Stable Diffusionからの概念消去⑨:Receler (論文)



Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers (ECCV2024)
ECCVのaccepted papersが公開されています. ただし, paper IDのみなのでどの論文なのかは不明です. 今回は"concept erase eccv2024"とGoogle検索したときにヒットしたRecelerについて見てみます. ことわりのない限り図表は論文からの引用です.
書籍情報
Huang, C.-P., Chang, K.-P., Tsai, C.-T., Lai, Y.-H., Yang, F.-E., and Wang, Y.-C. F. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers, 2024.
関連リンク
ECCVはまだ開催されていないのでCVFには論文がないです.
TL;DR
- U-Netの0.37%のパラメータを更新する軽量な手法であるReliable Concept Erasing via Lightweight Erasers (Receler)の提案
- LocalityとRobustnessな手法で言い換えにも対応
信頼できる消去とは?
論文のタイトルにある"Reliable Concept Erasing"とはいったいどのようなことを指しているのでしょうか. この論文では局所性と頑健性であると述べられています. 局所性とは, 消す対象概念以外の概念について汎化性能を維持することです. unrelated conceptの生成性能といえます. 頑健性とは, 対象概念を消すことは前提で, 言い換えによって消したはずの概念を出さないようにするというものです. 例えばcarを消したモデルに対してjeepと入力して車が生成されたらcarを消したことにはなっていません. この部分の議論はNLPでは複数の研究がありますが, それらの手法をそのままtext-to-imageには持ち込めないようです. ちなみに, それを検証した論文は私が知る限りはないです.
既存の研究では, この2つの特性について特別な設計がされていないと述べられています. 例えば, Ablating ConceptやESDはU-Netをfine-tuningします. これはモデル本来の能力を損ないます (ここでの「能力」とは何を指しているのかはよくわかりません). UCEやFMN (Forget-Me-Not)はcross attentionの重みを閉形式で更新しますが, 言い換えには脆弱です. これはテキストの分離しか考えていないためです (これは根拠がないです. 生成例を示すだけで根拠として主張できると思いますが, それすらされていません).
ということで, これまでも, これからも2つの特性を同時に満たす手法が求められています.
手法
局所性と頑健性の2つの特性を兼ね備えた手法としてRecelerが提案されています. 手法の概要は以下の図の通りです.
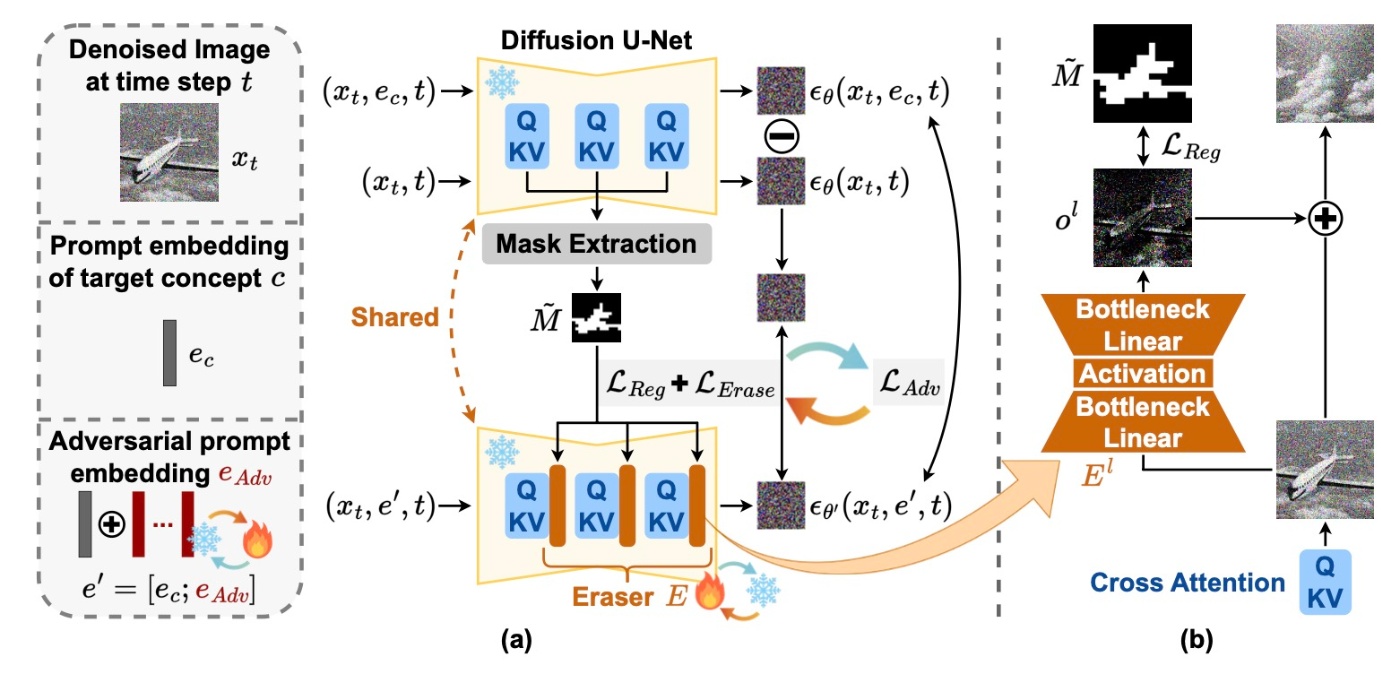
ここで重要なモジュールはEraser
Concept Erasing with Lightweight Eraser
これはEraser
です.
Concept-Localized Regularization for Erasing Locality
局所性はどのように獲得するかをここでは紹介しています. この論文では対象概念のテキストトークンに結びついた空間情報を利用します. これを用いてeraserを正則化することで局所性を獲得します.
まず, モデルの予測から得られるattention mapを閾値でバイナリにしたmask
ここで,
この正則化によって, 対象概念以外のものは維持されるよう強制されるようです.
Adversarial Prompt Learning for Erasing Robustness
さて, 頑健性はどのようにして手に入れるのでしょうか. いわゆる言い換えは, prompting attackと見なすことができます. なので, adversarial learningを導入します. 学習されたpromptが悪意のあるpromptを模倣するように促すことで, 連続的なsoft prompt
ここで,
実験
ベースラインはESD, SLD, Ablating Concept, FMN, UCEです. ベースとなるモデルはStable Diffusion1.4で, 生成時はDDIM Samplerを50stepsの設定で用います. guidance scaleは7.5を利用し, 512の解像度で生成します.
データセットとしてCIFAR-10とI2P datasetを用います. ObjectとInappropriate Contentについて実験し, 評価指標は以下の通りです.
Object
- Efficacy (Acc
_E - Robustness (ACC
_R - Locality (ACC
_L
EfficacyとRobustnessは150枚, Localityは50枚を各クラスにつき生成します. Localityはparaphrased promptで生成を行います. GroundingDINOを用いて特定のクラスが生成画像に登場したかを判定します. 全体的なパフォーマンスとして,
Inappropriate Content
ESDでの研究事例に従って, nudityとそれ以外を消した2つのモデルを用意します. NudeNetとQ16を検出器として用います. 頑健性はI2Pで, 局所性はCOCO-30kで確認します.
定量結果
Object
結果を表に示します. この表から, 調和平均が他の手法に比べて大幅に高いことがわかります. これは局所性と頑健性を兼ね備えているといえます. なぜかSLDの結果がないのが気になります.

驚くべきこととして, ACC
Inappropriate Content
まずはI2P datasetでの結果を確認します.
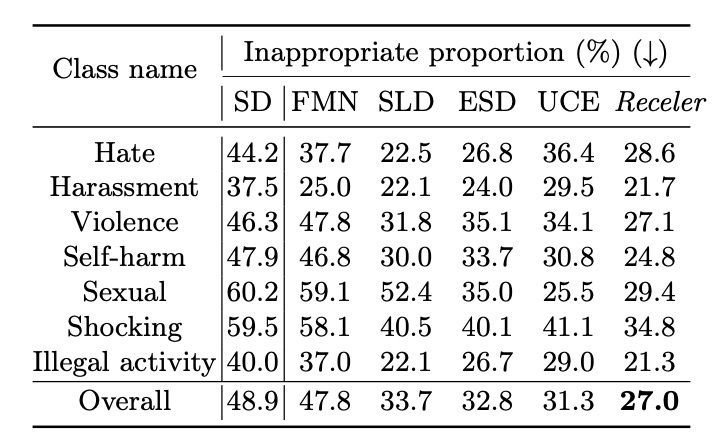
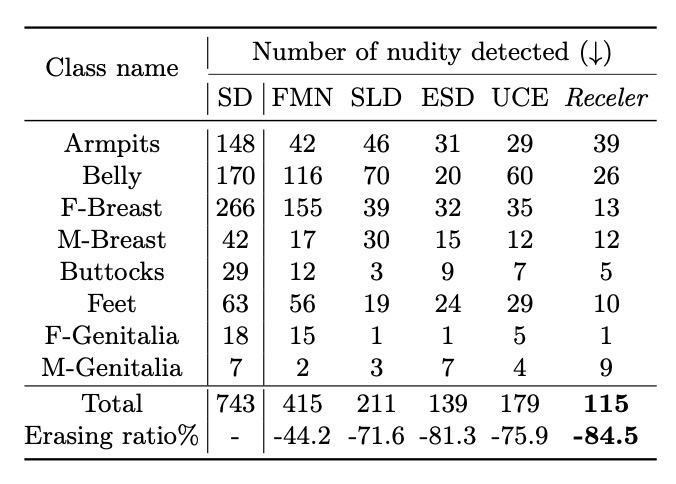
second-bestと比較するとどちらも数%の改善が見られます. 続いて, 頑健性と局所性を確認します. COCO-30kでの比較です.
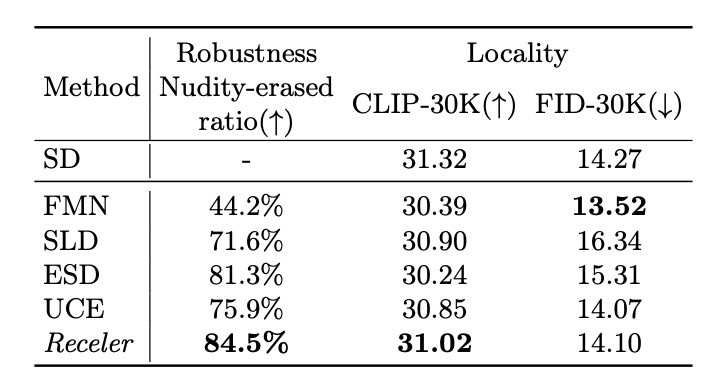
頑健性については非常に高いです. これは例えばoil paintingのようなpromptに対しても裸体が出ることが少ないといえます. 局所性についてはCLIP Scoreがベースラインの中では最も高く, text-image alignmentは維持できているといえます. しかし, FIDはFMNが最も良い結果です. これに対して論文ではFMNは頑健性の観点で非常に悪い結果ということで正当化をしています.
個人的に注目したいのはFIDのスコアです. 通常, モデルに対して何らかの変更を加えると, ベースモデルからの性能は低下します. そのことは冒頭でも挙げたとおりで, fine-tuningでの性能低下が確かにESDなどでは見られます. しかし, FMNやUCE, そして提案手法はStable Diffusionとの比較でFIDが改善していることがわかります. このことについてはもっと分析が欲しいです. 直感的には忘れさせることで生成画像の分布が近くなるとは考えにくいです.
Ablation
3つの要素がRecelerにはありました. そのablationを行います. eraserを導入すると, ACC

定性結果
実際の生成例を見て性能を確認します. Nudityの結果についてはここでは省略するのでそれを含めた結果は論文を参照してください (論文のFig. 3です).

ESDとUCEでは例えばautomobileやbirdなどの例で概念消去ができていないことがわかります. その一方でRecelerは背景などはそのままに目的の概念が消えていることがわかります. ちなみに, 思ったことでも触れるのですが, 定量評価での結果の性能差とこの生成例は乖離がありますので, cherry pickであると考えて良さそうです (そもそも1枚しか生成例がないので最初から信頼性は高くないと思います).
以下の図では, 局所性を確認しています. オレンジの枠は言い換えを行なって頑健性を確認しています (左の小さい文章が言い換えられたpromptです). 提案手法は言い換えに頑健である上に, 消した概念についてはOriginal SDと似た画像を生成しており, 非常に局所性に優れていると考えられます (これに関して私は以前の記事から疑義を抱いています).

論文中では他に複数概念の例もありますが, わざわざ取り上げるほどの結果でもないので省略します.
まとめ
- LocalityとRobustnessを確保した非常に軽量な手法であるRecelerの提案
- 他の手法より良い結果
思ったこと
読んでてネガティヴなことばかり思ってしまったので先にいい点を書いておきます.
- 既存研究だと多くの場合, 「消せればOK」のような感じです. 例えば言い換えには対応してないことが多いので, その点に目を向けているのは非常にいい着眼点だと思います.
- 実験でもCIFAR10の概念を利用しているのはいい点だと思います. これはCIFAR10に出てくるクラスは非常に登場頻度が高く, モデルが事前学習で遭遇する回数が高いので, モデルに深く根ざした概念と言えます. このような概念は消去することが難しいです. ただCIFAR10だけで行うならretrainとの比較が欲しいところです.
以下ではネガティヴなことを述べます.
- adapterを取り付けるのは本当に概念が消えたのかと自分はいつも思っています. これについてはよくわからないです.
- パラメータ数が非常に少ないのは分かったのですが, それと実行時間が対応するわけではありません. 実際に1つの概念にあたりどれくらいの時間がかかるかの比較が必要だと思います. 特に, Stable Diffusionはcomputational costが高いと言ってもそこまでではないです. 例えば自分が再現実験を行った例で言いますとU-Net全体をfine-tuningするESDは1時間ほどでできましたが, 逆にLoRAを用いたSPMは2.5時間かかりました. NVIDIAの論文なのでeDiff-Iでも実験があると嬉しいです.
- 定量評価を確認すると, automobileはACC
_E - Introductionで"Moreover, even though filtered image data can be collected, re-training generative models is still computationally expensive."と述べているのですが, re-trainingを行うと決してない概念についても生成例はOriginal SDと変わることが容易に考えられるので, やはりOriginal SDと似てるからOKみたいな話ではないと思います.
- これはこの論文に限った話ではないですが, Code is availableではない (公開されていない)ので事実と異なることは書かないで欲しいと思います.
参考文献
- Huang, C.-P., Chang, K.-P., Tsai, C.-T., Lai, Y.-H., Yang, F.-E., and Wang, Y.-C. F. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers, 2024.
Discussion