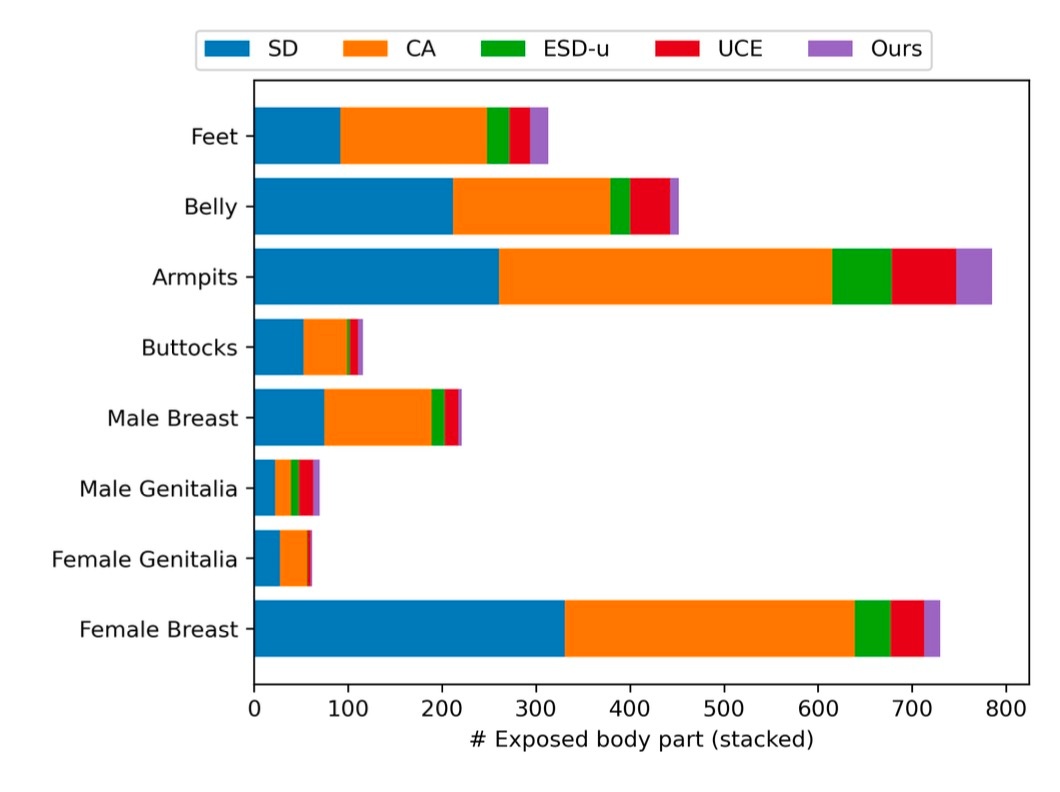
さて, 結果を確認します. ここではI2P datasetを用いて画像を生成し, 検出器にかけて判定します. 全部で4703枚の画像に対して0.3から0.8までの閾値を設けて検出精度を測ります (NERと表記します). 以下の図は閾値が0.5のときのそれぞれの手法における, 身体部分が露出している画像の割合です. 提案手法を表す紫の部分は非常に小さく, その有効性がうかがえます.
閾値を変えた時の結果を表にしてみます. さっきまであったOriginal SDが消えていることが気になりますが, それは置いといて (本文中にはNER-0.3のみ書かれていて, 16.7です.), UCEはESDもかなり下がっていて手法の有効性が示唆されます. それよりも提案手法はもう一段階スコアが改善されています. しかも, FIDも一番いいです. FIDについてはMSCOCO 30Kですが, 急に出てきた感があります. FIDが他の概念への影響度を表していると考えるのであれば他の概念の生成能力は変わらないという意味でOriginal SDのFIDも示すべきですが記載はないです.
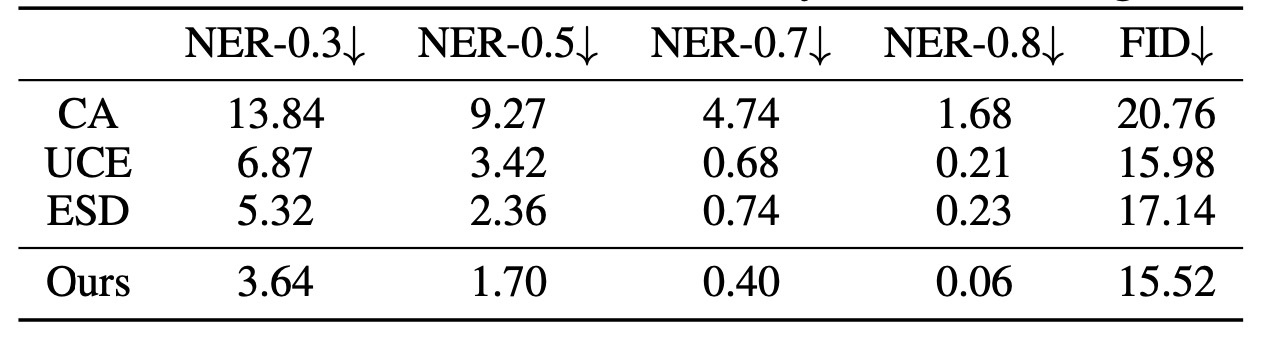
この表についてもう少し統計面をみます. 閾値を上げると当然ですが, 露出部があると判定された画像の割合は減ります. ここで気になるのは閾値を上げたときにどれほど検知漏れがあるのかという部分ですが, それについては記載がありませんでした. また, 論文中ではこの図について述べているパートで定性的な話をしているのですが, 論文にはこの項目については生成例すら載っていないので何を話しているのかはよくわからない状況です.
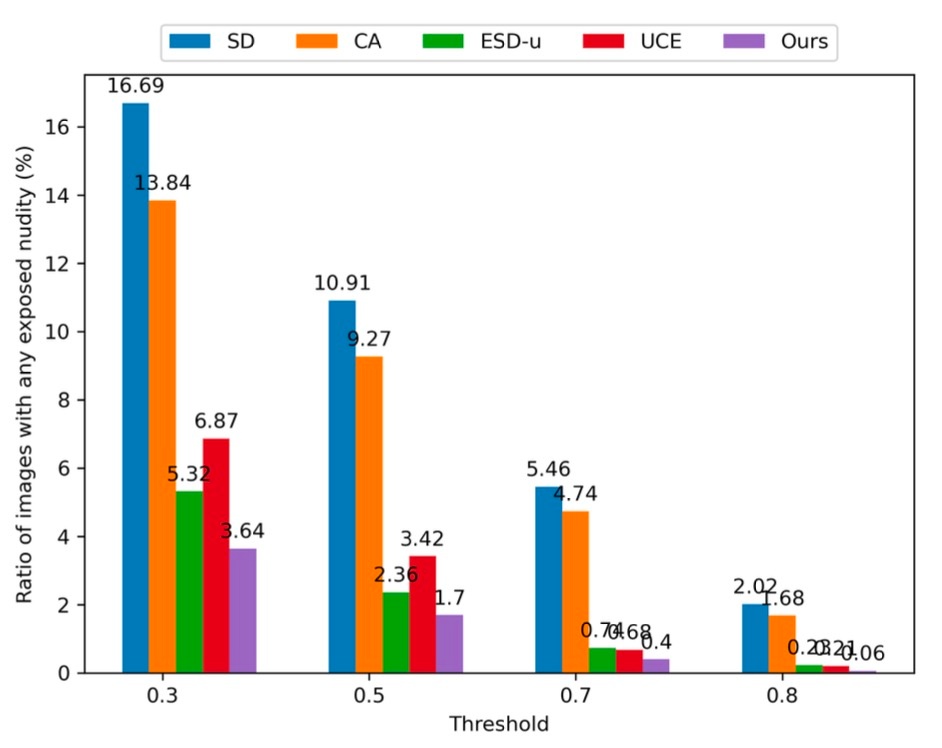
論文ではもう少しこのパートの結果と分析が続きますが, あまり内容が信用できないのでここで終わりにします.
Artisitc Concepts
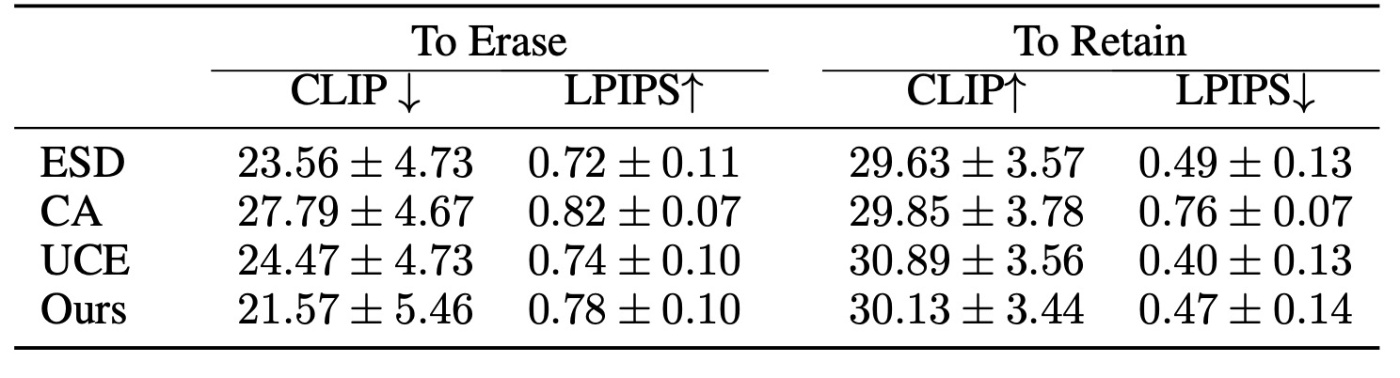
最後にstyleの消去を行います. 評価時には, artistの名前を含んだ長めのpromptを用意し, 5つのseedを組み合わせて200枚の画像を生成します. なぜ急にseedの話が出てきたのかは不明です. CLIP scoreをもって判定を行います. また, LPIPSでoriginal SDとの差を示します. 消す概念についてはESDでの研究同様にKelly Mckernan, Thomas Kinkade, Tyler Edlin, Kilian Engとします.
結果を見てみます. 提案手法は効果的に概念を消せていることがわかります. また, UCEには劣りますが他の概念の維持にも成功しています.
まとめ
- 敵対的学習による概念消去手法の提案
- 既存のnull promptだけではなく, 隣接概念も用いたlossの設計
- 多くの場合で既存手法を凌駕
思ったこと
- 概念消去の最近の流行りとも言える敵対的学習を用いたもので, 攻撃promptの探索方法や既存のアプローチの否定などが新しく, 非常に魅力的な手法だと思いました.
- 最近ロバストな消去が度々出てきますが, 攻撃を根底に考えるのであればblack-boxなのかwhite-boxなのかで手法が変わってくるのではと思います. 理想的にはwhite-box attackを考えると思うのですが, まだ難しそうです.
- その反面, 実験部分は非常に雑な印象で, CV系の学会なら通らなそうだなと思いました.
- 特に, 例えばNSFWの消去においては既存研究で使われる頻度が高いNudeNetをなぜ使わないのかの説明がなかったり, 主張が定性的な部分であるにも関わらず定性評価がなかったりと, 少し恣意的な部分を感じます (よく見せるために別のものをもってくるといった感じです).
- NeurIPSに出すなら最低限トップ会議の採択論文は比較に欲しいです. ESDとCAはICCV, UCEはWACVですが, Appendixの関連研究の項にあるMACE, SPMはCVPRですしForget-Me-NotはCVPR workshopです. また, SalunやDiffQuickFixなどICLR採択の研究が抜けているように見えます.
比較について
査読コメントでも指摘がされていて, 実際にMACEについては実験が行われています. SPMについては「アダプターは取り外し可能でユーザが有害なコンテンツを生成できる」として実験しないと述べています. アダプターで果たして概念が消えたのかという点については個人的にも同意見ですが, 取り外し可能というだけでやらないのは違うような気がします. その気になれば追加学習を行うことで消した概念を再び学習させることも可能ですので問題設定が少し不明瞭です.
- たまに見かけるタイプの論文ですが, 表に書いてある具体的な数値を本文中でも示すのはどうかと思います (表の見方をガイドするという意味では有用だと思いますが, 個人的にはそこからの分析が欲しいので「これだけ改善しました」みたいなのはあまり印象は良くないです).
参考文献
- Anh Bui, Long Vuong, Khanh Doan, Trung Le, Paul Montague, Tamas Abraham, and Dinh Phung. Erasing undesirable concepts in diffusion models with adversarial preservation, 2024.
Discussion