Llamaで画像生成:LlamaGen【論文】
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
関連リンク
はじめに
画像生成モデルはここ2年ちょっとは拡散モデルが主流です. それまではGANが主流だと思いますが, GANは2つのモデルを同時に学習するという大きな枠組みがあり[1], 学習が不安定であることが知られています. 一方拡散モデルはDDPMの論文以降, 損失関数関数が二乗誤差で非常にシンプルなことから学習が安定することが言われています. その他の生成手法はないのかと言われるとそのようなことは全くなく, VAEであったりflowといったアプローチもあります.
別の分野に目を向けると大規模言語モデル (LLM)は非常に高性能な生成を行えることが知られています. LLMはTransformerを用いた自己回帰モデルですが, 自己回帰で画像生成を行うことも当然検討されています[2].
特にことわりのない限りは図表は全て論文からの引用となります.
手法の概要
まず, 画像のピクセル
を \boldsymbol{x}\in\mathbb{R}^{H\times W\times 3} の離散トークンに量子化する. ここで, q\in\mathbb{Q}^{h\times w} をimage tokenizerのdownsample ratioとしたときに p である. h=H/p, w=W/p はimage codebookの添字である. これを q^{(i, j)} の長さのトークンの系列にreshapeしてTransformerに与える. h\cdot w
生成時はimage tokenをnext token predictionによって生成し, image tokenizerのdecoderによってピクセルに戻す. (q_1, q_2, \ldots, q_{h\cdot w})
と論文には書かれています. 自己回帰による画像生成の基本的なアプローチであると思います. 大まかに言うと, 画像をトークン化してそれを系列に並べてモデリングを行います. 生成時は系列を順番に予測し, トークンが手に入ったらそれをdetokenizeして画像に変換します.
Image Tokenizer
はじめに, 一般論としてのImage Tokenizerの話をします. これはPartiというGoogleが2022年に発表した自己回帰画像生成モデルの論文に書かれている内容を一部改変したものです.
自己回帰画像生成モデルでは, その都合から2次元である画像を1次元の列表現にする必要があります. 最も単純な考え方はピクセルひとつひとつを構成要素とし, それを並べることです. すぐにわかることではありますが, 非常に長い系列になってしまいます. 例えば小さめの画像として256ピクセルのものを考えてみても,
系列長になってしまいます. そこで, 離散的なcodeに画像情報を圧縮する方法としてVQVAEやVQGANといったものがあります. これらのcodeをimage tokenとして系列モデリングを行います. 256\times 256\times 3=196608
次に, アーキテクチャの話に移ります. ここからが論文の内容です.
ここではVQGANと同じアーキテクチャを採用します.
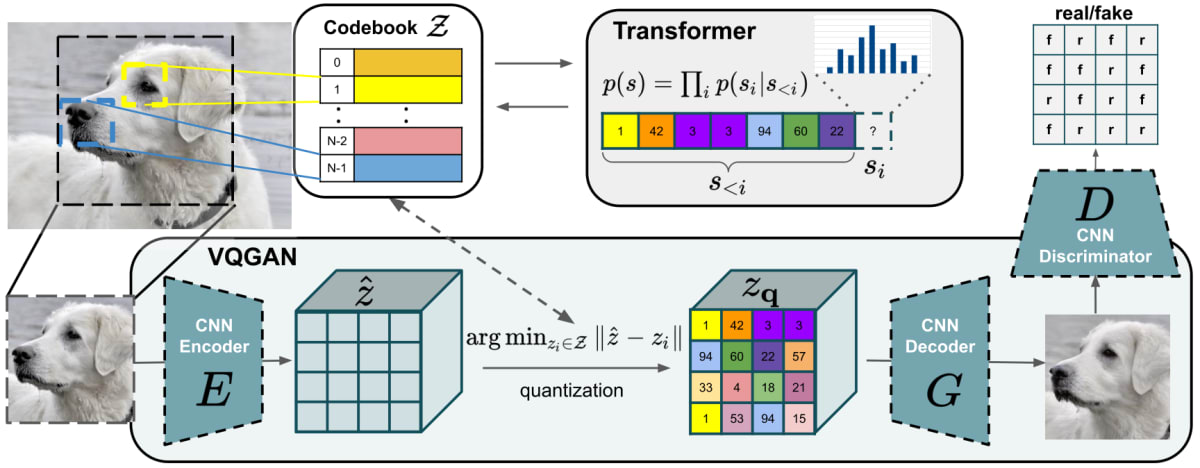
これはencoder-quantizer-decoderでencoderとdecoderはdownsample ration
codebookがtokenizationの品質に直結する要素ですが, VQGANの品質向上手法に倣って
Training losses
量子化は微分可能でない操作なのでgradient setimatorを用い,
画像再構成では
Image Generation by Autoregressive Models
大部分はLlamaのアーキテクチャを採用し, 事前正規化にはRMSNormを用い, SwiGLU活性化関数, rotary positional enmebdding (RoPE)を用います. 2DRoPEは各層で使用します. AdaLNなどのテクニックはLLMの構造を維持するためにも使用しないようです.
クラス指定生成では, class indexは学習可能なembeddingを用い, text-to-imageではFLAN-T5 XLをtext encoderとして使用します. テキスト特徴量は追加のMLPによってさらに変換され, prefilling token embeddingとして使われます. 著者らによると, この設計は最適ではないことに注意が必要です.
拡散モデルではclassifier-free guidanceによってtext-image alingmentを確保しています. ここでもそれを採用します. 訓練中は条件付けをランダムにdropしてunconditional embeddingsに置き換えます. 実験では10%を置き換えているようです. 推論時は各トークンに
全ての設計の選択は既存研究に大きく影響を受けていて, それらの組み合わせが本研究となっています. これは私の感想ではなく著者らがそう述べています.
It is worth noting that all design choices discussed so far are largely inspired by previous works, for example, image tokenizer is borrowed from [Rombach et al. 2022; Yu et al. 2021], image generation is from [Peebles & Xie 2023; Chen et al. 2023b; Esser et al. 2021]. A large portion of these techniques are well studied in diffusion models but little in AR models. Our work adapts these advanced designs collectively to AR-based visual generation models.
Scale Up
Llamaと同じアーキテクチャなので, LLMコミュニティで研究・開発されているものと同じ最適化手法, 訓練戦略が使えます. 下の表に3.1Bモデルまでのスケーリングを示します. 全てのモデルはPyTorch2で実装され, 80GBのA100GPUで学習されます. 1.4B以下のモデルはDDPを使い, それ以外はFSDPを用いてメモリを効率的に使用します.
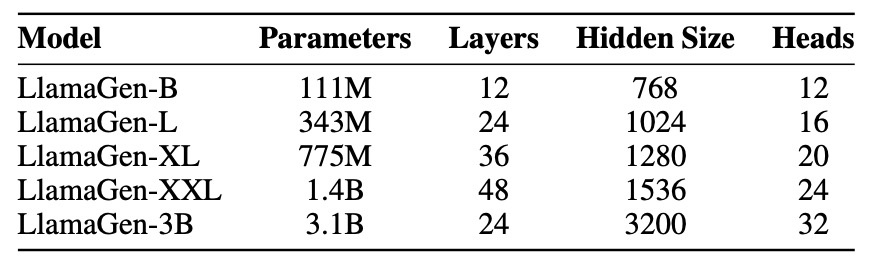
論文では実験コストなどは述べられていませんが, 公式実装のissueで述べられており, 最も大きいモデルは32 A100 GPUsで5日です. tokenizerには8 A100 GPUsで2日と述べられているので全体で1週間で訓練できるようです.
Serving
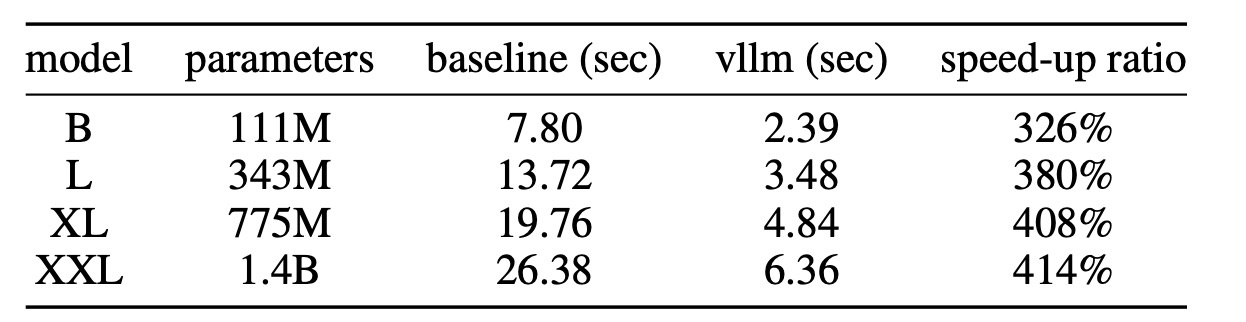
自己回帰モデルはいつも推論速度の遅さに苦しみます. LLMコミュニティの貢献はここでも用いることが可能になっていて, vLLMの技術を使うと326%~414%高速になります. 詳細は実験の最後に触れます.
Experiments
Image Tokenizer
ImageNetのtraining setで訓練を行います. データ拡張としてrandom cropを用い, 解像度は256です. tokenizerのサイズは72Mと70Mで, downsample ratioはそれぞれ16と8を使用します. 全てのモデルが同じ設定で訓練されていて, 学習率は
ImageNet 50kのvalidation setで再構成の品質をr-FID (reconstruction FID)で測定します. それとは別に, 追加でPSNRとSSIMが報告されています. usageはcodebook usageのことで, queueのサイズである65536のどれくらいを用いたかです.
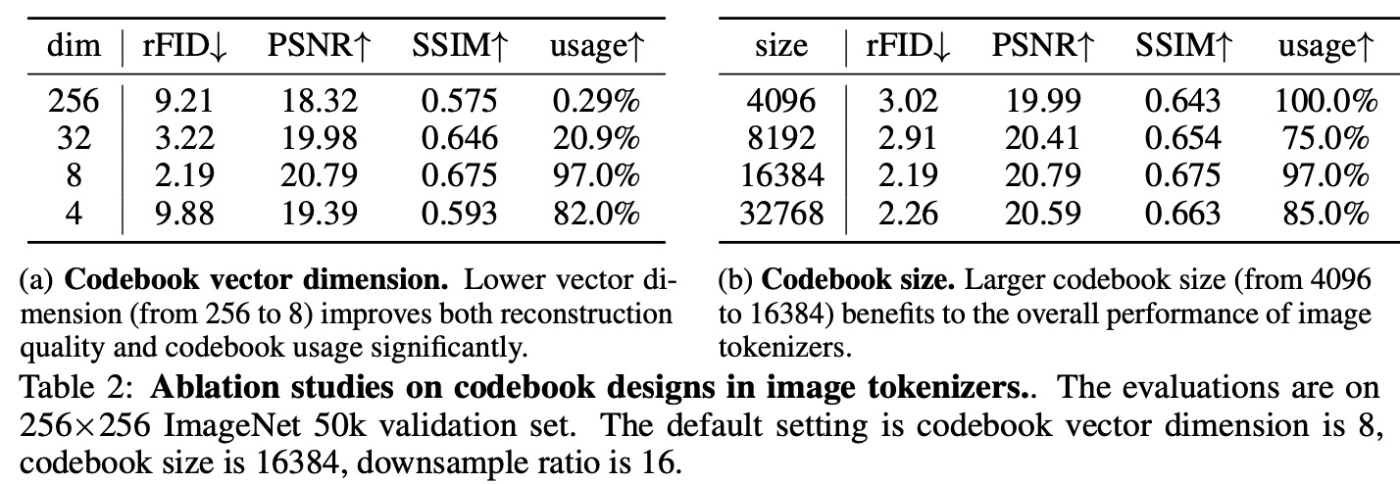
Effect of image codebook desings
codebookのベクトル次元を256, 32, 8と減らすとrFID含めた指標が向上します. codebook sizeは4096から16384までサイズを増やすと性能が上がります. これは既存研究でもみられた結果です.
Effect of number of tokens to represent the image
tokenのサイズを大きくするとどうなるのかを実験します. 例えば, ratioが16の場合では 256 tokenの場合のみ性能が悪いことがわかります. だから何が言いたいんだと思う人もいるとは思いますが, 特にこれといった考察は行われていません.

Comparisons with other image tokenizers
VQGAN, MaskGIT, ViT-VQGANと比較を行います. 提案手法は他の手法と比較しても優れた性能をしていて, それはImageNetより難しいデータセットであるCOCOでも同様です. 今回の実験ではImageNet training setで訓練してCOCOで評価しており, object-centricとscene-centricの画像の両方において汎化性能を獲得していると言えます. さらに重要な点として, 連続値で特徴空間を持つモデルとも競合する性能であることが挙げられます. OAIはOpenAIのConsistency decoderで, dalle-3でも使われているものです. 論文等は出ていませんが, モデルは公開されています.
総評として離散表現は画像再構成においてはもはやボトルネックにはならないと言うことができます.

Class Conditional Image Generation
ImageNetで訓練します. 先ほどと同様に全て同じ実験設定で行います...と言いたいですが若干異なるようです (similar setting). ただ, 論文ないでは細かく書かれていません. batch sizeは256で学習率は
FIDとISとsFID, Precision/Recallを用いて評価しますが主に使う指標はFIDとISとsFIDです.
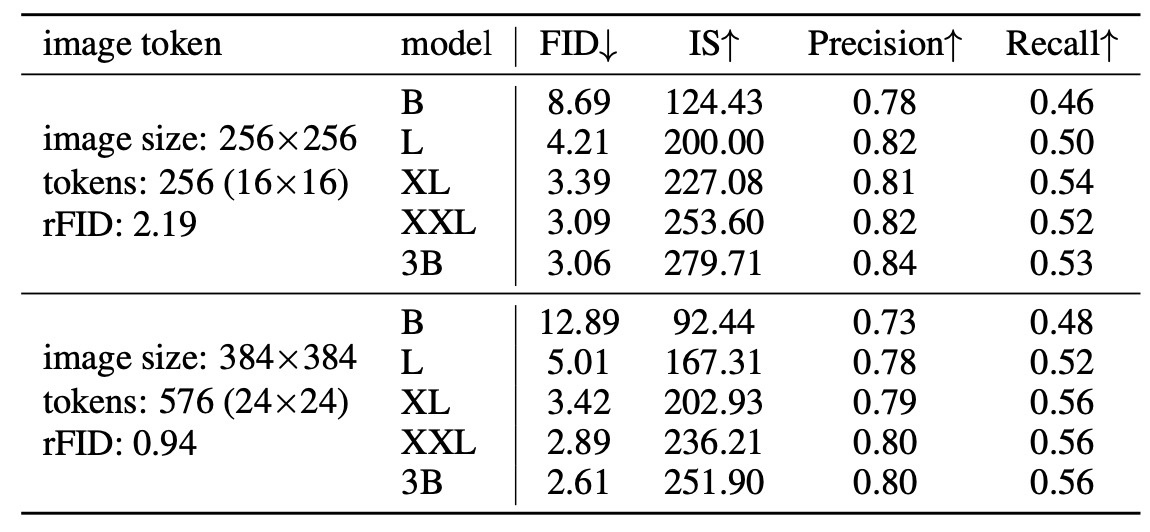
Effect of image tokens
tokenizerの性能は再構成の性能に直結しますが画像生成の品質には強い相関はありません. 例えば1Bモデルを比較すると, FIDはrFIDが高いtokenizerの方が低くなっています. とはいえ, image tokenが少ないとモデルパフォーマンスの改善は頭打ちになります. 最高性能である3Bモデルを比較するとFIDは3.06と2.61で最終的にはさらに性能改善が見込めます.
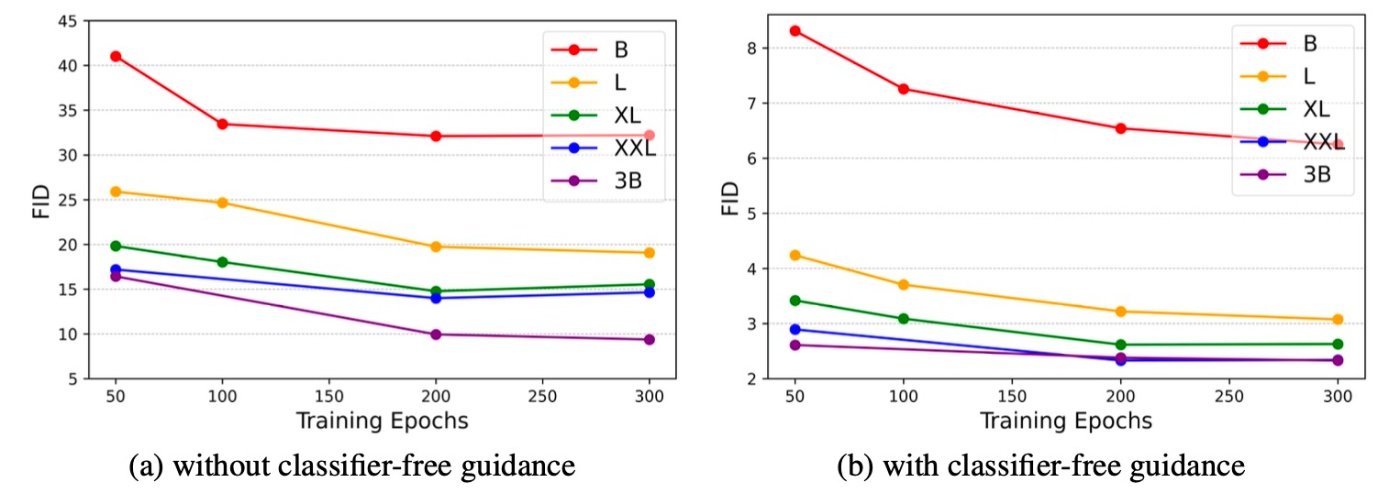
Effect of model size and classifier-free guidance
B, L, XL, XXXL, 3Bの5つのモデルを訓練させてclassifier-free guidanceの有無による性能比較も行います. Training epochごとのモデルの性能を表したのが下図です. 3B以外のモデルはclassifier-free quidanceありの場合にFIDが大きく改善していることがわかります. しかし, 3Bモデルは対して性能改善が見られません. このことについて著者らはImageNetのサイズがパラメータ数に対して小さくなってしまったと推測しています. さらに大きいデータセットを用いるか, データ拡張を行うことで性能改善できると考察されています. また, classifier-free guidanceの有無では, classifier-free guidanceありの方がFIDが大きく改善されていることがわかります.
Effect of sampling configuration
左下図ではclassifier-free guidanceが2.0のときにFIDが最低スコアとなっています. さらに増やすとFIDは悪化します. これはclassifier-free guidanceの提案論文と同じ現象です. また, classifier-free guidanceの増加はprecisionの上昇とrecallの減少によって, 多様性と忠実性のトレードオフが見られます. これもclassifier-free guidanceの一般的な話として知られていることです.
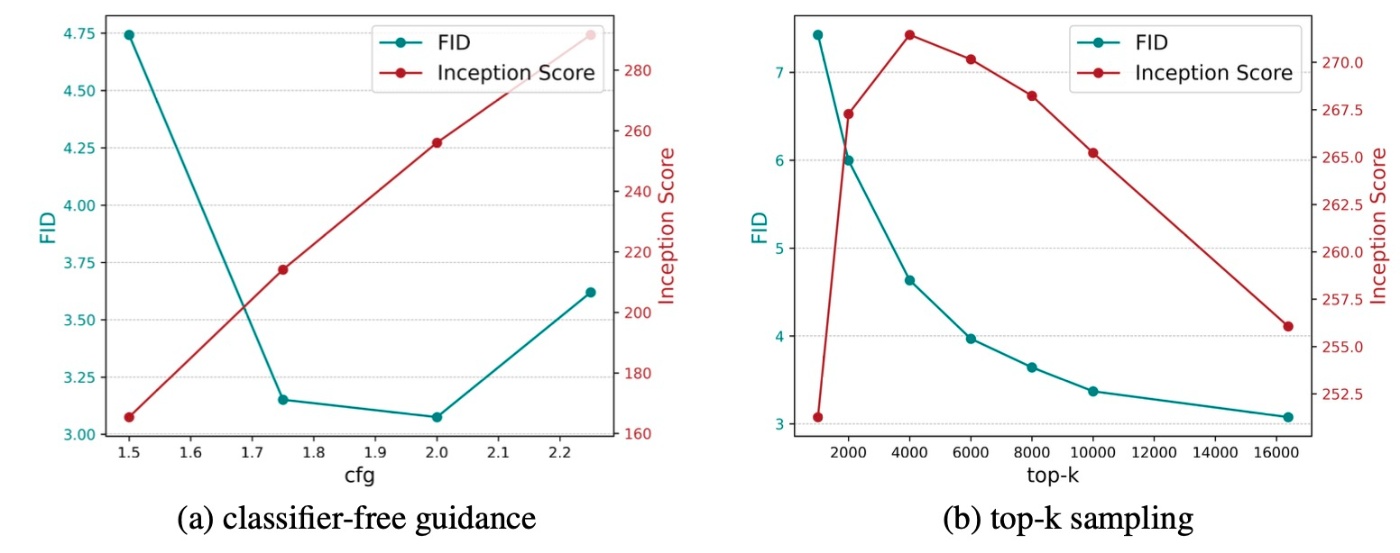
右上図からtop-kのkが小さいと生成品質は悪いです. kを増やすとFIDもISも改善しますが一定のラインからISは減少し, 忠実性と多様性のトレードオフが見られます. 図などはありませんが, top-pやtemperatureでも同様の傾向が見られるようです.
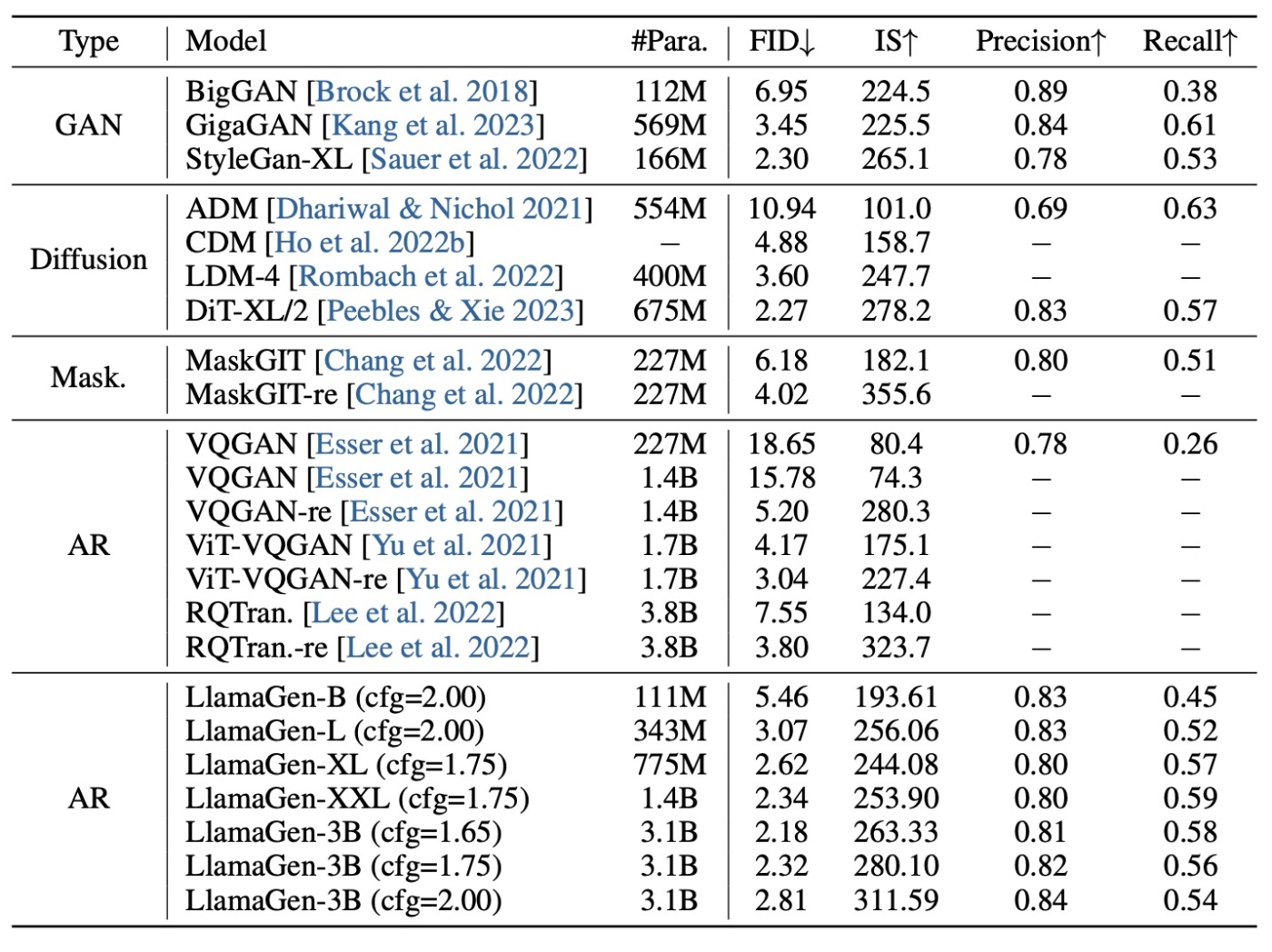
他のモデルとの比較
GAN, Diffusion Models, Masked Prediction Models, AR Modelsとの比較を行います. 全てのモデルで競争力のある結果になっています. 特に, 現在の主流は拡散モデルですが, LlamaGen-3B (cfg=1.65)はそれに匹敵する性能です. 前述した通り, アーキテクチャは既存研究の組み合わせで最適でないことを考慮すると, 今後の改善によって拡散モデルを凌駕する結果を得られると予想されます. ARモデルと比較すると, パラメータ数が少ないにも関わらず上回る性能が得られています. これは, image tokenizerが良い設計であること, scalingがしやすいことなどが挙げられます.
Text-conditional Image Generation
2段階の訓練戦略を採用します.
- LAION-COCOのサブセットである50M, 解像度256のデータを用いて学習する.
- モデルを高品質な10M, 解像度512のデータを用いてfine-tuningする.
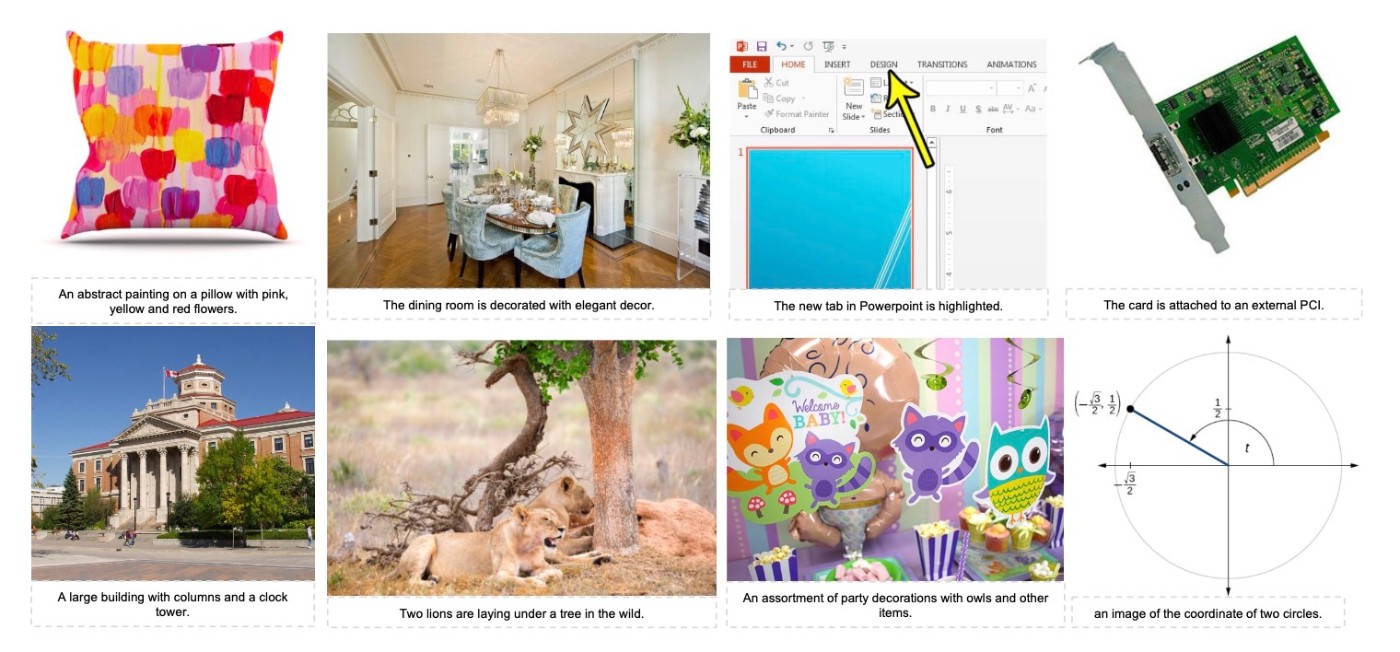
最初のデータは有効なURLをフィルタリングしたのちに, aesthetic score, watermark score, CLIP Score, 画像の大きさで選んで作ります. BLIPによって短いキャプションをつけた例が下図ですが, これは便宜的につけているものと思われます.
fine-tuningするデータではLLaVAを用いて長いキャプションをつけます. その例が下図です.

訓練は先ほどと同じような設定で行いますが, 2段階の学習を始める前にimage tokenizerを2つのデータセットでfine-tuningします.
COCO promptsでの生成例を下に示します. 最初の段階ではtextを反映していますが細部は不明瞭です. 2段階目を終えるとtextの忠実性はそのままに細部まで綺麗な生成が確認できます. このことについて著者らは高品質な画像によるドメインシフトと高解像度による細部の品質向上の2つを考察しています.

limitationとして著者らはテキストレンダリングが弱点である, common misconceptionがあるなどを挙げていますがその実例はありません.
inference speed
この研究ではvLLMを使って高速化を行なっていますが, それによってどれほど高速化が達成できているのかを確認します. classifier-free guidanceありで8枚, なしで8枚の画像を1バッチで生成させたときの比較が次の表です. 3~4倍程度の高速化がされています. なお, この実験ではKV-Cacheも使用されている点には注意です.
まとめ
- Llamaアーキテクチャを採用した自己回帰画像生成モデルの提案
- 拡散モデルの手法にもImageNetで上回る結果
- LLMでの研究成果がそのまま使える
- あくまで既存研究の組み合わせ的なものでアーキテクチャの洗練などがないのでここからさらに性能向上が期待できる
思ったこと
- 結構Techinal Reportの側面が強いなと感じました
- もっと大規模なデータでの結果も気になります
- 著者らも認めるように技術的な新規性は薄いと思いました
- 今回の手法はシンプルなので今後のベースラインとしての活用が見込めると著者らは述べているのですが, Transformerの完成度が高かったように, 本手法の完成度が高い可能性は考えられるのではないかと思います.
- LLMコミュニティでの成果がそのまま使えるのは非常に強いです. そのうちMoE採用などもあるのでしょうか
最後に
公式実装を動かした結果を載せます. 生成時のクラスは固定になっているのでモデルサイズによる比較となります.

LlamaGen-B (256)で生成

LlamaGen-XXL (384)で生成
確かにモデルサイズが大きくなったことで生成品質も向上しています.
簡単に実行環境を示すと下の様な環境です
- PyTorch2.3.1 (docker imageを使っています)
- 4枚のNVIDIA A5000が搭載されています
LlamaGen-Bは生成に3.72秒, decodeで0.27秒です. LlamaGen-XXLは生成に30.88秒, decodeに0.39秒です.
まだ生成速度などの面で拡散モデルには劣るのかなと思います (拡散モデルもschedulerによりますが).
参考文献
- Scaling Autoregressive Models for Content-Rich Text-to-Image Generation (Yu et al., TMLR)
- VQGANのプロジェクトページ
- Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation (Sun et al)
Discussion