Stable Diffusionからの概念消去㉖: CURE(論文)
CURE: Concept Unlearning via Orthogonal Representation Editing in Diffusion Models (NeurIPS2025)
今年も早いもので, 残りのメジャー会議もNeurIPSくらいになりました. そこで採択された概念消去の論文を確認します.
書籍情報
断りのない限りは以下の論文から図表を引用しています.
Shristi Das Biswas, Arani Roy, and Kaushik Roy. Cure: Concept unlearning via orthogonal representation editing in diffusion models. arXiv preprint arXiv:2505.12677, 2025.
関連リンク
概要
CUREは閉形式で更新を行う手法で, 著者らによれば2秒でできるそうです. これ以上閉形式の手法が出てくるとは思ってもいませんでしたが, どこが新しいのか見ていきたいです. 著者らが主張する貢献は3つで
- 直行射影とスペクトル幾何を利用したSpectral Eraserを用いて消去を行う
- 古典的な正則化理論に基づく選択的特異値展開機構(selective singular-value Expansion Mechanism,)を新たに導入し, 概念消去とその他の概念保持を両立することに成功した
- 実験結果がとてもよかった
最後のはさておき, 手法の核となりそうなのは上2つです. それぞれ見ていきます.
準備
手法に立ち入る前に, 前提を確認します. 拡散モデルでテキストの情報を伝える際にはcross attentionが用いられます. 各トークン埋め込みを
です. 言うまでもないですが,
問題設定
論文では小難しく述べられていますが, 定式化を行います.
識別的部分空間の構築
を得ます. ややこしいですが, 論文では
characterized by the orthonormal basis vectors
for each embedding \mathcal{U}
と書かれており, 先ほど定義した集合とは異なる
このことから,
続いて, 任意の埋め込み
このことへの対処として著者らは, 基底ベクトルの相対的な重要性に基づいて重みづけを行うエネルギースケーリング機構を組み込んだ, 射影演算子を提案しています. 具体的には, 埋め込みの共分散構造を
と書けます.
スペクトル拡張機構
先程の話には1つの課題があります. 共分散行列の対角構造は各成分にわたるエネルギー分布
と定義されます.
最終的には
となります. ここで,
閉形式によるスペクトル消去
これによる更新は埋め込み
消去演算子の重み空間への吸収
推論中に,
ここまでの流れを図にすると以下のようになります.
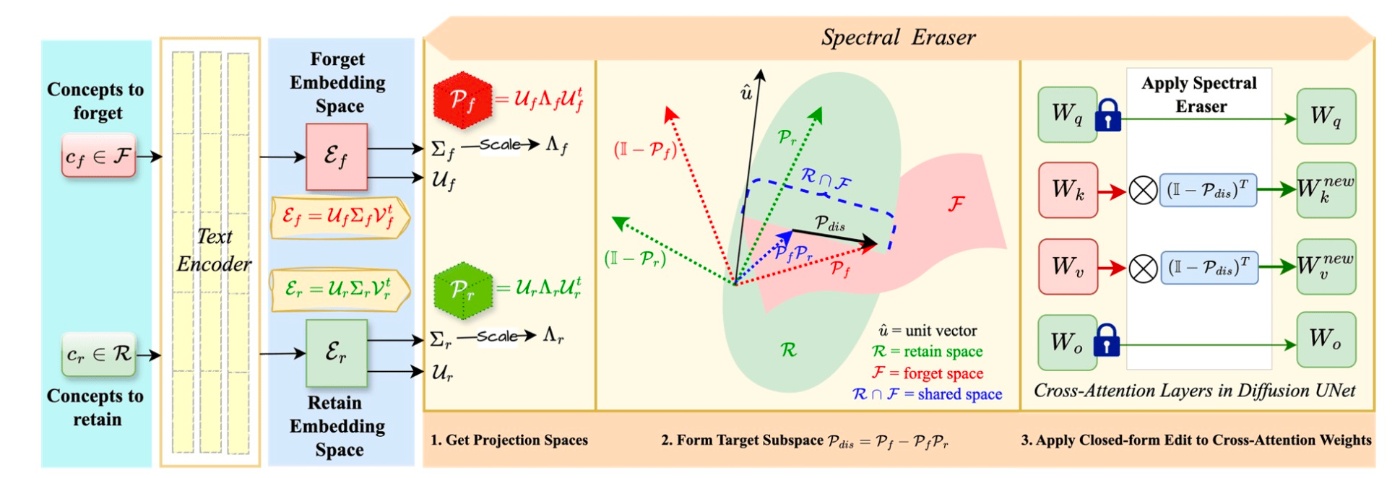
実験
いつものように, 設定を確認してから結果を確認します. 多くの既存研究と同様に, style, object, identity (celebrity), unsafe contents (NSFW), および堅牢性についてを確認します. ベースモデルはStable Diffusion 1.4です. ハイパーパラメータである
styleの消去
先行研究でも用いられている代表的なstyleを10個選んで実験します. 1つの概念につき20個のプロンプトを用意します. 定量評価としてVan GoghとKelly McKernanについて結果を示します. 評価指標として
結果を確認します.

著者らの主張によれば, 他の概念への影響を最小限に抑えつつ, 消去性能はベースラインを上回るとのことです. 本当にそうでしょうか...と言いたくなる結果ですが, 下図(a)を見ても, 確かに他の概念への影響は少なく, かつ消去性能はいいように見えます.

また, 上図(b)からは堅牢性も確認できます.
NSFWの消去
例によって, I2P datasetでの実験です. ここでもNudityの消去のみを行なっています. 検出はNudeNetです.
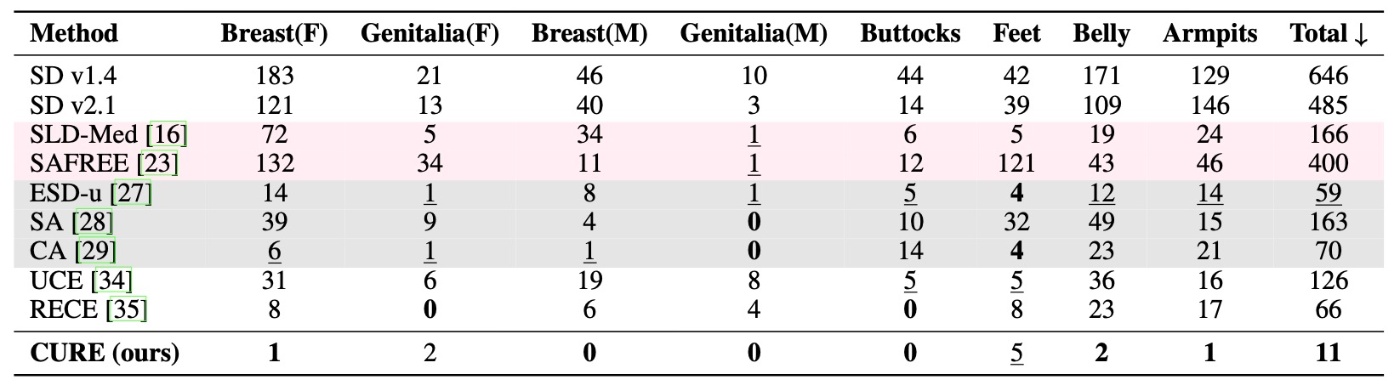
結果を見るとわかりますが, ほぼ消去に成功していそうな雰囲気です. 著者らは,
While methods like [27, 29] also reduce nudity, they incur overheads from fine-tuning all U-Net weights and still exhibit poor FID scores.
と述べていますが, 少なくともこれを裏付ける実験結果は示されていません. CAでは3種類のtuning手法が提案されていますし, この論文ではESDとESD-uは表記上は使い分けられており, ならば前者はESD-x (cross attentionのみを更新)と解するのが自然だからです. また, この部分が正しく表記されていたとしても, U-Net全体の更新によるオーバーヘッドが大きいこと結果とはあまり関係がないです (すくなくとも論文からはそう言えると思います).
また, いつものようにさまざまな攻撃手法に対しても実験を行なっています.
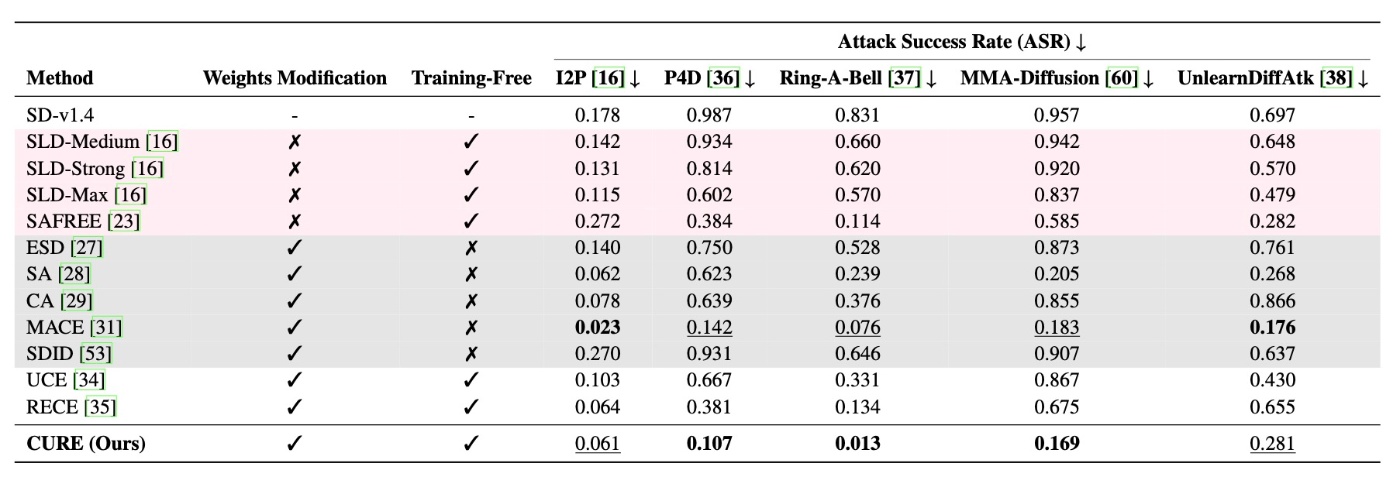
かなり低いASRです. 著者らはcaptioningで
Robustness of all methods against red-teaming tools, measured by Attack Success Rate (%).
としていますが, UnlearnDiffAtkの結果を見るに
%ではないです. %にするにはこれを100倍する必要があるように思えます. そうでなければあらゆる消去手法が1%未満のASRとなってしまいます.
objectの消去
こちらもお馴染みとなっているImagenetteを使用します. 500枚の画像を生成してResNet-50で分類します. 結果を見てみます.

結果を見るとそれなりによさそうです. 個人的には概念消去には順序があって
- target conceptを消すことができる
- target conceptが消せている状態で他の概念に影響がない
なので, この結果で優位性を主張するには無理があるのかなと思います.
Identityの消去
いわゆるcelebrityの消去にあたります. GIPHY Celebrity Detectorでのtop-1 accuracyで評価します, と論文では述べられていますが, 定量評価は見当たりません. 追加結果はAppendixとも述べられていますが, そこにも定量評価の結果は見当たりません. そのかわりと言ってはなんですが, 定性結果を見ておきます.

ここではJohn Wayneを消した時の結果が示されています. 著者らはJohn Wayneを消した際に, 他の手法ではfirst nameが一致するJohn Lennonの維持が難しいとしています. 確かに提案手法ではその区別がされてJohn Lennonは維持されてJohn Wayneは消えているように見えます. ただ, この現象自体は比較対象にもあるMACEの論文で既に触れられている話題であり, 特段新規性があるようには見えません.
消去効率
最後に消去効率を見ておきましょう. 実際のユースケースにおいてはたくさんの概念を消去したいため, 1概念あたりに要するコストは小さい方がいいです.

A40 GPU上での結果を確認すると, 結構高速に動作することがわかります. ただ, UCEはそれよりさらに速いですし, objectにおける他の概念の維持など提案手法に優っている部分もあり, 必ずしも提案手法が優れているとは言えなさそうです.
思ったこと
- 査読結果を見られていないのでコメントに困るところですが, 個人的にはNeurIPSなのかな..という気持ちです. 確かに提案手法はこれまでの閉形式の手法に手を加えたもので新規性があり, 性能面でもcompetitiveくらいにはなっています. 一方で, その手を加えた部分に見合った結果が出ているのかというと微妙なのではないかと思っています. Ablationで示せるとよさそうです (ablationは論文にはありませんでした).
- それに関連して, 比較対象があまり新しくないことが気になります. 既にESDやSLDは拡散モデルの概念消去において初期の研究ですから, 生成タスクに例えればDDPMやLDMとメインで比較しているような印象です. もちろん出発点に近い研究なので評価の表に載せるのは問題ないと思いますが, 参考程度の話ではないかと思います. 必ずしも最新の研究と比較する必要はないと思いますが, その選定理由 (特にrelated worksで引用した研究を選ばなかった理由)くらいは欲しいですね.
参考文献
- Lu, S., Wang, Z., Li, L., Liu, Y., and Kong, A. W.-K. Mace: Mass concept erasure in diffusion models. In Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6430–6440, June 2024.
- Shristi Das Biswas, Arani Roy, and Kaushik Roy. Cure: Concept unlearning via orthogonal representation editing in diffusion models. arXiv preprint arXiv:2505.12677, 2025.
Discussion